







作者 | 腾讯混元团队
在当前的大模型研究领域,MoE(混合专家)模型正迅速成为焦点。相比传统的Dense模型,MoE模型凭借其稀疏激活特性,在增加模型总参数的同时,有效控制了激活参数的数量,从而大幅提升计算效率。此外,每个专家专注于处理特定的数据和特征,使得模型能够更好地捕捉数据的多样性,显著增强整体性能。多个专家的协同计算还减少了过拟合风险,提高了模型的鲁棒性。
然而,MoE领域的研究与创新主要集中在优化模型训练和路由策略上。目前主流的MoE模型大多基于Google于2020年提出的混合同构专家模型Gshard。但MoE结构里的专家设计上长期未能取得显著进展。MoE模型面临以下三大挑战:
专家专业化程度不足,导致路由随机分发token,专家在训练中趋同
参数分配不够高效,简单输入消耗过多计算资源,而复杂输入得不到充分处理
表示坍缩和负载不均衡问题,限制了模型的表达能力和计算效率。
为了应对这些挑战,腾讯混元团队创新性地提出了混合异构专家模型(HMoE)。在HMoE中,每个专家的大小不再相同,从而赋予了每个专家不同的表达能力。这种差异化设计使得路由可以根据专家的实际能力动态分配不同难度的token,有效解决了专家专业化程度不足的问题。
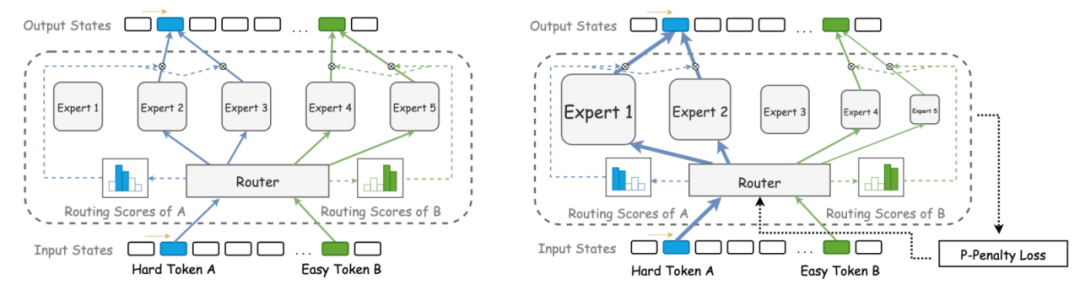
左:传统MoE结构,右:混合异构MoE结构
实验上,HMoE无论在性能上还是效率上都显著优于传统MoE。随着训练进行,HMoE的激活参数更少,在下游任务上的性能更强。
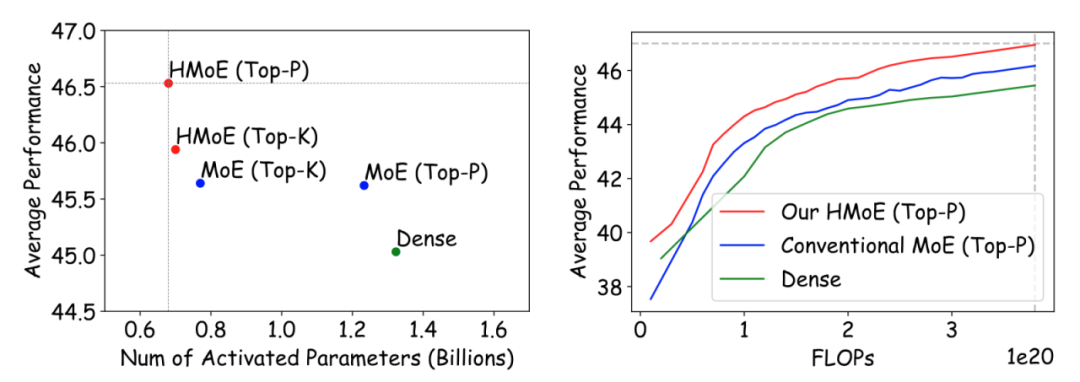
左:不同模型的性能和激活参数对比,右:随着训练进行,相同成本的性能对比
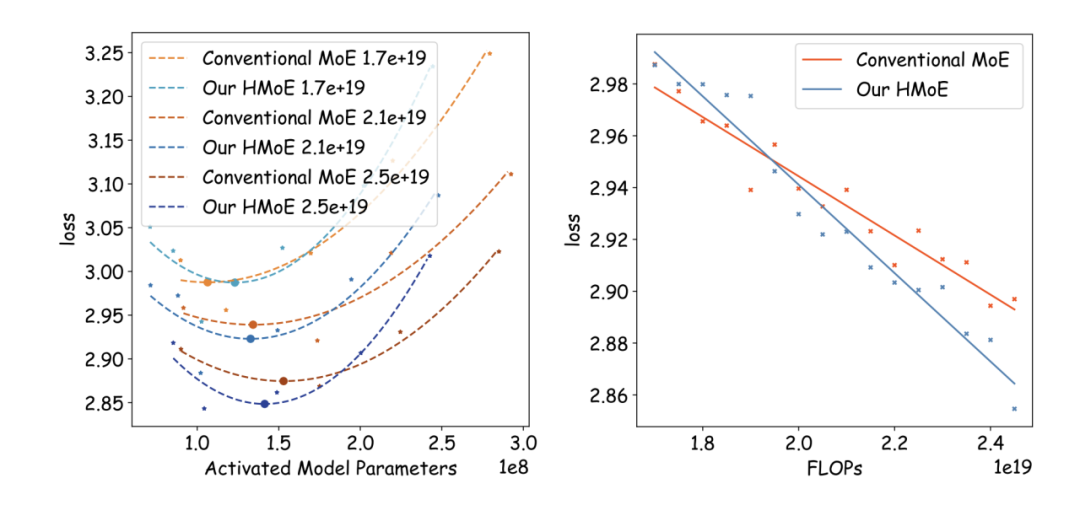 左:不同训练成本下的最佳激活参数,右:最佳激活参数设定下的loss对比
左:不同训练成本下的最佳激活参数,右:最佳激活参数设定下的loss对比
为了实现更高效的参数分配并利用MoE的负载不均衡现象,腾讯混元团队还提出了激活更多小专家的策略。他们设计了P-Penalty Loss来惩罚模型倾向于激活大专家的行为,从而引导模型更多地激活小专家:
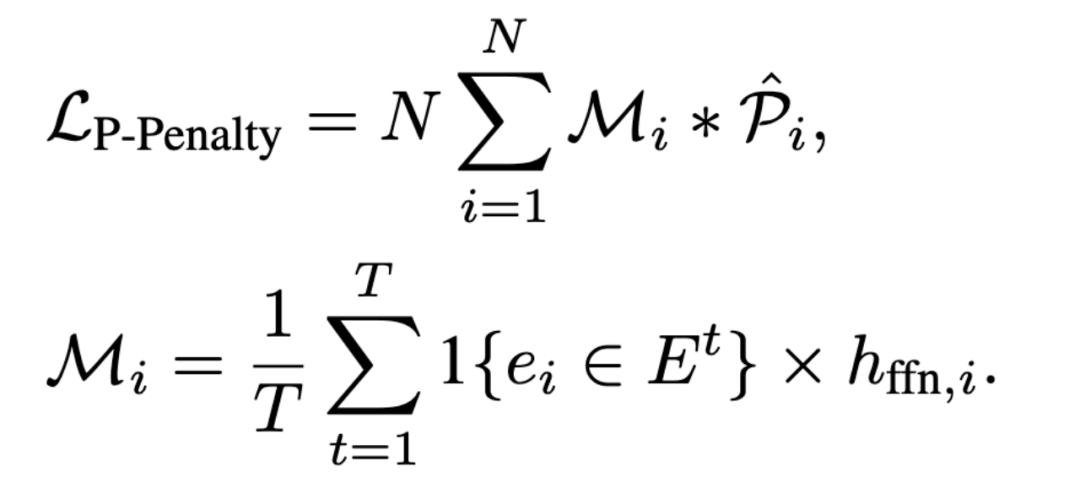
根据每个专家Hidden state的大小进行惩罚
这一策略不但有助于提高计算效率,而且也是使得HMoE在同等算力消耗下能让效果更佳的关键所在:
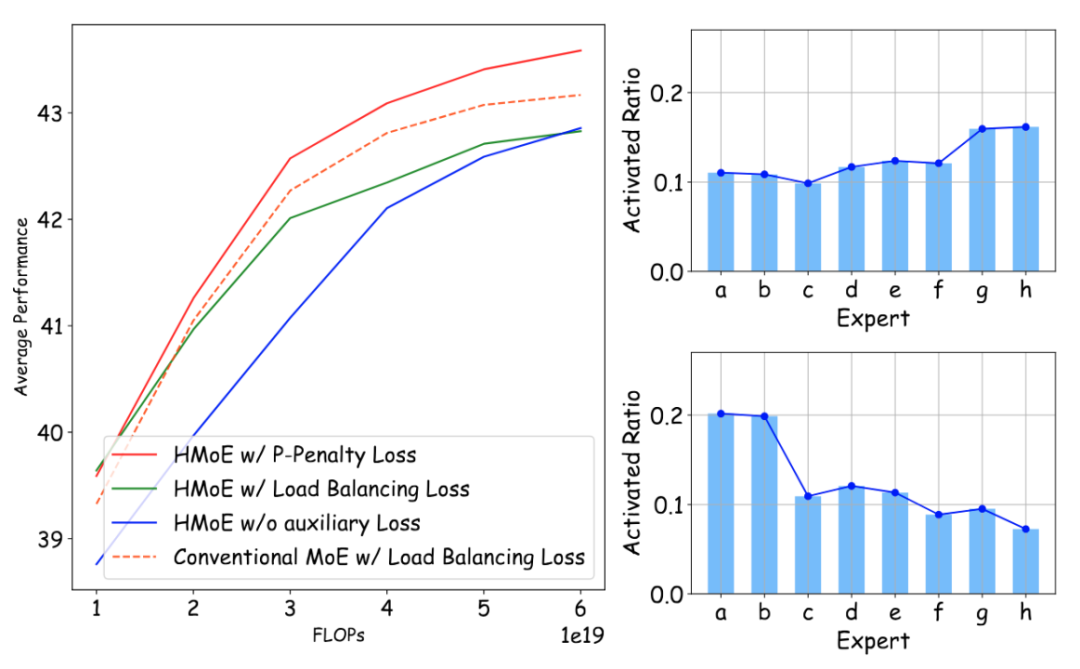
不同辅助Loss对模型效果的影响(左)。负载平衡Loss(右上)和P-Penalty Loss(右下)下,激活参数比率与专家尺寸的关系(a-h专家尺寸逐渐变大)
此外,腾讯混元团队还对HMoE的异构性进行了深入探索。他们设计了服从等比数列和等差数列的模型大小分布,并发现合理的模型大小差异对模型训练效果和稳定性具有至关重要的影响。通过调整异构性的设计,他们进一步提高了HMoE的性能。
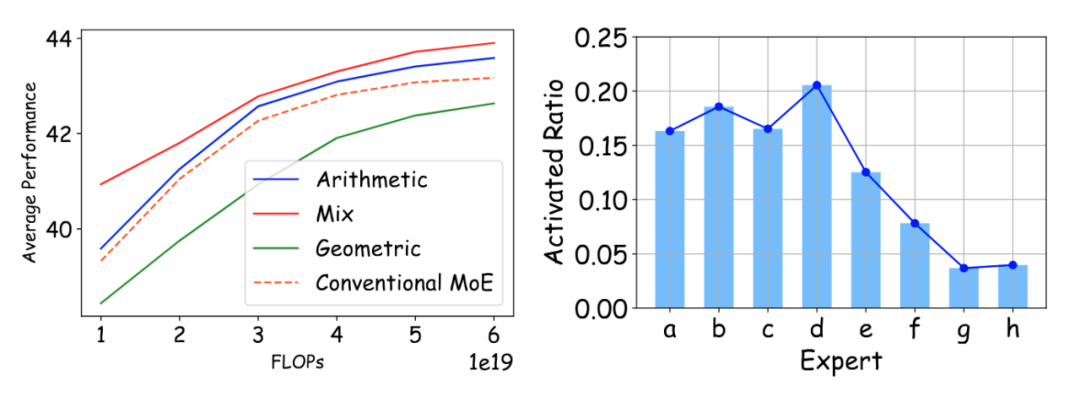 不同异构策略下模型效果比较
不同异构策略下模型效果比较
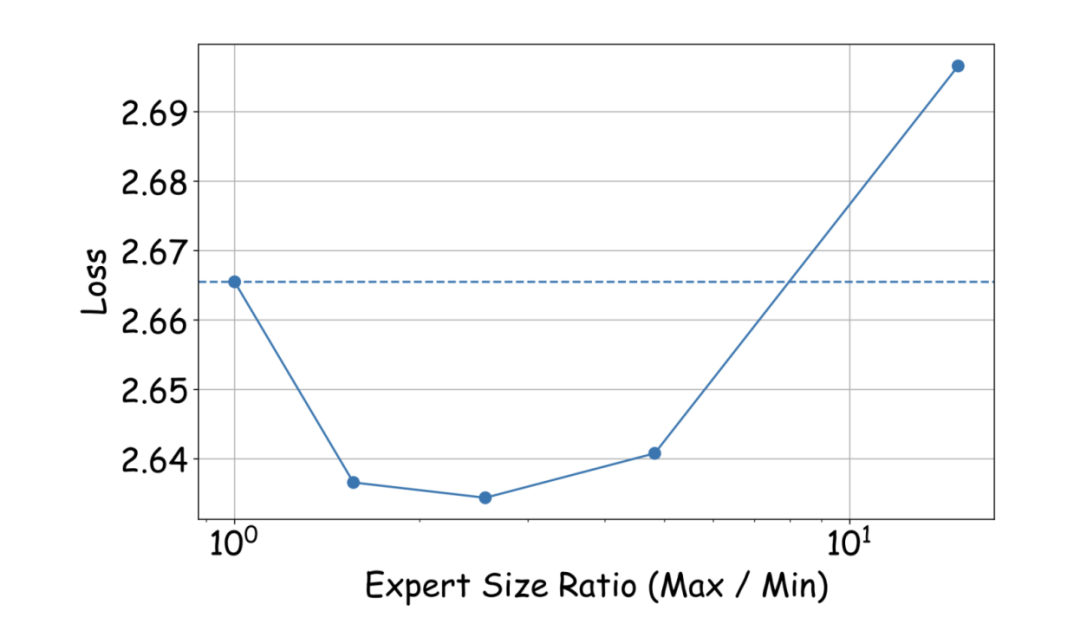
等差异构策略下“异构程度”对Loss的影响
在对异构expert的行为进行深入分析后,腾讯混元团队发现大小相近的专家相似度更高,小专家更频繁地参与其他专家的协同计算。这些发现揭示了小专家在通用语言理解能力上的优势,以及大专家在处理复杂token时的重要性。
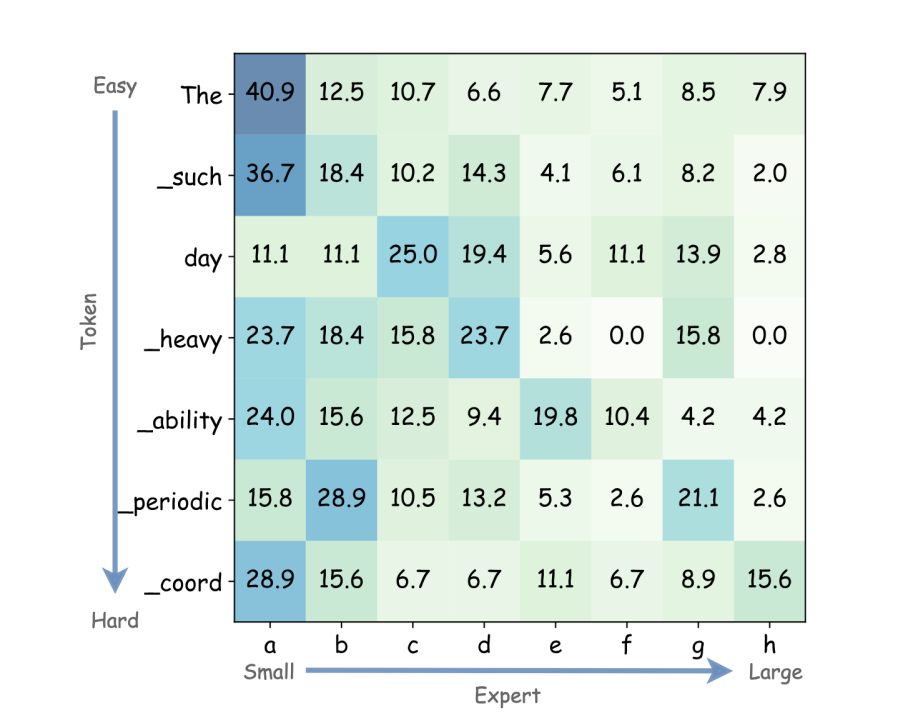
不同难易程度的词在不同大小专家上的激活百分比(a-h专家尺寸逐渐变大)
腾讯混元团队还对不同尺寸的专家进行了相似性分析和协同性分析。团队发现,尺寸相近的专家通常表现出更大的相似性。这表明它们倾向于发展出类似的能力,强调了异质性的重要性。另外,较小的专家比较大的专家参与合作更多,这表明HMoE中的小专家具有更广泛的通用语言理解能力。
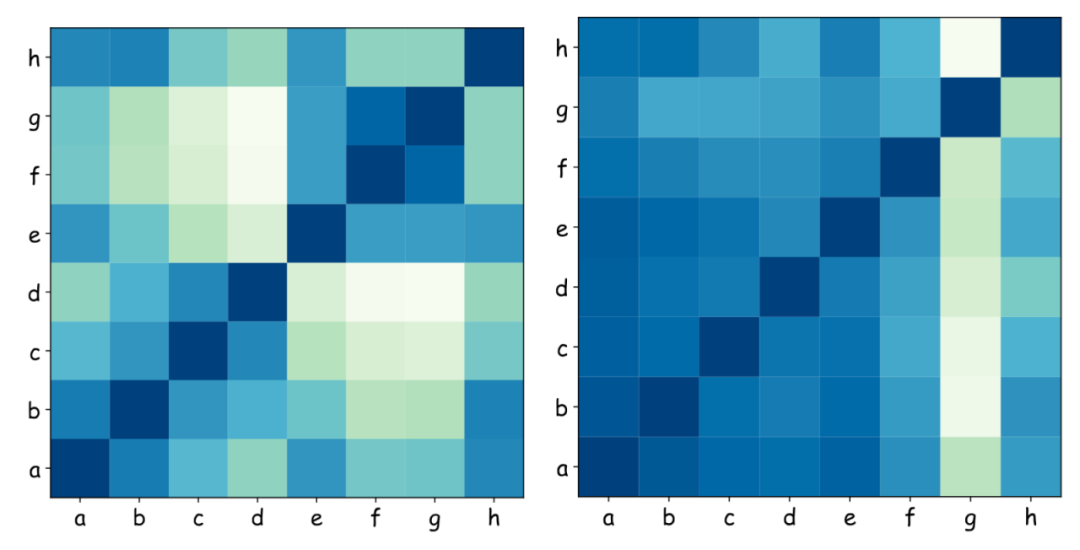
HMoE专家的相似性(左)和协同作用(右)分析,颜色越偏向蓝色相似性/协同作用越强(a-h专家尺寸逐渐变大)
混合异构专家的结构对训练框架层面也造成一些挑战。首先,专家模型形状不统一使传统的批量矩阵乘法方法失效。但是参考Megablocks的思路,可以使用块稀疏矩阵乘法,有效应对不同大小专家模型带来的复杂性。其次,异构专家模型导致计算和通信不平衡,资源利用效率低下。借鉴ES-MoE的方法,通过专家级卸载和动态专家放置,将专家参数卸载到CPU内存,并根据需要取回GPU,从而缓解负载不平衡问题。
混合异构专家模型(HMoE)的推出可以被视为MoE研究领域的一个新的里程碑。相较于传统MoE模型,HMoE在激活参数更少的情况下实现了更强的性能。它能够灵活理解和平衡分配不同难度的输入,在简单任务上实现高效计算,在困难任务上展现强大语言性能。
腾讯混元团队正在进行更大尺寸的HMoE的训练开发中,未来还会进行更深入的研究探索,比如:Infra侧同步的在训练和推理端的优化、对不同尺寸专家结合之前工作《腾讯混元、北大发现Scaling law「浪涌现象」,解决学习率调参难题 》结果采用不同的学习率和Scaling策略,对模型异构性进行进一步探索等。这些研究方向将会进一步提升HMoE的性能和应用潜力。腾讯混元团队的这一创新成果不仅展示了他们在推动人工智能技术进步方面的持续努力,也为未来大模型研究提供了新的方向。
更多信息查看原文:[2408.10681] HMoE: Heterogeneous Mixture of Experts for Language Modeling(https://arxiv.org/abs/2408.10681)
推荐阅读:
▶一周工作7天、加班到凌晨2点!英伟达五年股价飙升3776%,员工自曝:有钱挣没空花
▶“高强度”干活还不够,马斯克又出“新招”:写一页绩效自证价值,以获得股票!
▶传京东退租华南最大办公地;苹果罕见裁员,服务部门据传解雇百人;OpenAI接近以逾千亿美元估值进行新一轮融资 | 极客头条
▶生成式AI产品究竟怎么做?硅谷、百度、腾讯、WPS等40+大咖齐支招!



















 4582
4582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











