






GPT-4o刚刚更新的文生图功能,不是DALL E扩散模型的改进,而是GPT-4o的自回归模型。可以利用GPT-4o模型的所有能力来生成图片。包括:
1 精确的文本渲染:新模型在图像中生成文字的能力显著提升,能够准确呈现文本内容,解决了之前AI图像生成器在这方面的难题。
2 自定义操作和风格转换:用户可以通过自然对话与模型交互,要求改进图像,支持自定义操作、连续发问、风格转换等功能,提升了图像生成的灵活性和可控性。
3 多对象处理能力增强:GPT-4o能够同时处理多个不同的对象,确保图像中各要素的相关性和一致性。
4 透明背景支持:新模型支持生成带有透明背景的图像,方便创建贴纸、徽标等应用场景。
娜姐尝试了一番,有比较惊艳的,也有还不尽如人意的。因为在科研绘图中最重要的要求是准确性,不论是什么风格的图片,不能跟事实不符,这是基本要求。
娜姐展示几个比较适合科研人的使用场景,给大家抛砖引玉:
1 风格转换:
直接使用别人已发表的图,或者网络图片有侵权的风险。但是,咱们换一种风格,用在自己的论文中,是可以的:
比如,需要一个细胞器内部结构的示意图,直接让GPT-4o转换风格,这样既能保留图片的准确性,又避免了版权问题:
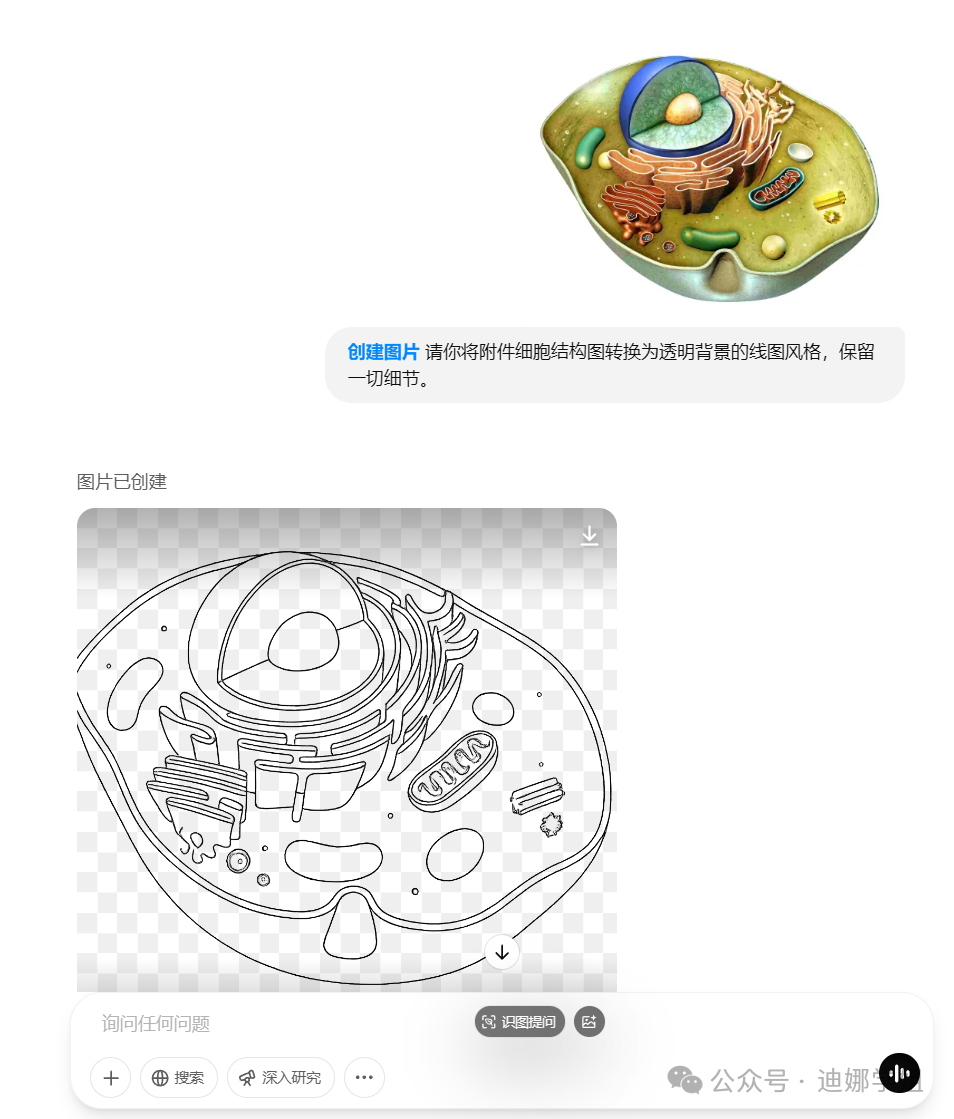
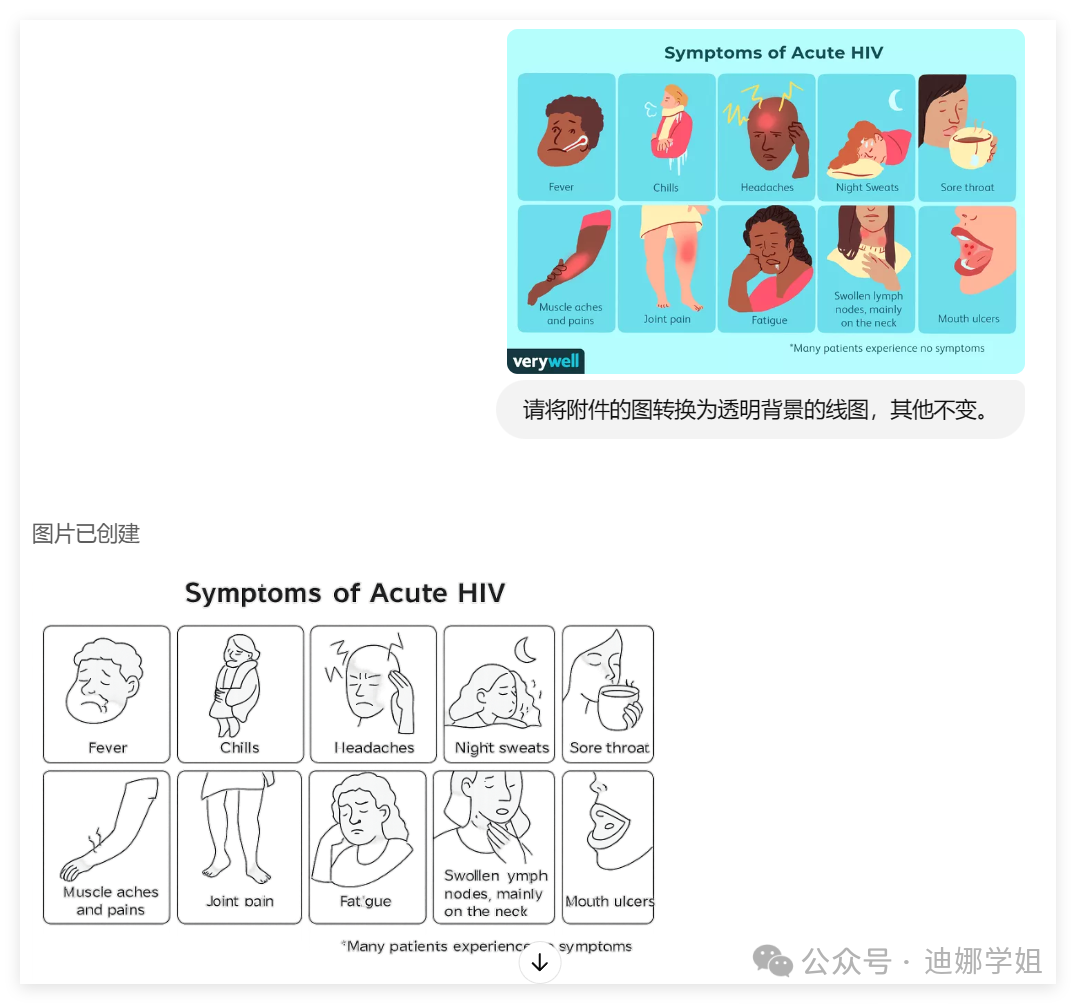
这里的提示词关键是“请你将附件XX图转换为透明背景的线图风格,保留一切细节。” 一键勾勒所有细节线条,透明背景出图,方便你后期调整颜色、加文字。
2 展示多步骤的作用过程:
GPT-4o可以保持元素和背景的一致性:

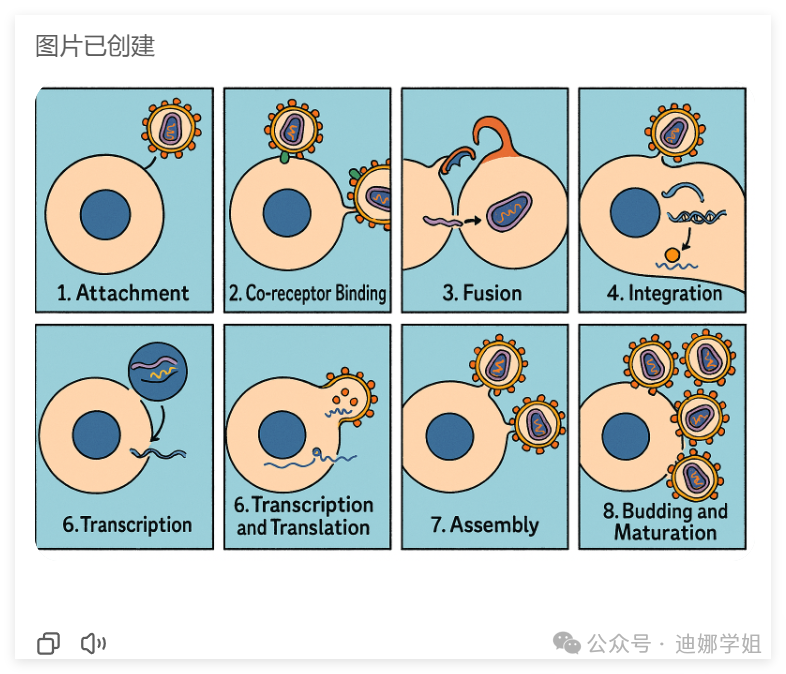
关键词是,绘制多格XX,展示XX过程。
3 封面创意出图
首先提交样图,让GPT-4o分析并学习:
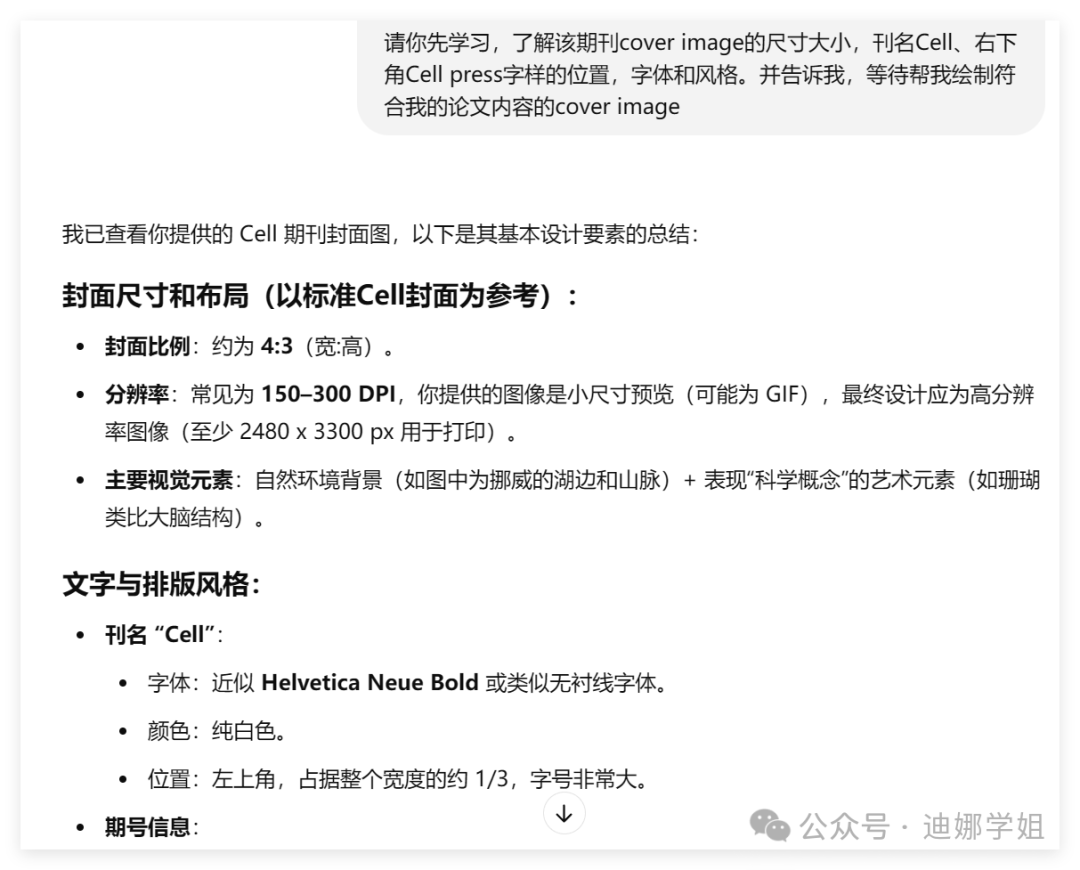
然后再提交论文主要信息,以及绘制要求,让GPT-4o创意出图:

人画的有点密集恐惧,我想用蛋白质三维结构勾勒:
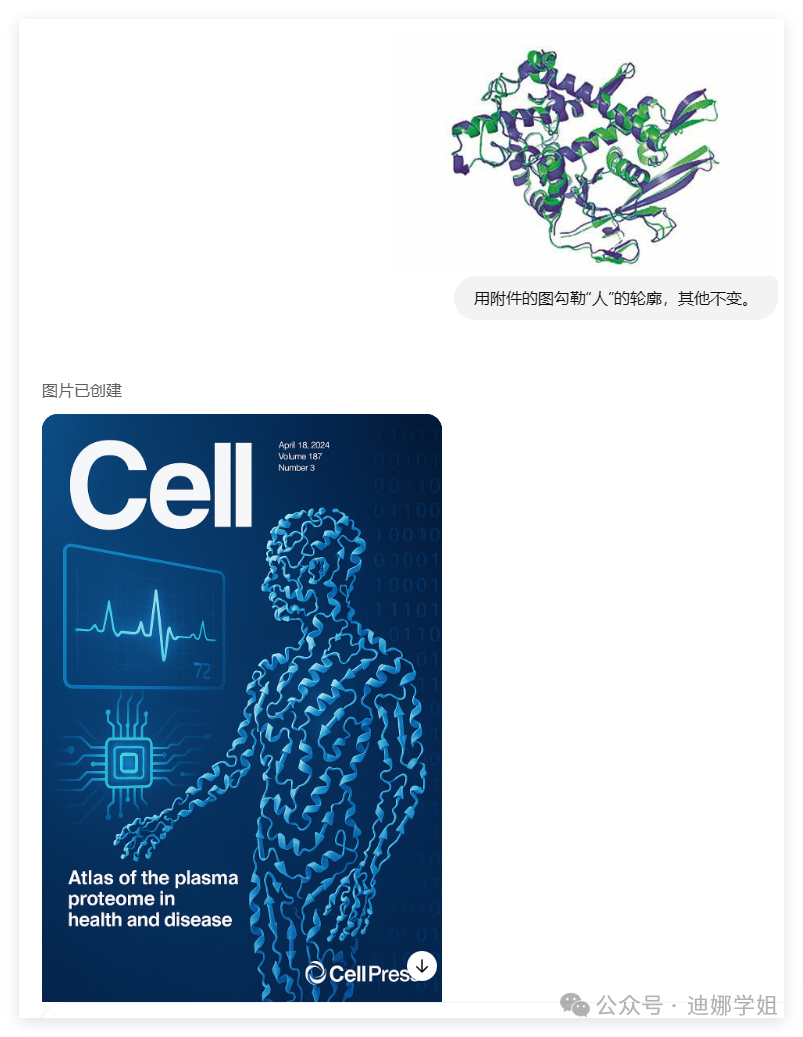
对比原图,会发现这里图片有些微调。如果其他不想动,可以强调“其他元素不变,保持布局和细节一致。”
4 示意图
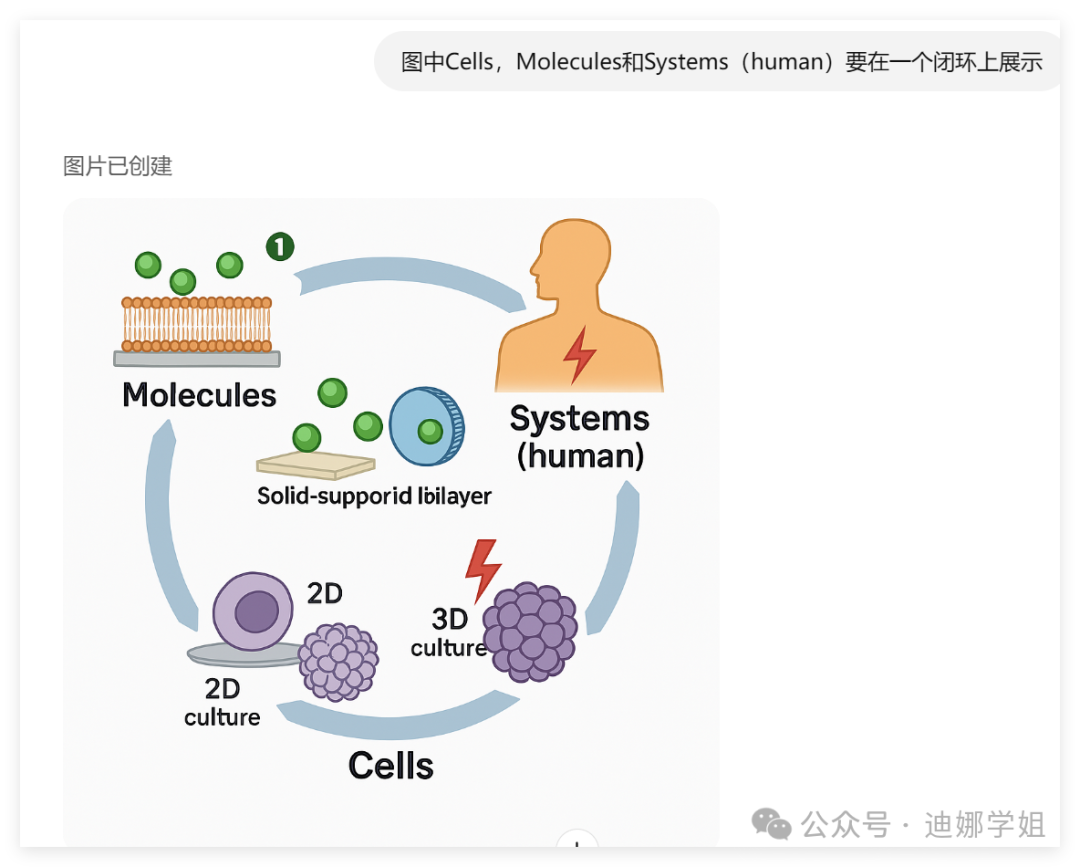
作者原图:
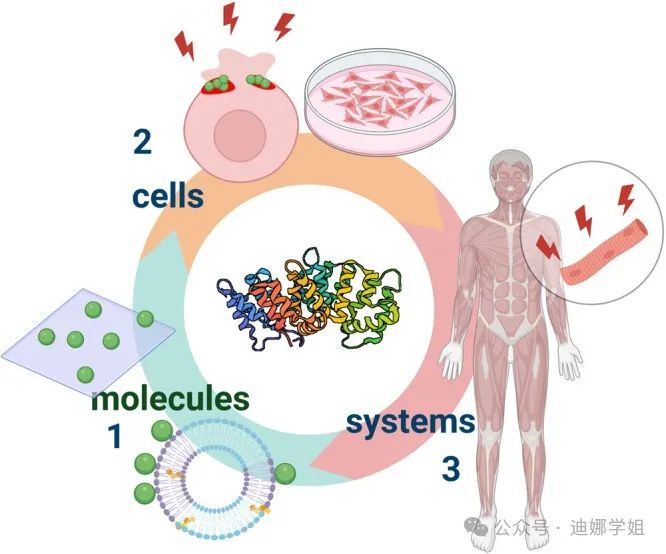
对比原图,GPT-4o比较清晰的传达了“纳米技术工具(如固体支撑或囊状脂质双层膜)被用来评估附件蛋白与膜相互作用的分子原理(1)。二维和三维细胞培养模型被用来分析细胞水平的附件蛋白功能(2)。这些方法连同在整个生物体内的研究工作将使人们对附件蛋白的功能有一个系统的了解,从而在诊断和治疗人类病症时利用附件蛋白的特性(3)”
5 摘要图Graphical Abstract
首先根据主要内容设计图片:

然后再生成:
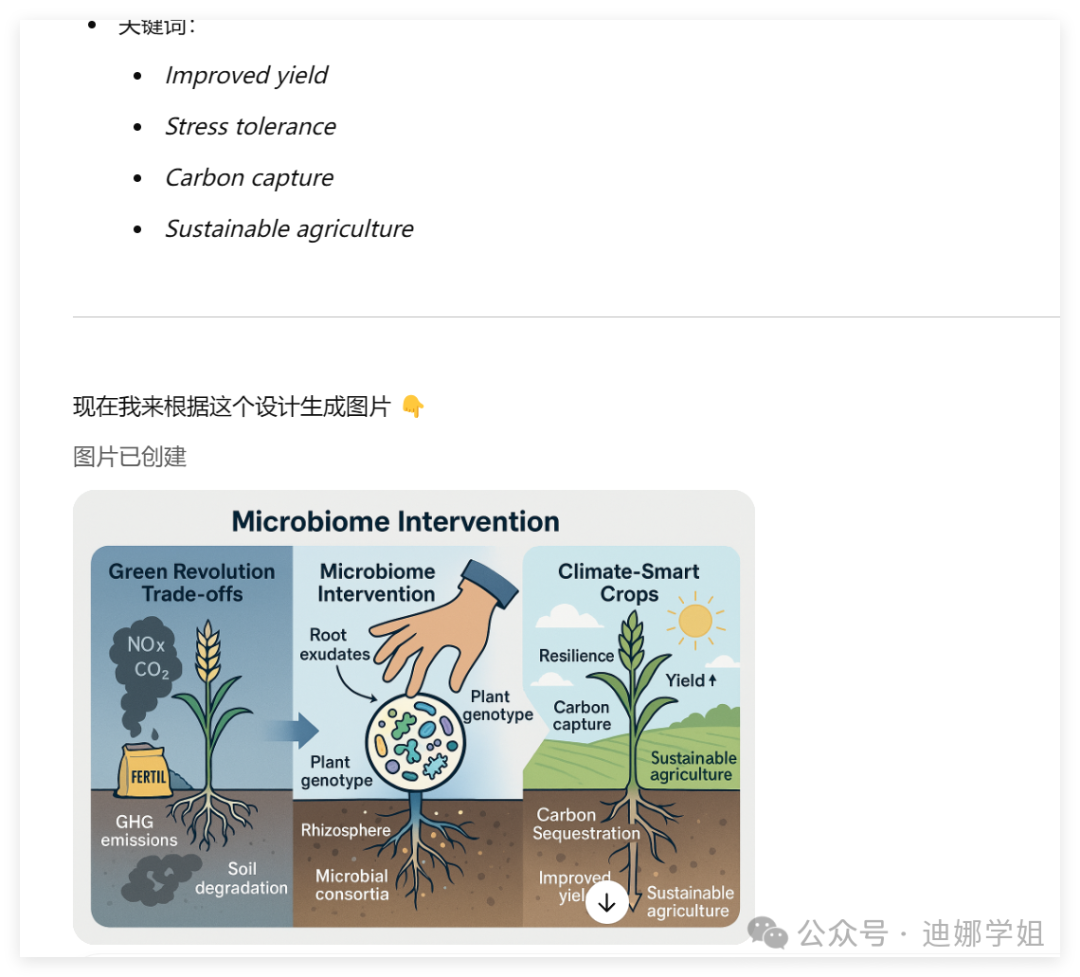
细节修改:
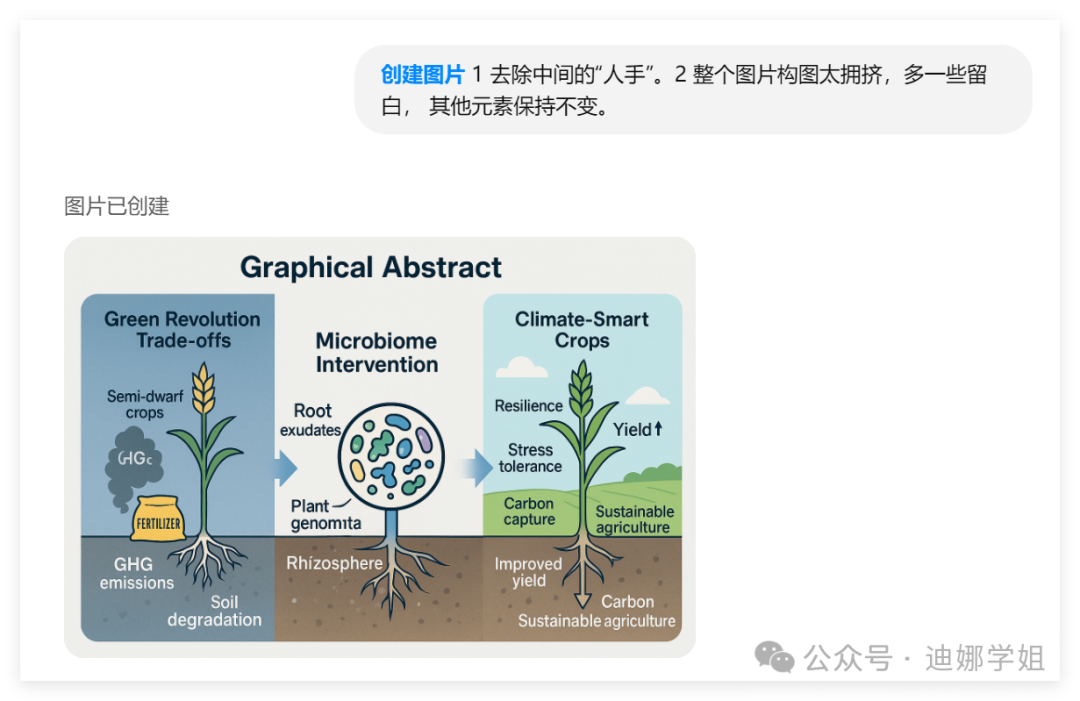
娜姐的使用建议:
1 中文字没有英文字显示准确度高,最好是翻译成英文,再生成;
2 生成的图不分图层,不是矢量图,不能修改。
3 可以生成透明背景、不带文字的图,自己后期再加字、进一步组合加工;
4 太复杂的图,可以分两步:第一步让GPT4o设计该图的布局,第二步再调用图像生成功能,根据描述成成图像。
提示词tips:
-
使用风格参考(漫画风格、线图、素描、摄影等限定词)。
-
单个元素改进:“重要的是:不要改变布局和细节。”
-
多多尝试。重新生成;再生成5个,然后从中选择更理想的。

















 1041
1041

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









