







论文链接:HENet: Hybrid Encoding for End-to-end Multi-task 3D Perception from Multi-view Cameras
代码链接:https://github.com/VDIGPKU/HENet
作者:Zhongyu Xia, ZhiWei Lin, Xinhao Wang, Yongtao Wang, Yun Xing, Shengxiang Qi, Nan Dong, Ming-Hsuan Yang
发表单位:北京大学王选所、长安汽车、加利福尼亚大学
会议/期刊:无
一、研究背景
目前的 3D 感知模型采用了大型图像编码器、高分辨率图像和长期时间序列输入,带来了显着的性能提升。然而,由于计算资源的限制,这些技术在训练和推理场景中通常不兼容。此外,现代自动驾驶系统更倾向于采用端到端的多任务3D感知框架,这可以简化整体系统架构并降低实现复杂度。然而,在端到端 3D 感知模型中联合优化多个任务时,任务之间经常会出现冲突。
当前的挑战:
首先,大型图像编码器、高分辨率图像和长期时间序列输入带来了精度的提升,但是这带来了训练期间的巨大成本。为了缓解这个问题,一部分研究人员通过将过去的信息存储在内存中,但是会遇到时间特征不一致、数据增强效率低等缺点。
其次,为了处理长期时间序列输入,许多工作直接将BEV中不同帧的特征沿通道维度进行求和或连接,但在较长的时间序列下表现出并不令人满意的感知性能。原因是 BEV 中运动物体的特征在不同帧中沿着其轨迹错位且分散在大片区域中。因此,有必要引入动态对准机制来对运动物体进行位置校正。
最后,对于端到端多任务学习,现有工作使用具有多个解码器的共享编码网络来处理不同的任务(比如BEVFusion)。然而,这些工作的实验结果表明,以端到端的方式联合学习多个任务通常不是最优的,即多任务学习中每个任务的性能低于独立训练(负迁移现象)。为了缓解这个问题,一些工作提出调整每个任务的损失权重,但没有全面分析为什么任务之间存在冲突。
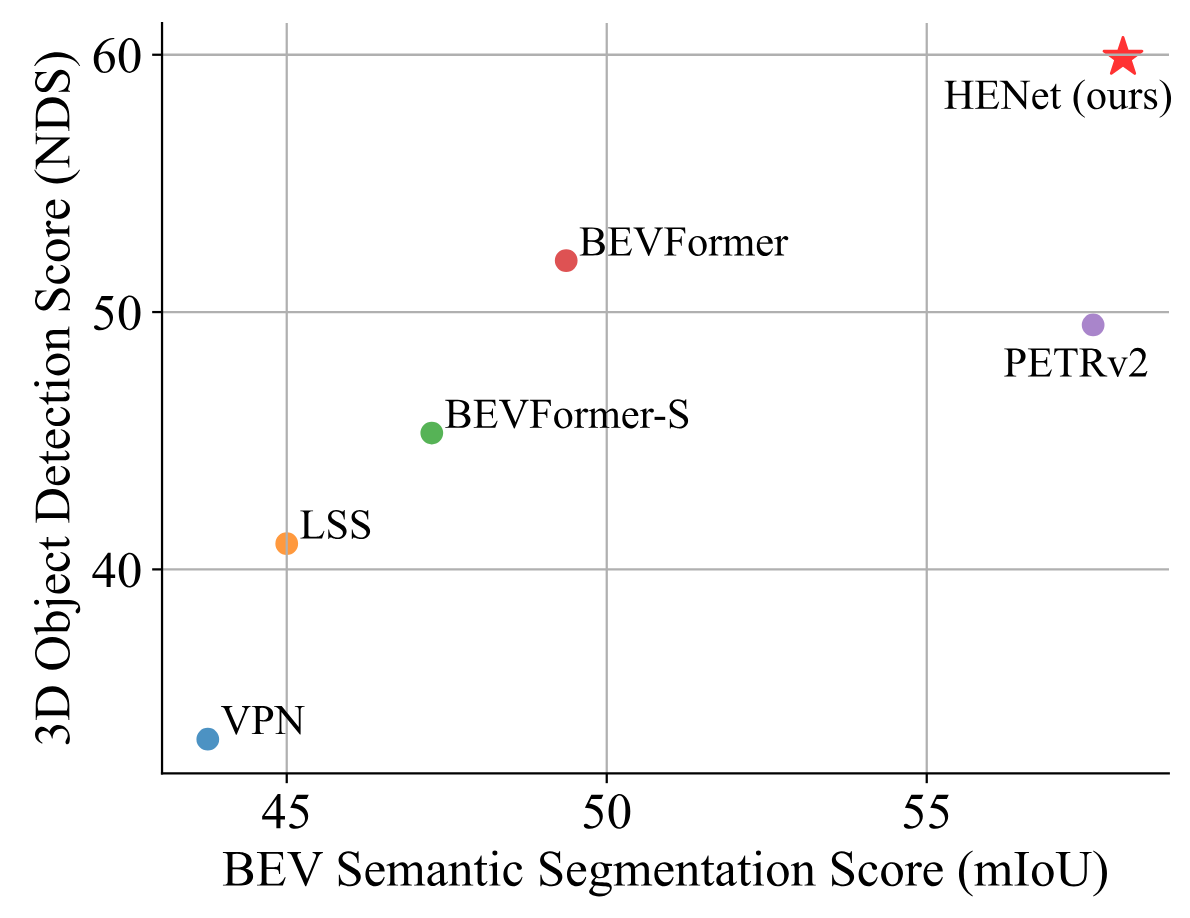
nuScenes val 集上的端到端多任务结果比较。
本文贡献:
-
提出了一个带有混合图像编码网络的端到端多任务3D 感知框架,称为HENet,以利用高分辨率图像、长期输入和大型图像编码器,并实现了较小的训练成本。
-
引入了基于注意力机制的时间集成模块来融合多帧BEV 特征并实现移动物体的动态帧间对齐。
-
分析了端到端多任务学习中的任务冲突,并提出了特征大小选择和独立特征编码来缓解这个问题。
-
在nuScenes 上的端到端多任务学习中取得了最先进的成果,包括3D 对象检测和BEV 语义分割任务。
二、整体框架
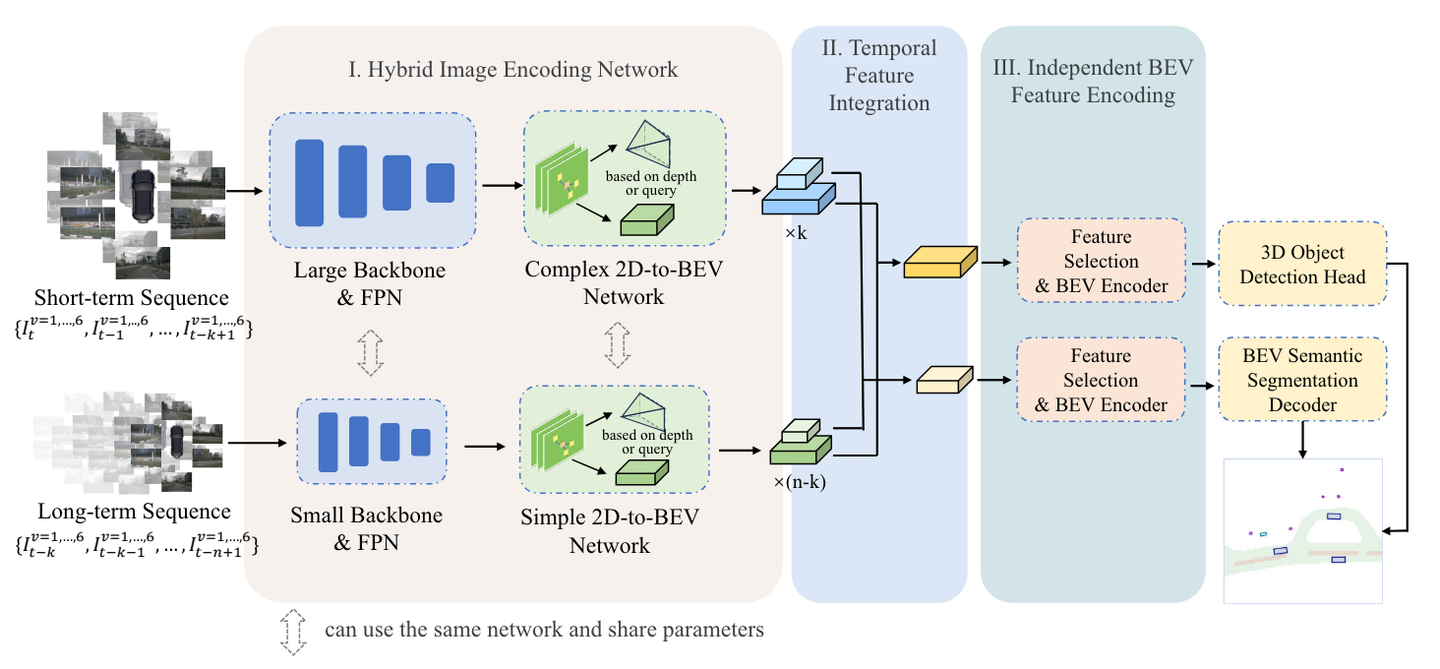
HENet 总体架构。 i) 混合图像编码网络使用不同复杂度的图像编码器分别对长序列帧和短期图像进行编码。 ii)基于注意力机制的时间特征集成模块融合来自多个图像编码器的多帧特征。 iii)根据不同任务的特点,选择合适大小的BEV特征图,并对每个任务进行独立的BEV编码。
对于给定时间多视图图像输入,混合图像编码网络提取其 BEV 特征。然后,使用时间特征集成模块来聚合多帧 BEV 特征。最后,将不同网格大小的BEV特征发送到针对不同任务的独立BEV特征编码器和解码器,以获得多任务感知结果。
三、核心方法
3.1 混合图像编码网络
混合图像编码网络包含了2个不同复杂度的图像编码器,第一个用于处理短时间帧,放大高分辨率输入并将其发送到大型图像backbone和FPN,然后应用复杂的2D-to-BEV网络生成高精度BEV特征。
第二个图像编码器通过将输入下采样到低分辨率并利用小型Backbone和FPN来提取图像特征来处理长期序列。随后采用简单的2D-to-BEV网络来生成高效的BEV特征。
2个图像编码器的某些部分可以共享,比如使用相同的Backbone,而2D-to-BEV网络是不同的。
上述的思路是可以合并到现有的多视图3D目标检测方法中。作者以2种流行的基于BEV的方法BEVDepth和 BEVStereo作为示例来展示所提出的混合图像编码网络的工作原理。
对于处理短期帧的第一个图像编码器,保持图像的高分辨率并利用大型骨干网(VoVNetV2-99),然后使用 FPN来提取特征。然后,应用BEVStereo中的多个卷积层和EM算法来生成立体深度和视锥体特征。 BEVPoolv2将截锥柱体特征转换为多尺度 BEV 特征。
对于第二个图像编码器,首先对长期图像序列的图像大小进行下采样,然后使用小型骨干网络(ResNet50),然后使用 FPN来提取多视图图像特征。之后,采用BEVDepth中的简单单目深度估计网络来获得视锥体特征。此外,使用BEVPoolv2根据相机的内外参数将透视图中的平截头体特征转换为多尺度BEV特征。
同时,为3D目标检测和BEV语义分割任务选择不同的BEV大小。具体来说,使用 256x256 的 BEV 大小进行 3D 对象检测任务,使用 128x128 的 BEV 大小进行 BEV 语义分割任务。
第一个编码器(高复杂度):
-
输入:短期图像帧,高分辨率。
-
结构:一个大的主干网络,如 VoVNetV2-99,后跟特征金字塔网络 (FPN),以提取图像特征。
-
2D-to-BEV 转换:应用 BEVStereo 中的卷积层和 EM 算法,将图像特征转换为视锥特征和立体深度信息。然后通过 BEVPoolv2 进行多尺度 BEV 特征转换。
第二个编码器(低复杂度):
-
输入:长期图像序列,低分辨率。
-
结构:一个小的主干网络,如 ResNet-50,后跟特征金字塔网络 (FPN)。
-
2D-to-BEV 转换:使用 BEVDepth 中的单目深度估计网络获得视锥特征,然后通过 BEVPoolv2 将其转换为多尺度 BEV 特征。
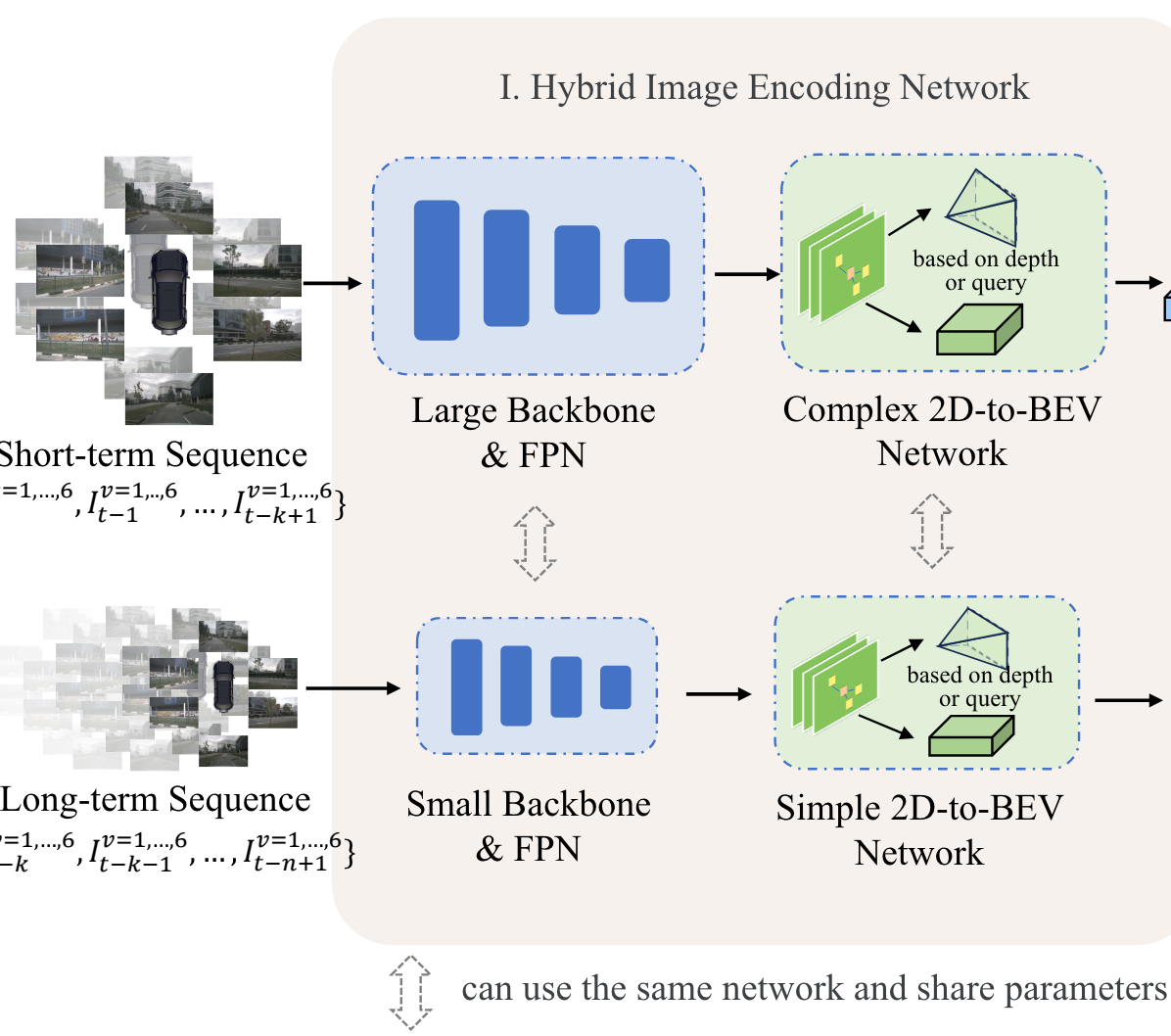
混合图像编码网络结构
3.2 时间特征整合
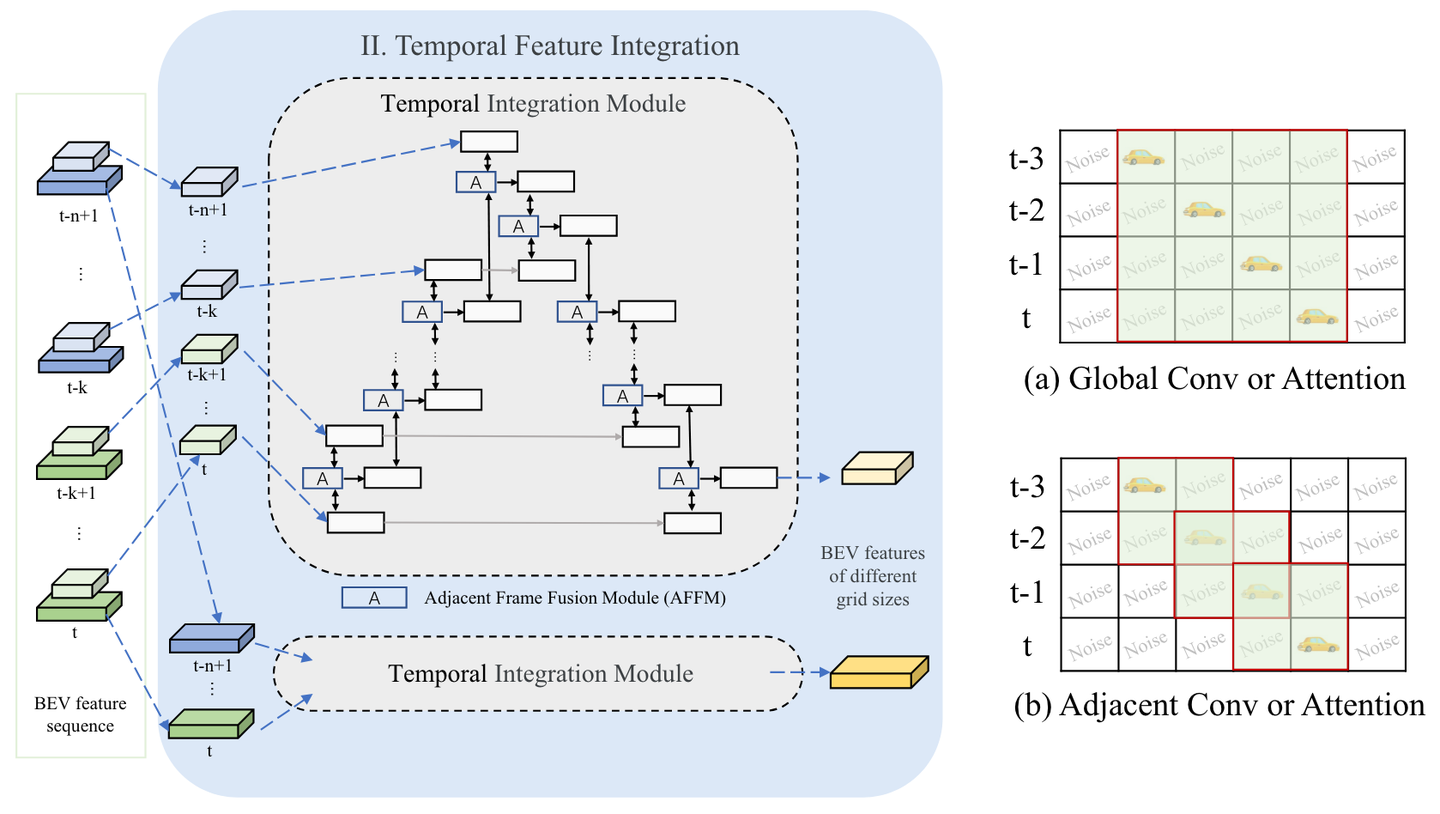
时间特征集成模块的架构。提出了相邻帧融合模块(AFFM),并采用具有时间后向和前向过程的时间融合策略。

伪代码说明
在自动驾驶中,由于摄像头和周围物体的相对运动,相同物体在不同时间帧的特征可能会出现在不同的位置。时序特征整合的目的是要动态地对这些特征进行空间对齐,使得同一物体在不同帧中的特征能够对应起来
通过3.1节的混合图像编码器网络生成多帧BEV特征后,采用时间集成模块来融合BEV特征,如上图所示。时间集成模块由后向过程和前向过程组成。后向过程将当前帧的特征融合到过去的帧,而前向过程聚合从过去到当前帧的特征。在每个处理步骤中,采用具有交叉注意力的相邻帧融合模块(AFFM)来融合两个相邻帧的 BEV 特征。
假设两个帧的BEV特征分别表示为fi和fj,那么AFFM模块可以表示为:
其中,Avg代表平均算子,r是可学习的放缩参数,<>代表串联,Atn()代表注意力模块,可以表示如下:
在后向过程,j=i-1,在前向过程,j=i+1。
为了更好地整合信息,HENet 在时序特征整合中采用了双向处理策略,即不仅将当前帧的信息向前传递,也会向后聚合过去的信息。这种双向处理允许模型在当前帧中利用未来和过去的信息,从而更好地处理速度较快的物体和突发的场景变化。在 AFFM 的帮助下,特征融合不是简单地叠加或连接,而是根据不同帧特征的重要性进行加权平均。
3.3 独立BEV特征编码
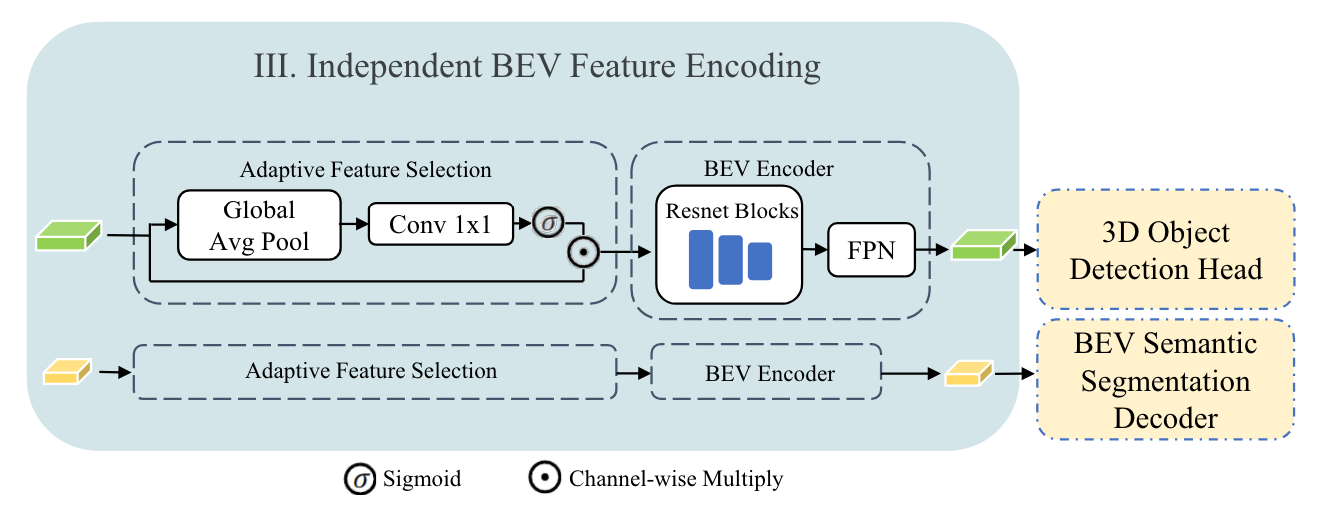
独立 BEV 特征编码的设计。通过独立的自适应特征选择和BEV编码,为每个任务解码器提供不同网格大小的BEV特征图。
在多任务的三维感知系统中,不同任务(例如 3D 目标检测和 BEV 语义分割)通常需要对 BEV 特征进行不同的编码和解码,以确保每个任务能够得到针对性的特征表示。但在统一的 BEV 特征表示上进行多任务操作时,不同任务的需求往往不尽相同,这种情况下共享相同的特征会导致任务之间发生冲突,影响整体性能。
作者通过实验发现,不同任务适合不同大小的BEV特征,因此在获得融合的多尺度BEV特征后,首先将不同大小的BEV特征分配给不同的任务。受 BEVFusion的启发,所提出的编码过程包括自适应特征选择和 BEV 编码。
自适应特征选择如下公式所示,以f adaptive表示,应用了一个简单的通道注意模块来选择重要特征:
其中, 是BEV特征,W代表线性变换矩阵(就是线性层),f avg代表全局平均池化操作, 𝜎 代表sigmoid函数。对于BEV编码器,采用3个残差块和一个简单的FPN,遵循现有的基于 BEV 的方法,在 BEV 特征图上执行局部特征集成。值得注意的是,不同任务的自适应特征选择和 BEV 编码器共享相同的架构,但具有不同的权重。
3.4 解码器和损失
采用 Centerpoint 作为 3D 对象检测解码器,采用 SegNet 作为 BEV 语义分割解码器。 Centerpoint 的分类和回归损失由ℒ𝑐𝑙𝑠和ℒ𝑏𝑏𝑜𝑥表示。将Focal Loss用于 BEV 语义分割任务。车辆、可行驶区域和车道线的损失函数分别表示为ℒ𝑠𝑒𝑔𝑣𝑒ℎ、ℒ𝑠𝑒𝑔𝑎𝑟𝑒𝑎和ℒ𝑠𝑒𝑔𝑑𝑖𝑣。
最终的损失函数定义为:
其中,L depth是深度估计损失, 𝛼 是损失权重。
四、实验结果
4.1 实验细节
以端到端的方式训练 HENet 来执行多任务,包括 3D 对象检测和 BEV 语义分割,与 LSS 相同。分别为大图像编码器选择图像分辨率为896×1600的 VovNet-99 ,为小图像编码器选择图像分辨率为256×704的 ResNet-50 。对于输入时间序列,设置短期帧𝑘=2和长期帧𝑛=9。混合图像编码网络的权重根据预先训练的 3D 检测器进行初始化。选择 0.4m(256×256 BEV 大小)和 0.8m(128×128 BEV 大小)的 BEV 网格大小进行 3D 物体检测和 BEV分别是语义分割。端到端多任务模型在没有 CBGS(类别平衡分组采样,应对自动驾驶中不平衡数据问题,将训练集中包含每个类别的帧进行分组,并从各组中随机选择相同数量的帧构建新的数据集,以保证在训练时,每个类别的数据被选择的机会相同) 的情况下训练了 60 个 epoch。此外,为了进一步将 HENet 与一些单任务方法进行比较,使用 CBGS 训练 HENet 的单个 3D 目标检测模型 12 个 epoch。
4.2 详细实验结果
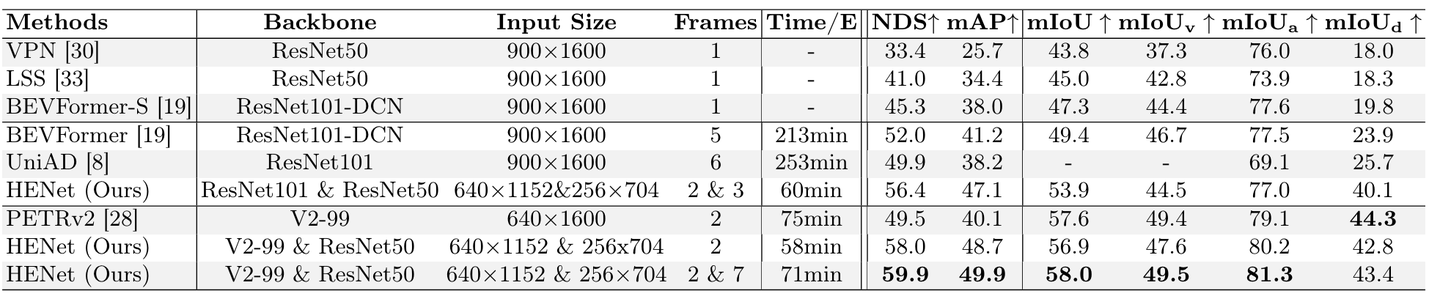
nuScences验证集端到端多任务学习比较。 Time/E 表示 FP32 在 8 × A800 GPU 上每个 epoch 的训练时间。 mIoUv 、 mIoUa 和 mIoUd 分别表示车辆、可行驶区域以及车道和道路分隔线的 mIoU
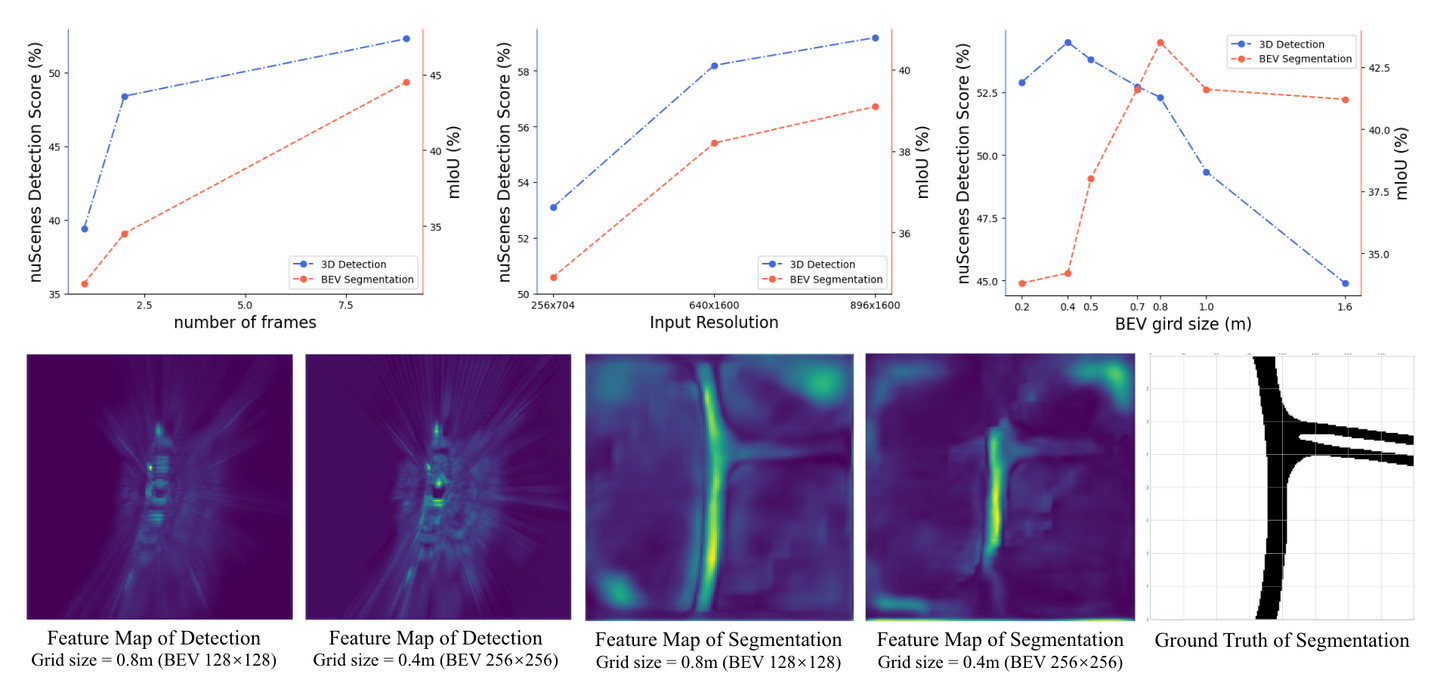
3D 物体检测和 BEV 语义分割之间的异同分析。实验结果表明,每个任务都有合适的BEV网格大小。 BEV语义分割适合的网格大小比3D物体检测大。
如图 5 上半部分所示,当输入分辨率和时间帧数量增加时,3D 对象检测和 BEV 语义分割任务的结果持续改善。然而,对于 BEV 特征网格大小,发现不同的任务更喜欢不同的 BEV 网格大小。
作者推测这种不一致可以归因于任务的特征。 3D 对象检测任务侧重于定位局部前景对象。相比之下,BEV语义分割任务需要全面理解大规模场景,包括车道线和道路。如图5底部所示,检测的BEV特征是局部突出显示,而分割特征则显示全局更多的激活区域。因此,当 BEV 特征网格尺寸太小时,BEV 语义分割任务会受到聚合局部特征的影响,无法捕获用于整个场景理解的全局信息。相比之下,更大的 BEV 特征可以为 3D 物体检测任务提供更多局部细节。
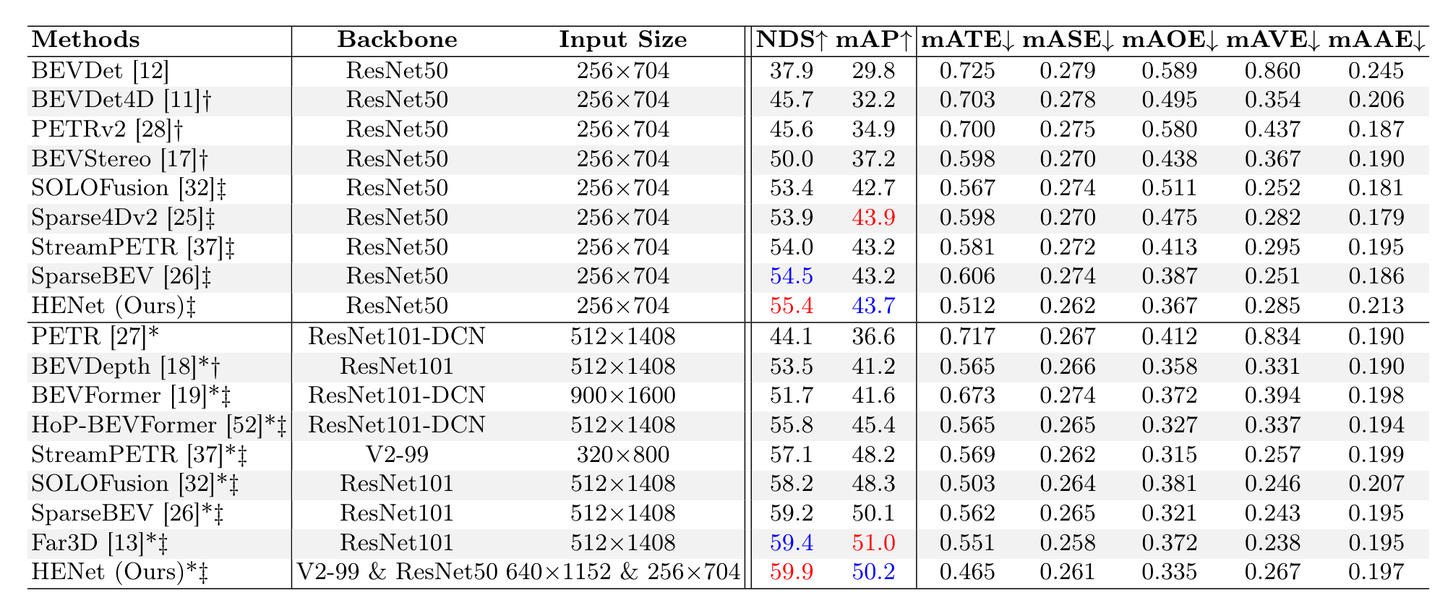
nuScences val 集上 3D 物体检测结果的比较。 ∗ 表示结果受益于透视预训练(有迁移学习)。 † 表示使用一个时间帧信息。 ‡ 表示整合两个或多个时间帧。最好和第二好的结果用红色和蓝色标记。
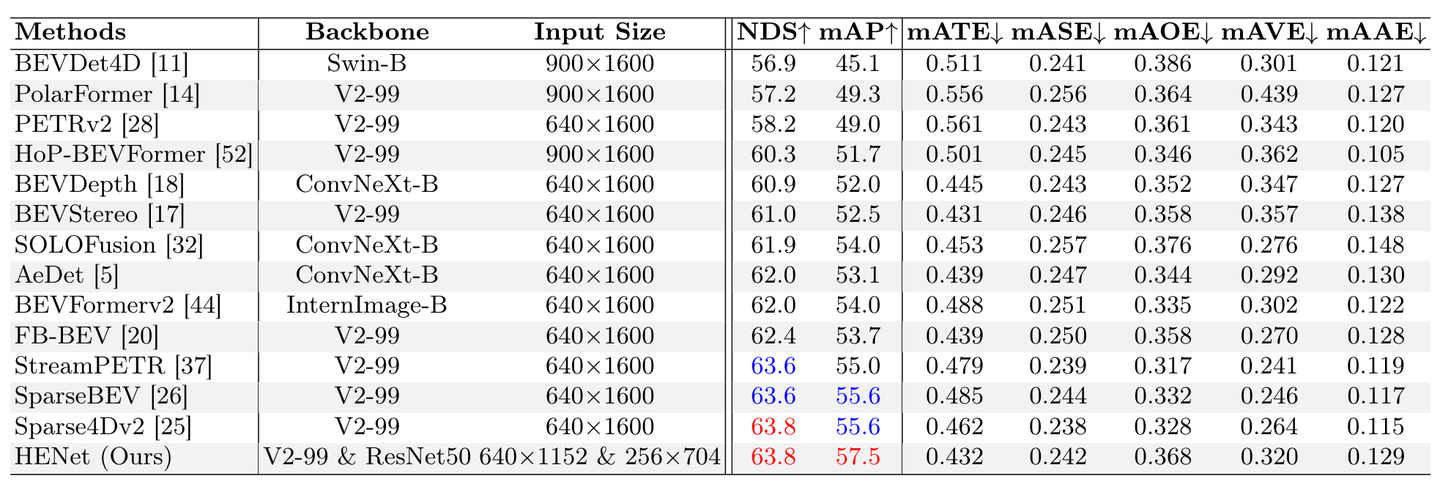
nuScences 测试集上 3D 物体检测结果的比较。最好和第二好的结果用红色和蓝色标记。
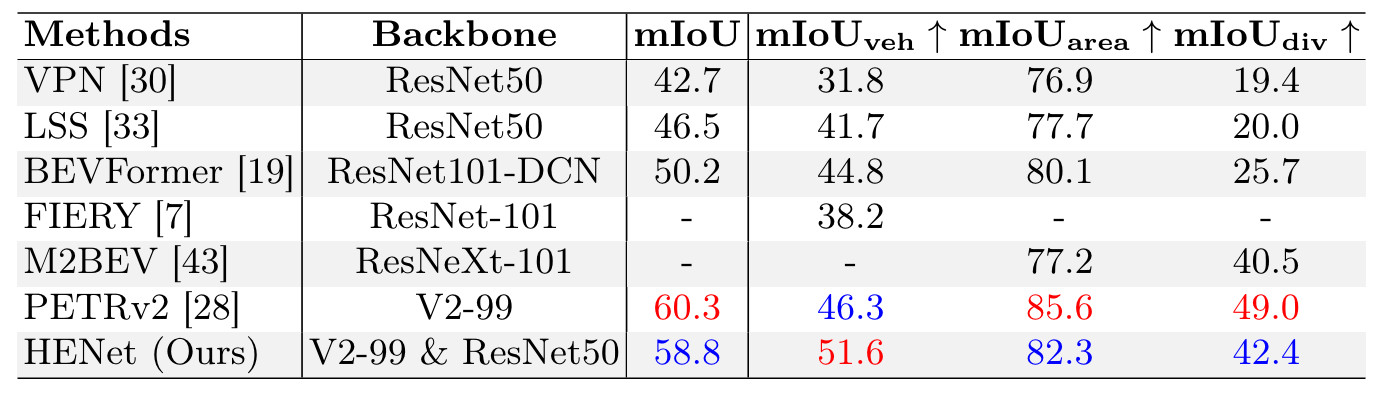
nuScences val 集上的 BEV 语义分割结果比较。最好和第二好的结果用红色和蓝色标记。
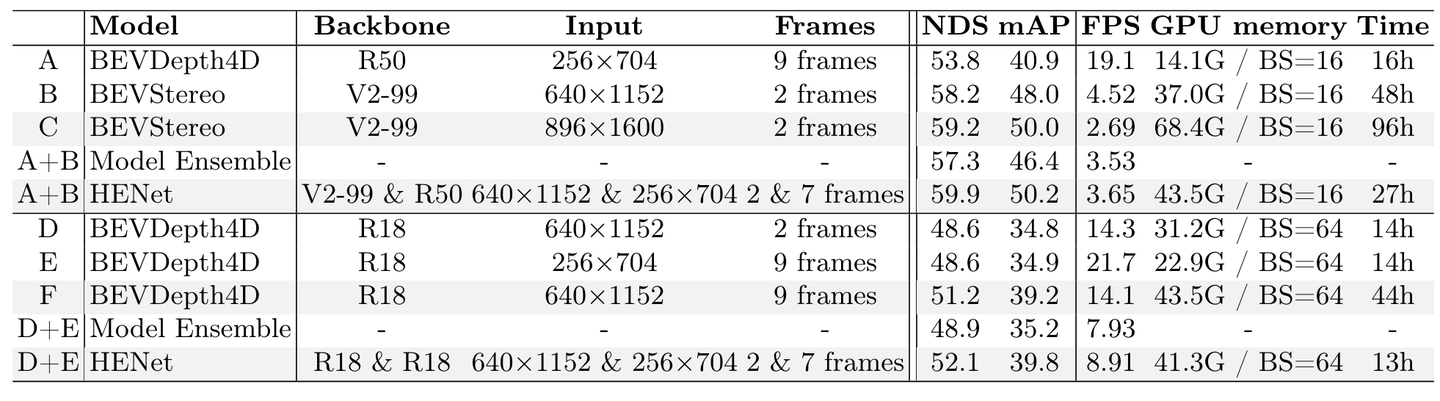
混合图像编码网络的消融实验。 “Time”表示总训练时间。 “BS”表示批量大小。 FPS 是在带有 FP32 的单个 RTX3090 上测量的。训练成本(GPU 内存和时间)是在 8 个带有 FP32 的 × Tesla A800 GPU 上估算的。
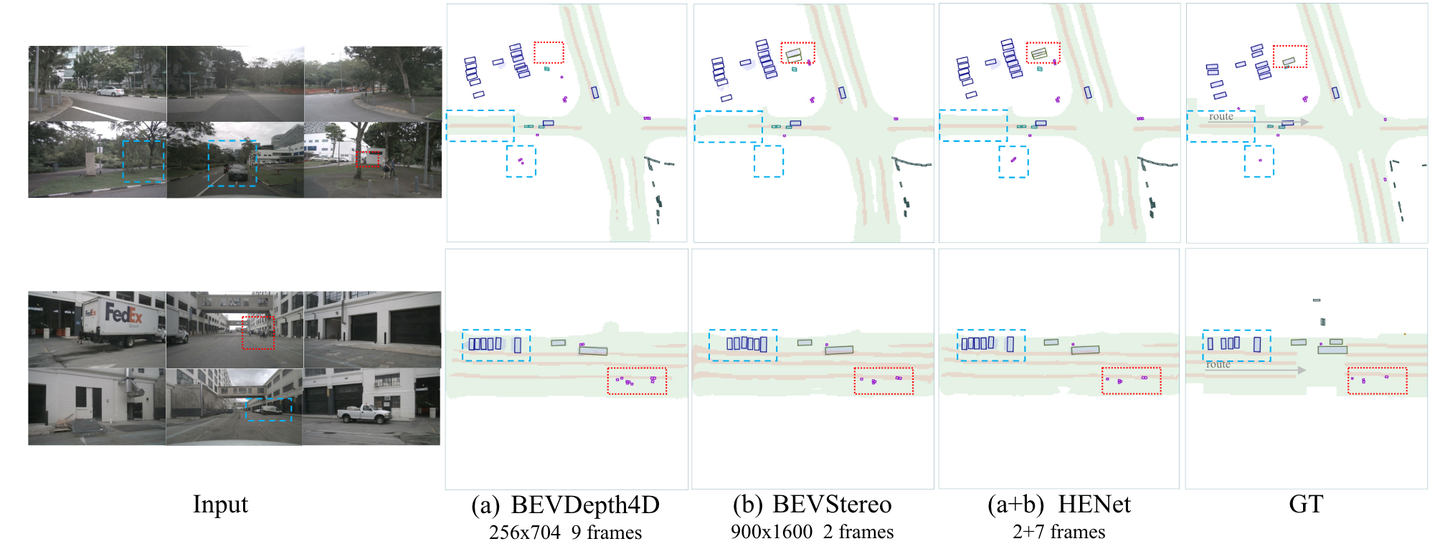
HENet 的可视化结果和端到端多任务处理的基线。从左到右,显示多视图图像输入、BEVDepth4D、BEVStereo 和 HENet(BEVDepth4D + BEVStereo)的结果以及地面实况。拟议的 HENet 通过长期信息更好地估计被遮挡的对象,并通过高分辨率信息做出更准确的预测。
可以看出,由于运动或遮挡,某些物体或场景(如蓝色框中所示)需要更长的时间序列。此外,高分辨率和复杂的深度估计方法有利于困难物体和场景的感知(如红框所示)。 HENet可以有效地结合长时间序列、高分辨率和复杂深度估计的优点。

时间特征集成模块的消融。所提出的使用 AFFM 的后向和前向流程可实现最佳结果。

独立 BEV 特征编码的消融“AFS”是自适应特征选择。 “IE”表示独立 BEV 编码器。所有实验仅使用单个 BEVDepth4D 和 ResNet-50 作为图像编码器。















 871
871











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









