







在SCI文章中,基线表通常是表一,表示的是数据基线的比较情况。本公众号陆陆续续介绍了多个方法绘制基线表,今天来介绍一下gtsummary包绘简洁的介基线表。
下面咱们导入R包和数据,使用的是一个糖尿病的数据集。
library(gtsummary)
diabetes<-read.csv("diabetes")
这是个印度糖尿病的数据集,数据集由几个医学预测变量和一个目标变量“结果”组成。预测变量包括患者的怀孕次数、BMI、胰岛素水平、年龄等。Pregnancies:怀孕次数,Glucose:口服葡萄糖耐量试验中2小时的血浆葡萄糖浓度,BloodPressure:舒张压(mm Hg),SkinThickness:三头肌皮褶厚度(mm),Insulin:2小时血清胰岛素(μU/ml),BMI:体重指数,DiabetesPedigreeFunction:糖尿病患者饮食功能,Age年龄(岁),Outcome:结局变量,是否是糖尿病。
下面开始分析,咱们先来个简单点的
diabetes2<-diabetes %>% tbl_summary()
diabetes2

咱们以是否糖尿病为分组,并且添加P值
diabetes %>%
tbl_summary(by = Outcome) %>%
add_p()
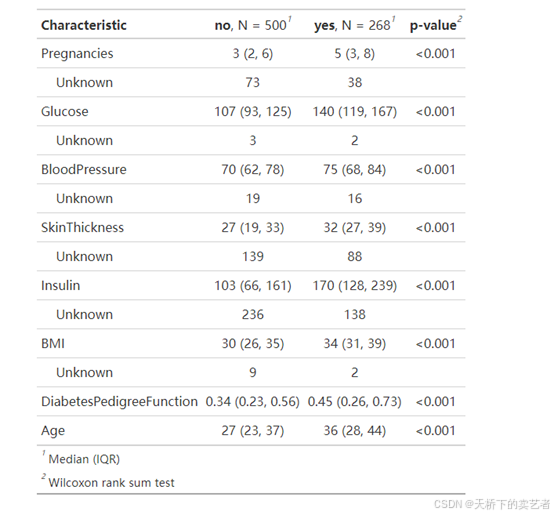
一个非常漂亮的基线表就制作好了。咱们生成一个新变量bmi2,如果bmi大于25,表示1,否者表示0
diabetes$bmi2<-ifelse(diabetes$BMI>25,1,0)
diabetes$bmi2<-as.factor(diabetes$bmi2)
咱们再从新制作一下基线表,bmi2在是否是糖尿病是有差异的
diabetes %>%
tbl_summary(by = Outcome) %>%
add_p()
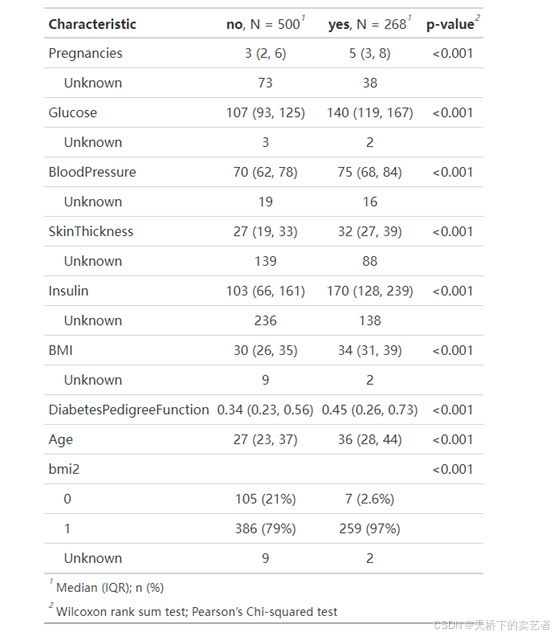
咱们注意到表格中有个 Unknown的字符显得有点奇怪,这个是缺失值的统计,咱们可以修改一下,并且对一些分类变量进行自定义标签
diabetes %>%
tbl_summary(
by = Outcome,
statistic = list(
all_continuous() ~ "{mean} ({sd})",
all_categorical() ~ "{n} / {N} ({p}%)"
),
digits = all_continuous() ~ 2,
label = bmi2 ~ "是否肥胖",
missing_text = "(Missing)"
)
)"

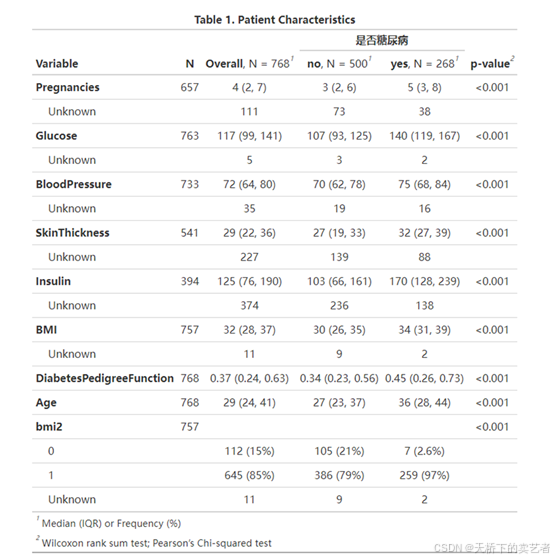
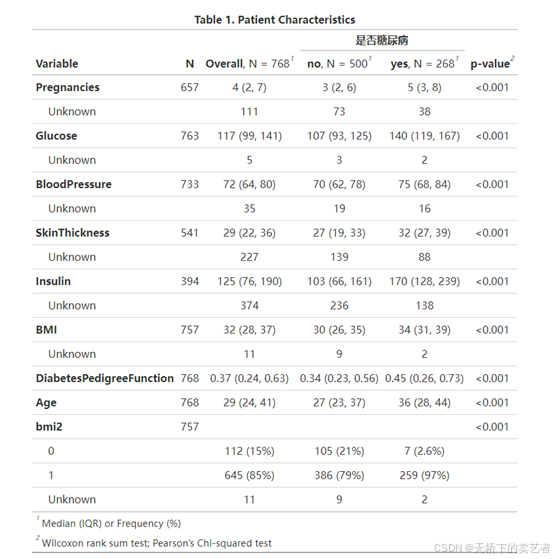
{gtsummary}包附带了专门用于修改和格式化汇总表的函数。可以制作非常专业的表格
diabetes %>%
tbl_summary(by = Outcome) %>%
add_p() %>%
add_overall() %>%
add_n() %>%
modify_header(label ~ "**Variable**") %>%
modify_spanning_header(c("stat_1", "stat_2") ~ "**是否糖尿病**") %>%
modify_footnote(
all_stat_cols() ~ "Median (IQR) or Frequency (%)"
) %>%
modify_caption("**Table 1. Patient Characteristics**") %>%
bold_labels()
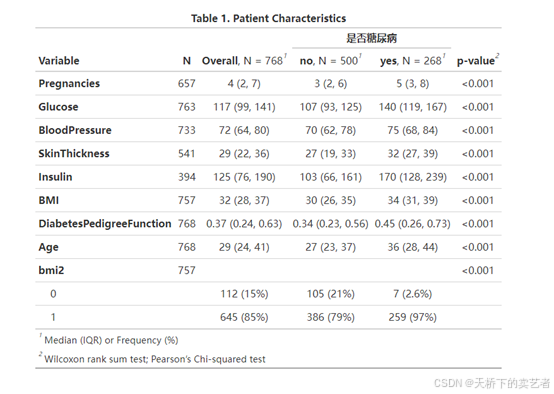
如果不想显示缺失值,咱们可以添加参数把它去掉missing = “no”
diabetes %>%
tbl_summary(by = Outcome, missing = "no") %>%
add_p() %>%
add_overall() %>%
add_n() %>%
modify_header(label ~ "**Variable**") %>%
modify_spanning_header(c("stat_1", "stat_2") ~ "**是否糖尿病**") %>%
modify_footnote(
all_stat_cols() ~ "Median (IQR) or Frequency (%)"
) %>%
modify_caption("**Table 1. Patient Characteristics**") %>%
bold_labels()
本期简单介绍到这里,总之这是个强大的绘制基线表的R包,还有许多功能可以自己探索。


















 1446
1446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











