







 本文介绍了深度强化学习中的Actor-Critic算法,它结合了策略迭代和值迭代,通过行动者网络选择动作和评论家网络评估动作效果。算法分为Actor和Critic两部分,分别用于动作选择和策略评价。文中提供了代码示例,展示了如何在OpenAIGym环境中使用该算法解决具体问题。
本文介绍了深度强化学习中的Actor-Critic算法,它结合了策略迭代和值迭代,通过行动者网络选择动作和评论家网络评估动作效果。算法分为Actor和Critic两部分,分别用于动作选择和策略评价。文中提供了代码示例,展示了如何在OpenAIGym环境中使用该算法解决具体问题。
大家好,今天和各位分享一下深度强化学习中的 Actor-Critic 演员评论家算法,Actor-Critic 算法是一种综合了策略迭代和价值迭代的集成算法。我将使用该模型结合 OpenAI 中的 Gym 环境完成一个小游戏,完整代码可以从我的 GitHub 中获得:
https://github.com/LiSir-HIT/Reinforcement-Learning/tree/main/Model
1. 算法原理
根据 agent 选择动作方法的不同,可以把强化学习方法分为三大类:行动者方法(Actor-only),评论家方法(Critic-only),行动者评论家方法(Actor-critic)。
行动者方法中不会对值函数进行估计,直接按照当前策略和环境进行交互。通过交互后得到的立即奖赏值直接优化当前策略。例如:Policy Gradients
评论家方法没有需要维护的策略,评论家方法的策略是直接通过当前的值函数获得的,并通过值函数获得的策略与环境交互。交互得到的立即奖赏值用来优化当前值函数。例如:DQN
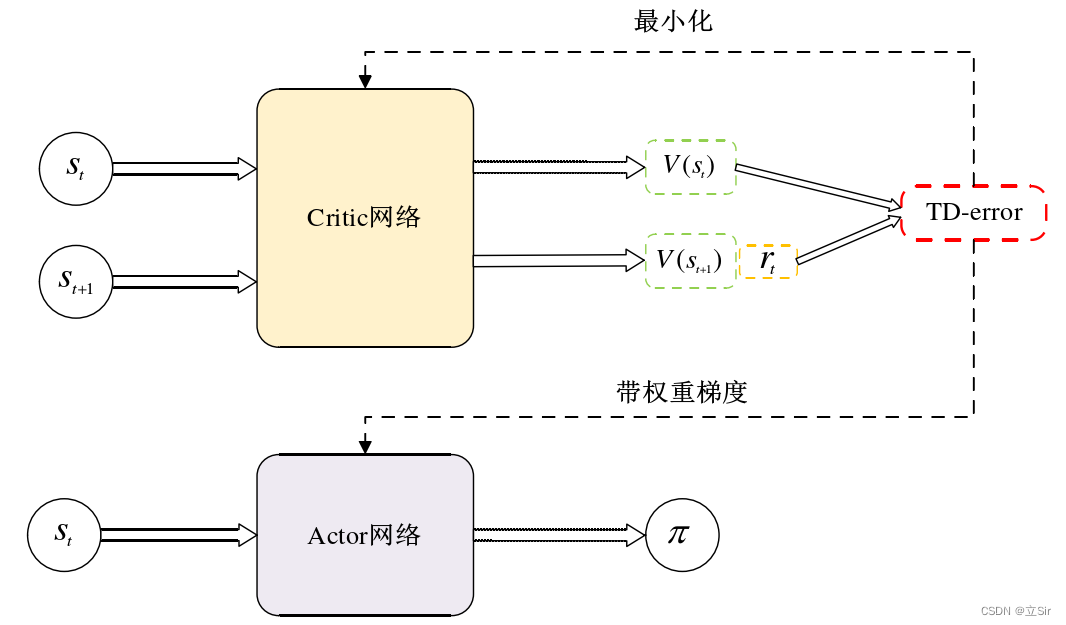
行动者评论家方法是由行动者和评论家两个部分构成。行动者用于选择动作,评论家评论选择动作的好坏。行动者选择动作的方法不是依据当前的值函数,而是依据存储的策略。评论家的评论一般采用时间差分误差的形式,时间差分误差是根据当前的值函数计算获得的。时间差分误差是是评论家的唯一输出,并且驱动了行动者和评论家之间的所有学习。
2. 公式推导
根据策略梯度算法的定义,策略优化目标函数如下:
令 ,,称
为优势函数。采用 n 步时序差分法求解时,
可以表示如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











