







 超级会员免费看
超级会员免费看
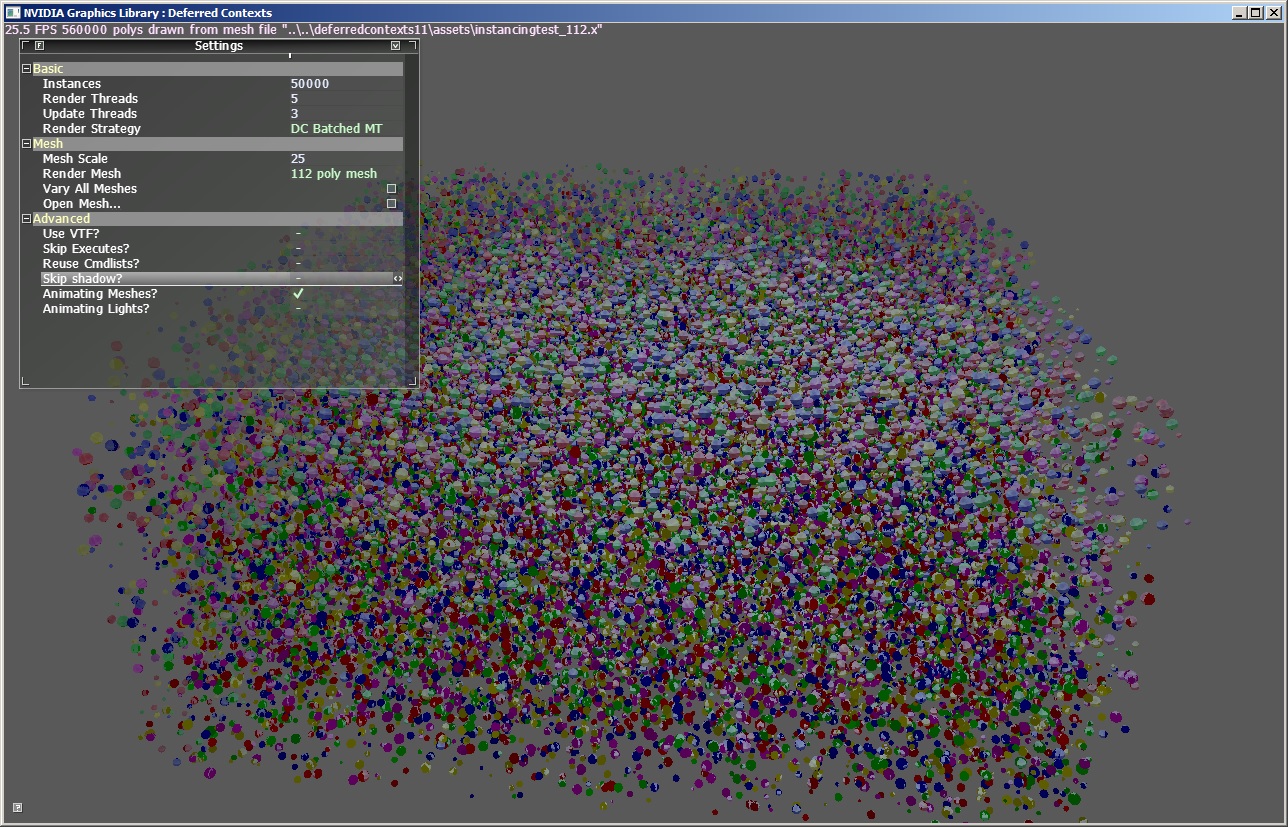
D3D11的device context分为Immediate Context和Deferred Context两种。
Immediate context的命令都会立刻得到执行,deferred context则是把命令存在列表里,
等他被提交的时候才开始执行。因为在调用Draw的时候,
CPU需要做一些额外的事情,所以如果Draw call被分散到多个core去执行,
是会有性能提升的。

里面有关于不同渲染方式的优缺点
This sample shows how to use D3D11 Deferred Rendering contexts to lower the CPU overhead and improve performance when rendering large numbers of objects per frame, in situations where instancing is not feasible.
APIs Used
- D3D11
App-Specific Controls
This sample has the following app-specific controls:
| Device | Input | Result |
|---|---|---|
| mouse | Left-Click Drag | Rotate the view |
| keyboard | Arrow Keys | Translate the view left/right/forward/back |
| W/S | Translate the view forward/back | |
| A/D | Translate the view left/right | |
| TAB | Toggle the HUD | |
| F1 | Toggle help display | |
| F2 | Toggle the Test mode HUD | |
| gamepad | Right ThumbStick | Rotate the camera |
| Left ThumbStick | Move forward/backward, Slide left/right |
Technical Details
Overview
Direct3D11 introduced the concept of a deferred context (DC). DCs allow an application to issue D3D calls on multiple threads simultaneously by recording those calls in a driver level command list which is later executed on the main render thread against the Immediate Context (IC).
This DirectX 11 SDK sample illustrates the benefit of using Direct3d11 deferred contexts to fill command lists on threads and amortize API and driver CPU load across multiple CPU cores.
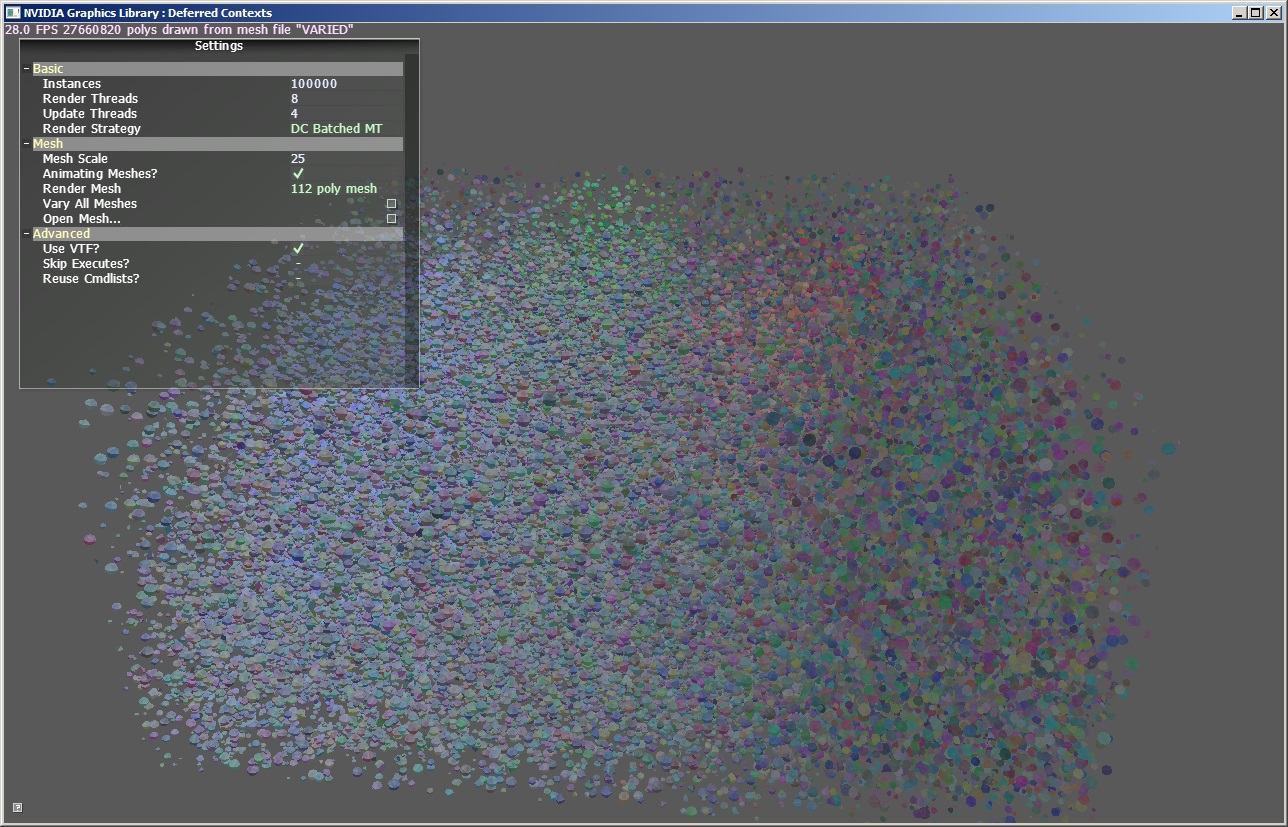
What is a deferred context or a command list?
A deferred contexts is a special ID3D11DeviceContext that can be called in parallel on a different thread than the main thread which is issuing commands to the immediate context. Unlike the immediate context, calls to a deferred contexts are not sent to the GPU at the time of call and must be marshalled into a command list which is then executed at a later date. It is also possible to execute a command list multiple times to replay a sequence of GPU work against different input data.
This documentation will not go into the syntax and low level mechanics of using deferred contexts and command lists in Direct3D11. For that information please refer to Microsoft's DirectX Graphics Documentation on command lists [MicrosoftDirect3D] and my GDC 2013 presentation on deferred contexts [DUDASh43].
Render Strategies
This samples is best evaluated by running on your local machine and observing the performance for different render strategies and object counts. With animation or without. As the number of render threads vary. Then subsequently investigating the render strategy code and understanding how it works.
It is quite possibly a cop out to not fully explain everything in this documentation. However, every engine is different and every use case is different. Use of deferred contexts is very dependent on data set and running environment and as such there is no single recommended technique for every case.
What follows in this documentation is a high level overview of the render strategies in the sample application and some analysis on their strengths and weaknesses.
Immediate Context Rendering
Aka "what most engines do". This technique issues all commands against the D3D11 immediate context. Draws are grouped to minimize state changes and API calls per draw. At the limit a single draw should consist of a few buffer bindings and a draw.
Strengths
- You're likely doing this already (i.e. no work).
- You can do anything you like with no restrictions.
Weaknesses
- All commands must be called on the immediate context, which acts as a sync point.
- CPU bottleneck increases steeply with draw call count.
- Buffer updates (Map) calls are serialized on render thread.
VTF Immediate Context Rendering
This is the same as normal immediate context rendering with the single change to push per object data into a texture that is populated at the start of rendering and used by a large number of draws. This allows the application to batch up per object updates.
Strengths
- Greatly reduced sync points for buffer updates.
- Still fairly flexible, can still change render state, shaders, buffers between calls.
Weaknesses
- Effective max size limit on per object uniform constant data.
Instanced Rendering
Instancing allow for efficient drawing of large numbers of objects which share the same vertex buffer, shaders and render state. It is by far the lowest CPU overhead to draw large numbers of objects, but it comes with significant restrictions to what can be batched together.
It should be noted that in this sample instancing render strategy always uses VTF. Additionally, it must sort all objects to be rendered by vertex buffer. As this sample is simple we are able to make use of instancing, but in a general engine, other state, shaders and mesh data will differ so as to make general use of instancing for all draws infeasible.
Strengths
- Can draw 10s of thousands of independently moving meshes with very low overhead.
- Greatly reduced API call count.
Weaknesses
- Must use VTF or large instance data buffers.
- Must bind the same render state.
- Must bind the same shaders.
- Must bind the same vertex buffer.
Deferred Context Rendering
Deferred contexts allow us to create command lists in parallel which are then executed on the main thread. This can allow us to efficiently assemble everything that needs to be drawn. In this sample we have the option to draw using DCs with or without using VTF.
Strengths
- Almost as flexible as IC draw calls. Can change any state, buffer or shaders as you like.
- Reusable. Can update buffers outside of a DC command list and then replay just the state setup and draw calls.
- Parallelizable. The whole point is to allow the game engine to process d3d calls on multiple threads in parallel.
Weaknesses
- No state inheritance. Must rebind all buffers and state at the start of a command list (but not buffer contents).
- Queries not supported.
- Execution of command lists still takes CPU time, so there is an overhead (amortized by parallelization).
On Vertex Texture Fetch
The sample has an option to draw for all render strategies using Vertex Texture Fetch (VTF). This method skips the per-object uniform constant buffer map and update in favor of a single monolithic texture that contains per instance world matrix and instance color. Additionally, it will bind a second vertex stream that contains per instance UV information which is used to load data from the bound texture in the vertex shader.
It should be noted that at low draw call counts the overhead of using VTF is such that the application can become bottlenecked on updating that texture. As draw/instance counts go up VTF becomes faster as the overhead is amortized and the benefit of reduced buffer mapping outweighs the overhead. In situations where it is possible for an application to easily assemble this monolithic texture of instance data, it is advisable to do so.
However, for normal engine rendering, it is often that case that each draw call will have a significant amount of per instance data mapped into constant buffers and in these cases making use of VTF would be problematic.
The bottom line is that if you can use this technique, it should be faster than individual mapping of instance data for large numbers of relatively homogeneous draws.
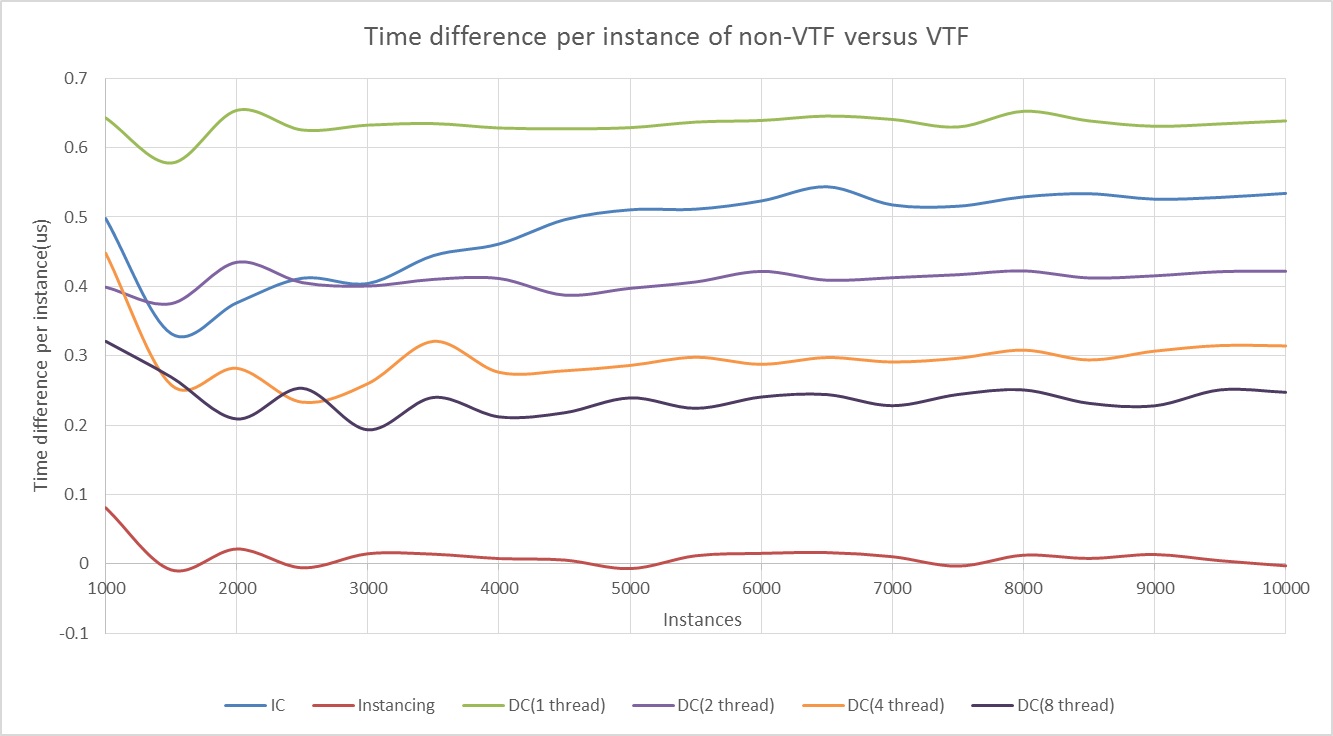
Performance
The entire reason for using or not using deferred contexts revolves around performance. There is a potential to parallelize CPU load onto idle CPU cores and improve performance.
You will be interested in using deferred context command lists if:
- Your game is CPU bottlenecked.
- You have a significant # of draw calls (>3000).
- Your CPU bottleneck is from render thread load or Direct3D API calls.
- You have a threaded renderer but serialize to a main render thread for mapping incurring sync point costs.















 521
521

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









