







 文章详细介绍了Transformer模型的核心组成部分,包括自注意力机制、多头注意力、位置编码以及Transformer的编码器和解码器结构。Transformer通过自我注意力来处理序列数据,解决了RNN在长序列依赖问题上的挑战,并通过多头注意力捕捉不同模式。此外,位置编码用于注入序列顺序信息,而BERT是Transformer的一个重要改进,结合预训练和双向Transformer,取得了很多NLP任务的突破。
文章详细介绍了Transformer模型的核心组成部分,包括自注意力机制、多头注意力、位置编码以及Transformer的编码器和解码器结构。Transformer通过自我注意力来处理序列数据,解决了RNN在长序列依赖问题上的挑战,并通过多头注意力捕捉不同模式。此外,位置编码用于注入序列顺序信息,而BERT是Transformer的一个重要改进,结合预训练和双向Transformer,取得了很多NLP任务的突破。
Vaswani et al. 在2017年发表了论文Attention Is All You Need,介绍了Self-attention以及基于前者的Transformer架构。我的栏目其他文章已经介绍了:seq2seq结构,经典的attention结构,QKV注意力机制,自注意力机制,多头注意力机制。以此为基础知识,现在讨论:Transformer。讲完了transformer,我后续有机会会讲一下BERT。
the Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence-aligned RNNs or convolution. – Attention Is All You Need
文章目录
1、自注意力
Self-attention, sometimes called intra-attention, is an attention mechanism relating different positions of a single sequence in order to compute a representation of the sequence. – Attention Is All You Need
在Attention机制里,是output sequence对于Encoded sequence的不同位置施加不同的注意力,还是有两个Sequences(Encoded sequence和output sequence),还是Seq2Seq的架构。
注意力机制有三个量 Q K V,通过一定的计算形式,Q和K计算相似度,然后用V作为参考进行输出,其计算形式作为一个算子被使用:
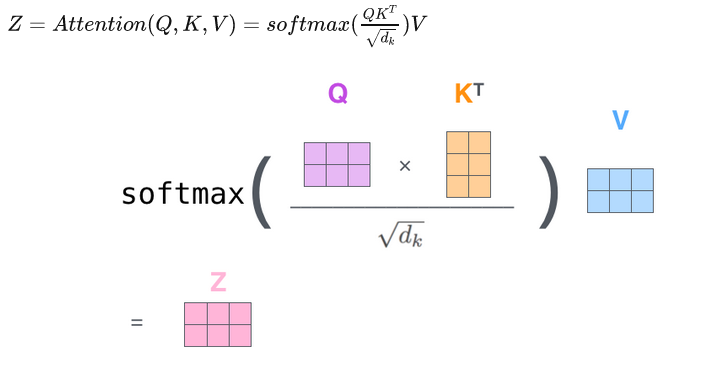
而Self-attention不同,它计算给定的input sequence各个位置之间彼此的影响力大小。注意力的计算在sequence内部进行,所以叫做Self-attention.具体见这篇文章的第三小节:【Attention】 自上而下的会聚式注意力,注意力机制怎么运行的?自注意力是什么,为何会产生?多头注意力机制是什么?
对于经典的注意力机制的公式:
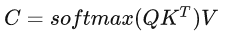
差别仅在系数√dk 。为什么要除以√dk ?作者说,如果不除以√dk ,当 dk 很大时,算法收敛变慢。他猜测道:We suspect that for large values of dk , the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients.
如果 Q K 的维度过大,它们的内积数值较大,使得softmax落在梯度较小的区间,会降低优化速度。
2 Multi-Head Attention
用了许多对 Q K V ,组成了Multi-Head Attention。作者希望通过Multi-Head Attention类比CNN中多个卷积核的效果,捕捉不同的模式。
Vaswani用了8组WQ WK WV ,因此也有8组Q K V ,每一组都套用self-attention的计算方法,可以得到8个向量Z0,Z1…Z7:
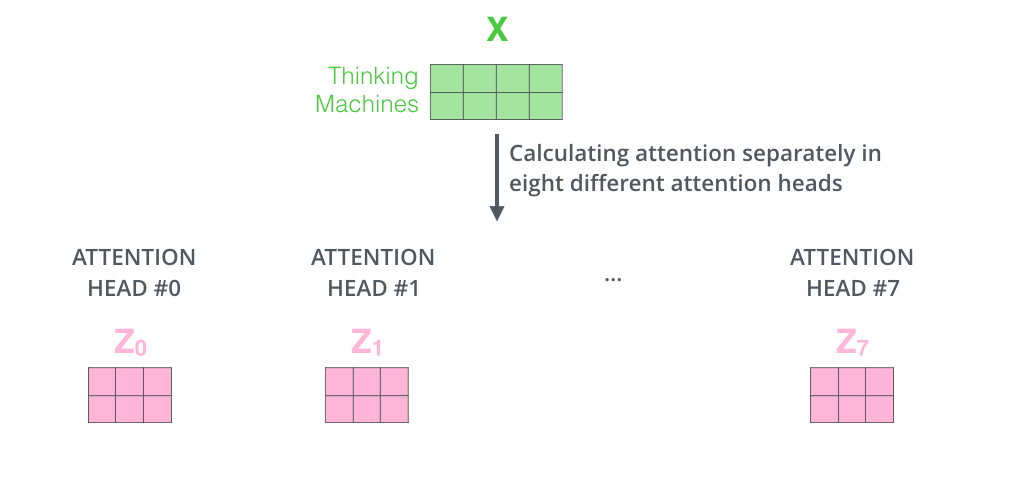
把它们在水平方向上堆叠起来(concatenate),再乘以一个矩阵Wo ,得到整合了所有attention heads的总输出。用公式表达:
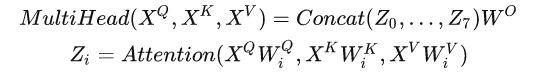
再来看公式,用来计算 Q K V 的输入 X 可能不是同一个。应该是所有的X 想换之间都需要算相似性,因此至少是O的3次方,O(3)。
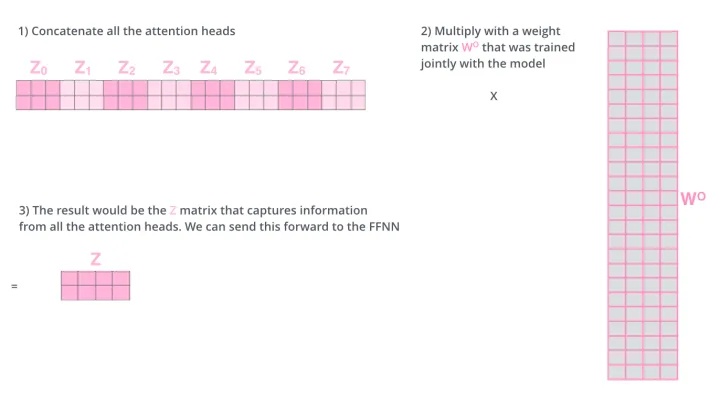
水平堆叠后,乘以矩阵W_O
Multi-Head Attention 整体图
这个流程还算是比较好理解的,水平过程为数据流动,从1–>5。先有
1、输入Thinking Machines,
2、然后进行embed得到X,
3、8组WQ WK WQ 得到8组Q K V,
4、然后计算注意力Z0 Z1 … Z7
5、然后用Wo相乘后得到输出 Z
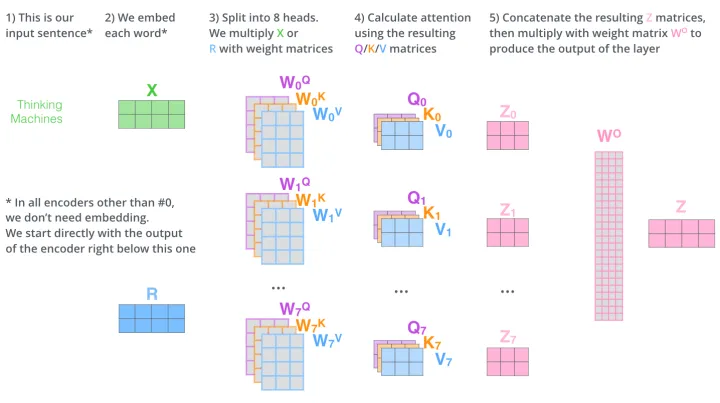
梳理一下维度:

4 Positional Encoding
Since our model contains no recurrence and no convolution, in order for the model to make use of the order of the sequence, we must inject some information about the relative or absolute position of the tokens in the sequence. To this end, we add “positional encodings” to the input embeddings at the bottoms of the encoder and decoder stacks. – Attention Is All You Need
不同于RNN架构,Transformer的self-attention结构并不能体现序列的顺序信息。为此,Vaswani在原来Input embeddings的基础上添加了positional encodings。后者的编码方式为:

5、参数个数计算
以四层 multi-head attention layers 为例,使用 Transformer 的默认参数,下图展示了计算可训练参数个数的细节(忽略偏置项以及 Normalization layer)。
虽然 Positional Encoding 也有参数,但这些参数不是可训练参数,不进行更新,故不计入。
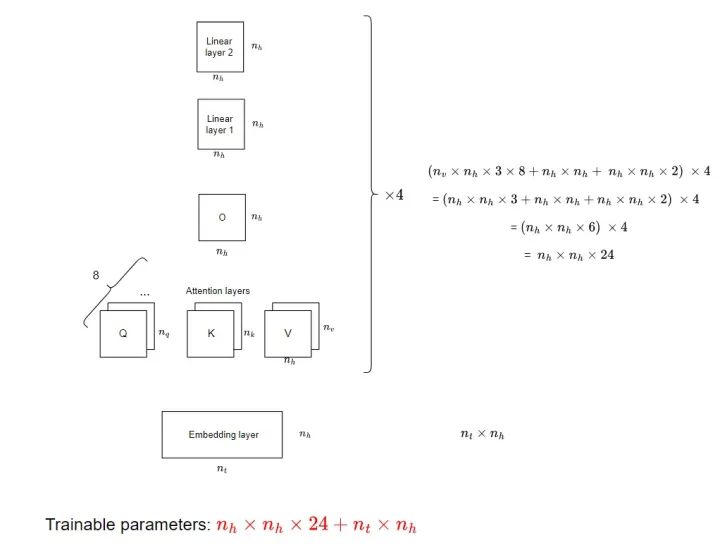
6、Transform(仅仅自注意力和前馈网络来进行编码和解码)
Transformer由Google Brain团队于2017年在论文Attention is all you need中提出,其将自注意力作为网络结构中的一层,采用seq2seq模型中的encoder-decoder框架,仅仅使用自注意力和前馈网络来进行编码和解码。如图1(a)(b)所示,Transformer的编码器和解码器都由6个小块组成,最后一级编码块的输出就是每一级解码块的输入,如图1©所示。
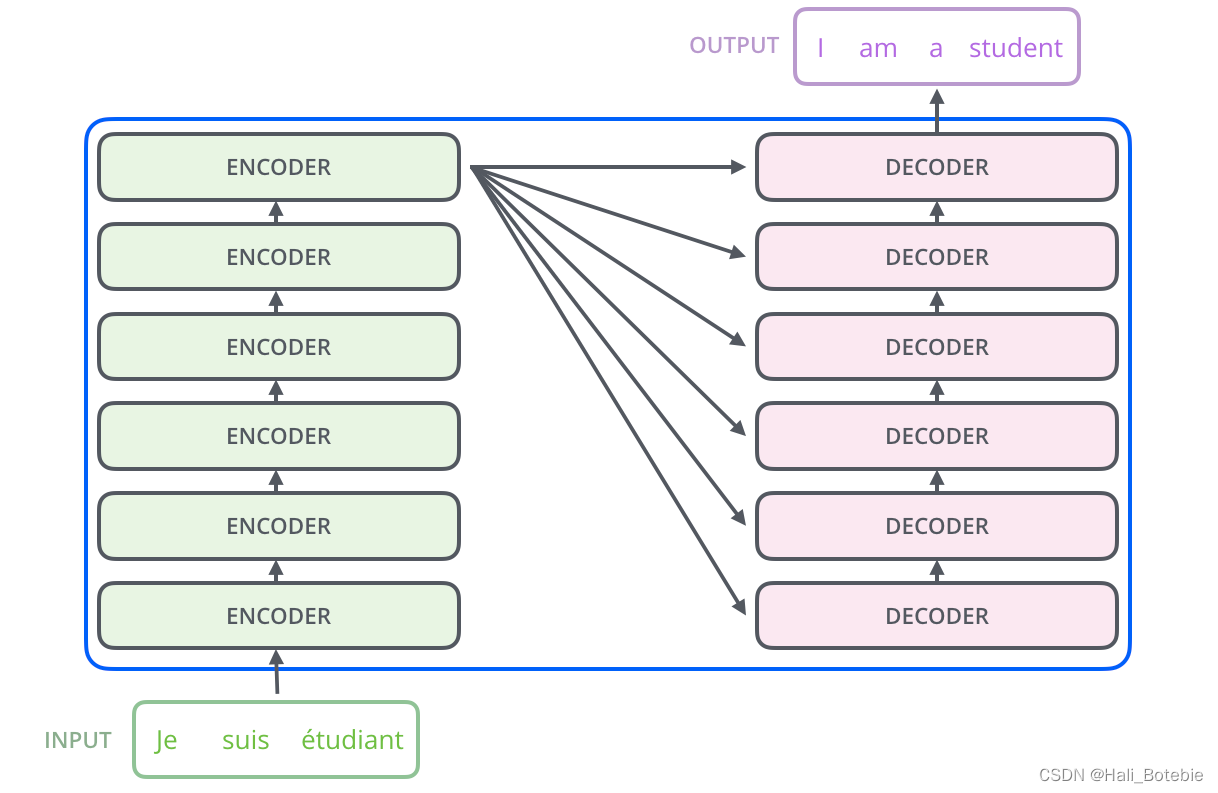
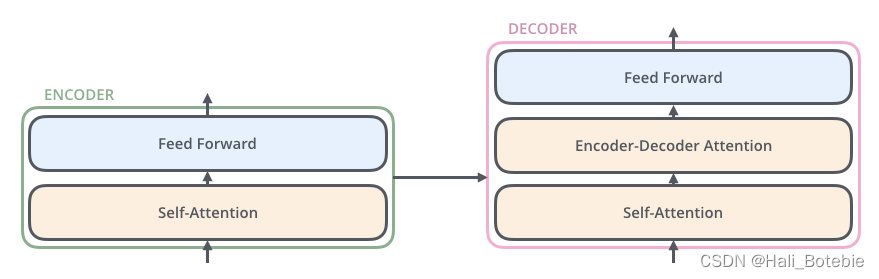
细说Transform 流程

这是Vaswani给出的Transformer架构,左边是Encoder,右边是Decoder,左右两边各有一些Multi-Head Attention layers。并且Encoder和Decoder之间也存在Multi-Head Attention layer。这就是论文中说的:
The Transformer uses multi-head attention in three different ways.
不同的Multi-Head Attention layer,它们的参数(WQ,WK,WV们)是相互独立,各自训练的。
Encoder
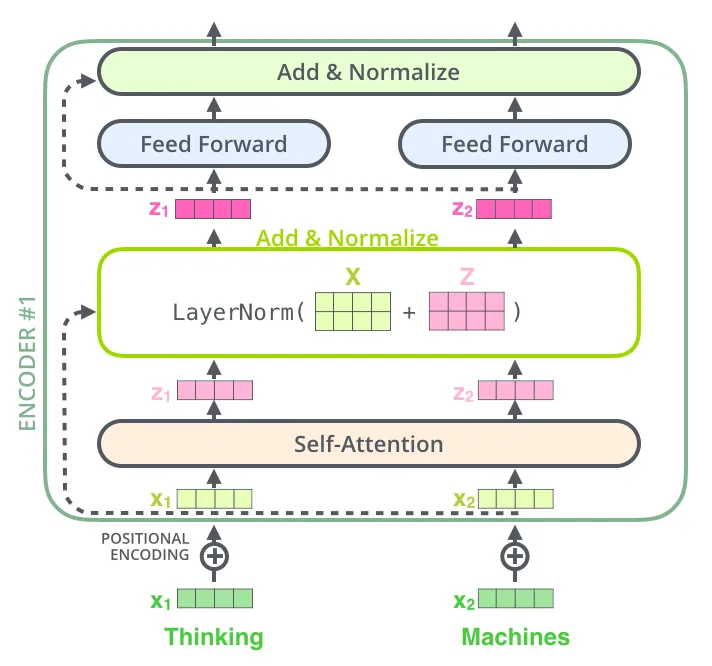
经过Embedding layer或者干脆使用已经训练好的word embedding, 得到Input embedding,与Positional Encoding相加后,作为 X 输入Encoder
注意看Multi-Head Attention,三个箭头分别代表query, key, value, 这里的意思是,三个矩阵都等于input 。
再看红色圆圈,它借用了ResNet跳接的思想,在Multi-Head Attention Layer输出 Z 的基础上,直接加上原输入X (对应元素相加,而不是堆叠)。经过Layer Normalisation,后接一个前馈神经网络,并搭配跳接结构。以上重复N次,构成Encoder。
Decoder
decoder 是输入的真值,具体为:这对应着Seq2Seq的Teaching forcing mode.
所谓Teacher Forcing,就是在学习时跟着老师(ground truth)走!
它是一种网络训练方法,对于开发用于机器翻译,文本摘要,图像字幕的深度学习语言模型以及许多其他应用程序至关重要。它每次不使用上一个state的输出作为下一个state的输入,而是直接使用训练数据的标准答案(ground truth)的对应上一项作为下一个state的输入。不明白的看看文章,对比下seq2seq不同结构的差异三种传统Seq2Seq的框图,这篇文章也不错:一文弄懂关于循环神经网络(RNN)的Teacher Forcing训练机制
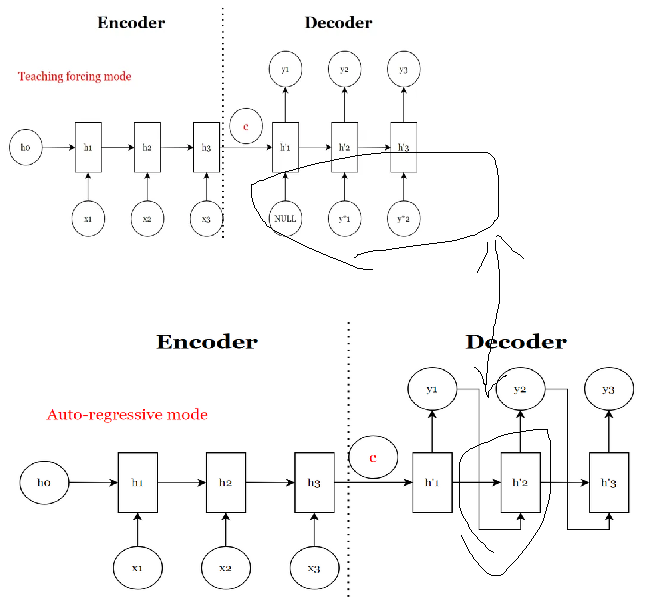
Decoder的输入是向右平移一位的Ground Truth. 什么意思呢?
如果我们要把I'm a student翻译成法语,那么就把对应的target sentence <SOS> Je suis un étudiant输入Decoder(第一个位置可以是标志句子开始的Start of sentence)。
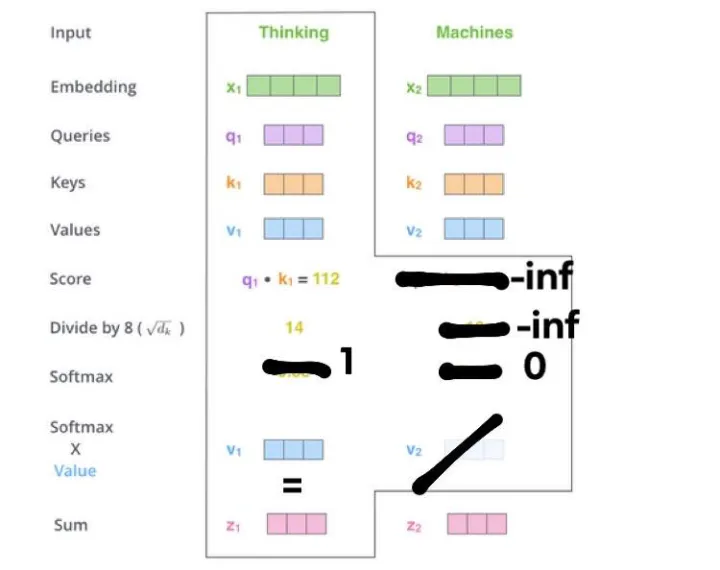
前半部分的Decoder结构和Encoder差不多一样,除了这个Masked Multi-Head Attention。所谓masked,是指某些东西被隐藏了。那么究竟隐藏了什么呢?
答案是future information. Decoder的输入是整个target sentence。在Multi-Head Attention layer里, 我们不希望前面的单词能够关注到后面的单词。比如,我们不希望Je能够关注到suis. 否则这就是“作弊”了。解决方法就是,对于前面的单词,我们把后面单词的信息隐藏掉。如何实现呢?——把后面单词对应的score全部设为-inf。
Encoder-Decoder
在Encoder-Decoder连接的地方,也存在着Multi-Head Attention layer。
左边Encoder的输出,它是作为key和value输入右边Multi-Head Attention layer的;
而后者的query由Decoder之前的输出决定。
Decoder之后,还跟着一个全连接层和softmax,用来计算各个位置最有可能出现的单词。
LayerNorm
Transformer采用了LayerNorm,而没有用BatchNorm。实际上,BatchNorm虽然在CNN中很常用,但它在序列模型中并不吃香,原因就是序列可能会长短不一,导致较大的均值和方差波动。
可以参考
暧暧内含光:BatchNorm and its variants
Dropout
训练过程中,Transformer 在两个地方采用了 Dropout layer:
We apply dropout to the output of each sub-layer, before it is added to the sub-layer input and normalized.
# https://github.com/huggingface/transformers/blob/main/src/transformers/models/bert/modeling_bert.py#L353
# Normalize the attention scores to probabilities.
attention_probs = nn.functional.softmax(attention_scores, dim=-1)
attention_probs = self.dropout(attention_probs)
...
context_layer = torch.matmul(attention_probs, value_layer)
得到 attention weights 之后 apply Dropout;然后乘以 V:
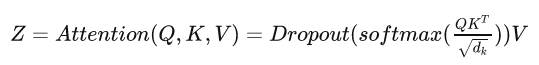
We apply dropout to the sums of the embeddings and the positional encodings in both the encoder and decoder stacks.
# https://github.com/huggingface/transformers/blob/main/src/transformers/models/bert/modeling_bert.py#L235
# Line 235
embeddings += position_embeddings
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
Summary
Transformer完全抛弃了RNN顺序结构,只用self-attention机制捕捉序列间的关联信息。这样一方面可以并行计算,另一方面解决了长序列的前后依赖问题。另外,Transformer为了添加顺序信息,在输入的时候专门添加了Positional embedding.
当然,除了Transformer架构,self-attention机制还有很大的用武之地。它可以和传统的RNN结合,比如分层注意力模型(Hierarchical Attention Networks, HAN),用来作文档分类(Document classification)。之后会专门介绍一下HAN。
Transformer之所以能够解决长期依赖问题,刻画更多的长距离相关,主要是因为引入了自注意力机制、残差前馈网络和多头机制,而Transformer中利用位置编码刻画时序信息的设计,还可以进一步改进。
Transformer借鉴了许多CNN中的思想。例如,multi-head attention和多卷积核是十分相似的,所不同的只是用注意力代替卷积;再例如,Tranformer使用了ResNet中的short-cut结构。这就使得Transformer具有了CNN擅长而RNN欠缺的能力,也就是刻画salient feature的能力。这一能力与RNN刻画时序特征的能力实现了互补,也使得Transformer不仅在序列数据(例如自然语言处理)中的许多问题得到应用,而且在矩阵数据(例如计算机视觉、推荐系统)等问题上也得到了广泛应用。
Transformer一个最出众的改进版本,也就是bidirectional encoder representation transformer(BERT),将预训练步骤同深度双向Transformer相结合,在自然语言处理的许多问题中取得了十分出色的成绩。
参考
https://zhuanlan.zhihu.com/p/577905764


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









