






B站:AITIME论道(主页有各大顶会的预讲会以及研究者的专题报告会)B站链接:https://space.bilibili.com/503316308?spm_id_from=333.788.0.0
会议链接:https://www.bilibili.com/video/BV1Ut421T7Bf/?spm_id_from=333.337.search-card.all.click&vd_source=e2062c270d5c1a12c05b00541190be09


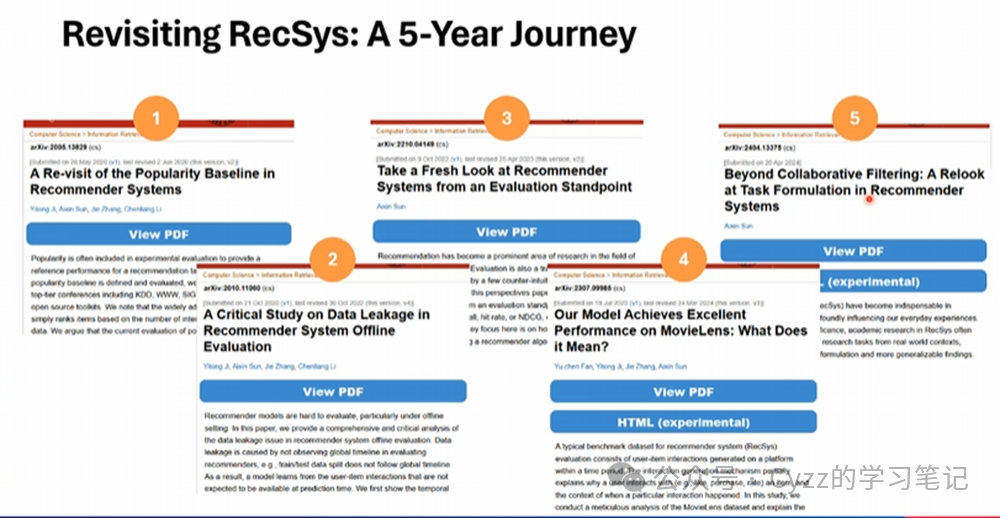
此次会议对推荐系统研究的进行了5年的回顾性研究,包括上图所提到的五篇论文。首先是流行度的定义问题到RS的数据泄露,并发现在RS中关于评价指标的问题,其次是关于数据集自身的问题,主要针对的就是Movielens(时间跨度大、用户长期偏好和bias),最后对推荐任务的理解(这篇文章会在本文后半段进行论文阅读讲解)
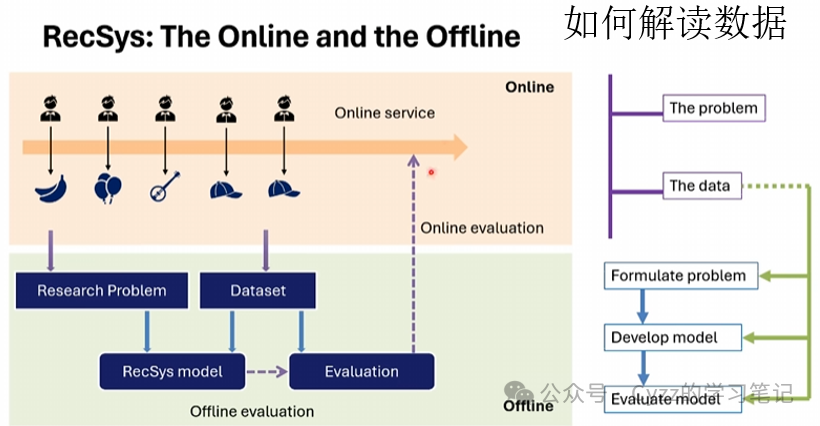
在RS中,在明确了推荐目标,得到用户的历史交互数据后,就可以搭模型进行评估了。但是在这过程中所有的部分都只涉及数据端,没有涉及到问题端。因此该如何去解读数据(包括数据中存在的大量的bias)
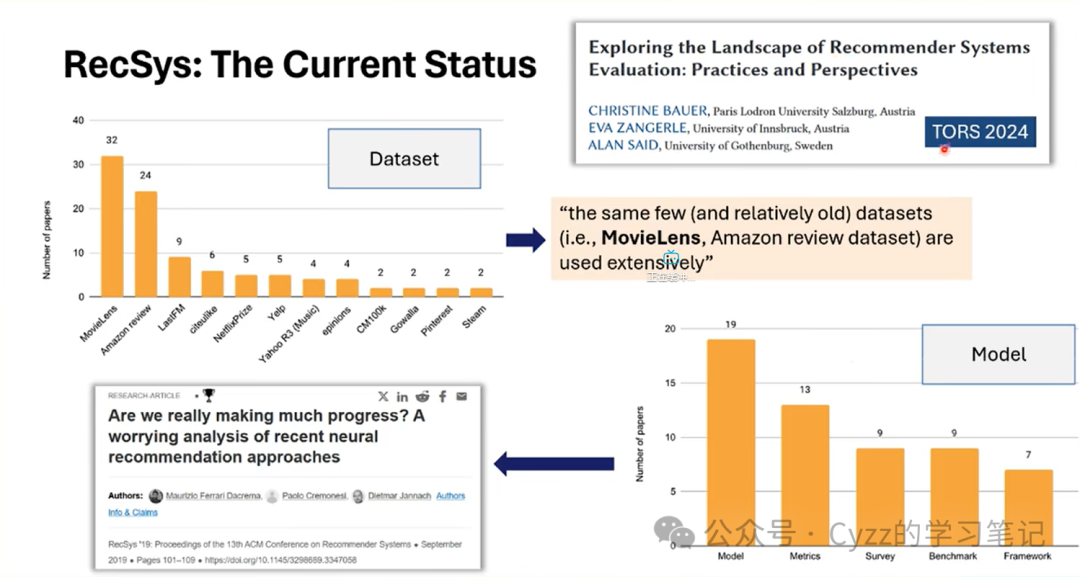
今年TORS的一篇论文中分析了在RS中,Movielens是最常用的数据集,大量使用的数据集普遍偏旧(Movielens具有十年的时间跨度),同时发表文章的贡献更多都是倾向于建立一个新的模型,其次就是推荐的多样性的bias,缺乏统一的评测标准。

同时,现有文章基线的选择是不一样的,没有一个通用的指标去选择相应的基线,此外,就算选择了基线后,也可以对基线进行调参,使得自己的模型性能显著优于所选择的基线。
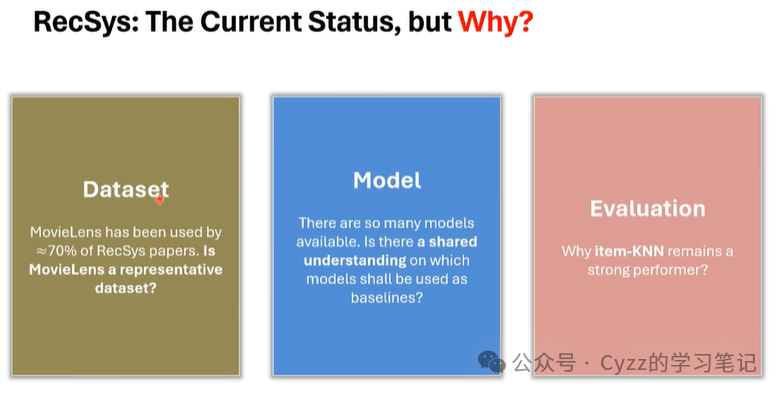
RS的现状:在数据集方面有固定常用的数据集,在模型方面如何选择一个适当的基线以及在评估方面,为什么item-KNN这个方法相较于其他方法要好。
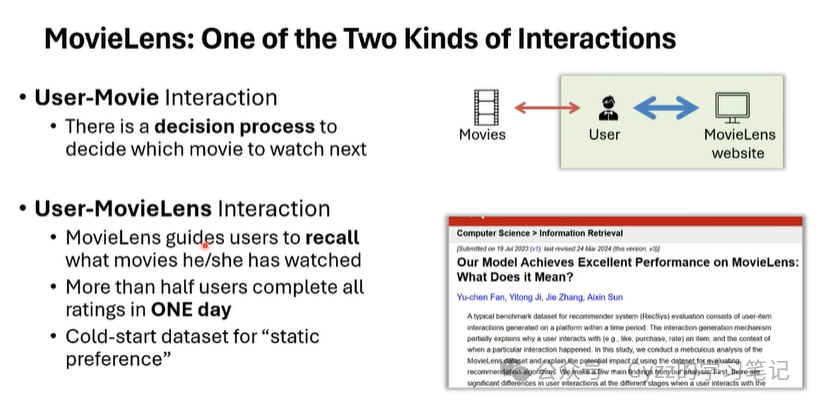
在数据部分,由于Movielens的数据采集方式是首先给用户一堆备选电影,通过用户选择后使用基于项目的协同过滤方法为用户推荐相似的电影。一方面是信息茧房,另一方面忽略了用户的一个动态的决策过程(用户需要回忆之前看过的电影并在一天内打出评分)
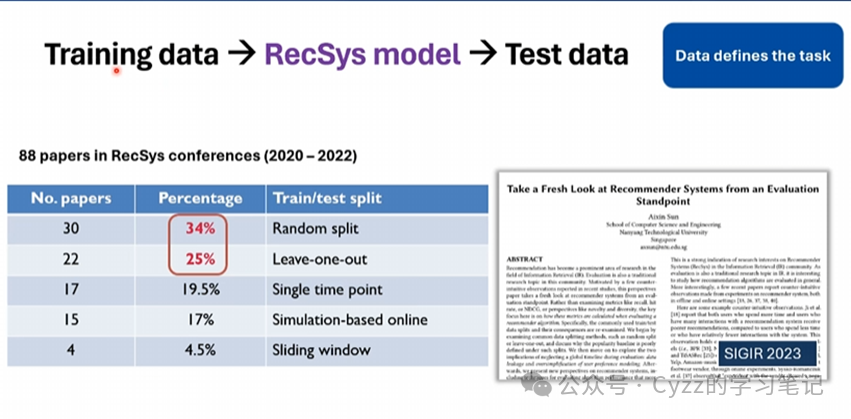
在模型部分,现有模型大多使用随机划分或留一法来划分训练集和测试集

然而通过随机划分或留一法来划分训练集和测试集,会使得在计算项目流行度的时候产生流行度偏差(划分原因+时间原因)

因此孙老师在这里做了个实验,针对时间跨度为10年的数据集,将第五年的数据作为样本,并且将前五年的数据作为训练集,采用留一法将第五年最后的数据作为测试集,并依次加入后续每一年的数据作为训练集。
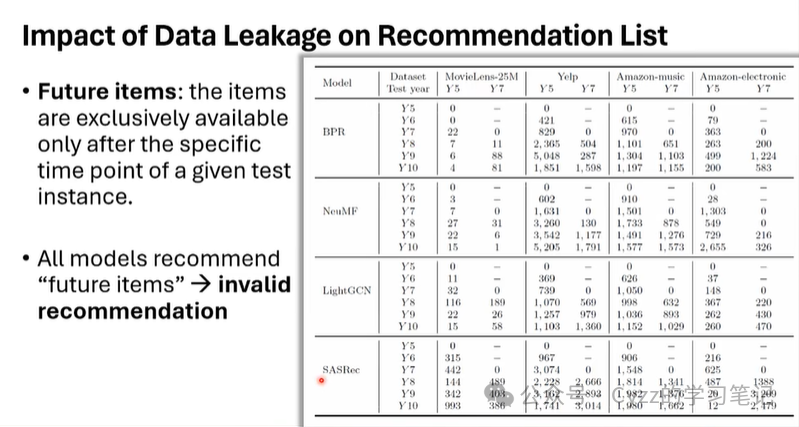
从表可以看出,使用这种数据集划分方法在四大基线模型上的性能都得到了提升,特别是纳用了未来五年中每一年的数据都得到了提升,这说明在以往的工作中,忽略了用户的动态决策过程(即用户的动态偏好,现有一些工作有类似观点,例如在序列推荐中针对用户的交互序列长度对其进行划分,从而捕获用户的长期偏好和短期偏好)
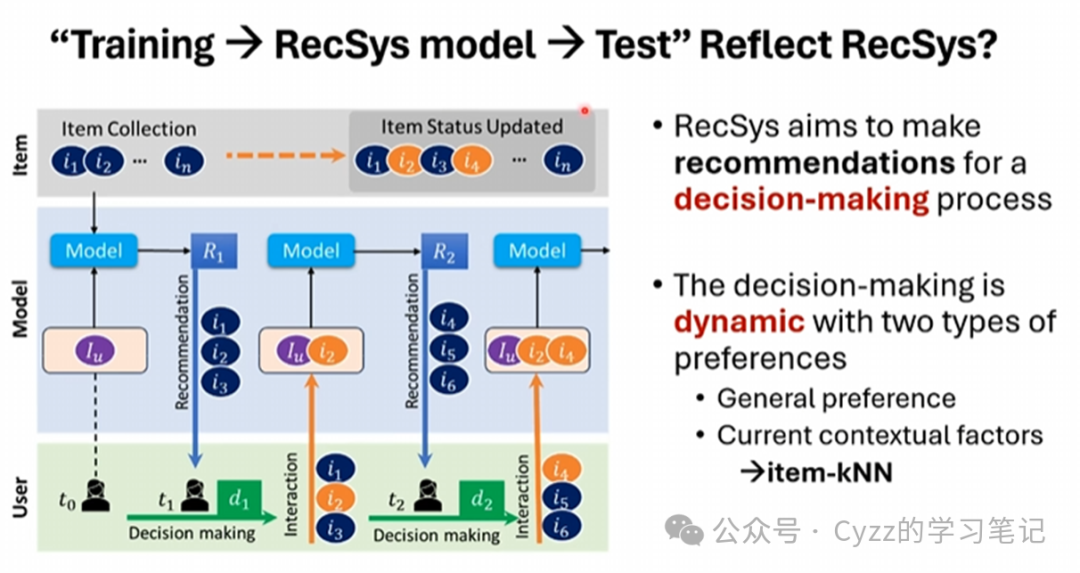
上图模拟了一个RS的流程,在推荐的开始模型拥有用户的历史交互行为Iu(冷启动的话可以像Movielens一样在一开始先选几个感兴趣的电影),通过分析现有项目的流行程度向用户推荐了项目I1、I2、I3,用户通过在T1时刻进行决策选择了项目I2,那么模型基于项目I2寻找与其相似的项目I4、I5、I6,用户通过在T2时刻进行决策选择了项目I4,那么现有用户感兴趣的项目就有Iu、I2、I4,下一步模型将会在Iu、I2、I4中寻找类似的项目进行推荐。因此推荐系统真正需要模拟的是用户的决策过程,其中包含了用户的一般偏好和当前的偏好(这也就是为什么Item-KNN相较于其他模型的性能最好,因为都是基于当前的偏好进行推荐)

同时还举例了不同推荐任务有着不同的特性,例如电商推荐和外卖推荐,相较于电商推荐,外卖推荐还需要考虑位置远近等其他因素。因此推荐系统在特定应用场景中,需要结合应用场景特定的知识。
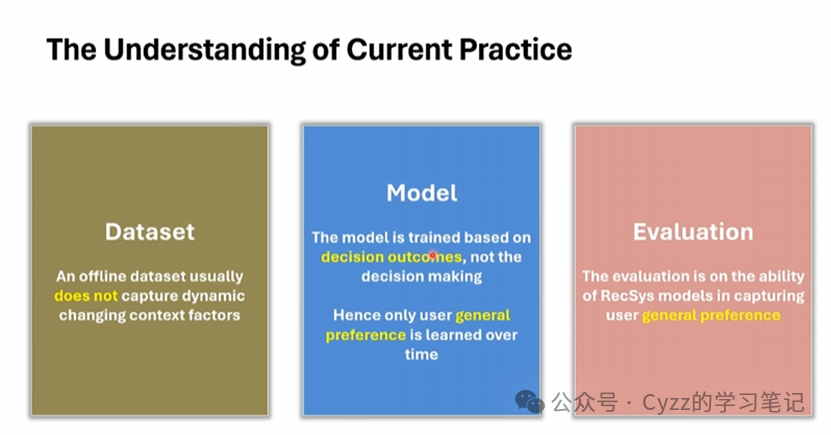
那么当前的的问题就是,首先一个离线的数据集不能捕获用户的动态偏好,其次模型基于用户的历史交互(存在偏差),不能有效学习到用户的决策过程。即过分强调决策结果的建模,而不是决策过程。
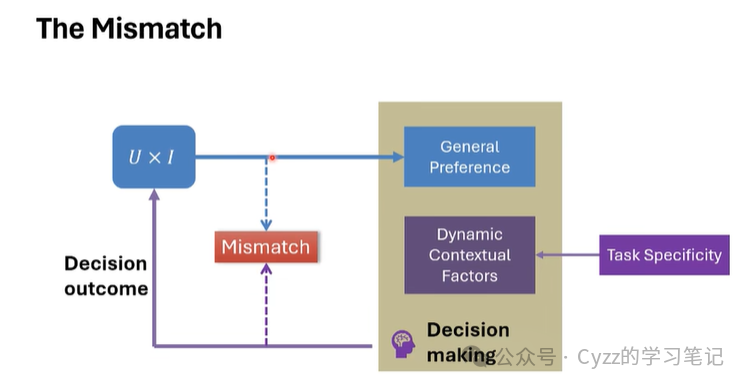
用户真正做决策的过程不仅仅包含用户的一般偏好,还拥有着特定于任务场景的动态因素(例如在电商平台随时间做出的多行为序列交互以及在外卖平台中用的送餐时间、配送地址、历史订单等不同的信息),现有基于用户交互数据做出的推荐大多都是捕获用户的一般偏好,但一般偏好与动态因素(偏好)并不匹配。

那么用户的交互(偏好)受多重因素所影响,例如长短期偏好以及不同推荐任务所特有的因素,例如基于数据划分的多行为推荐、序列推荐、跨域推荐等,基于场景划分的电商推荐、电影推荐、广告推荐等,共同导致了不同的模型或方法在不同的数据集上产生了很大的差别。同时用户的一般偏好可以通过协同过滤方法很好地被捕获,但忽略了时间维度,这也就导致了模型在线上的时候性能不佳。
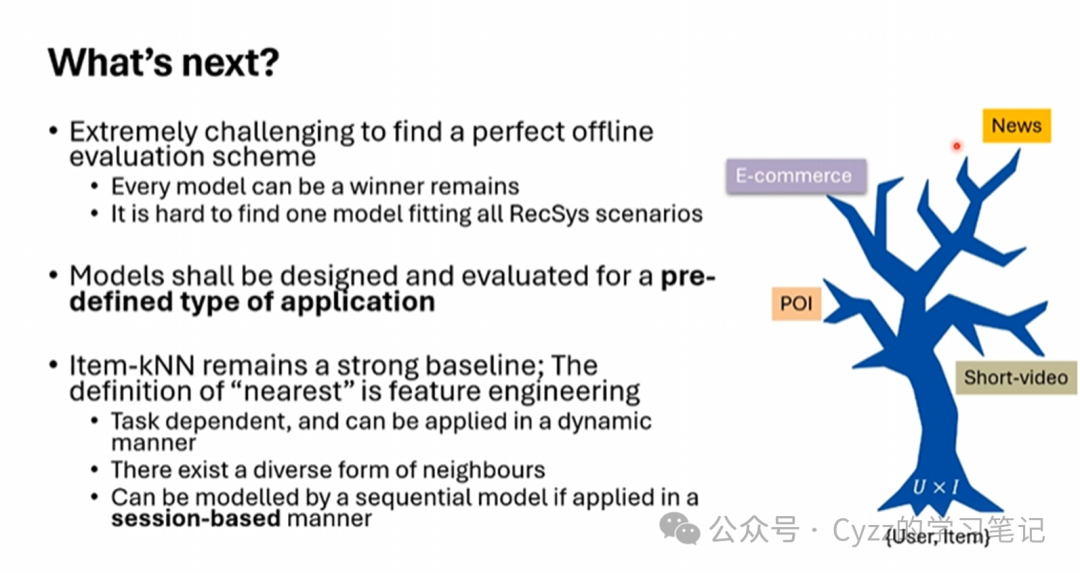
很难找到一个模型在所有推荐场景中的性能都很好,那么可以基于用户当前感兴趣的项目进行推荐。

下面就是之前提到孙老师在今年撰写的论文,论文的大概内容和讲座的内容一致。

Motivation:
-
当前推荐系统研究主要集中在捕获用户的一般偏好,而忽略了用户决策过程中的动态环境因素。
-
当前推荐系统研究中,缺乏统一的基线模型和评估方法,导致不同研究之间的可比性较差。同时很多研究采用的离线评价方法存在数据泄漏问题,从而导致评价结果不准确
-
推荐系统任务的定义与实际具体的应用场景脱节,未能充分考虑特定应用场景下的外部信息和动态情境因素。
Contribution:
-
基于应用场景和领域特定数据来定义研究任务,并考虑用户决策过程中的动态情境因素,如时间、地点、用户当前的兴趣和需求等,通过结合领域特定的外部信息(知识图谱、多模态信息)和上下文信息,来设计更加有效的推荐系统模型。
-
采用更严格的离线评价方法,避免数据泄漏问题,例如采用全局时间线分割数据集进行训练和测试(之前提到以第五年的数据为样本)
-
通过动态更新模型输入,进而反映用户的当前兴趣和需求。强调推荐系统应在动态环境中运作,而不仅仅是捕获用户的一般偏好。(现有研究有相似的想法,例如动态超图,增量学习)
同时,孙老师在第三章探讨了推荐系统任务定义的三个关键维度,即用户、模型和物品,并强调了推荐系统应在动态环境中进行推荐,以下图为例。
用户
-
用户在与推荐系统交互的过程中,通常会受到多种情境因素的影响。具体来说,用户的每一次交互都发生在特定的时间点,是用户决策过程的结果。
-
用户决策过程可能会考虑多种因素,如推荐物品的属性、用户当前的位置、时间、正在进行的活动,甚至是用户的情绪。例如,用户在 YouTube 上观看的视频类型可能会因为他们是感到快乐还是悲伤而有所不同。
模型
-
模型的主要任务是根据用户的历史交互记录生成推荐。典型的推荐任务被视为在不完整的用户-物品交互矩阵中预测缺失值(建模用户的一般偏好)。
-
模型输入通常包括用户的历史交互记录,模型的输出依赖于这些输入来生成推荐结果。对于每一轮推荐,模型的输入都会根据最新的用户交互记录进行更新,从而生成更加准确的推荐。
物品
-
每次用户与推荐系统中的物品交互,都会影响物品的属性。例如,某个视频的观看次数会因为新用户的观看而增加,进而影响该视频的受欢迎程度。
-
随着时间的推移,物品的属性会动态变化,推荐系统需要实时更新这些信息,以提供准确的推荐。
此外还强调了数据集的问题:
-
学术研究中常用的数据集(如MovieLens和Amazon评论数据集)通常记录的是用户-物品交互的结果(离线),而不是用户决策过程中的情境因素(实时)。这些数据集不能很好地模拟现实中的用户行为和偏好。此外,在其他论文中也提到:推荐系统的数据通常是观察性而非实验性,其中用户的交互数据不仅受到推荐系统的曝光策略的影响,还与用户的个性化偏好密切相关,同时项目在数据中的呈现不均匀,存在长尾效应。例如某些项目的流行度较高,从而获得更多的用户交互,导致推荐系统在数据中、模型中以及推荐结果中发生了偏差,随着模型的在线更新,已有的偏差会加剧推荐结果中的偏差 (数据偏差→数据不平衡→结果偏差);而有偏差的推荐反过来会影响用户的决策选择,从而强化用户未来行为中的偏差(结果偏差→数据偏差)。
-
数据集的使用方式也存在问题,特别是在模型的训练和测试过程中,通常没有考虑全局时间,这可能导致数据泄漏问题。
-
现有的数据集往往不能捕捉用户决策过程中的关键输入,导致模型在实际应用中的表现与离线评价结果存在显著差异。因此该关注更符合实际应用环境的数据集和评价方法,以提高模型在现实场景中的表现。
总结
-
推荐系统任务的应用特定性:推荐系统的任务定义应当考虑具体应用场景,并关注应用特定的推荐任务。而不是依赖于通用和简化的设置,尤其是最近越来越火的LLM。
-
推荐系统的动态性:推荐系统是动态的,不仅要学习用户的总体偏好,还需要捕捉决策过程中的动态因素。当前的协同过滤方法虽然有效,但未能充分考虑用户决策的动态过程。平衡这两个方面将有助于将推荐系统任务重新定义为一个排序问题。
-
数据集的重要性:高质量的数据集对于推荐系统研究至关重要。应开发包含决策场景信息的丰富数据集,以更好地模拟实际应用场景。
-
未来展望:未来的研究应重点开发高质量的数据集,并明确推荐任务的定义,以促进更有效的模型设计和评价。并更好地理解推荐系统任务的复杂性和动态性。
-
最后,很长一段时间没有更新内容了,在忙申博的事,现在有时间啦,并且我开始在微信公众号发表一些内容了,感兴趣的各位还请关注我的公众号
-


















 1662
1662

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









