







这是一篇清华大学2020年发表在sensors上的工作,20多页比较详细;
paper链接:https://www.mdpi.com/1424-8220/20/7/1870
一、目的和创新点
通过单目提取语义特征和矢量高精地图对齐, 低成本实现智能驾驶的定位需求(vo+矢量高精地图纠偏);
对于特征稀疏的场景, 提出和验证了一种基于滑动窗口的帧到帧的运动融合方案,提高了定位稳定性并兼顾实时性;
通过仿真数据和实际数据对提出的方案进行了验证;
二、精度和速度
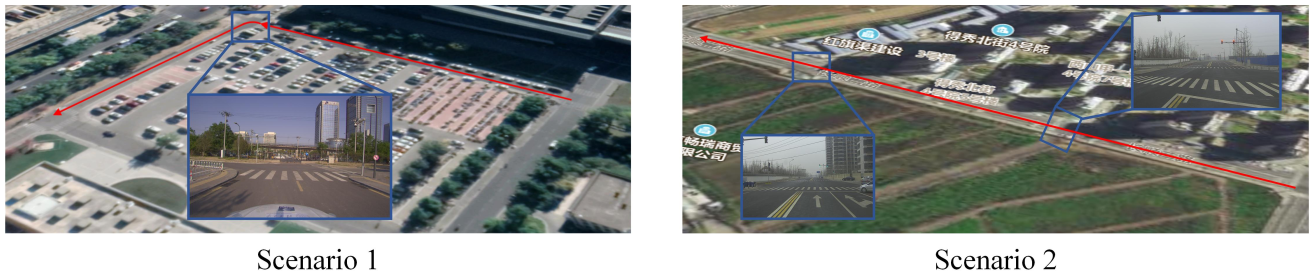
真实场景主要是两个,一个校园内场景,含一个直角转弯;一个校外场景,是一条直道;
gt是lidar定位方法给出的轨迹, 可以看到百米级别translation的精度在0.5m以内,且没有累积误差;
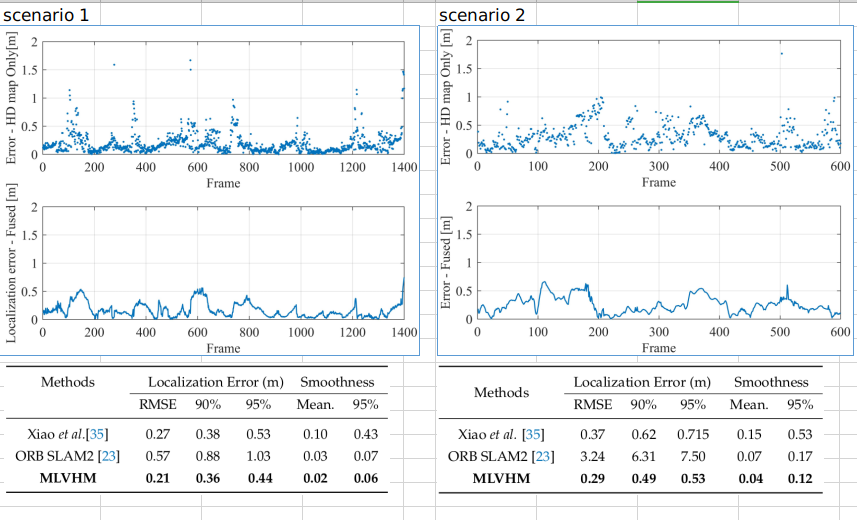
E5-2620 v4+1080ti上, 增加frame to frame fusion后, delay大约是0.059s
三、实现
3.1 系统概览
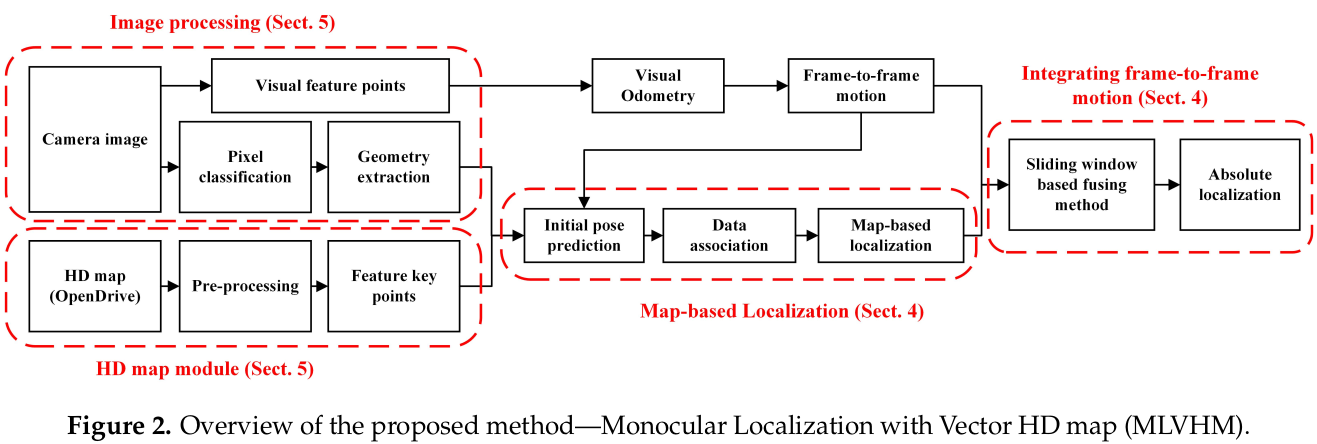
可以理解为基于地图的定位以一个较低的帧率(~2Hz),矫正VO(~20Hz)的漂移,既保证精度,又保证速度;
VO同时为基于地图的定位提供初值。
3.2 基于地图的定位
3.2.1 数据关联策略和优化目标函数
基于地图的定位还是典型的匹配+优化的两步:
数据关联采取了ransac的策略, 我理解应该是一个二分匹配+ransac筛除outlier的过程:
产生一组初始关联c0
多次从c0随机选取3个线特征的关联,并基于这3个线特征计算优化后的位姿x*
如果x*距离初始位姿比较近,则基于x*产生一组c*加入候选集合C{c*1, c*2, ...}
选C中匹配数目最多的一组作为最终的关联

优化的目标函数是线特征和点特征的重投影误差, 其中线特征的重投影误差是地图上控制点投影到图片上以后,和图片上检测出来的线的距离;点特征的重投影误差就是简单的投影点到检测点的距离;
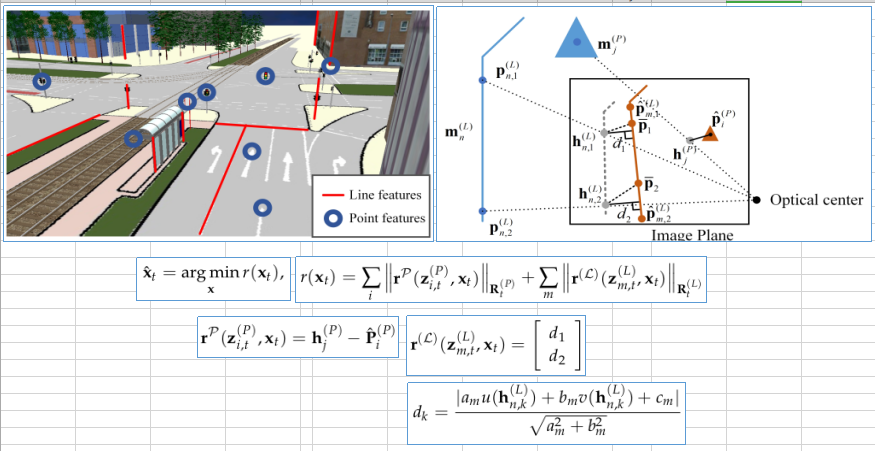
3.2.2 融合帧到帧运动信息(个人理解)
以当前帧为基准,向前取M帧,以最旧的一帧作为基准C0,可以计算这M帧相对C0的旋转和平移;
地图定位有滞后,M帧中只有N帧(N<=M)有地图定位的结果,所以只能用这N帧来融合,优化的变量是C0相对地图坐标系的旋转,平移和尺度;
基于优化后的C0的位姿和尺度, 得到当前的位姿;
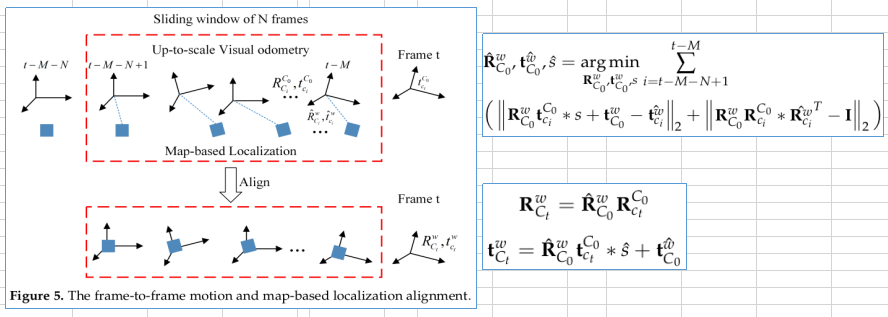
3.3 实施
视觉特征:先做语义分割, 然后线特征用最小二乘法拟合,点特征用型心做控制点进行模板匹配;
地图:opendrive格式
优化器:LM
四、消融实验
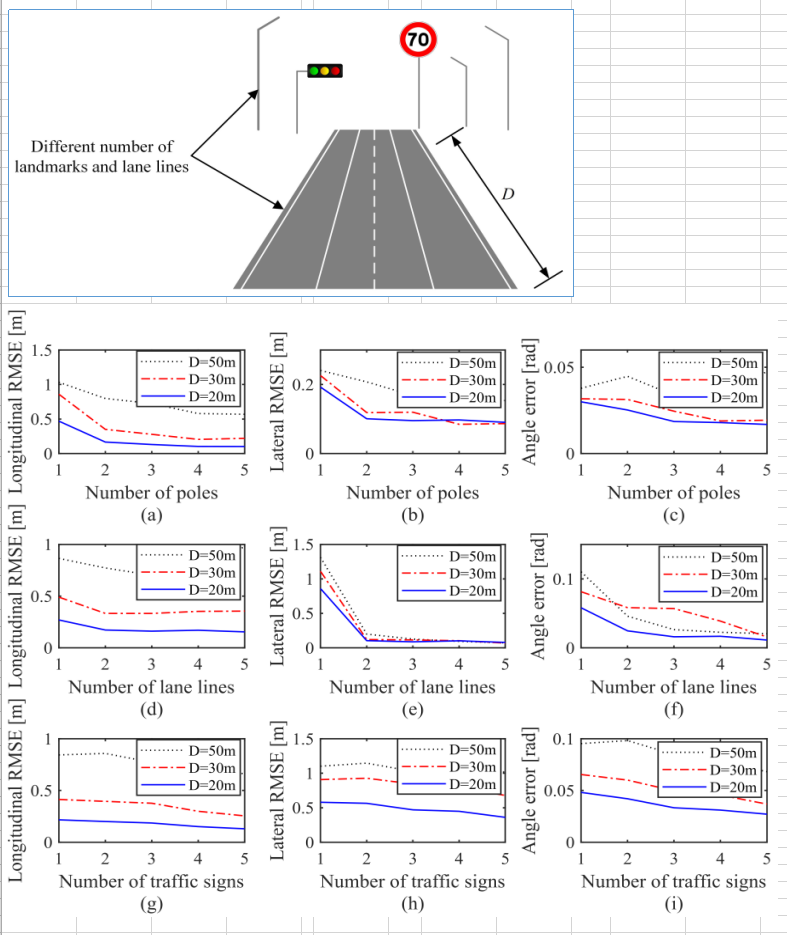
4.1 精度
使用仿真数据进行精度测试,4个线特征能把精度提升到厘米级别:
五、重要参考文献
这篇文章是之前工作的升级版: (2018.05) Monocular Vehicle Self-localization method based on Compact Semantic Map















 2731
2731











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









