







文章链接:https://arxiv.org/abs/2411.11839
文章目录
Abstract
现实世界的真实数据获取变得日益重要。然而,通过远程操作捕获的大规模示范数据通常成本极高,难以高效地扩展数据规模。在模拟环境下采样任务数据是一种实现大规模数据收集的有前景方法,但现有的模拟器在纹理和物理的高保真建模方面存在不足。【也就是说,对现实进行数据采样成本太高了,可以做的是在模拟环境下进行数据的采样,但是现在模拟器太烂了,所以提出了新的模拟器】为了解决这些限制,我们提出了 RoboGSim,一种基于真实到模拟再到真实(real2sim2real)转换的机器人模拟器,集成了3D高斯点云(Gaussian Splatting)技术和物理引擎。
RoboGSim 主要由四个部分组成:高斯重建器(Gaussian Reconstructor)、数字孪生构建器(Digital Twins Builder)、场景编辑器(Scene Composer) 和 交互引擎(Interactive Engine)。它能够通过生成新的视角、对象、轨迹和场景来合成模拟数据。此外,RoboGSim 提供了一种在线、可重复和安全的评估机制,用于验证不同操作策略的表现。真实到模拟(real2sim)和模拟到真实(sim2real)的转换实验表明,在纹理和物理效果上具有高度一致性。此外,基于真实操作任务验证了合成数据的有效性。
我们希望 RoboGSim 能成为用于策略学习公平比较的闭环模拟器。【闭环仿真:模拟环境中的机器人或代理不仅执行动作,而且根据这些动作产生的反馈进行自我调整或优化】更多信息可访问我们的项目页面 https://robogsim.github.io/。

图1.RoboGSim是一个高效、低成本的互动平台,具有高保真渲染功能。它通过新场景、新物体和新视角实现演示合成,促进了策略学习的数据规模扩展。此外,它还可以执行闭环仿真,提供安全、公平和真实的评估,适用于不同的策略模型。
1. Introduction
收集大规模操作数据对高效策略学习至关重要。一些方法提出通过远程操作捕获示范数据及其对应的动作【11, 36, 38】。虽然这类方法相对提高了数据收集效率,但随着数据规模的增加,成本也随之显著增加。为了解决这一问题,一些研究【14, 33】尝试在模拟环境中生成合成数据,并利用这些数据学习操作策略。然而,这些模拟到真实(Sim2Real)的方法由于模拟环境与现实环境之间的域差距较大,往往导致学习的策略难以有效应用。
近年来,一些研究引入了真实到模拟再到真实(Real2Sim2Real, R2S2R)范式用于机器人学习【3, 20】。其核心思想是通过辐射场方法(如 NeRF【24】和 3D Gaussian Splatting, 3DGS【15】)实现真实感的重建,并将学习到的表示插入模拟器中。其中,典型方法 Robo-GS【20】提出了一个 Real2Sim 管线,并引入混合表示以生成支持高保真模拟的数字资产。然而,它缺乏在新场景、新视角和新物体上的示范数据合成,也未能验证这些数据在策略学习中的有效性。此外,由于潜在表示、模拟和现实空间之间的对齐问题,该方法无法实现不同策略的闭环评估。
在本文中,我们开发了一个名为 RoboGSim 的 Real2Sim2Real 模拟器,既支持高保真的示范数据合成,也支持物理一致的闭环评估。RoboGSim 包括四个主要模块:高斯重建器(Gaussian Reconstructor)、数字孪生构建器(Digital Twins Builder)、场景编辑器(Scene Composer) 和 交互引擎(Interactive Engine)。具体而言,给定多视角 RGB 图像序列和机械臂的 MDH【6】参数,高斯重建器基于 3DGS【42】重建场景和物体;接着,数字孪生构建器进行网格重建,并在 Isaac Sim 中创建数字孪生。在数字孪生构建器中,我们引入了布局对齐模块,用于对齐模拟空间、真实空间和 3DGS 表示之间的空间布局。之后,场景编辑器将场景、机械臂和物体结合在模拟环境中,并从新视角渲染图像。最后,在交互引擎中,RoboGSim 作为合成器(Synthesizer)和评估器(Evaluator),完成示范数据合成与闭环策略评估。
与现有的Real2Sim2Real 框架相比,RoboGSim 带来了多项优势。它是首个将示范数据合成与闭环评估统一起来的神经模拟器。RoboGSim 可以生成包含新场景、新视角和新物体的真实感操作示范数据,用于策略学习;同时,它也可以作为评估器,在真实感环境下以物理一致的方式执行模型评估。【该结构的作用:生成数据、模型评估】
总结来说,我们的核心贡献如下:
- 基于 3DGS 的真实感模拟器:我们开发了一个基于 3DGS 的模拟器,通过多视角 RGB 视频重建具有真实纹理的场景和物体。RoboGSim 针对弱纹理、低光照和反射表面等挑战性条件进行了优化。
- 数字孪生系统:我们在系统中引入布局对齐模块。通过布局对齐的 Isaac Sim,RoboGSim 实现了真实空间与模拟空间中物体与机械臂间物理交互的映射。
- 合成器与评估器:RoboGSim 能够合成用于策略学习的真实感操作示范数据(包括新场景、新视角和新物体),并作为评估器以物理一致的方式执行模型评估。
2. Related Work
2.1. Sim2Real in Robotics
Real2Sim2Real 方法的核心目标是解决模拟到真实(Sim2Real)转换中的域间差距【就是普通的差距】,这一问题一直是从模拟到现实应用的主要障碍【8, 26】。为了尽可能弥合 Sim2Real 差距,近年来出现了许多功能丰富的模拟器【7, 22, 27, 34, 37】,并提出了多种数据集和基准用于高效策略学习【12, 13, 16, 25】。
现有的 Sim2Real 方法大致可分为三类:域随机化(Domain Randomization)、域适配(Domain Adaptation)和干扰学习(Learning with Disturbances)【39】:
- 域随机化:通过引入随机性扩展机器人在模拟器中的操作范围,使得模拟环境能够迁移这些能力到现实场景【1, 10, 14, 33】。
- 域适配:旨在统一模拟环境与真实环境的特征空间,从而在统一特征空间内完成训练和迁移【2, 18, 40】。
- 干扰学习:在模拟环境中引入干扰,训练机器人策略,使其能够在充满噪声和不可预测性的现实环境中高效运行【5, 35】。
【总结:sim2real方法:加干扰、加随机、适配】
2.2. 3D Gaussian Splatting in Robotics
作为 3D 重建领域的重要进展,3D Gaussian Splatting(3DGS)【15】通过显式高斯点表示场景,并结合高效的光栅化实现高保真实时渲染,扩展了 NeRF【24】的能力。近年来,许多研究开始探索 3DGS 在模拟器及现实中的操作任务应用。
例如,ManiGaussian【21】引入了一个动态的高斯框架和高斯世界模型,分别通过隐式表示高斯点及其参数化来建模并预测未来的状态和动作。类似地,Gaussian Grasper【41】以 RGB-D 图像为输入,通过特征蒸馏和几何重建,将语义和几何特征嵌入 3DGS,从而实现语言指导下的抓取操作。
为了有效地将模拟中的知识迁移到现实并减少 Sim2Real 差距,基于 3DGS 的研究【17, 20, 28】近年来不断涌现。其中,与我们工作最相似的是 Robo-GS【20】和 SplatSim【28】:
- Robo-GS:通过绑定高斯点、网格和像素实现机械臂的高保真重建,主要专注于 Real2Sim 转换,但对 Sim2Real 阶段的讨论较少。
- SplatSim:重建了场景中的机械臂和物体,同时验证了该方法在 Sim2Real 任务中的可行性。然而,它缺乏对生成物体数字孪生资产的讨论,而数字孪生资产是实现精确操作的关键。
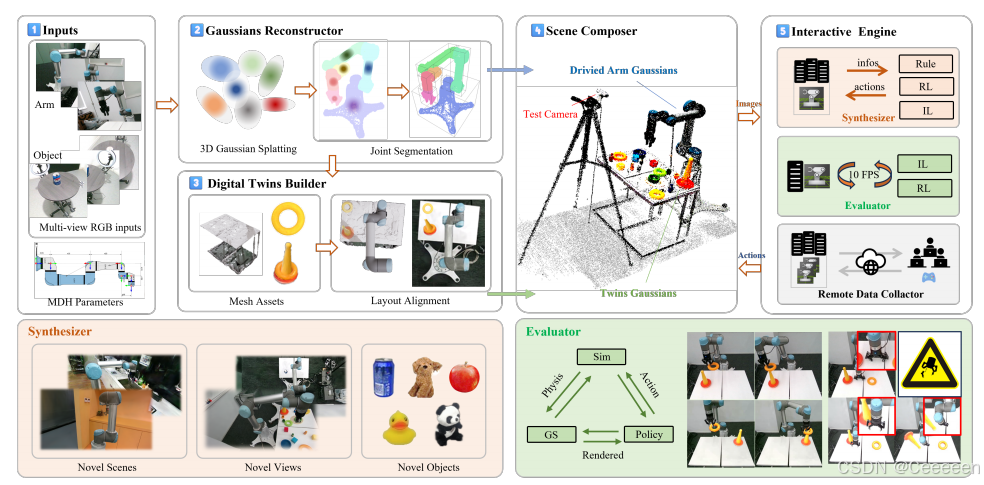
图2. RoboGSim流程概述: (1) 输入:多视角RGB图像序列和机械臂的MDH参数。 (2)高斯重建器:使用3DGS重建场景和物体,分割机械臂并构建MDH运动学驱动图结构,以精确建模机械臂的运动。 (3)数字双胞胎构建器:对场景和物体进行网格重建,然后在Isaac Sim中创建数字双胞胎,确保仿真中的高保真度。 (4)场景编排器:将机械臂和物体结合到仿真中,通过跟踪识别最佳测试视角,并从新的视角渲染图像。 (5) 互动引擎: (i)用于政策学习的合成图像,包含新场景/视角/物体。 (ii) 政策网络可以以闭环方式进行评估。 (iii)可以通过VR/Xbox设备收集具身数据。
3. Methods
3.1. Overall Architecture
如图 2 所示,RoboGSim 主要包括四个模块:高斯重建器(Gaussian Reconstructor)、数字孪生构建器(Digital Twins Builder)、场景合成器(Scene Composer) 和 交互引擎(Interactive Engine)。
- 高斯重建器(详见第 3.2 节):通过 3DGS 方法利用多视图图像和机械臂的 MDH 参数重建场景和物体。它对机械臂进行分割,并构建基于 MDH 的运动学驱动图结构,从而实现机械臂的精准运动建模。
- 数字孪生构建器(详见第 3.3 节):对场景和物体进行网格重建。通过布局对齐(layout alignment),连接资产数据流,为后续在交互引擎中的评估提供支持。
- 场景合成器(详见第 3.4 节):实现新物体、场景和视角的合成。
- 交互引擎(详见第 3.5 节):合成用于策略学习的全新视角/场景/物体图像,同时支持闭环方式评估策略网络。此外,还可利用真实世界中的 VR/Xbox 设备在模拟环境中采集操作数据。
3.2. Gaussian Reconstructor
我们采用 3D Gaussian Splatting(3DGS) 方法重建静态场景,并对机械臂关节的点云进行分割。随后,通过 MDH 动态模型控制与各关节对应的点云,从而实现机械臂的动态渲染。
3DGS 方法【15】使用多视图图像作为输入,进行高保真场景重建。该方法通过高斯点集表示场景,并采用可微分的光栅化渲染技术,实现实时渲染能力。
具体来说,对于由 N N N 个高斯点组成的场景 G = { g i } i = 1 N G = \{g_i\}_{i=1}^N G={ gi}i=1N,每个高斯点 g i g_i gi 可以表示为:
g i = ( μ i , Σ i , o i , c i ) g_i = (\mu_i, \Sigma_i, o_i, c_i) gi=(μi,Σi,oi,ci)
其中: μ i ∈ R 3 \mu_i \in \mathbb{R}^3 μi∈R3 表示高斯点的均值(位置)。 Σ i ∈ R 3 × 3 \Sigma_i \in \mathbb{R}^{3 \times 3} Σi∈R3×3 表示协方差矩阵(描述高斯点的形状和方向)。 o i ∈ R o_i \in \mathbb{R} oi∈R 表示不透明度(opacity)。 c i ∈ SH ( 4 ) c_i \in \text{SH}(4) ci∈SH(4) 表示颜色因子,用球谐系数(spherical harmonic coefficients)表示。
在渲染过程中,像素的最终颜色值 C C C 可以通过一种类似于 A l p h a Alpha Alpha 混合的渲染方法计算得到【15】。该方法利用与像素重叠的 N N N 个有序高斯点的序列,其过程可以表示为:
C = ∑ i ∈ N c i α i ∏ j = 1 i − 1 ( 1 − α j ) (1) C = \sum_{i \in N} c_i \alpha_i \prod_{j=1}^{i-1} (1 - \alpha_j) \tag{1} C=i∈N∑ciαij=1∏i−1(1−αj)(1)
α i = o i ⋅ exp ( − 1 2 δ i ⊤ Σ i − 1 δ i ) (2) \alpha_i = o_i \cdot \exp\left(-\frac{1}{2} \delta_i^\top \Sigma_i^{-1} \delta_i \right) \tag{2} αi=oi⋅exp(−
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 387
387

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









