







目录
1. torch.cat((self.label_emb(labels.long()), noise), -1) 函数理解
一、CGAN模型介绍
CGAN(Conditional Generative Adversarial Network)模型是一种 深度学习模型,属于生成对抗网络(GAN)的一种 变体。它的 基本思想是通过 训练生成器和判别器 两个网络,使生成器能够生成与给定条件 相匹配的 合成数据,而判别器则 负责区分真实数据和 生成数据。相比于GAN,它引入了条件信息(y),使得生成器可以生成与给定条件相匹配的合成数据,从而提高了生成数据的可控性和针对性。
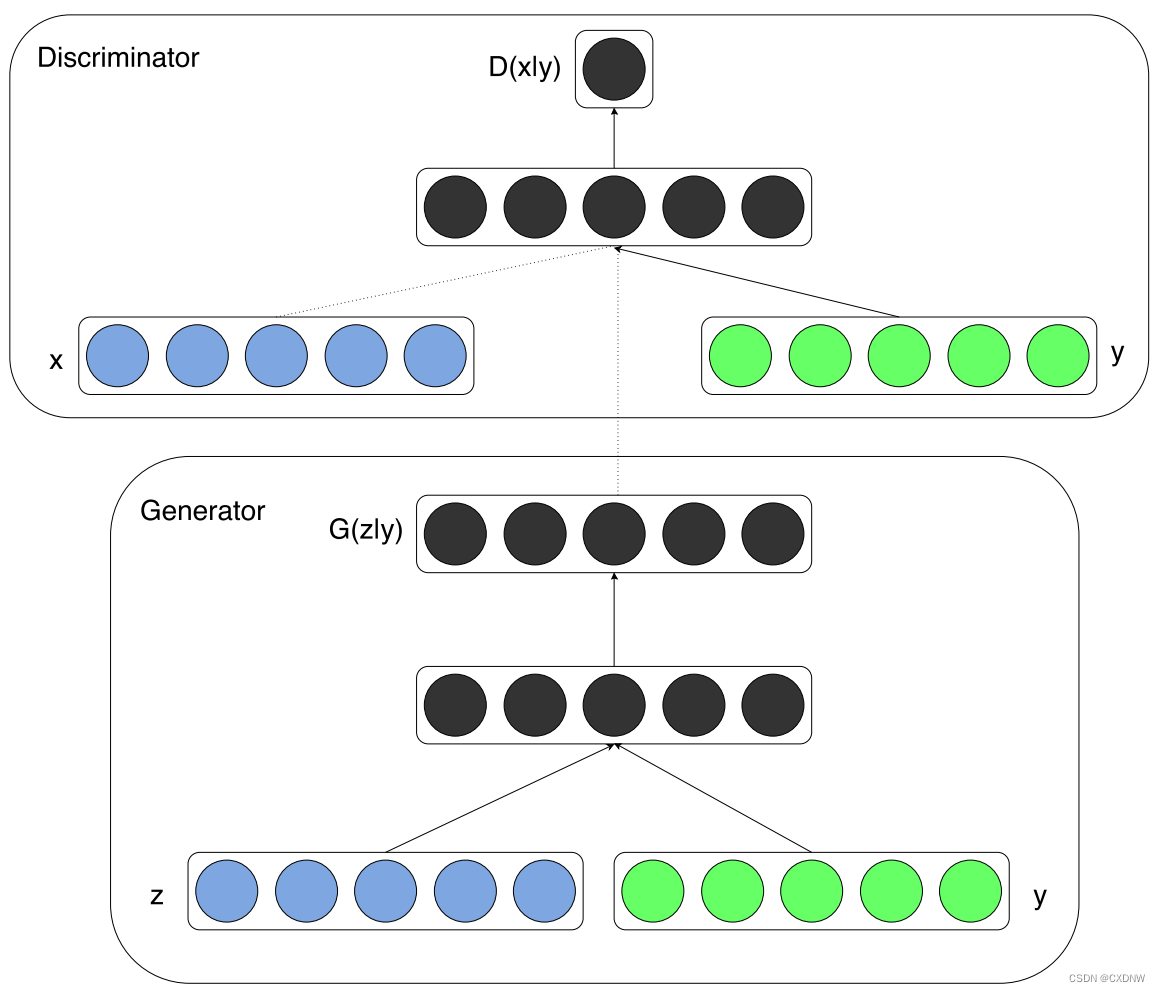
二、CGAN训练流程
1. 初始化
首先,初始化生成器和判别器的网络参数(本例未初始化)。
2. 数据准备
准备真实数据集和对应的条件信息。条件信息可以是类别标签、文本描述等。
# labels 即真事条件信息
for i, (imgs, labels) in enumerate(dataloader):
# gen_labels 即假条件信息
gen_labels = torch.randint(0, opt.n_classes, (batch_size,))3. 输出模型计算结果
(1)对于生成器:从随机噪声分布中采样噪声向量,并与条件信息一起输入到生成器中,生成合成数据。
gen_imgs = generator(z, gen_labels)(2)对于判别器:将真实数据 及其 条件信息 和 生成数据及 其条件信息分别输入到判别器中,得到真实数据 和 生成数据的 判别结果。
validity_fake = discriminator(gen_imgs.detach(), gen_labels)
validity_real = discriminator(imgs, labels)4. 计算损失
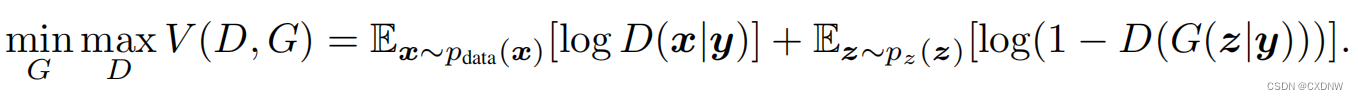
(1)生成器损失:鼓励判别器对生成样本及相应条件c的判断为“真实”,即最大化log(D(G(z|c), c))。
g_loss = adversarial_loss(validity, valid)(2)判别器损失:激励判别器正确区分真实样本(X, c)与生成样本(G(z|c), c)。
d_loss = (d_real_loss + d_fake_loss) / 25. 反向传播和优化
使用梯度下降算法或其他优化算法更新生成器和判别器的网络参数,以最小化各自的损失函数。
6. 迭代训练
重复步骤 3至 5,直到达到预设的训练轮数或满足其他停止条件。
三、CGAN实现
1. 模型结构
(1)生成器(Generator)

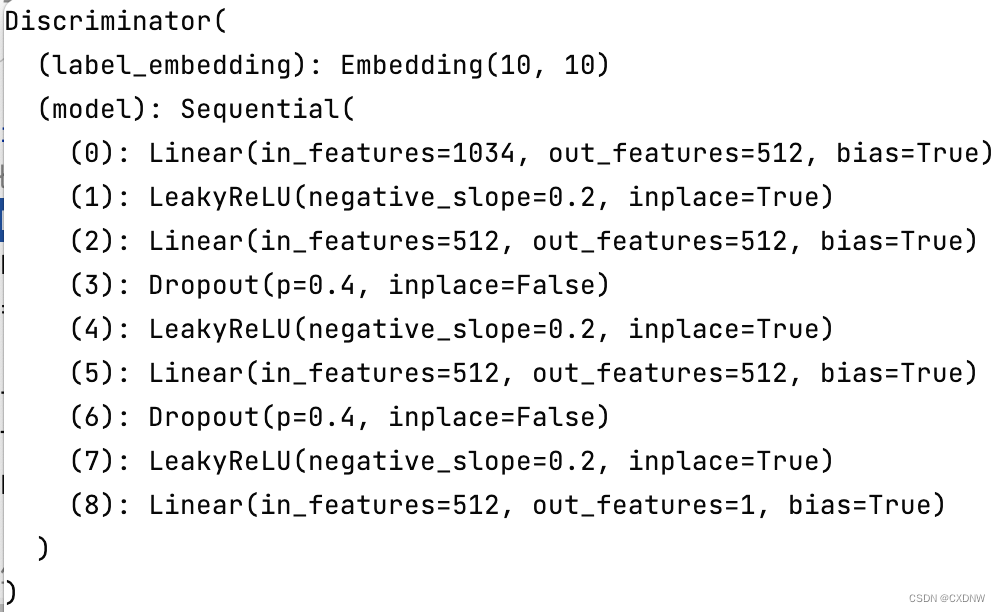
(2)判别器(Discriminator)
2. 代码
import torch
import torch.nn as nn
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
import matplotlib.pyplot as plt
import argparse
import numpy as np
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=50, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--n_classes", type=int, default=10, help="number of classes for dataset")
parser.add_argument("--img_size", type=int, default=32, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval between image sampling")
opt = parser.parse_args()
print(opt)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST(
"./others/",
train=False,
download=False,
transform=transforms.Compose(
[transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
),
batch_size=opt.batch_size,
shuffle=True,
)
img_shape = (opt.channels, opt.img_size, opt.img_size)
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.label_emb = nn.Embedding(opt.n_classes, opt.n_classes)
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(opt.latent_dim + opt.n_classes, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))), # np.prod 计算所有元素的乘积
nn.Tanh()
)
def forward(self, noise, labels):
# 噪声样本与标签的拼接,-1 表示最后一个维度
gen_input = torch.cat((self.label_emb(labels.long()), noise), -1)
img = self.model(gen_input)
img = img.view(img.size(0), *img_shape)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.label_embedding = nn.Embedding(opt.n_classes, opt.n_classes)
self.model = nn.Sequential(
nn.Linear(opt.n_classes + int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 512),
nn.Dropout(0.4), # 将输入单元的一部分(本例中为40%)设置为0,有助于 防止过拟合
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 512),
nn.Dropout(0.4),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 1),
)
def forward(self, img, labels):
d_in = torch.cat((img.view(img.size(0), -1), self.label_embedding(labels.long())), -1)
validity = self.model(d_in)
return validity
# 实例化模型
generator = Generator()
discriminator = Discriminator()
# 优化器
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
# 均方误差
adversarial_loss = torch.nn.MSELoss()
def sample_image(n_row, batches_done):
"""Saves a grid of generated digits ranging from 0 to n_classes"""
# Sample noise
z = torch.randn(n_row ** 2, opt.latent_dim)
# Get labels ranging from 0 to n_classes for n rows
labels = torch.Tensor(np.array([num for _ in range(n_row) for num in range(n_row)]))
gen_imgs = generator(z, labels)
save_image(gen_imgs.data, "./others/images/CGAN/%d.png" % batches_done, nrow=n_row, normalize=True)
def gen_img_plot(model, text_input, labels):
prediction = np.squeeze(model(text_input, labels).detach().cpu().numpy()[:16])
plt.figure(figsize=(4, 4))
for i in range(16):
plt.subplot(4, 4, i + 1)
plt.imshow((prediction[i] + 1) / 2)
plt.axis('off')
plt.show()
# ----------
# Training
# ----------
D_loss_ = [] # 记录训练过程中判别器的损失
G_loss_ = [] # 记录训练过程中生成器的损失
for epoch in range(opt.n_epochs):
# 初始化损失值
D_epoch_loss = 0
G_epoch_loss = 0
count = len(dataloader) # 返回批次数
for i, (imgs, labels) in enumerate(dataloader):
batch_size = imgs.shape[0]
valid = torch.ones(batch_size, 1)
fake = torch.zeros(batch_size, 1)
# 生成随机噪声 和 标签
z = torch.randn(batch_size, opt.latent_dim)
gen_labels = torch.randint(0, opt.n_classes, (batch_size,))
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
gen_imgs = generator(z, gen_labels)
validity_fake = discriminator(gen_imgs.detach(), gen_labels)
d_fake_loss = adversarial_loss(validity_fake, fake)
validity_real = discriminator(imgs, labels)
d_real_loss = adversarial_loss(validity_real, valid)
d_loss = (d_real_loss + d_fake_loss) / 2
d_loss.backward()
optimizer_D.step()
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
validity = discriminator(gen_imgs, gen_labels)
g_loss = adversarial_loss(validity, valid)
g_loss.backward()
optimizer_G.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item())
)
# batches_done = epoch * len(dataloader) + i
# if batches_done % opt.sample_interval == 0:
# sample_image(n_row=10, batches_done=batches_done)
with torch.no_grad():
D_epoch_loss += d_loss
G_epoch_loss += g_loss
# 求平均损失
with torch.no_grad():
D_epoch_loss /= count
G_epoch_loss /= count
D_loss_.append(D_epoch_loss.item())
G_loss_.append(G_epoch_loss.item())
text_input = torch.randn(opt.batch_size, opt.latent_dim)
text_labels = torch.randint(0, opt.n_classes, (opt.batch_size,))
gen_img_plot(generator, text_input, text_labels)
x = [epoch + 1 for epoch in range(opt.n_epochs)]
plt.figure()
plt.plot(x, G_loss_, 'r')
plt.plot(x, D_loss_, 'b')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['G_loss', 'D_loss'])
plt.show()
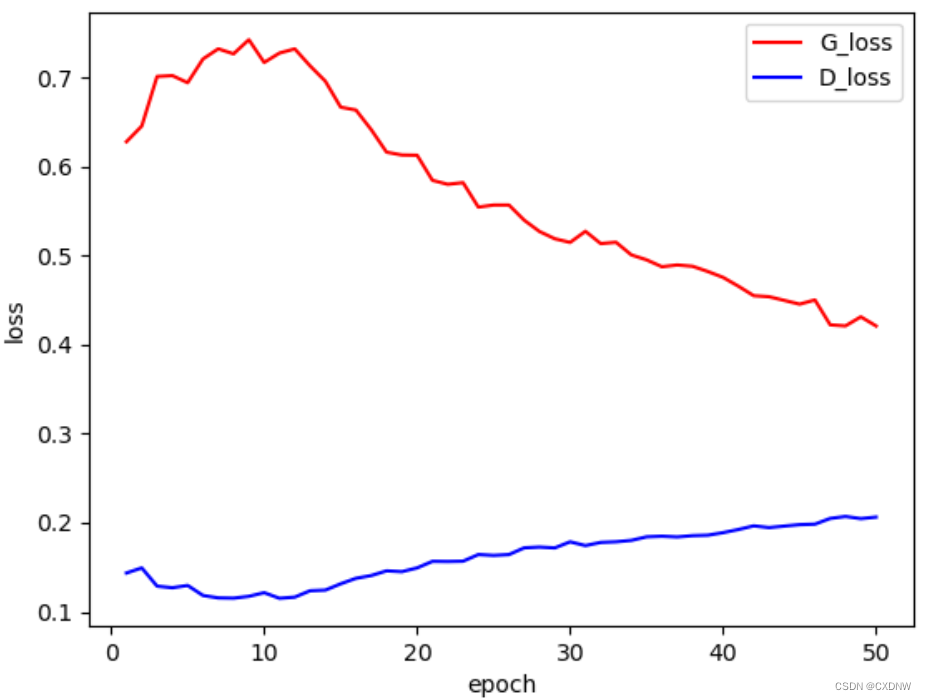
3. 训练结果

四、学习中产生的疑问,及文心一言回答
1. torch.cat((self.label_emb(labels.long()), noise), -1) 函数理解

2. Discriminator 模型疑问

后续更新 GAN 的其他模型结构。















 966
966

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









