







 本次比赛要求参赛者解答由GPT3.5生成的科学难题,评估LLM在资源受限环境下的性能。数据集基于OpenBookQA,通过GPT3.5从维基百科生成多项选择题。提交的模型将根据MeanAveragePrecision@3评分,测试集包含约4000个问题。比赛旨在探索大、小模型间的性能差异及LLM的自我测试能力。
本次比赛要求参赛者解答由GPT3.5生成的科学难题,评估LLM在资源受限环境下的性能。数据集基于OpenBookQA,通过GPT3.5从维基百科生成多项选择题。提交的模型将根据MeanAveragePrecision@3评分,测试集包含约4000个问题。比赛旨在探索大、小模型间的性能差异及LLM的自我测试能力。

比赛简介
受OpenBookQA数据集的启发,本次比赛挑战参赛者回答由大型语言模型编写的基于科学的困难问题。
您的工作将帮助研究人员更好地了解LLM自我测试的能力,以及LLM可以在资源受限的环境中运行的潜力。
随着大型语言模型功能范围的扩大,越来越多的研究领域正在使用LLM来表征自己。由于许多预先存在的NLP基准已被证明对于最先进的模型来说是微不足道的,因此也有有趣的工作表明LLM可用于创建更具挑战性的任务,以测试更强大的模型。
与此同时,量化和知识蒸馏等方法正被用来有效地缩小语言模型,并在更适度的硬件上运行它们。Kaggle环境提供了一个独特的视角来研究这个问题,因为提交受到GPU和时间限制的约束。
这个挑战的数据集是通过给出gpt3.5的文本片段来生成的,这些文本片段来自维基百科的一系列科学主题,并要求它写一个多项选择题(有一个已知的答案),然后过滤掉简单的问题。
现在我们估计在 Kaggle 上运行的最大模型大约有 10 亿个参数,而 gpt3.5 有 175 亿个参数。如果一个问答模型能够在一个由问题写作模型编写的测试中胜出,超过其大小的 10 倍,这将是一个真正有趣的结果;另一方面,如果一个较大的模型可以有效地难倒一个较小的模型,这对LLM进行基准测试和测试的能力具有令人信服的影响。
评估方法
提交根据Mean Average Precision @ 3 (MAP@3) 进行评估:
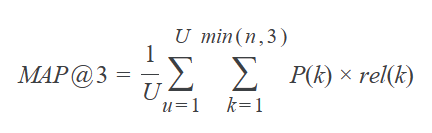
U
U
U是测试集中的问题数,
P
(
k
)
P(k)
P(k)是截止
k
k
k时的精度,
n
n
n是每个问题的数量预测,以及
r
e
l
(
k
)
rel(k)
rel(k)是一个指标函数, 如果处于排名
k
k
k的结果是相关的(正确的)则指标函数等于 1,否则为0。
一旦为测试集中的单个问题赋予评分正确的标签后,在计算中将跳过该标签的其他预测。例如,如果用于观测值的正确的标签 A A A,则以下预测的平均精度均为 1.0 1.0 1.0 。
[A, B, C, D, E]
[A, A, A, A, A]
[A, B, A, C, A]
提交文件
对于测试集中的每个标签
i
d
id
id,您最多可以预测 3 个标签在你的
p
r
e
d
i
c
t
i
o
n
prediction
prediction中。该文件应包含标头并具有以下格式:
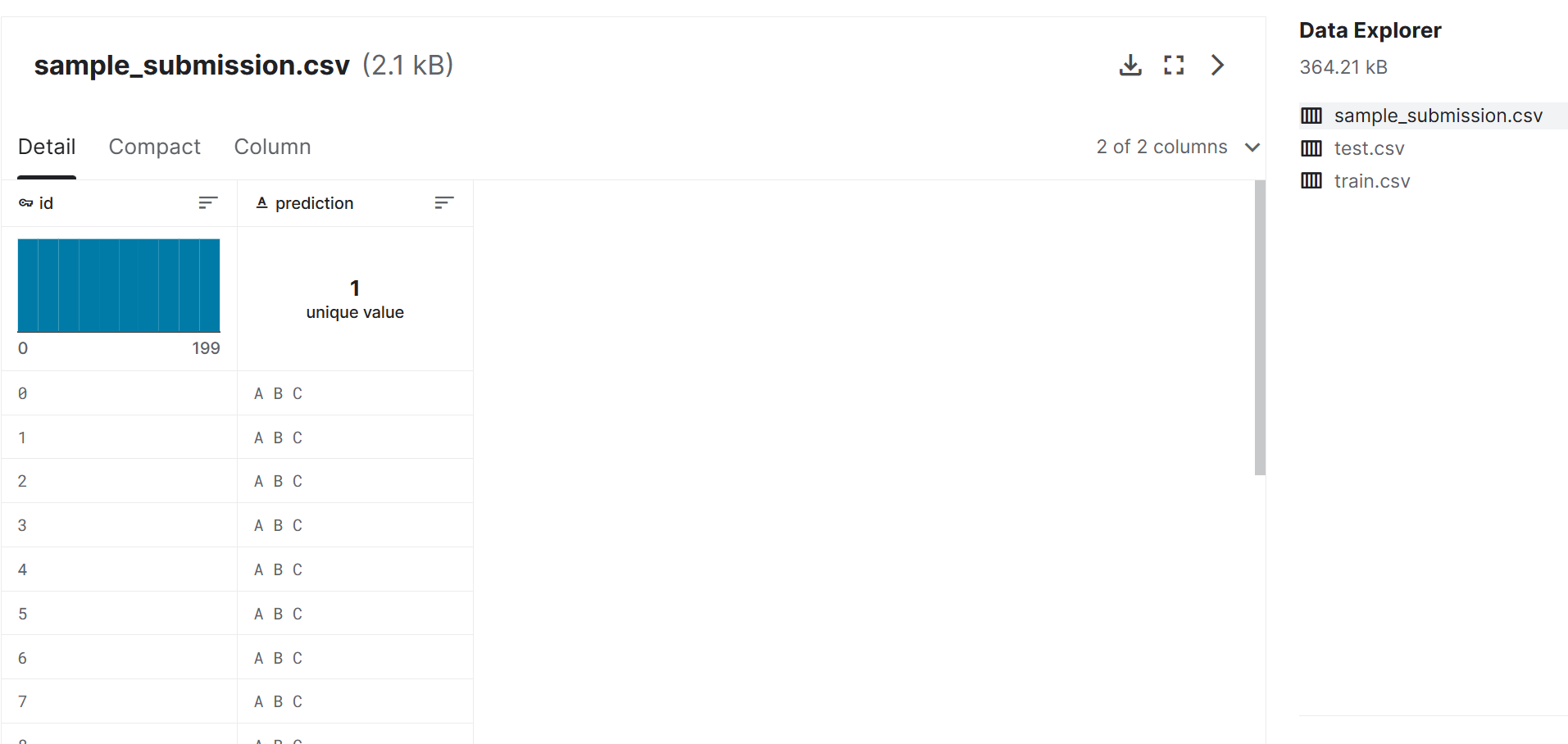
id,prediction
0,A B C
1,B C A
2,C A B
etc.
数据描述
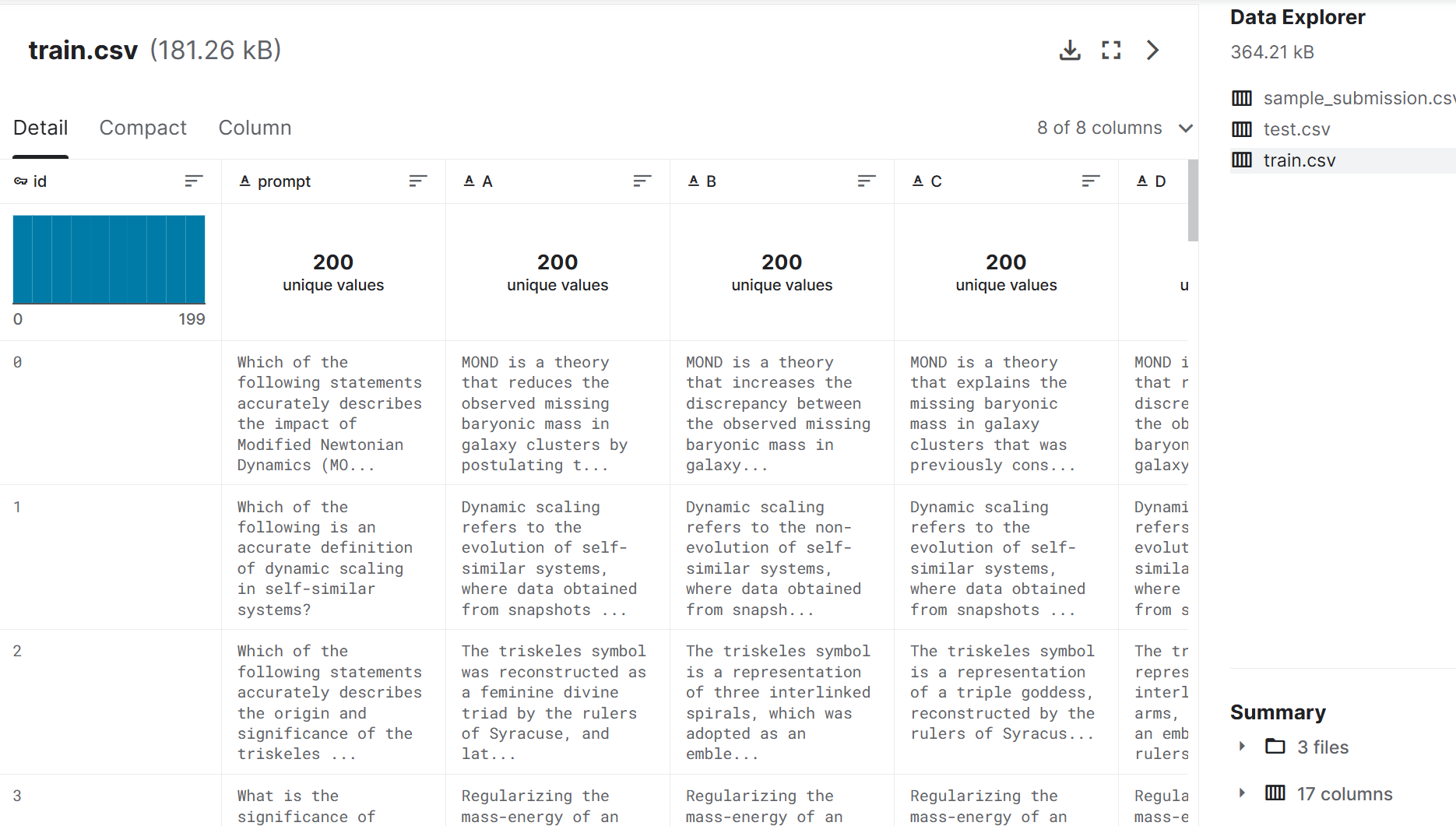
您在本次比赛中的挑战是回答法学硕士编写的多项选择题。虽然用于生成这些问题的过程的细节并不公开,但我们提供了 200 个示例问题和答案,以显示格式,并大致了解测试集中的问题类型。但是,示例问题和测试集之间可能存在分布偏移,因此泛化为一组广泛问题的解决方案可能会表现得更好。每个问题由一个prompt(问题)、5 个标记为A 、B、C、D 和 E 的选项以及标记的正确答案answer组成(这包含由生成的 LLM 定义的最正确答案的标签)。
本次比赛使用隐藏测试。对提交的笔记本进行评分后,实际测试数据(包括示例提交)将提供给笔记本。测试集与提供的test.csv具有相同的格式.csv但有 ~4000 个可能不同的主题问题。
文件
train.csv - 一组 200 个问题,带有答案列。
test.csv - 测试集;你的任务是预测给定提示的前三个最可能的答案。注意:您在此处看到的测试数据只是训练数据的副本,没有答案。看不见的重新运行测试集由 ~4000 个不同的提示组成。
sample_submission.csv - 正确格式的示例提交文件。
列
prompt- 所问问题的文本。
A- 备选方案A;如果此选项正确,则answer为A。
B- 备选案文B;如果此选项正确,则answer为B。
C- 备选方案C;如果此选项正确,则answer为C。
D- 备选方案D;如果此选项正确,则answer为D。
E- 备选方案E;如果此选项正确,则answer为E。
answer- 最正确的答案,由生成的 LLM定义(A、B、C、D、或E 之一)。


















 2323
2323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











