








 超级会员免费看
超级会员免费看


 本文深入浅出地介绍了生成对抗网络(GAN)的基本原理、优缺点,以及训练技巧。通过DCGAN和Wasserstein GAN(WGAN)的详细解析,展示了GAN在图像生成、图像变换、图像补全等方面的应用。此外,还探讨了WGAN的改进策略WGAN-GP,并总结了GAN在图像处理和非线性系统辨识等领域的广泛应用。
本文深入浅出地介绍了生成对抗网络(GAN)的基本原理、优缺点,以及训练技巧。通过DCGAN和Wasserstein GAN(WGAN)的详细解析,展示了GAN在图像生成、图像变换、图像补全等方面的应用。此外,还探讨了WGAN的改进策略WGAN-GP,并总结了GAN在图像处理和非线性系统辨识等领域的广泛应用。
文章目录
一、原理部分
Generative Adversarial Networks(GAN):生成对抗网络。
2014年Ian J. Goodfellow等人在论文《Generative Adversarial Nets》中第一次提出GAN的概念。
大牛Yann LeCun甚至评价GAN为 “adversarial training is the coolest thing since sliced bread”。
1.1举例解释
论文中举了一个很通俗的例子——假币与真币的例子。
造假币的团伙相当于生成器,他们想通过伪造金钱来骗过银行,使得假币能够正常交易,而银行相当于判别器,需要判断进来的钱是真币还是假币。因此假币团伙的目的是造出银行识别不出的假币而骗过银行,银行则是想办法准确的识别出假币。

这样,G和D构成了一个动态的“博弈过程”。因此,生成对抗网络由此而来。
1.2基本知识
GAN的主要灵感来源于博弈论中零和博弈的思想。GAN属于非监督式学习,但与一般非监督式学习不同。GAN被誉为近年来复杂分布上无监督学习最具前景的方法之一。
组成: GAN包括两个部分, 生成器G(generator) 和 判别器D(discriminator) 。生成器接收一个随机噪声(随机数),并且学习真实图像分布从而让自身生成的图像更加真实,以骗过判别器。判别器则需要对接收的图片进行真假判别。
目标: 使得判别器无法判断,无论对于真假样本,输出结果概率都是0.5。
原理: 在训练过程中,生成器努力地让生成的图像更加真实,而判别器则努力地去识别出图像的真假,这个过程相当于一个二人博弈,随着时间的推移,生成器和判别器在不断地进行对抗。最终两个网络达到了一个动态均衡:生成器生成的图像接近于真实图像分布,而判别器识别不出真假图像,对于给定图像的预测为真的概率基本接近0.5(相当于随机猜测)。
在分析GAN结构模型之前,我们首先要明白在使用以下两个问题:
- 我们有什么?
我们所拥有的,也就是向神经网络中填喂的数据仅仅是真实采集来的数据集,仅此而已,甚至连类标签都没有。 - 我们要得到什么?
我们希望根据输入数据,当输入一个噪声时,能模拟得到与输入数据类似的图像,以此得到以假乱真的效果。
模型结构如图所示:

- G表示生成器,它接收一个随机噪声z(随机数),通过这个噪声生成图像;
- D代表判别器,判别图像真假,它的输出是(0,1)之间的数字,代表真实图像的概率。如果是1,表示是真实图片;如果是0则代表不是真实图像,而是生成器生成的图像。
【注意】:需要注意的是生成模型和对抗模型可以说是完全独立的两个模型,他们之间是没有什么联系的。因此训练这两个模型的方法是:单独交替迭代训练。也就是说,当一个神经网络开始训练时,另一个必须停止;而另一个训练时,第一个就需要停止。
1.3优缺点
关于优缺点部分,作者在论文中是这样写的:

具体来说,
优点:
- 相比较其它模型,只需使用反向传播来获得梯度,而不需要复杂的马尔科夫链(Markov chains)
- 在学习过程中不需要推理,非常灵活,并且可以将多种函数合并到模型中(无监督学习方式)
- 相比较于VAE,可以产生更加清晰真实的样本
缺点:
- 不适合处理离散形式的数据,比如文本
- 在训练过程中D必须与G很好地同步(特别是,G在不更新D的情况下不能训练太多),否则可能会出现 训练不稳定、梯度消失、模式崩溃等问题。
【注1:模式崩溃(model collapse)现象】
GAN采用的是对抗训练的方式,G的梯度更新来自D,所以G生成的好不好,得看D怎么说。具体就是G生成一个样本,交给D去评判,D会输出生成真假样本的概率(0-1),相当于告诉G生成的样本有多大的真实性,G就会根据这个反馈不断改善自己,提高D输出的概率值。但是如果某一次G生成的样本可能并不是很真实,但是D给出了正确的评价,或者是G生成的结果中一些特征得到了D的认可,这时候G就会认为我输出的正确的,那么接下来我就这样输出肯定D还会给出比较高的评价,实际上G生成的并不怎么样,但是他们两个就这样自我欺骗下去了,导致最终生成结果缺失一些信息,导致训练失败。
二、GAN的主要问题
GAN从本质上来说,有着与一般神经网络不同的特点,因为GAN的训练是依次迭代D和G,如果判别器D学的不好,生成器G得不到正确反馈,就无法稳定学习。如果判别器D学的太好,整个loss迅速下降,G就无法继续学习。
GAN的优化需要生成器和判别器达到纳什均衡,但是因为判别器D和生成器G是分别训练的,纳什平衡并不一定能达到,这是早期GAN难以训练的主要原因。另外,最初的损失函数也不是最优的。
三、公式说明

生成网络G的损失函数为:
log
(
1
−
D
(
G
(
z
)
)
)
\log (1 - D(G(z)))
log(1−D(G(z)))或者
−
l
o
g
D
(
G
(
z
)
)
-log D(G(z))
−logD(G(z))。
判别网络D的损失函数为:
−
(
log
D
(
x
)
+
log
(
1
−
D
(
G
(
z
)
)
)
)
- (\log D(x) + \log (1 - D(G(z))))
−(logD(x)+log(1−D(G(z))))
我们从式子中解释对抗,损失函数的图像是一个类似于y=log(x)函数图形,x>1时,y>0,x=1时,y=0。
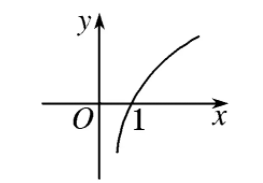
生成网络和判别网络对抗(训练)的目的是使得各自的损失函数最小,生成网络G的训练希望 D ( G ( z ) ) D(G(z)) D(G(z))趋近于1,也就是正类,这样生成网络G的损失函数 log ( 1 − D ( G ( z ) ) ) \log (1 - D(G(z))) log(1−D(G(z)))就会最小。而判别网络的训练就是一个2分类,目的是让真实数据x的判别概率D趋近于1,而生成数据G(z)的判别概率 D ( G ( z ) ) D(G(z)) D(G(z))趋近于0,这是负类。
- 当判别网络遇到真实数据时: E x ∼ p d a t a ( x ) [ log D ( x ) ] {E_{x \sim {p_{data}}(x)}}[\log D(x)] Ex∼pdata(x)[logD(x)],这个期望要取最大,只有当D(x)=1的时候,也就是判别网络判别出真实数据是真的。
- 当判别网络遇到生成数据时: E z ∼ P z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] {E_{z \sim Pz(z)}}[\log (1 - D(G(z)))] Ez∼Pz(z)[log(1−D(G(z)))],因为0<概率<1,且x<1的对数为负,这个数学期望要想取最大值,则需要令D(G(z))=0,D(G(z))=0是判别器发现了生成数据G(z)是假的。
综上:
优化Discriminator:
max
D
V
(
D
,
G
)
=
E
x
∼
p
d
a
t
a
(
x
)
[
l
o
g
(
D
(
x
)
)
]
+
E
z
∼
p
z
(
z
)
[
l
o
g
(
1
−
D
(
G
(
z
)
)
)
]
\max \limits_D V(D,G)=E_{x \sim p_{data}(x)}[log(D(x))]+E_{z \sim p_{z}(z)}[log(1-D(G(z)))]
DmaxV(D,G)=Ex∼pdata(x)[log(D(x))]+Ez∼pz(z)[log(1−D(G(z)))]
优化Generator:
min
G
V
(
D
,
G
)
=
E
z
∼
p
z
(
z
)
[
l
o
g
(
1
−
D
(
G
(
z
)
)
)
]
\min \limits_G V(D,G)=E_{z \sim p_{z}(z)}[log(1-D(G(z)))]
GminV(D,G)=Ez∼pz(z)[log(1−D(G(z)))]

分布如下:
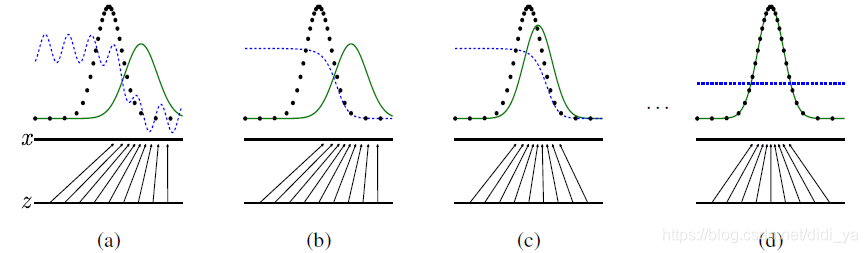
黑色线表示真实数据的分布,绿色线表示生成数据的分布,蓝色线表示生成数据在判别器中的分布效果。
生成对抗网络的目标在于让绿色线(也就是生成数据的分布)逐渐逼近黑色线(代表真实数据的分布)。
我们对每个图逐一进行分析:
(a)、判别网络D还未经过训练,分类能力有限,有波动,但是真实数据x和生成数据G(z)还是可以的
(b)、判别网络D训练的比较好,可以明显区分出生成数据G(z)。
©、绿色的线与黑色的线偏移了,蓝色线下降了,也就是判别生成数据的概率下降了。
由于绿色线的目标是提升提升概率,因此会往蓝色线高的方向引动。那么随着训练的持续,由于G网络的提升,生成网络G也反过来影响判别网络D的分布。在不断循环训练判别网络D的过程中,判别网络的判别能力会趋于一个收敛值,从而达到最优。
论文中算法解释如下:

作者采用交替训练策略,首先训练判别器网络D,优化判别器参数,然后再训练生成器网络G。
其伪代码表示为:
for 迭代 in range(迭代次数):
for batch in range(batch_size):
从生成器前置随机分布pg(z)取出m个小批次样本z(1),...,z(m);
从真实数据分布pdata(x)取出m个小批次样本x(1),...x(m);
使用随机梯度下降更新判别其参数;
end for
从生成器前置随机分布pg(z)取出m个小批次样本z(1),...,z(m);
使用随机梯度下降更新生成器参数;
步骤一:固定生成器G,希望判决器D能正确判断1和0(训练D)
步骤二:固定判决器D,调整生成器G,使输出尽可能为1(训练G)
反复进行
通俗介绍就是:
(1)初始化生成器G和判别器D两个网络的参数
(2)从训练集抽取n个样本,以及生成器利用定义的噪声分布生成n个样本。固定生成器G,训练判别器D,使其尽可能区分真假
(3)循环更新k次判别器D之后,更新一次生成器G,使判别器尽可能区分不了真假。
多次迭代后,理想状态下,最终判别器D无法区分图片到底来自真实的训练样本,还是来自生成器G生成的样本,此时辨别的概率为0.5,完成训练。
四、训练GAN的一些技巧
-
输入为(-1,1)之间的随机噪声,最后一层的激活函数使用tanh(BEGAN除外)
-
使用wassertein GAN的损失函数
-
如果有标签数据的话,尽量使用标签,也有人提出使用反转标签效果很好,另外使用标签平滑,单边标签平滑或者双边标签平滑
-
使用mini-batch norm, 如果不用batch norm 可以使用instance norm 或者weight norm
-
避免使用RELU和pooling层,减少稀疏梯度的可能性,可以使用LeakyReLU激活函数
-
优化器尽量选择Adam,学习率不要设置太大,初始1e-4可以参考,另外可以随着训练进行不断缩小学习率;优化器不要使用SGD,因为GAN的纳什均衡点是一个鞍点,但SGD只会找到局部极小值,容易使GAN训练不稳定。
-
给D的网络层增加高斯噪声,相当于是一种正则
(其实,这里给到的相关训练技巧就是GAN的一些变种,接下来会进行详细介绍)
五、GAN的改进策略
关于GAN目前暴露出来的缺陷,很多学者提出了相应的改进策略。常见的有CGAN、DCGAN、ACGAN、LAPGAN、EBGAN、WGAN等。
六、 DCGAN
6.1 DCGAN介绍
DCGAN的全称为deep convolutional generative adversarial networks,其论文可参考《Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks》

与普通GAN相比,DCGAN有如下改进以克服GAN的缺陷:
- 所有pooling都用strided convolutions代替,pooling的下采样是损失信息的,strided convolutions可以让模型自己学习损失的信息
- 生成器G和判别器D都要用BN层(解决过拟合)
- 把全连接层去掉,用全卷积层代替
- 生成器除了输出层,激活函数统一使用ReLU,输出层用tanh
- 判别器所有层的激活函数统一使用LeakyReLU
6.2 DCGAN应用案例
6.2.1 DCGAN用于生成图像变换

随着输入z的不断变换,输出图像会平滑地转变成另一副景象。如上图,每一行从左面第一张平滑迁移到右边,第六行从一个没有窗的我是逐步变成一个有大窗的卧室,第十行我们可以看到卧室中的电视逐渐转变为窗户。
其次,研究者对DCGAN网络内部层进行了可视化。我们知道传统的有监督式的CNN网络通常在中间层中能够学习到某些事物的特征,而对于无监督式的DCGAN在基于大量图片数据的训练后同样能够学习到很多有趣的特征。下图为生成对抗网络中判别器在训练后卷积层学习到的特征的可视化,其中可以隐约看出已经有了卧室中床和窗户的样子。

为了研究这些特征在生成器中的作用,研究者们故意把生成器中对应“窗户”的filter去除了,得到的结果非常有意思,在原来应该生成窗户的地方,最终生成的图像中都使用其他物品进行了替换。下图第一行是未经修改的生成模型产出的图片,第二行是移除了“窗户”filter层生成的对应图片,可以发现被修改后的生成器在不影响整体卧室场景的情况下悄悄地把窗户从画面中抹除了。

6.2.2 DCGAN用于生成图像的算术运算
此外,DCGAN还可用于图像的算术运算。这里引入一个类似概念——词嵌入。所谓的词嵌入是指将单词映射到一个低维度连续向量空间的技术,用词嵌入技术构成的词向量在空间中具备了一定的语义关系,含义比较接近的词在词向量空间中距离会比较近一些。一个比较直观的例子为:
V
e
c
t
o
r
(
"
K
i
n
g
"
)
−
V
e
c
t
o
r
(
"
M
a
n
"
)
+
V
e
c
t
o
r
(
"
W
o
m
a
n
"
)
=
V
e
c
t
o
r
(
"
Q
u
e
e
n
"
)
Vector("King")-Vector("Man")+Vector("Woman")=Vector("Queen")
Vector("King")−Vector("Man")+Vector("Woman")=Vector("Queen")
此外,谷歌tensorflow网站有一个Embedding Projector项目,可以实际感受词向量的可视化,地址链接:http://projector.tensorflow.org/。
同样,词向量计算思路也可以用于图像上,如下图所示:
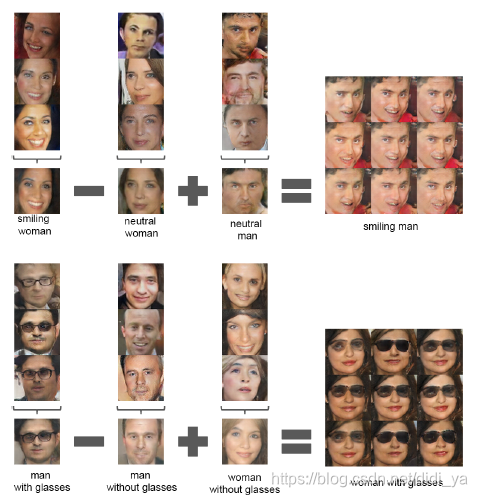
此外基于上述方法,我们还可以进行图像演变的制作,把某个图像的向量线性转换成另一个图像的向量时,对应的图像也会逐渐转移,如下图所示。

6.2.3 DCGAN用于残缺图像的补全
对于一张丢失某一部分的图像,人类可以依靠自己的想象能力知道完整的图像大概是什么样子,通过DCGAN的方法,机器也可以在一定程度上做到这一点。

上图是使用DCGAN进行图像补全的结果。每行包含五张图片:第一列是数据库原始图片;第二列是随机去除80%像素点的图片;第三列是使用补全方法对第二列修复的结果;第四列是原始数据中间被扣掉一大块的图片;第五列是使用补全方法对第四列修复的结果。
要使用生成网络补全图像需要满足两个条件:
- 使用DCGAN在大量头像数据训练后能够生成“骗过”判别器的照片;
- 生成图像与原图像未丢失部分的差值要尽量最小。
参考:https://arxiv.org/abs/1812.01071
6.3 DCGAN代码实战
利用DCGAN生成MNIST手写数字的Keras代码实战可参考文章:https://blog.csdn.net/didi_ya/article/details/115280757
七、Wasserstein GAN
7.1 WGAN介绍
WGAN全称为Wasserstein GAN,其论文可参考:https://arxiv.org/abs/1701.07875。在分析WGAN之前,我们先来看看GAN的缺陷 :
- G和D迭代的方式大部分情况都是局部最优解,无法生成全局最优解
- 不一定收敛,学习率不能高,G和D要共同成长,不能使其中一个成长太快
○ 判别器训练的太好,生成器梯度消失,生成器loss降不下去;
○ 判别器训练的不好,生成器梯度不准,四处乱跑 - 容易出现崩溃的问题,通俗的说,G找到D的漏洞,每次都生成一样的骗D
- 无需预先建模,模型过于自由,不可控
其原因通俗地讲主要是:
“生成器没能生成真实的样本” 惩罚小
“生成器生成不真实的样本” 惩罚大
因此,GAN偏向于生成“稳妥”的样本。
而WGAN从原理上解决了GAN的缺陷。
WGAN的改进主要有:
- 判别器最后一层去掉sigmoid
- 生成器和判别器的loss不取log
- 每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c,比如0.01
- 不要用基于动量的优化算法(包括momentum和Adam),推荐RMSProp,SDG也行
虽然WGAN在原始GAN的基础上只进行了少量改动,但是它的作用是巨大的。
数学表达式:

用Wasserstein距离代替KL散度,训练网络稳定性大大增强,不必拘泥于DCGAN的那些策略,这也是WGAN的优势所在。
下图为对应GAN与WGAN的判别器曲线示意图,左右两边蓝色和绿色的曲线分别代表了真实数据和生成数据,中间垂直阶梯式的红色曲线对应的是原始GAN的判别器,而中间有一定斜率的浅蓝色曲线则是WGAN的判别曲线。
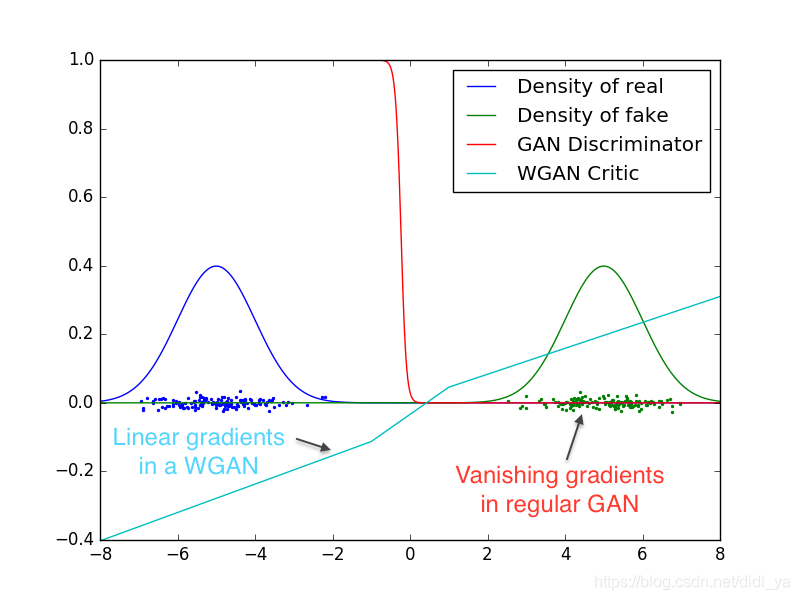
WGAN网络要做的事情是通过判别器的梯度来优化网络参数,让生成数据分布尽可能地靠近真实数据分布,而我们可以很明显地看到原始GAN在两个分布各自的区域所对应的梯度几乎为0,也就是所谓的梯度消失,非常难以对网路进行优化迭代,而WGAN对应的梯度则几乎是线性的,可以很好地达到真实数据分布与生成数据分布重合的目的。
【注】:WGAN虽然使用wassertein距离代替了JS散度,但是在生成文本上能力还是有限,GAN在生成文本上的应用有seq-GAN,和强化学习结合的产物。
(关于WGAN的详细介绍,强烈推荐这篇文章:https://zhuanlan.zhihu.com/p/25071913)
7.2 WGAN-GP
WGAN-GP即WGAN with gradient penalty,不再截断,而是增加惩罚项。其数学表达式为:

八、其他结构的GAN
8.1 EBGAN
EBGAN全称为:Energy-based GAN,加入编码器Enc和解码器Dec

8.2 总结
我们都在找寻一种完美的策略,但是研究人员发现,没有一种方法可以一劳永逸!!!具体问题具体分析永不过时。详情可参考如下博文:
Are GANs Created Equal? A Large-Scale Study
十、GAN的应用领域
1.GAN最常见且最普遍的应用是图像生成领域,其次在图像其他相关领域,如图像风格迁移、图像降噪等等都有很大的发展潜力。
2.GAN作为一种非监督式学习的典范,在该领域有着广泛的应用。
3.目前我正在研究的领域是GAN与控制结合,构建基于GAN的非线性系统辨识。
总结:GAN作为新兴的深度学习神经网络,可以说GAN的出现,给深度学习界带来了很多的研究(shui)课(lun)题(wen)。
参考
1.https://blog.csdn.net/Sakura55/article/details/81512600
2.https://blog.csdn.net/on2way/article/details/72773771
3.https://blog.csdn.net/qq_34218078/article/details/108666692
更多相关论文,可参考gan-zoo。


















 875
875

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











