







本系列已完结,全部文章地址为:
1 VAE的基本原理
VAE(Variational AutoEncoder)变分自编码器是在AE的基础上发展而来的。整体网络结构、训练过程与AE很相似。VAE的网络结构如下图所示:
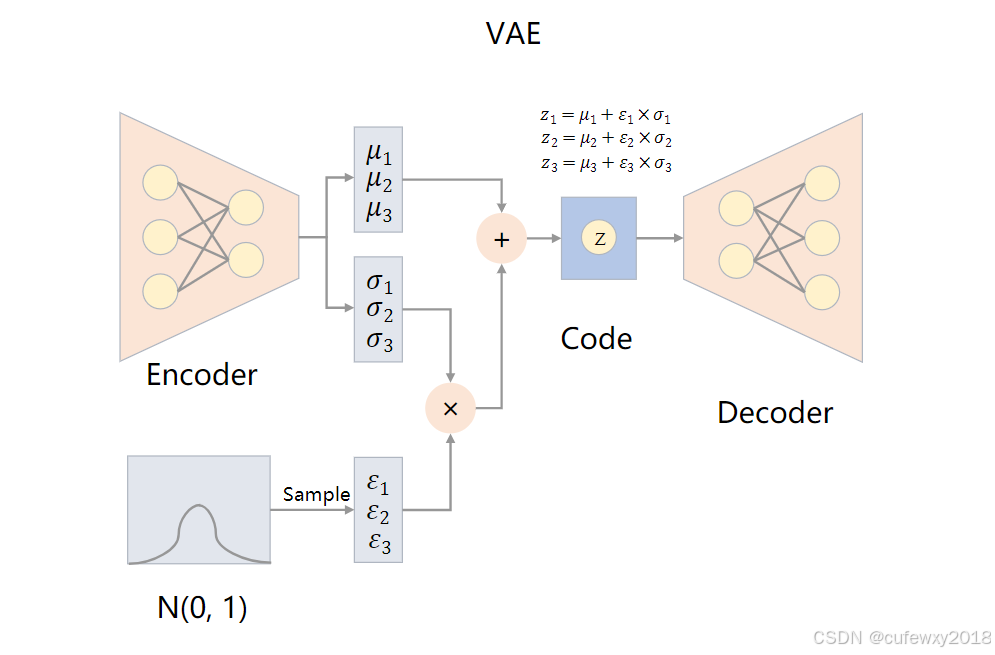
2 VAE的训练过程
2.1 正向计算
在Encoder中,将输出划分为2部分,一部分是均值,一部分是标准差。从标准正态分布N(0, 1)中抽样得到的变量乘标准差,加回均值,即可得到编码Z。将编码Z传入Decoder中,得到输出。损失函数除了输出与输入的差距以外(可用MSE损失函数或者交叉熵等),还要计算一项
为了最小化这一项,与0越接近越好,
与1越接近越好,因此这一项会要求Z的分布接近正态分布。
还可以理解成L2正则化,达到的效果是
不能有异常值,避免过拟合。
下一篇笔者将从数学推导角度说明,此时实际是正态分布与标准正态分布
的KL散度。
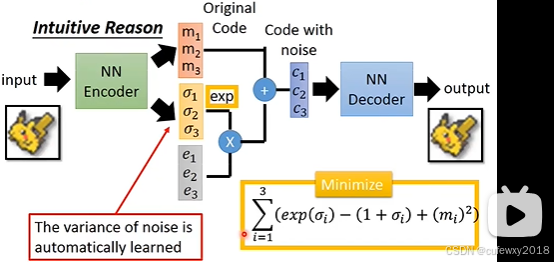
李宏毅老师课件中最小化表达式是
这是因为此处做了一些trick,Encoder的输出是均值和对数方差。这样右下角的最小化函数与前文是一致的。
由于一般
表示标准差,因此先将此处的
,相当于先学习到方差,再使用对数激活函数。取对数可以降低值的规模,也相当于一种激活函数,这样就不用自己加激活函数了。
实际的编码计算公式为
将
,与上文相比只有1/2系数差距,最小化时可忽略,因此是统一的。
2.2 重参数化
编码Z实际上相当于从均值为,标准差为
的正态分布中抽样得到,但在网络构建上不能直接用
和
抽样,因为“抽样”这一步计算不是可导的,因此引入了外部的标准正态分布,这样就可以计算误差对
和
的梯度了。
3 VAE的改进——直觉上的解释
VAE相对于AE做了很多改进,下面分别说明。
3.1 引入分布
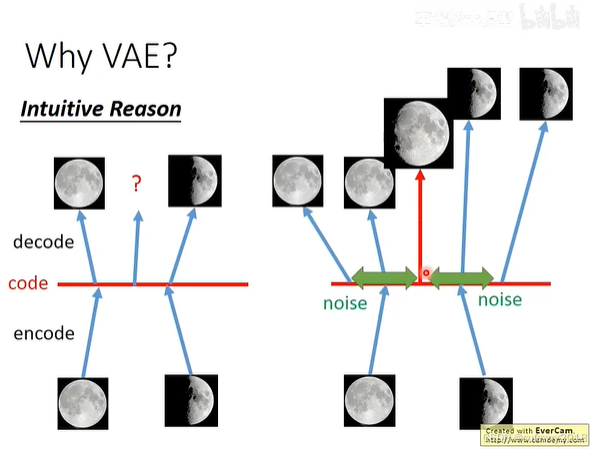
在AE中,编码是离散的点,由于模型主体是非线性的神经网络,拟合出的运算非常复杂,比如卷积、乘方、对数等等,因此不同编码之间是没有数量关系的。比如编码A对应图像X,编码C对应图像Z,那么将A和C之间的某个点B传入Decoder,并不能期望生成一个介于X和Z之间的图像。由于这个特性,AE不适合生成任务。
为了方便理解,以《潜伏》中余则成和翠平暗号为例,做以下分析:
(1)假设模型是线性的,比如事先约定编码1代表需要外部支援1人,编码3代表需要外部支援3人,那么某天余则成给翠平比手势“2”,翠平就知道需要支援2人。即使这个编码不是事先约定的,翠平也知道含义。
(2)现在模型是非线性的,比如事先约定编码1代表撤退,编码3代表带上武器,他们之间可能是毫无关联的。某天余则成给翠平比手势2,翠平就懵了,因为事先没有约定这个暗号。
如上图左侧所示,编码层左边的点生成满月图像,编码层右边的点生成弦月图像,编码层中间的点并不能生成中间月相的图像,可能是一个完全不相干的图像。
而VAE在编码层做了处理,用一个分布来表示编码,这样编码B在A的分布下概率较高,在C的概率下分布较高,那么生成的图像Y就兼具X和Z的特征。
还是以上文《潜伏》为例,在VAE下,余则成和翠平约定好,编码是一种分布,也就是说编码1只代表撤退概率大,编码2只代表带上武器的概率大。余则成只是给出大方向行动,允许翠平有主观能动性,相机决断。那么余则成给翠平比手势2,翠平认为2与1和3的距离都比较近,所以既要撤退,又要带上武器,因此翠平选择边带上武器边撤退。这样,他们就有一定的创造性,虽然不能发明新的暗号,但至少实现了现有暗号的组合。顺带一提,在GAN下,是可以创造新暗号的。
3.2 调整损失函数
AE的损失函数是计算输出与输入的区别,即重建的损失。在VAE下如果只考虑此损失,会导致VAE退化成AE,生成的将非常小,在均值处概率近似为100%,在其他处概率近似为0,也就相当于编码由一个分布退化成均值这单个点。
这是因为从正态分布抽样出的是有不确定性的,模型为了让重建损失更小,降低了不确定性的因素,所以导致分布的标准差极小。这样VAE就没意义了,因此损失函数必须还要考虑分布。
在损失函数中,增加了一项损失函数,前文已分析,最终的效果是分布要与标准正态分布尽可能相似,因此标准差不会近似为0。
4 VAE的问题及GAN的出现
以图像生成为例,VAE只能产生样本集中已有图像的组合,这有2个问题:第一,不能产生全新的图像,如下图所示产生的图片与样本有1个像素点的差距,左侧加在7的延长线上,相当于生成了全新的图像,右侧加在不相关的空白处,对于VAE来说二者代入损失函数是一样的,但是对于人类而言,显然左侧的图像损失函数应该要小,所以VAE无法生成新的图像;第二,在组合时,由于结果兼具样本集中多个图像的特征,所以清晰度不高。

由此学者提出了GAN模型解决此问题。
GAN中的Generator就相当于VAE中的Discriminator。更多关于GAN的详细内容可参考笔者关于GAN的学习笔记系列。
参考资料
李宏毅VAE课程

















 920
920

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









