






01
背景
当前常见的 LLM 推理框架通常是在单模型、同构硬件资源、均匀流量分布和有限序列长度等条件下优化其 Serving 能力。在这种情况下,各种分布式并行方案、量化压缩、算子优化、PagedAttention、Continuous Batching 等等技术可以充分发挥作用,提升服务吞吐量。然而,真实场景往往更加复杂,通常会包括以下几种情况:
-
多种 LLM 模型:不同的大小的模型,比如,常见的 7B、13B、70B 甚至上百 B 模型;或者同等大小但应用于不同垂类场景的模型。
-
异构硬件环境:不同的 GPU 类型,推理 GPU 可能包含 T4、L4、A30、4090 等,训练 GPU 可能包含 V100、A100、A800、H100、H800 等;网络拓扑也会不同,比如,训练 GPU 很可能机内会有 NVLink + NVSwitch 互联,机间会有 IB 网络高速互联;而推理 GPU 机内可能只能通过 PCIe,机间也只是低速网络。
-
并行编排方案:推理中常用 Tensor Parallel 和 Pipeline Parallel 并行方案,TP 数量和 PP 数量对模型性能也有重要影响。
-
复杂的流量分布:不同模型的 QPS 可能不同,且不均匀;不同 Query 的输入、输出 Token 数也很可能不同,比如,常见场景请求的序列长度通常在 8K 以内,而有些模型和场景支持百万 Token 的处理。
-
不同的 SLO 要求:Online 服务和 Offline 服务对时延的要求差异显著,即使同类的 Online 服务也有不同要求。
为了获得整体最优的推理性能,通常需要构建一个庞大的推理系统,将上述条件视作约束条件,近似为一个复杂的整数线性规划(Integer Linear Programming,ILP)问题,其复杂度通常是指数级的。因此,当前出现了很多 LLM 推理系统,但这些系统都在某些方面进行了约束,实际上是求解一个简化的 ILP 问题。
本文我们将简单介绍几种常见的 LLM 推理系统,它们分别关注了不同的约束条件:
-
AlpaServe:针对多个 LLM 模型,同构 GPU 集群,并行编排方案,简化的流量分布进行优化。
-
多 LoRA(Punica 和 S-LoRA):同构 GPU 集群,多个 LLM 模型,但是每个流量都较小,可以共享基座模型。
-
Splitwise:针对异构 GPU 集群(高算力和高带宽两种),单一 LLM 模型,Prefill 和 Decoding 分离计算进行优化。
-
Infinite-LLM:同构 GPU 集群,单一 LLM 模型,复杂流量分布,分布式 KV Cache 优化。
-
Mélange:异构 GPU 集群,不同模型采用不同方案,没有混合调度。复杂流量分布,不同 SLO 要求。(单一请求只使用同一种 GPU)
-
MuxServe:同构 GPU 集群,不同 LLM 模型混合调度。并行编排优化,采用 MPS 切分算力单元,处理复杂 QPS 流量。
-
Helix:复杂异构 GPU 集群,单一 LLM 模型,复杂并行编排方案。(单一请求可能使用不同 GPU)
我们在之前的文章中已经总结过各种 LLM 推理相关技术,也包含一系列背景知识,这里不再赘述,具体可以参考:
-
全面解析 LLM 推理优化:技术、应用与挑战
-
万字综述 10+ 种 LLM 投机采样推理加速方案
-
揭秘 LLM 推理:全面解析 LLM 推理性能的关键因素
-
LLM 推理常见参数解析
-
LLM 推理性能优化最佳实践
-
MiniCache 和 PyramidInfer 等 6 种优化 LLM KV Cache 的最新工作
-
阿里 Infinite-LLM:超长上下文的高效 LLM 推理系统
02
AlpaServe
2.1 摘要
在 [2302.11665] AlpaServe: Statistical Multiplexing with Model Parallelism for Deep Learning Serving 中,作者证明了当为多个模型提供服务时,即使单个模型可以放置在单个设备上,模型并行性也可以额外用于多个设备的统计多路复用。文中作者也探索了模型并行性引入的开销与利用统计多路复用来减少存在突发工作负载时的服务延迟之间的权衡。作者探索了新的权衡空间,并提出了新的服务系统 AlpaServe,其确定了一种有效的策略,用于在分布式集群中排布和并行化大规模深度学习模型的集合。
评估结果表明,AlpaServe 能处理高达 10x 速率的请求或 6x 速率的突发性请求,同时超过 99% 的请求都可以保持时延约束。
2.2 方法
想要有效地利用模型并行性进行深度学习模型 Serving 存在几个关键挑战:
-
确定高效的模型并行策略,减少模型并行的开销。具体来说,找到一种分布式排布策略,以最大程度地减少各种并行 Stage 的不均衡。
-
根据请求分布模式确定模型排布位置,以最大限度地保证 SLO。
作者提出了 AlpaServe 专门来应对这些挑战。其架构图如下所示,AlpaServe 利用集中式 Controller 将请求分派给不同的 Group。每个 Group 在共享的 Model Parallel Runtime 上托管多个模型副本。
自动并行策略:由于不同的并行化配置具有不同的时延和吞吐量,作者为每个模型枚举了多个可能的配置,让排布算法为整个集群中的所有模型选择最佳组合。因此,作者在现有的自动并行化训练系统 Alpa([2201.12023] Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning) 上构建了几个扩展,使其适合生成针对 Serving 的并行化策略。给定一个模型,AlpaServe 首先执行具有各种约束的并行化编译器,以生成可能的配置列表。
排布算法:给定一组模型和一个固定集群,AlpaServe 将集群划分为几组设备。每组设备选择要使用的共享模型配置的模型子集,不同组可以保持副本相同的模型,比如 Group 1 包含模型 a/b/c,Group 2 包含模型 a/d/e。针对每个模型的请求都会被调度到对应的组,比如针对模型 a 的请求会被调度到 Group 1 和 Group 2。作者将特定集群组分区、模型选择和并行配置称为排布(Placement)。目标是找到一个能最大限度提高 SLO 的排布,然而,这是一个困难的组合优化问题。整个优化空间会随着设备数量、型号种类的增加呈指数级增长。为此,作者设计了一个两级排布算法:给定一个集群 Group 分区和每个 Group 的共享模型并行配置,算法 1 使用模拟器引导的贪婪算法来决定为每个组选择哪些模型;然后,算法 2 枚举各种潜在的集群分区和并行配置,并比较算法 1 的 SLO 实现情况,以确定最佳排布。

03
多 LoRA
3.1 Punica
在 [2310.18547] Punica: Multi-Tenant LoRA Serving 中,作者设计了一个多租户系统,该系统管理一个 GPU 集群,以使用共享的预训练基座模型为多个 LoRA 模型提供服务,最多获得了 12 倍的吞吐提升。
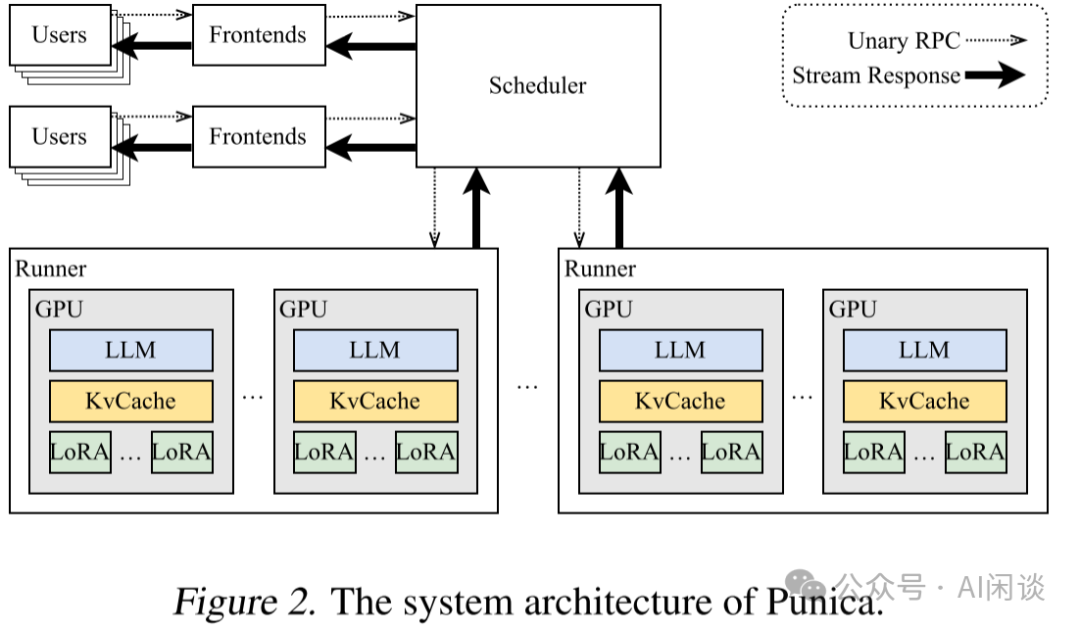
如下图 Figure 2 所示为 Punica 的系统架构,与其他模型服务相比:
-
Punica 具有前端服务(Frontends),可面向用户提供 RESTful API,并将用户的请求转发给 Punica 调度器(Scheduler)。用户的请求包含 LoRA 模型的标识符和提示(prompt)。
-
Scheduler 将请求分发给 GPU。
-
每个 GPU 都会启动一个 Runner,该 Runner 与 Scheduler 通信并控制所有 GPU 的执行。
-
当 GPU 生成新 Token 时,新 Token 会由 Runner 以 Streaming 方式传输给 Scheduler,再通过 Frontends 返回给用户。
3.2 S-LoRA
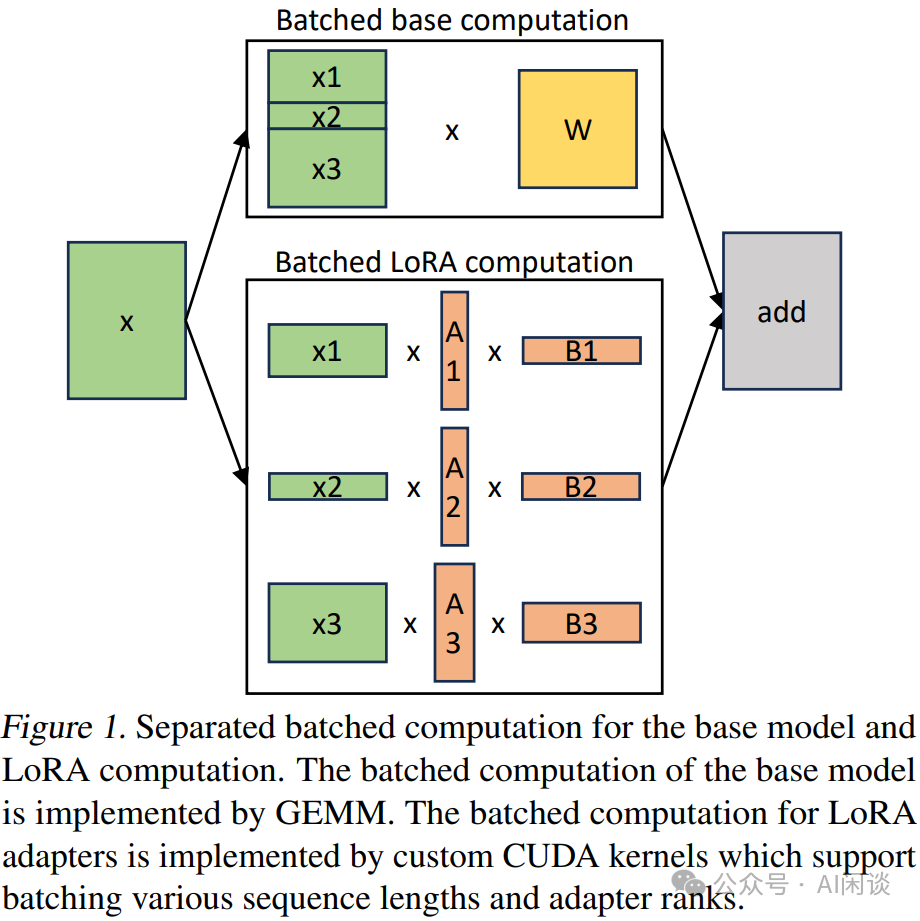
在 [2311.03285] S-LoRA: Serving Thousands of Concurrent LoRA Adapters 中,作者发现,在传统的方案下,如果有多个 LoRA Adapter,就需要合并成多个模型副本,这也就丧失了不同请求间 batching 的机会(例如 query1 需要调用 lora1,query2 需要调用 lora2,query3 需要调用 lora3,那么,如果单独合并的话,query1,query2,query3 就要分别调用独立的模型 model1,model2 和 model3。然而,如果不合并的话,三个 query 在基座模型上的计算就可以 batching 处理)。最终可以支持上千个 LoRA 模型,获得 4 倍以上吞吐提升。
作者对于基座模型使用 batching 计算,然后使用自定义的 CUDA Kernel 为所有的 LoRA Adapter 执行额外的 xAB 计算,过程如下图 Figure 1 所示:
3.3 Lorax
GitHub - predibase/lorax: Multi-LoRA inference server that scales to 1000s of fine-tuned LLMs 是一个基于 Huggingface TGI 推理框架和 Punica 的多租户 LoRA 系统,其支持动态的 LoRA 模型加载,以及针对 LoRA 的 Continuous Batching 策略,并集成了各种高性能 CUDA Kernel,比如 FlashAttention、PagedAttention 等。
04
SpotServe
4.1 摘要
在 [2311.15566] SpotServe: Serving Generative Large Language Models on Preemptible Instances 中作者基于不同云平台的廉价抢占式实例实现了快速、可靠的 LLM 推理服务。
-
独占实例:用户可以独享物理服务器上的虚拟机资源,不会受到其他用户的影响,确保了高稳定性和高可用性。由于资源独享,因此相应价格会比较高。
-
抢占式实例:通常是运营商在有闲置资源时提供,且在需要时可随时终止这些实例,释放资源给其他更高优先级的任务。由于利用的是闲置资源,价格通常比独占实例便宜很多,但是可靠性和稳定性相对也更低。
-
宽限期:在抢占式实例被终止之前通常会有一个宽限期,提供一段时间让用户进行处理和调整,以避免立即终止对业务造成的影响。
SpotServe 中通过几个关键技术来保证其能提供可靠的 LLM 推理服务:
-
首先,动态的调整 LLM 并行化配置,以适应波动的工作负载以及动态伸缩的实例,同时在整体吞吐量、推理延迟和推理成本之间取得平衡。
-
其次,为了最大限度降低动态迁移实例的成本,将迁移实例的任务表述为二分图匹配问题,使用 KuhnMunkres 算法来确定最小化通信成本的最佳迁移方案。
-
最后,利用云平台的宽限期,作者引入了推理状态恢复机制,以更细粒度(Token 级,而不是 Query 级)的方式管理推理进度,允许 SpotServe 在抢占时以低成本恢复推理任务。
作者在真实的抢占式实例场景中基于各种常见 LLM 评估了 SpotServe 的能力。结果表明,与现有的最佳 LLM 服务系统相比,SpotServe 可以将 P99 长尾时延降低 2.4x-9.1x。此外,还可以利用抢占式实例的价格优势,节约 54% 的成本。
4.2 方法
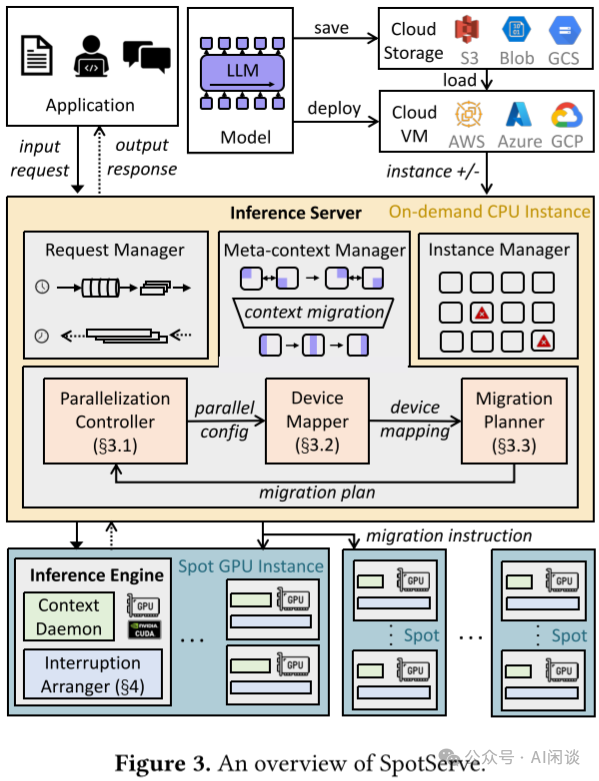
如下图 Figure 3 所示为 SpotServe 的架构概览。SpotServe 的 Inference Server(管理服务) 部署在独占 CPU 实例上,Inference Engine(执行 LLM 推理任务) 部署在抢占式 GPU 实例上。其中的关键组件包括:
-
Request Manager:负责接收用户请求,动态地将其分成 Batch,然后将这些 Batch 分配给 GPU 实例上运行的推理实例,并收集推理实例生成的输出,将结果发送回用户。
-
Instance Manager:负责与各种云平台进行交互,接收实例抢占和获取通知。
-
Meta-Context Manager:当系统的服务能力与工作负载不兼容或即将不兼容时,Meta-Context Manager 通过向所有 GPU 实例发送上下文迁移指令来管理并行配置的调整。新配置由 Parallelization Controller 生成,并由 Device Mapper 和 Migration Planner 来实现。
-
Context Daemon:每个推理实例都包含一个上下文守护进程,用于管理特定 GPU 内不同请求的模型参数(模型上下文)和中间激活(KV Cache)。Inference Engine 可以通过 Context Daemon 进程提供的 Proxy 来访问这些上下文信息。
-
Interruption Arranger:每个 Inference Engine 还会启动一个 Interruption Arranger 来支持有状态的推理恢复,以降低推理时延。
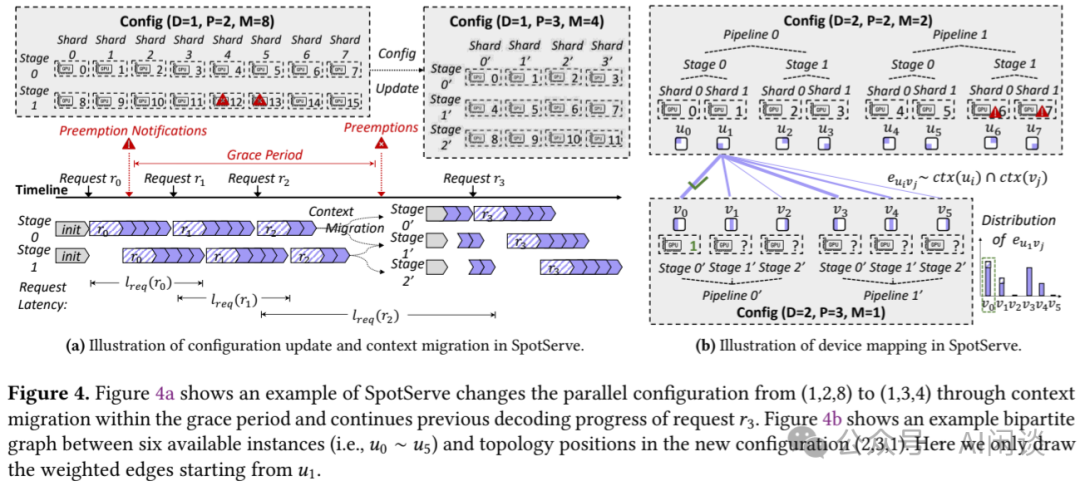
如下图 Figure 4a 展示了 SpotServe 将分布式排布从 1DP 2PP 8MP 切换为 1DP 3PP 4MP 的过程;如下图 Figure 4b 展示了 SpotServe 依据每个 GPU Context Daemon 的当前状态(2DP 2PP 2MP)和目标分布式排布(2DP 3PP 1MP),然后将最优设备映射转换为二分图匹配任务,并使用 KM 算法找到最大权重匹配,从而最大限度地重用可用 GPU 实例上的模型参数和 KV 缓存,并最大限度地减少数据传输量:
4.3 SkyPilot
在 SkyPilot: Run LLMs, AI, and Batch jobs on any cloud. Get maximum savings, highest GPU availability, and managed execution—all with a simple interface. 中也提供了类似的方案。SkyPilot 是一个用于在任何云上运行 LLM、AI 和批处理作业的框架,可最大限度地节省成本、实现最高的 GPU 可用性和可管理的执行。
如下图所示,可以使用 SkyPilot 提供的工具评估不同配置的性价比。根据结果可以选择成本最低(EST($)) 或执行时间最快 (EST(hr)) 的配置。在此示例中,**AWS g5.xlarge(NVIDIA A10G GPU)**在成本和时间方面都是最佳选择。

4.4 TrueFoundry
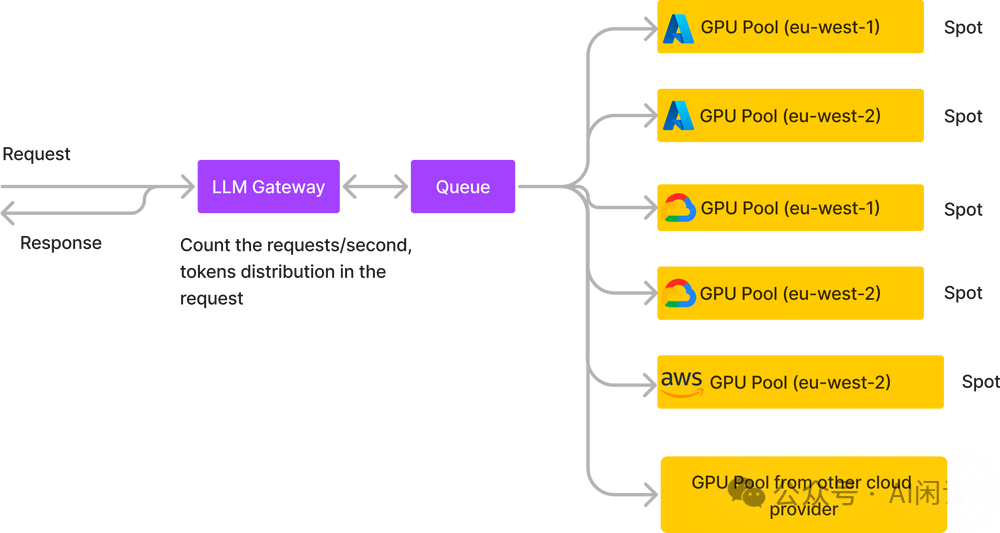
TrueFoundry 也提供了多 GPU Pool 部署的方案,采用生产者-消费者模式,其 LLM Gateway 接收用户请求,并将请求放入 Queue 中,供部署于不同 GPU Pool 的 LLM 实例来消费。主要有几个好处:
-
在 Gateway 可以更好地对流量分布进行统计和调度。
-
可以统计不同云平台的报价,动态的调整实例伸缩,以降低整体成本。
-
每个 LLM 实例也可以根据需求尽可能的以高负载运行,比如同时从 Queue 中获取 batch 的请求来处理。
05
Spitwise
5.1 摘要
微软和华盛顿大学在 [2311.18677] Splitwise: Efficient generative LLM inference using phase splitting 中提出了 Splitwise,为 LLM 推理不同阶段选择不同的 GPU 类型。Prefill 阶段为计算密集型,可以选择高算力 GPU,而 Decoding 阶段为访存密集型,相应的可以使用算力不是特别强而访存带宽比较大的 GPU。同时为了两个阶段 KV Cache 的共享,需要在 GPU 间有高速的 IB 网络互联。
作者使用 Splitwise 技术构建了 LLM 推理集群,使用相同或不同类型的 GPU 机器来进行 Prefill 计算和 Decoding 计算。集群针对三个关键目标进行了优化:吞吐量、成本和功耗。实验表明,与传统设计相比,Splitwise 可以以低 20% 的成本实现 1.4× 的吞吐量。或者,可以在相同的成本和功耗预算下实现 2.35× 的吞吐量。
5.2 方法
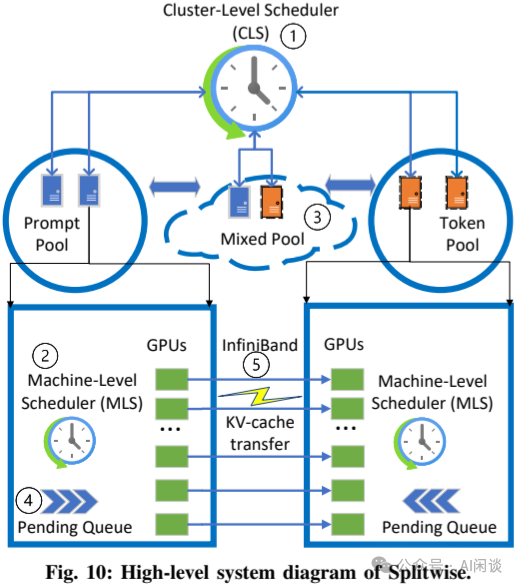
如下图 Figure 10 所示为 Splitwise 的架构概览。Splitwise 会维护两个独立节点池:Prompt Pool 和 Token Pool,用于 Prefill 和 Decoding 的处理。第三个混合池(Mixed Pool)根据工作负载的情况来扩展 Prompt Pool 和 Token Pool。
-
当新的推理请求到达时,调度进程会将其分配给一对节点(Prompt 和 Token)。Prompt 节点还会将 KV Cache 发送给 Token 节点。在 Token 节点上使用 Continuous Batching,以最大限度地提高其利用率。
-
为了满足 SLO 并避免在较高负载下由于碎片而导致性能突降,Splitwise 维护了一个特殊的 Mixed Pool,该 Pool 根据输入和输出 Token 的请求速率和分布动态增长和收缩,没有任何的切换时延。Mixed Pool 中的节点仍然保留其作为 Prompt 节点或 Token 节点的标记,并在其挂起队列中没有相反类型的任务时返回其原始 Pool。
Splitwise 使用分层的两级调度,Cluster 级调度(CLS)进程 1 负责将输入请求路由到特定节点并重新调整节点的用户。Machine 级调度(MLS)进程 2 维护挂起的队列并管理每个节点上的批量请求。
在较低的请求速率下,目标是在 Splitwise 中实现更好的延迟,而在更高的请求速率下,目标是避免由于 Prompt 节点和 Token 节点池之间的碎片而导致的任何性能或吞吐量降低。
06
Infinite-LLM
6.1 摘要
LLM 基本都是 Decoder Only 的 Transformer 结构,其 Decoding 阶段是逐个 Token 生成,如果不采用 KV Cache 将导致巨大的重复计算,而采用 KV Cache 又会给显存占用带来比较大的挑战,尤其当序列比较长时。
[2401.02669] Infinite-LLM: Efficient LLM Service for Long Context with DistAttention and Distributed KVCache 中,作者提出了 DistAttention,这是一种分布式注意力算法,可将 KV Cache 分割为更小的、可管理的单元,从而实现注意力模块的分布式处理和存储。基于此,作者也提出了 DistKV-LLM,它是一个分布式 LLM Serving 系统,可以动态管理 KV Cache,并有效地协调整个数据中心中所有可以访问的 GPU 显存和 CPU 内存,确保其可以适应各种上下文长度,提供高性能的 LLM 服务。
作者在 4 台 8 卡 A100 GPU 机器(共 32 A100 GPU)上进行了验证,配置从 2 到 32 个实例,使用 18 个数据集进行测试,提出的系统获得 1.03x-2.4x 的端到端吞吐提升,支持的上下文长度比当前最先进的 LLM 推理框架长 2-19 倍,支持的上下文长度高达 1900K。
6.2 DistAttention
DistAttention 中,作者将传统的注意力计算分解为更小、更易于管理的单元,称为 Micro Attention(MA),每一个 MA 对应一个 KV Cache 的子序列的 Token。这种方法的独特之处在于它能够通过单独形成 MA 来计算注意力结果,在所有 MA 完成各自 Token 子块计算后,通过聚合过程获得最终的注意力结果,这涉及到对每个 MA 的输出进行 Scaling 和 Reducing。聚合的公式如下所示:
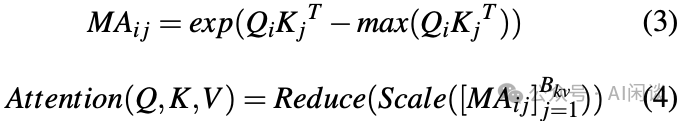
其中 Reduce 和 Scale 操作如下所示:
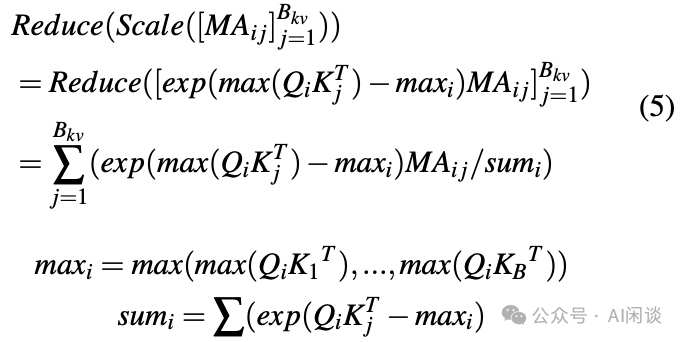
6.3 DistKV-LLM
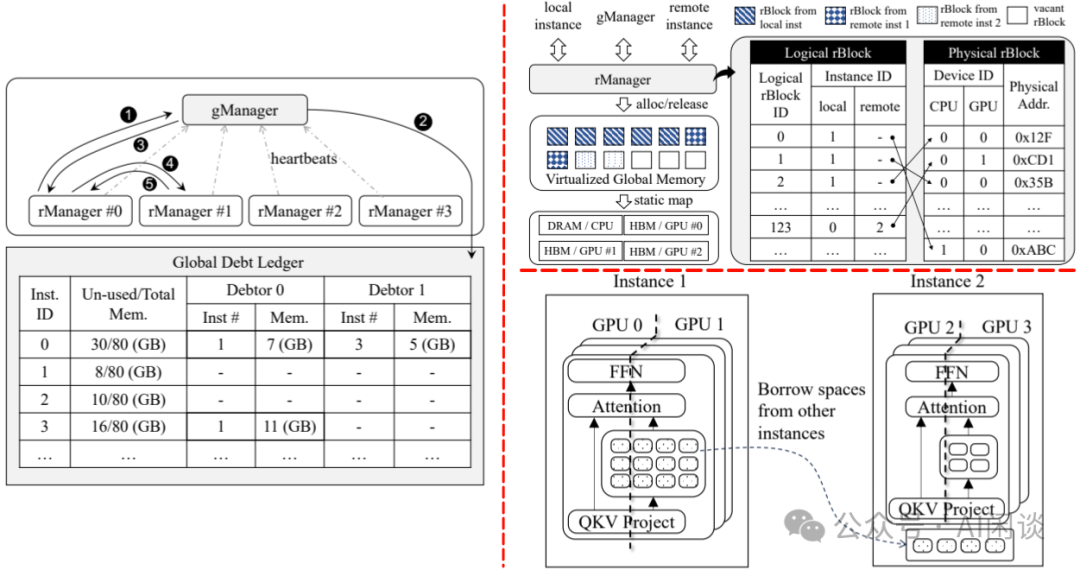
为了应用提出的 DistAttention,作者将其与分布式 LLM Serving 引擎相结合。DistKV-LLM 旨在提供高效的 KV Cache 管理服务,协调整个数据中心的 GPU 和 CPU 之间的内存使用。当 LLM 服务实例由于 KV 缓存增加而遇到内存不足时,DistKV-LLM 会主动识别并借用其他容量过剩的设备中的可用内存空间,如下图 Figure 2 所示,这种自动化机制是通过两个主要组件(rManger 和 gManager)的协作操作来实现的:
-
gManager 充当中心化管理器,维护所有实例的全局内存信息,如下图左图所示。每个实例定期向 gManager 发送心跳信号,发送有关其剩余可用内存空间的更新信息。gManager 利用这些信息构建了一个详细的表,称作 Global Debt Ledger。
-
rManger 提供统一的 API 接口,用于本地和远程内存操作,如下图右上所示。这些操作包括:
-
为新生成的 KV Cache 分配 Physical rBlock,并在不再需要时释放。
-
在收到 local 或 remote 的内存分配请求时,rManager 会查询 rBlock 表,以确定第一个可用的 Physical rBlock 空间。
-
在没有足够的空间时,rManager 会启动从其他实例空间借用过程,如下图右下所示。此时,如果分配请求来自 remote 实例,则 rManager 会返回错误响应,表示 remote 分配不可用,避免陷入死循环。
-
可以为分配给 remote 实例的 rBlock 数量设置上限,避免抢占 local 分配的空间。当然,该配置需要通过实验确定,并配置为超参。
07
Mélange
7.1 摘要
在 [2404.14527] Mélange: Cost Efficient Large Language Model Serving by Exploiting GPU Heterogeneity 中,作者首先通过大量分析证明了 GPU 的成本和性能并不是严格的线性关系,提出了为不同的流量采用不同的 GPU 进行推理可以有效降低 LLM 推理的成本。由于影响 LLM 推理性能的因素很多,因此作者将问题缩小到 3 个关键因素:模型请求大小、请求速率和 SLO。然后提出了 Mélange,可以为 LLM 服务构建最具性价比的 GPU 集合。通过 Mélange ,可以将 LLM 部署成本降低多达 77%,这凸显了为 LLM 服务提供异构感知 GPU 配置的重要性。
7.2 请求大小与成本
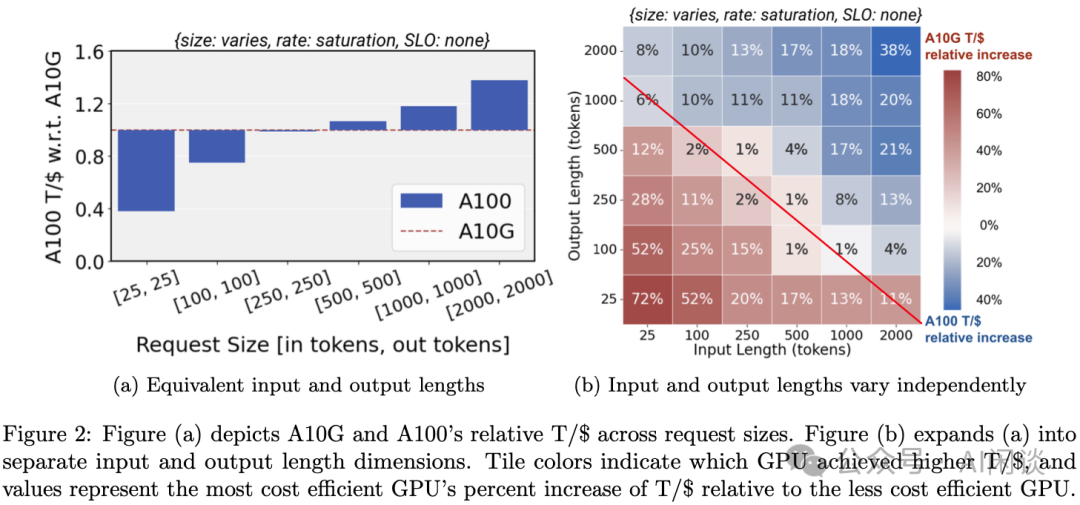
如下图 Figure 2 所示,作者在 A10 和 A100 上评估 LLaMA2-7B 模型的性能,来评估请求大小和成本的关系,需要说明的是,在每种测试中作者都尽可能地打满 GPU,也就是尽可能增加 Batch Size。
-
左图:每种情况下都把 A10 的 T/$ 作为参照归一化为 1,可以看出:
-
在 [输入,输出] 为 [25, 25] 时,A10 的性价比是 A100 的 2.6 倍(1/0.38)
-
在 [输入,输出] 为 [250, 250] 时,A10 的性价比和 A100 相当
-
在 [输入,输出] 为 [2000, 2000] 时,A100 的性价比是 A10 的 1.5 倍(1.5/1)
-
右图:不同输入和输出组合情况下的性价比,基本可以以红线的对角线为分界线,也就是说,对于比较大的输入、输出,A100 具有更高的性价比,对于比较小的输入输出,A10 具有更高的性价比。
如下图 Figure 8 所示,作者进一步在更多的序列组合和更多的 GPU 下测试了相应的性价比。其中左图为性价比最高的 GPU 相比第二高的 GPU 的比例,右图为性价比最高的 GPU 相比性价比最低的 GPU 的比例。此外,黑框中为 H100 和 A100 的比例,因为只有这两个 GPU 能支持 12K 和 16K 的序列长度。从图中可以得出和之前类似的结论。

主要结论:成本与请求大小密切相关,低端 GPU 更适合处理比较小的请求,高端 GPU 比较适合大的请求。
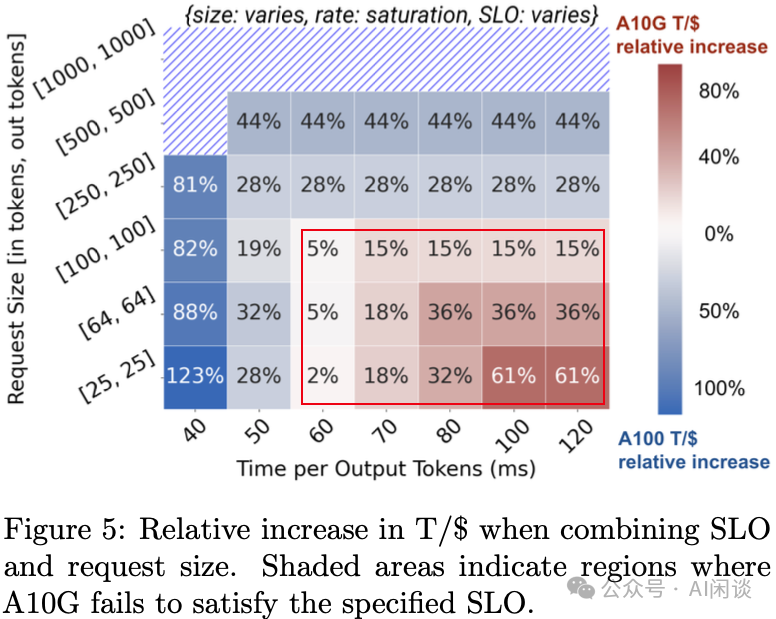
7.3 SLO 与成本
作者进一步评估了 SLO 与成本的关系,具体来说,Batch Size 越大,吞吐越高,但相应的时延也就越大。作者评估时会保证在满足 SLO(TPOT)的同时尽可能充分利用 GPU,也就是 Batch Size 尽可能大。如下图 Figure 5 所示,可以看出,A10 只在序列比较短,同时对 SLO 要求不高时比较有性价比:
08
MuxServe
8.1 摘要
在 [2404.02015] MuxServe: Flexible Multiplexing for Efficient Multiple LLM Serving 中,作者提出 MuxServe,这是一种灵活的时空复用系统,用于高效为多个不同模型规模、不同流量分布的 LLM 提供 Serving 能力。
关键想法是充分考虑其多路复用内存资源,并利用 Prefill 和 Decoding 阶段的特性将它们分离并灵活地放置到多路复用计算资源中。MuxServe 正式提出了多路复用问题,并提出一种排布(Placement)算法和自适应 Batching 调度策略,以确定最佳排布并最大程度地提高利用率。MuxServe 设计了一个统一的资源管理器,以实现灵活高效的多路复用。
评估结果表明,MuxServe 可以实现高达 1.8x 的吞吐量,或在达成 99% 的 SLO 目标下处理 2.9x 的请求。
8.2 方法
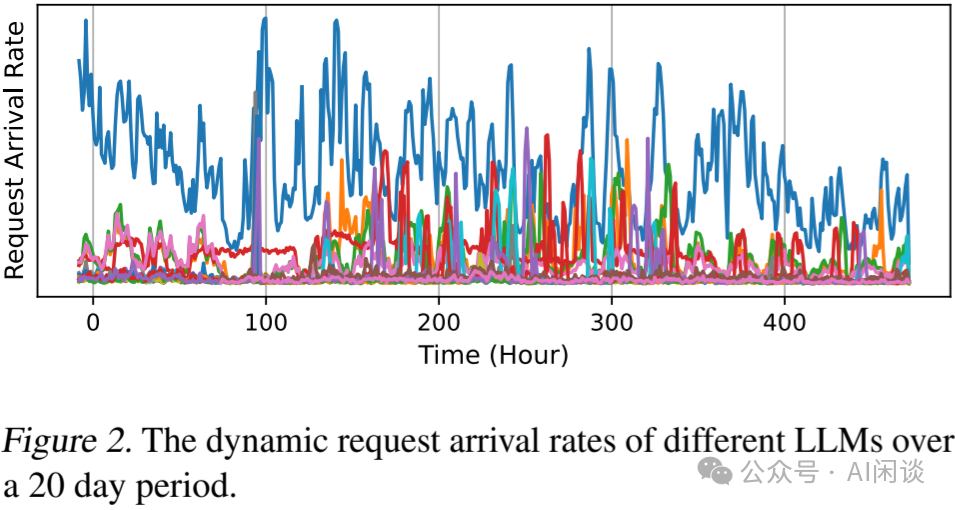
如下图 Figure 2 所示为多个 LLM 在 20 天的流量分布,可见流量很不均匀,并且会出现突发的流量增加和降低:
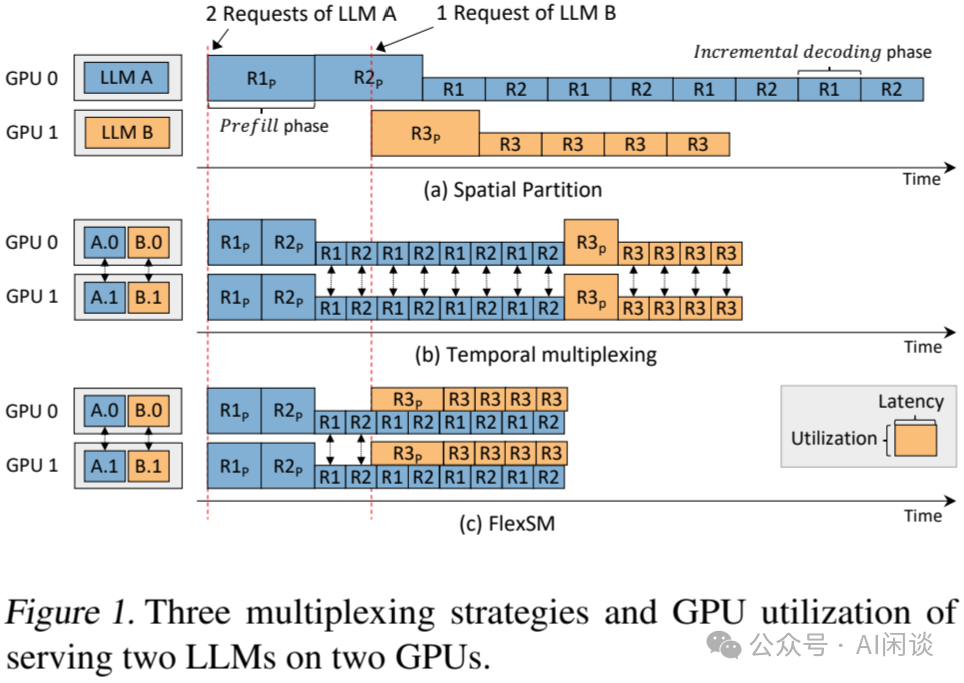
如下图 Figure 1 所示为 MuxServe 与相同方案的对比,其中两种颜色代表两个模型,矩形的高度代表利用率,宽度代表 Latency(PS:如果两个模型的流量都足够大,并且比较均匀,可以充分的 Continuous Batching 是不是就不存在下述的问题?):
-
(a):最简单的空间切分方案,一个 GPU 部署一个模型,当流量比较小,不够均匀时会存在巨大的算力浪费。
-
(b):AlpaServe 中模型切分复用 GPU 的方案,两个模型共享两个 GPU,可以将两个模型的工作负载放在两个 GPU 上,因此可以避免低流量模型导致的空闲。
-
(c):本文 MuxServe 的方案,在 A 模型的 Decoding 阶段也会同时执行 B 模型。
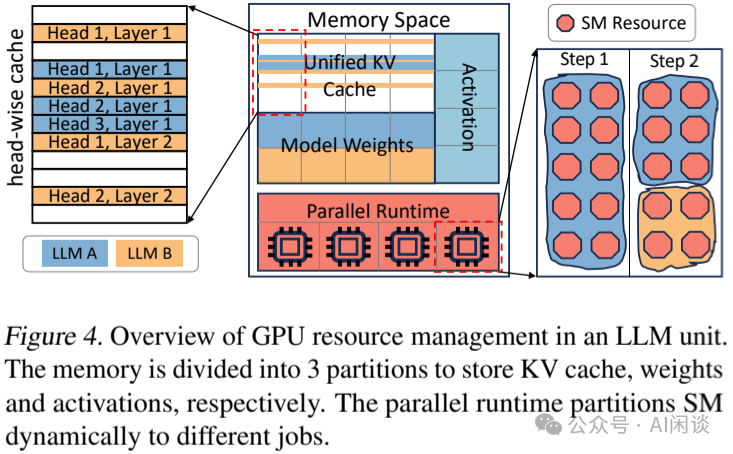
如下图 Figure 4 所示为相应的 GPU 资源管理方案:
-
Memory Space 分为 3 个区域:模型权重、统一的 KV Cache 以及激活。其 KV Cache 以每个模型一个 Layer 的一个 Attention Head 为单位。
-
Parallel Runtime 负责管理 GPU SM 计算单元,比如 Step 1 中模型 A 使用所有 SM,Step 2 中模型 A 使用 60% SM,模型 B 使用 40% SM。Parallel Runtime 切分计算单元 SM 是通过 CUDA 的 MPS(Multi-Process Service)来实现的。
09
Helix
9.1 摘要
[2406.01566] Helix: Distributed Serving of Large Language Models via Max-Flow on Heterogeneous GPUs 是一个用于在异构 GPU 集群上提供高吞吐、低延迟 LLM 推理服务的分布式系统。Helix 的关键思想是将异构 GPU 和异构网络连接的 LLM 推理计算表示为一个有向加权图的最大流量问题,其节点代表 GPU 实例,边捕获通过异构 GPU 和网络的流量。然后,Helix 使用混合整数线性规划(Mixed Integer Linear Programming,MILP)算法来发现高度优化的策略,以支撑 LLM 服务。这种方法允许 Helix 共同优化模型排布和请求调度,这是异构 LLM 服务中两个高度关联的任务。
作者对 24 到 42 个 GPU 节点的几种异构集群进行评估,结果表明,与现有最佳方法相比,Helix 将服务吞吐量提高了 2.7x,并将 Prefill 和 Decoding 延迟分别降低了 2.8x 和 1.3x。
9.2 示例
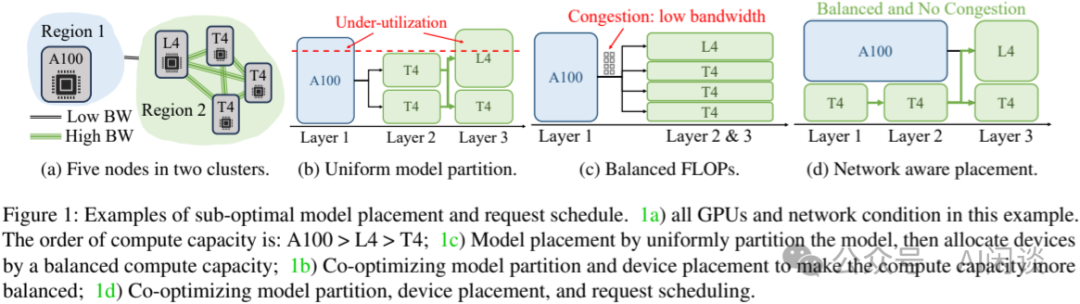
如下图 Figure 1 所示,作者提供了一个异构 GPU 和异构网络的示例:
-
(a)中为两个 Region 的 5 个 GPU,Region 1 为高性能的 A100,Region 2 为 4 个较低性能的 L4 和 T4。Region 2 之间可以高速通信,而 Region 1 和 Region 2 之间带宽比较低。
-
(b):如果使用简单的 TP + PP 方式调度,A100 执行 Layer 1,2 个 T4 执行 Layer 2,1 T4 + 1 L4 执行 Layer 3,则 A100 和 L4 会存在算力浪费。因为 A100 算力大于 2 个 T4,而 L4 算力大于 T4.
-
(c):Region 1 的 A100 执行 Layer 1,Region 2 的 T4 和 L4 共同执行 Layer 2 和 Layer 3,此时 Region 1 和 Region 2 的低带宽可能成为瓶颈。
-
(d):更优的方案:A100 和 2 个 T4 共同执行 Layer 1 和 Layer 2,一个 L4 和 1 个 T4 共同执行 Layer 3。(PS:此时如果 A100 和两个 T4 使用 TP,则需要大规模通信,依然会有瓶颈,但是可以让 A100 和两个 T4 执行不同的 Micro Batch,则它们不用通信,也同时可以降低 Region 1 和 Region 2 之间的通信量)
9.3 方法
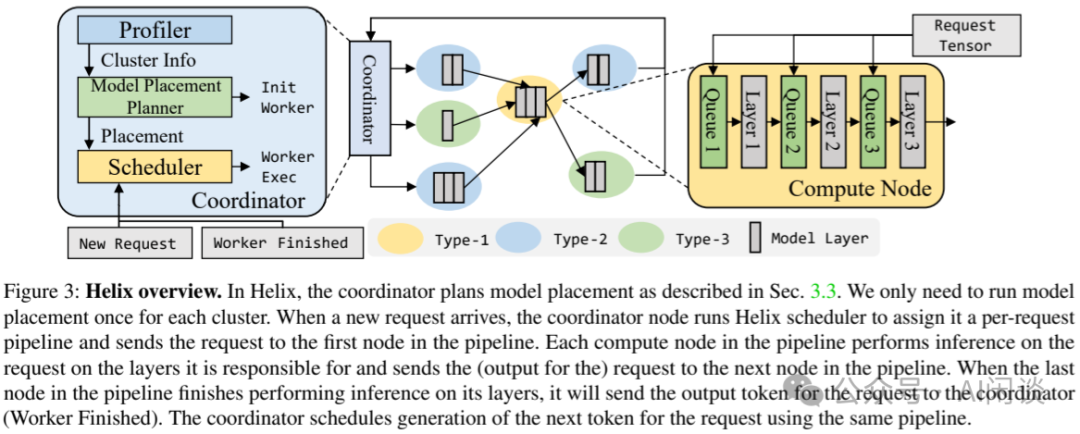
为了实现上述最优的调度机制,作者提出了 Helix,其方案如下图 Figure 3 所示:
-
当 Coordinator(集群中分为 Coordinate 节点和计算节点) 收到一个请求后,会调用 Request Scheduler 为该请求分配一个 per-request pipeline。
-
然后 Coordinator 会将请求发送到 Pipeline 的第一个计算节点。
-
当第一个计算节点收到请求后,它使用该 Pipeline 中对应的 Layer 对请求进行处理。
-
然后将请求发送给下一个计算节点。
-
直到请求结束。
9.4 对比
如下图 Figure 10 所示,作者基于 LLaMA 70B 模型对比了在单集群和分布式集群中进行推理时不同方案的性能。其中,Swarm(SWARM Parallelism: Training Large Models Can Be Surprisingly Communication-Efficient) 将模型层划分为等长的 Stage,并为每个 Stage 分配节点,使得每个 Stage 具有相等的计算量。而 Petals([2209.01188] Petals: Collaborative Inference and Fine-tuning of Large Models) 则允许节点承载不同数量的 Layer,旨在实现去中心化的 LLM 服务,因此逐个节点地决定模型排布,并贪心地选择涵盖计算量最少 Layer 的放置策略。从图中可以看出,Helix 的相对吞吐量分别为 Petals 和 Swarm 的 1.34x 和 2.49x。
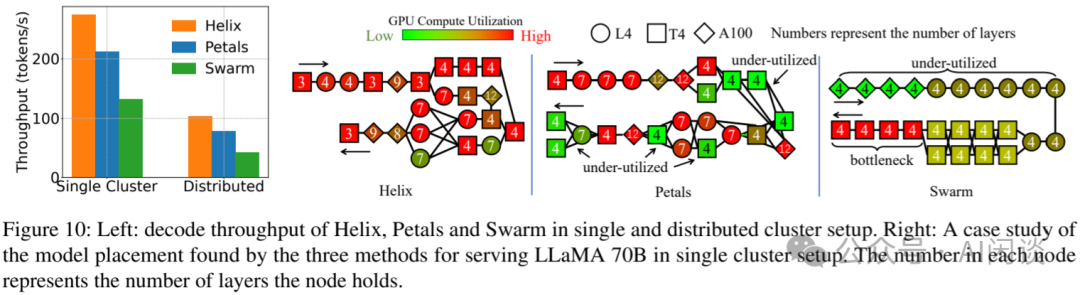
10
附录
10.1 长上下文部署挑战
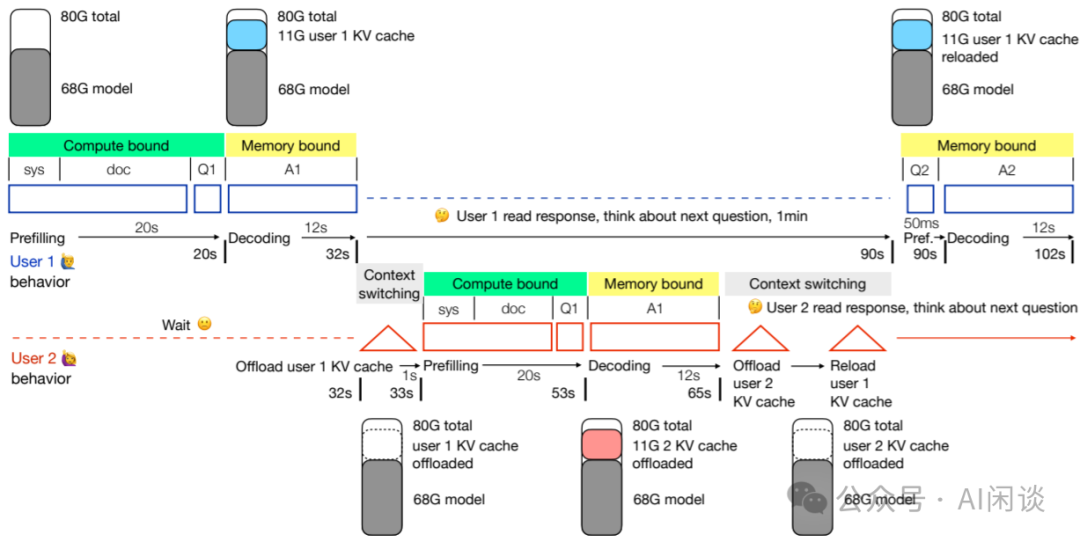
在 [2405.08944] Challenges in Deploying Long-Context Transformers: A Theoretical Peak Performance Analysis 中符尧大佬也分析了部署长上下文(100k-10M Token)模型场景下的挑战,其目标是将 1M 上下文的服务成本降低到 4K 一样便宜,为此将任务分解为 4 个关键指标:并发、Prefill、Decoding 和上下文切换。作者也进一步讨论了常见因素如何影响这 4 个指标,以及现有工作如何关注不同的指标。
如下图所示为一个并发编程框架,用于在有限的 GPU HBM 大小下处理多个长上下文的用户请求。上述 4 个指标共同决定了用户交互会话的整体吞吐。与短上下文相比,并发和上下文切换的挑战要严重的多:
-
长序列 KV Cache 很大,并发受 HBM 大小限制。
-
Prefill 是 Compute Bound,第一个 Token 时间,也就是 Prefill 时间受 GPU 算力限制。
-
Decoding 是 Memory Bound,每个 Token 时间受 HBM 带宽限制。
-
上下文切换(从 HBM offload 到 CPU 内存)受 PCIe 限制,用户 1 的 KV Cache offload 到 CPU 内存,用户 2 的 KV Cache 重新加载到 HBM。
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】















 2995
2995

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









