









机器学习可解释性
正文
理解各自特征的预测结果?
介绍
您已经看到(并使用)了从机器学习模型中提取一般解释技术。但是,如果你想要打破模型对单个预测的工作原理?
SHAP 值 (SHapley Additive exPlanations的首字母缩写)对预测进行分解,以显示每个特征的影响。你可以在哪里使用这个?
- 一个模型说,银行不应该借钱给某人,法律要求银行解释每笔拒绝贷款的依据
- 医疗保健提供者想要确定是什么因素导致每个病人患某种疾病的风险,这样他们就可以通过有针对性的健康干预措施直接解决这些风险因素
在本次课程中,您将使用SHAP 值 来解释单个预测。在下一次课中,您将看到如何将这些聚合为强大的模型级洞察力。
SHAP 值 最初来自博弈论中的一个核心问题:在由具有不同技能组合的多个玩家组成的联盟中,这会导致一些集体回报,什么是最公平的如何在玩家之间分配收益?
它们是如何工作的
SHAP 值解释了对给定特性具有特定值的影响,并将其与我们在该特性采用某个基线值时所做的预测进行了比较。
举一个有用的例子,我们将继续从排列重要性和部分依赖图中关于足球数据预测全场最佳球员的例子。
在这些教程中,我们预测了一支球队是否会有球员赢得全场最佳球员奖。
我们可以问:
- 球队进了3个球这个事实对预测的影响有多大?
但如果我们将其重述为: - 有多少预测是由球队进了3个球这一事实驱动的,而不是一些基线的进球数。
当然,每个团队都有很多特点。因此,如果我们回答了目标数量的问题,我们就可以对所有其他功能重复这个过程。
SHAP 值 以一种保证良好属性的方式做到这一点。具体来说,你可以用下面的公式来分解预测:
sum(所有特征的SHAP值) = pred_for_team - pred_for_baseline_values
也就是说,所有特征的SHAP值加起来解释了为什么我的预测与基线不同。这允许我们将预测分解成如下图:

你如何理解这一点?
我们预测的值是0.7,而base_value是0.4979。导致预测增加的特征值是粉红色的,它们的看上去的大小显示了特征影响的大小。减少预测的特征值用蓝色表示。最大的影响来自于进球2。而控球值对预测结果有显著的降低作用。
如果用粉色条的长度减去蓝色条的长度,它等于从基本值到输出的距离。
这项技术有一些复杂性,要确保基线加上个体影响的总和加起来就是预测(这并不像听起来那么简单)。我们不会在这里详细讨论,因为它对使用该技术并不重要。这篇博文有一个更详细的理论解释。
计算SHAP值的代码
我们使用很棒的SHAP库来计算SHAP 值。
对于本例,我们将重用您已经看到的带有Soccer数据的模型。
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
data = pd.read_csv('../input/fifa-2018-match-statistics/FIFA 2018 Statistics.csv')
y = (data['Man of the Match'] == "Yes") # 将 "Yes"/"No" 转化为 2进制 0 或 1
feature_names = [i for i in data.columns if data[i].dtype in [np.int64, np.int64]]
X = data[feature_names]
train_X, val_X, train_y, val_y = train_test_split(X, y, random_state=1)
my_model = RandomForestClassifier(random_state=0).fit(train_X, train_y)
我们将查看数据集的单行(我们任意选择第5行)的SHAP值。对于上下文,我们将在查看SHAP值之前查看原始预测。
row_to_show = 5
data_for_prediction = val_X.iloc[row_to_show] # 在这里使用1行数据。如果需要,可以使用多行吗
data_for_prediction_array = data_for_prediction.values.reshape(1, -1)
my_model.predict_proba(data_for_prediction_array)
array([[0.29, 0.71]])
该队有70%的可能性有一名球员获得该奖项。
现在,我们将继续研究获取该预测的SHAP值的代码。
import shap # Shap Values的 数据包
# 创建可以计算SHAP 值的对象
explainer = shap.TreeExplainer(my_model)
# 计算 SHAP 值
shap_values = explainer.shap_values(data_for_prediction)
上面的shap_values对象是一个包含两个数组的列表。第一个数组是消极结果(未获奖)的SHAP值,第二个数组是积极结果(获奖)的SHAP值列表。我们通常根据对积极结果的预测来考虑预测,因此我们将为积极结果提取SHAP值(提取shap_values[1])。
查看原始数组很麻烦,但是shap 包提供了一种很好的方式来可视化结果。
shap.initjs()
shap.force_plot(explainer.expected_value[1], shap_values[1], data_for_prediction)

如果您仔细查看我们创建SHAP值的代码,您会注意到我们在SHAP.TreeexPlainer (my_model)中引用了Trees。但是SHAP包为每种类型的模型都提供了解释器。
shap.DeepExplainer适用于深度学习模型。shap.KernelExplainer适用于所有模型,尽管它比其他解释器慢,并且它提供了近似值而不是精确的shap 值。
下面是一个使用KernelExplainer获得类似结果的示例。结果并不相同,因为KernelExplainer给出了一个近似的结果。但结果都是一样的。
# 使用内核SHAP来解释测试集预测
k_explainer = shap.KernelExplainer(my_model.predict_proba, train_X)
k_shap_values = k_explainer.shap_values(data_for_prediction)
shap.force_plot(k_explainer.expected_value[1], k_shap_values[1], data_for_prediction)
这里会出现一堆的提示 这里就不一一展显。

轮到你了
SHAP值是很棒的。将它们与您学过的其他工具一起应用,以解决完整的数据科学场景。
练习部分
设置
此时,您已经拥有了足够的工具,可以将令人信服的解决方案组合在一起,以解决实际问题。您需要为以下数据科学场景的每个部分选择正确的技术。在此过程中,您将使用SHAP值以及其他解释工具。
下面的问题通过使用一些检查代码来反馈您的工作。运行以下单元格来设置我们的反馈系统。
# Get most recent checking code
!pip install -U -t /kaggle/working/ git+https://github.com/Kaggle/learntools.git
from learntools.ml_explainability.ex4 import *
print("Setup Complete")
这里就一系列的安装信息,以及完成设置信息
场景
一家医院一直在与“再入院”作斗争,即他们在病人恢复得足够好之前就让病人出院,病人又带着健康并发症回来了。
医院希望你能帮助确定再次入院风险最高的病人。医生(而不是你的模型)将最终决定何时让每个病人出院;但他们希望你的模型能突出医生在让病人出院时应该考虑的问题。
医院已经给了你相关的病人医疗信息。以下是数据中的特征列列表:
import pandas as pd
data = pd.read_csv('../input/hospital-readmissions/train.csv')
data.columns
显示各列名称
Index(['time_in_hospital', 'num_lab_procedures', 'num_procedures',
'num_medications', 'number_outpatient', 'number_emergency',
'number_inpatient', 'number_diagnoses', 'race_Caucasian',
'race_AfricanAmerican', 'gender_Female', 'age_[70-80)', 'age_[60-70)',
'age_[50-60)', 'age_[80-90)', 'age_[40-50)', 'payer_code_?',
'payer_code_MC', 'payer_code_HM', 'payer_code_SP', 'payer_code_BC',
'medical_specialty_?', 'medical_specialty_InternalMedicine',
'medical_specialty_Emergency/Trauma',
'medical_specialty_Family/GeneralPractice',
'medical_specialty_Cardiology', 'diag_1_428', 'diag_1_414',
'diag_1_786', 'diag_2_276', 'diag_2_428', 'diag_2_250', 'diag_2_427',
'diag_3_250', 'diag_3_401', 'diag_3_276', 'diag_3_428',
'max_glu_serum_None', 'A1Cresult_None', 'metformin_No',
'repaglinide_No', 'nateglinide_No', 'chlorpropamide_No',
'glimepiride_No', 'acetohexamide_No', 'glipizide_No', 'glyburide_No',
'tolbutamide_No', 'pioglitazone_No', 'rosiglitazone_No', 'acarbose_No',
'miglitol_No', 'troglitazone_No', 'tolazamide_No', 'examide_No',
'citoglipton_No', 'insulin_No', 'glyburide-metformin_No',
'glipizide-metformin_No', 'glimepiride-pioglitazone_No',
'metformin-rosiglitazone_No', 'metformin-pioglitazone_No', 'change_No',
'diabetesMed_Yes', 'readmitted'],
dtype='object')
下面是解释字段名的一些快速提示:
- 你的预测目标是
readmitted“再次接纳” - 带有
diag一词的栏表示病人所患疾病的诊断代码。例如,diag_1_428表示医生说他们的第一次疾病诊断是428。428对应什么疾病?你可以在编码本里查一下,但如果没有更多的医学背景,这对你来说也没什么意义。 - 列名如
glimepiride_No表示患者没有服用glimepiride药物。如果该特征值为False,则患者确实服用了glimepiride(格列美脲)药。 - 以
medical_specialty开头的特征描述了为病人看病的医生的专业。这些字段中的值都是True或False。
你的代码库
在编写处理此场景的代码时,前面教程中的这些代码片段可能会很有用。您仍然需要修改它们,但我们已经将它们复制到这里,以便您不必查找它们。
参考代
参考码如下
计算并显示排列重要性:
import eli5
from eli5.sklearn import PermutationImportance
perm = PermutationImportance(my_model, random_state=1).fit(val_X, val_y)
eli5.show_weights(perm, feature_names = val_X.columns.tolist())
计算并显示部分依赖图:
from matplotlib import pyplot as plt
from sklearn.inspection import PartialDependenceDisplay
feature_name = 'Goal Scored'
PartialDependenceDisplay.from_estimator(my_model, val_X, [feature_name])
plt.show()
计算和显示Shap 值为一个预测:
import shap # package used to calculate Shap values
data_for_prediction = val_X.iloc[0,:] # use 1 row of data here. Could use multiple rows if desired
# Create object that can calculate shap values
explainer = shap.TreeExplainer(my_model)
shap_values = explainer.shap_values(data_for_prediction)
shap.initjs()
shap.force_plot(explainer.expected_value[0], shap_values[0], data_for_prediction)
第一步
你已经建立了一个简单的模型,但医生说他们不知道如何评估一个模型,他们希望你向他们展示一些证据,证明这个模型正在做一些符合他们医学直觉的事情。创建任何图形或表格,向他们快速展示模型正在做什么?
他们很忙。所以他们希望你将你的模型概述浓缩成1或2个图形,而不是一长串图形。
我们将在您建立基本模型之后开始。只需运行以下单元格来构建名为“my_model”的模型。
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
data = pd.read_csv('../input/hospital-readmissions/train.csv')
y = data.readmitted
base_features = [c for c in data.columns if c != "readmitted"]
X = data[base_features]
train_X, val_X, train_y, val_y = train_test_split(X, y, random_state=1)
my_model = RandomForestClassifier(n_estimators=30, random_state=1).fit(train_X, train_y)
上述正常情况下,用随机森林分类建立模型并拟合,有了模型后,再有以下分析
现在使用下面的单元格创建医生的材料。
这里需要您 填写你的代码
# 填写你的代码
____
答案:
import eli5
from eli5.sklearn import PermutationImportance
perm = PermutationImportance(my_model, random_state=1).fit(val_X, val_y)
eli5.show_weights(perm, feature_names = val_X.columns.tolist())
运行结果如下:
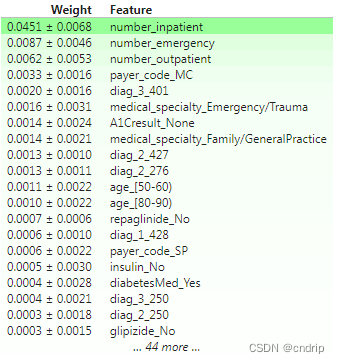
要了解要显示什么,请运行下面的单元格。
# Run this code cell to receive credit!
q_1.solution()
第二步
看来number_inpatient是一个非常重要的特性。医生们想知道更多这方面的情况。为它们创建一个图表,显示num_inpatient如何影响模型的预测。
# 填写你的代码
____
答案 : 将上述的参数代码中的 Goal Scored 修改为 number_inpatient
from matplotlib import pyplot as plt from sklearn.inspection import
PartialDependenceDisplayfeature_name = ‘number_inpatient’
PartialDependenceDisplay.from_estimator(my_model, val_X, [feature_name])
plt.show()

# Check your answer (Run this code cell to receive credit!)
q_2.solution()
第三步
医生们认为,住院治疗次数的增加导致预测的增加是一个好兆头。但是他们不能从这个图中看出这个图的变化是大还是小。他们希望您为time_in_hospital创建类似的东西,以查看其比较效果。
# 填写你的代码
____
答案 : 因为需要查看 time_in_hospital 影响,因此特征修改为time_in_hospital
from matplotlib import pyplot as plt from sklearn.inspection import
PartialDependenceDisplayfeature_name = ‘time_in_hospital’
PartialDependenceDisplay.from_estimator(my_model, val_X, [feature_name])
plt.show()

第四步
哇!住院时间似乎一点也不重要。部分依赖性图上的最低值与最高值之间的差异约为5%。
如果这是你的模型得出的结论,医生会相信的。但它似乎很低。数据可能是错误的,或者你的模型比他们预期的更复杂?
他们希望您向他们展示time_in_hospital的每个值的原始再入院率,以便将其与部分依赖图进行比较。
- 画出那个图。
- 结果相似还是不同?
# Your Code Here
____
提示:这需要对原始数据进行分组(来自pandas),而不是使用模型
答案
一个简单的pandas组,显示每次住院的平均再入院率。
使用concat将验证数据分开,而不是使用所有原始数据
all_train = pd.concat([train_X, train_y], axis=1)
all_train.groupby([‘time_in_hospital’]).mean().readmitted.plot()
plt.show()

第五步
现在医生们确信你有正确的数据,模型概述看起来是合理的。是时候把它变成他们可以使用的成品了。具体来说,医院希望您创建一个函数patient_risk_factors,该函数执行以下操作
- 获取单行患者数据(格式与原始数据相同)
- 创建一个可视化显示患者的哪些特征增加了他们再入院的风险,哪些特征降低了风险,以及这些特征有多重要。
展示每一个特征对再入院风险的每一个微小影响并不重要。只关注病人最重要的特征是可以的。
# Your Code Here
____
提示:这里需要填写显示 SHAP 值,注意要用函数
答案
import shap # package used to calculate Shap values
sample_data_for_prediction = val_X.iloc[0].astype(float) # to test function
def patient_risk_factors(model, patient_data):
# Create object that can calculate shap values
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(patient_data)
shap.initjs()
return shap.force_plot(explainer.expected_value[1], shap_values[1], patient_data)
继续深入
您有一些强大的工具来了解模型和单独预测。接下来,您将查看SHAP值的聚合,以便将模型级和预测级的解释联系起来。

















 3705
3705

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









