









本文来源公众号“算法进阶”,仅用于学术分享,侵权删,干货满满。
原文链接:对比学习在学啥?全面概述!
导读
在不使用任何假设的情况下,阐述了对比学习与谱聚类算法的等价关系。
对比学习是大模型的入门算法。它的想法很简单:对于输入x, 找一些它的正样本和负样本,希望在学习之后的网络特征空间中,x离正样本近一点,负样本远一点。
实际上,对比学习并非个例,预训练算法大多非常简单:要么是遮盖一部分数据内容让模型猜出来,要么是让模型不断预测一句话的下一个词是什么等等。因为这些算法过于简单,人们很难理解它们究竟如何创造出了强大的模型,所以往往会把大模型的成功归功于海量数据或巨大算力,把算法设计归为炼丹与悟性。
有没有更本质的方式,可以帮助我们理解对比学习?下面我给大家介绍一下我们最近的工作[1],可以在不使用任何假设的情况下,刻画出对比学习与谱聚类算法的等价关系。
呃……但这关我什么事?
从理论的角度来看,对比学习与谱聚类算法的等价关系是一个很优美的结果,至少我是这么觉得的——但这对大部分朋友来说并不重要。实际上,可能有一半以上的AI科研人员对谱聚类不太熟悉,对这样的理论刻画自然没有太多兴趣。不仅如此,
-
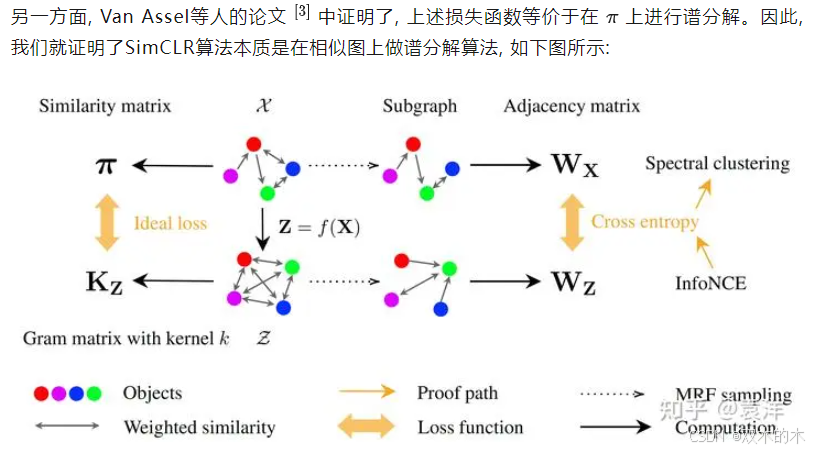
对比学习与谱聚类算法的关系不是我们第一个提出的。人们早就在实践中发现,对比学习得到的模型在分类任务上有突出的效果,但是在其他下游任务中表现一般。马腾宇老师组在2021年的论文[2]中极具创新性地证明了,如果把对比学习中常用的InfoNCE loss改成某种变体(他们称之为spectral contrastive loss),那么得到的模型几乎就是在做谱聚类:是谱聚类的结果乘以一个线性变换矩阵。换句话说,他们已经证明了,对比学习的变体是谱聚类的变体。我们的结果可以看作是对他们结果的进一步完善:对比学习就是谱聚类。因此,虽然我们的结果可以看做是这个问题的一个完美句号,但并不出人意料。
-
我们的理论框架精致,但并非原创。事实上,我们使用了Van Assel等人2022年发表的用于分析Dimension reduction的概率图框架[3],将其调整之后用于对比学习分析之中。虽然这一调整并不显然,相信原作者也没有想到他们的框架可以用来分析预训练模型;但是我们的理论工具确实来源于他们的工作。
所以我想,我们的工作最重要的地方是提供了理解大模型的新视角。对我来说,当对比学习的底层逻辑以一种简洁、优雅的方式展现出来时,它的意义远远超出了谱聚类的理论刻画本身,给我带来了巨大震撼。这种新的视角可以帮助AI从业者更好地理解预训练算法和模型,对未来的算法设计与模型应用都会有帮助。当然,这意味着要先理解一点点数学——不过我保证,这是值得的。
从SimCLR谈起
我们先从Hinton团队2020年提出的SimCLR算法[4]谈起,它也是对比学习的代表算法。SimCLR专门用于理解图像,它基于一个重要的先验知识:把一只狗的图片进行翻转、旋转、切分或者其他相关操作,得到的图片还是在描绘同一只狗。具体来说,论文中考虑了9种不同类型的操作,如下图所示:

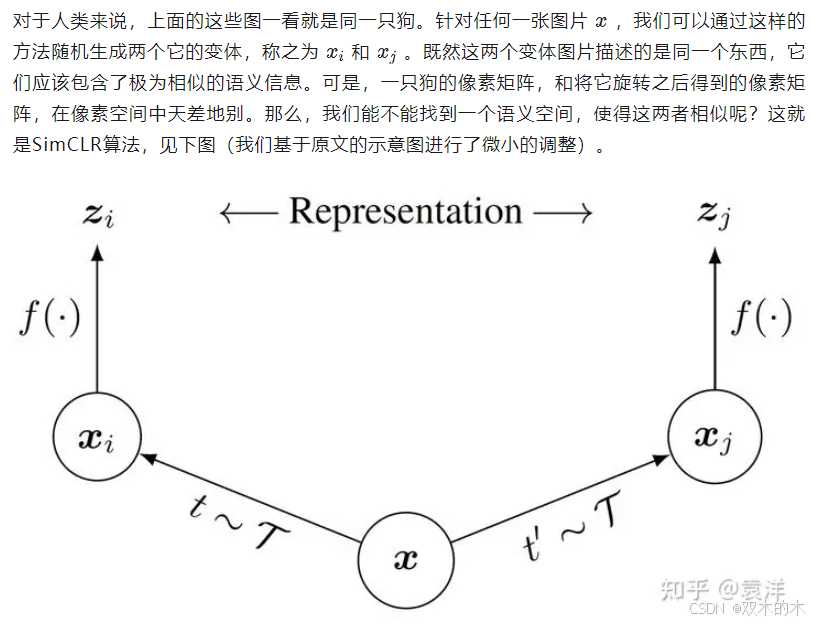

上述就是SimCLR算法分析的传统思路。我们跳过或者模糊不清的部分,就是深度学习中非常重要的玄学——不懂没关系,效果好就行。
我们今天的目标,就是把这些部分解释清楚,同时给出一个与传统分析思路截然不同的新思路。整个故事环环相扣,我们把SimCLR算法搁置一下,先从理想空间谈起。
什么是理想空间?
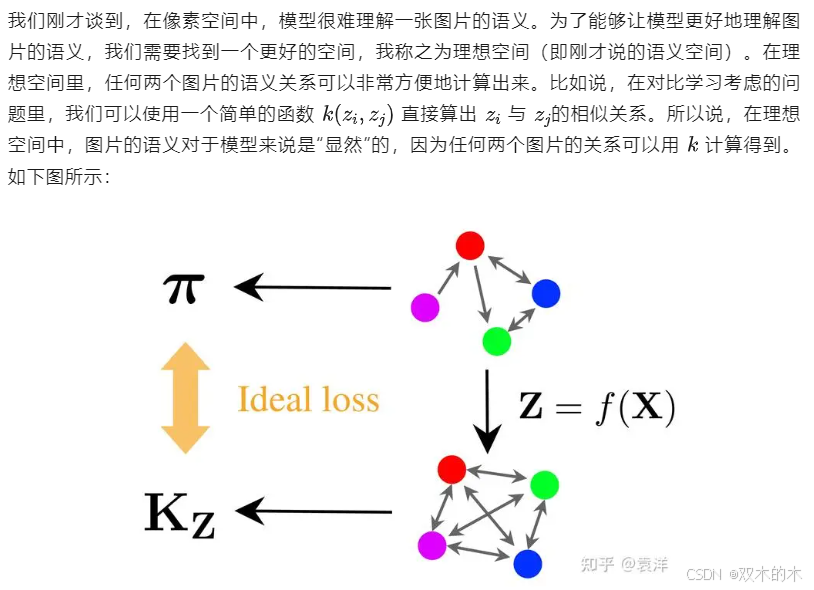

然而,这个算法有个问题,就是损失函数不好算。考虑到我们的数据集非常大,可以包含几百万张甚至更多图片,所以上下两行对应的图都非常庞大,无法直接计算两个邻接矩阵的距离。那该怎么办呢?
很简单,我们可以对原图进行降采样,取两个子图进行比较。如下图所示:
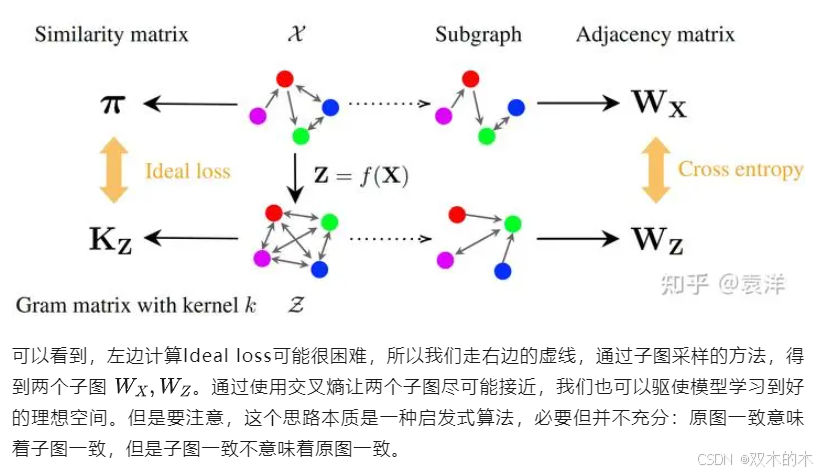
子图采样评分
如何对原图采样呢?我们可以使用Van Assel等人提出的框架[3],使用Markov随机场。对这个工具不太熟悉的朋友不必惊慌,它背后的原理很简单。如果我们想要对原图采样(假设它有 n 个点),那么我们首先需要定义子图的分布。这个分布说白了,就是给每个子图一个得分,使得每个子图被采到的概率与它的得分成正比。换句话说,我们需要设计一个评分函数,用于给每个子图评分,这样就可以定义出一个采样的分布。分高的经常被采,分低的就不怎么会被采到。

从SimCLR到谱聚类

拓展到CLIP
与SimCLR相比,CLIP算法的用途更加广泛。例如,OpenAI提出的文图生成模型Dall-E2就是使用CLIP模型将文字与图像连在了一起,使得人们可以使用文字生成极高质量的图片。CLIP算法同样很简单,就是把图像和其文字描绘当做一组对象,使用InfoNCE损失函数把这两个对象连在一起。使用我们的分析方法,不难发现CLIP本质是在一个二分图上做谱聚类,具体可以参考论文[1]。
总结
可以看到,我们全程并没有为了证明SimCLR而证明SimCLR,也没有加入任何假设。实际上,我们是先从理想空间的角度来理解SimCLR算法,认为应该采用子图采样的方式才能够把理想空间学到。子图采样的方法有很多,我们选了比较自然、容易计算的一个,而它恰好就直接对应了SimCLR的算法!真是颇有一种踏破铁鞋无觅处,得来全不费工夫的感觉。
我认为这背后提供的新视角是非常重要的。SimCLR/CLIP这些基础的预训练算法,其实是在把对象映射到理想空间,使得要学习的关系在理想空间中可以用简单函数自然地计算。当我们关注预训练算法的时候,我们不应该只看它的算法描述,而应该更多地关注模型通过学习对象的表征,构建了一个什么样的理想空间。
毕竟,算法的最终目标可能要比算法的前行路线更值得分析。
本文介绍的论文题为《Contrastive Learning Is Spectral Clustering On Similarity Graph》[1],由谭智泉、张伊凡、杨景钦和我合作完成。
参考
-
^abcd[3] https://arxiv.org/abs/2303.15103v2
-
^[1] https://arxiv.org/abs/2106.04156
-
^abc[2] https://arxiv.org/abs/2201.13053v2
-
^[4] https://arxiv.org/abs/2002.05709
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









