







论文标题:GLM-130B: AN OPEN BILINGUAL PRE-TRAINED MODEL
论文链接:https://arxiv.org/pdf/2210.02414.pdf
GLM-130B地址:https://github.com/THUDM/GLM-130B
ChatGLM-6B地址:https://github.com/THUDM/ChatGLM-6B
GLM-130B论文真的是yyds,建议原论文“全文背诵”,全文都是干货。
LLM系列主要会分享大语言模型,包括gpt1、gpt2、gpt3、codex、InstructGPT、Anthropic LLM、ChatGPT、LIMA、RWKV等论文或学术报告。本文主要分享ChatGLM(GLM-130B)的论文。
本文训练了千亿模型:GLM-130B,其性能与gpt3相当,上图显示了多个千亿模型在各个任务上的表现。 相比于百亿或更小参数规模的模型来说,千亿模型显得尤其难以训练,在训练过程中会遇到很多意想不到的技术与工程相关的问题,尤其是loss的激增和不收敛问题。
类似GPT3的千亿模型,他们的模型参数或者训练过程,公众都是很难获得的。训练如此一个高质量的大语言模型,并将其模型与训练过程分享给公众,这是一个非常有意义的事情。
本论文则完全开源了GLM-130B的参数、代码及训练过程,揭示了如何成功地预训练如此规模的模型。本文介绍了GLM-130B的整个训练过程,包括技术的选择、兼顾效率与稳定性的训练策略和一些工程问题。
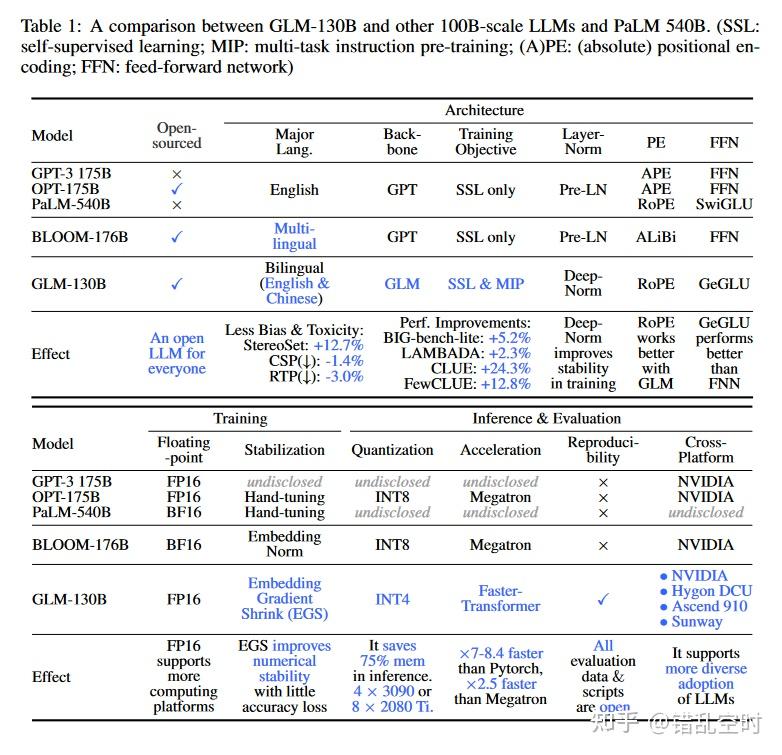
如上表所示,论文比较了GLM-130B与其他千亿模型在开源方式、模型结构、训练过程、推断和评估方面的异同。可以看出,GLM-130B在模型结构上选择了较为不同的方向,放弃了普遍选用的GPT类的框架,而是使用了带有双向注意力的GLM【1】结构;推断方面,可以看出这是第一次将千亿模型量化到int4层次,并且在没有量化感知训练的条件下,性能损失也很少,这让模型能够在4块3090(24G)或8块2080Ti(11G)就可以推断GLM-130B模型;可复现性也很显眼,GLM-130B从预训练到评估都是可复现的,所有评估代码也是开源的。当然,跟其他千亿模型相比还有很多的异同,下文会一一介绍模型整个训练过程中的困难与选择。
GLM-130B的技术选择
tokenization
本论文在icetk的基础上做了简单调整,icetk有150000个token,前20000个是给图片token使用的,其他的是文本token。本论文只使用了后面的130000个文本token,将换行符\ntoken 转为了<n>,并新增了MASK、gMASK、eop、eos、sop等token。
GLM结构
大都数千亿模型多是使用的传统的GPT结构,本文反而想探索下双向GLM【1】模型结构的潜力,所以选择了GLM作为基础结构。 GLM基本遵循transformer框架,layer-norm和残差的执行循序做了调整,token的预测也只用了一层简单的线性回归,并用GeLU代替了ReLU 激活函数,主体思想如下图所示。

如图中a部分搜索,是一个文本序列,其中x3、[x5 x6]是选中的两个span,论文会将这个文本分成两个部分,如图中b所示,第一个部分(Part A)会保留所有上下文信息,但会用[M] 替代选中的span部分,第二个部分(Part B)是被随机打乱的span部分(【1】中的消融实验中显示,随机打乱span可以提高效果);
图中c部分可以看出,GLM是通过自回归的方式预测span部分,每个span都是以[S]开始,预测到 [E]结束,预测时是不知道该span的长度的;图中还显示了GLM的Position策略,包含两个维度,第一维是显示该token在Part A部分的位置(每个span都是显示[M]在Part A中的位置),第二维是显示每个span中的token在自身span中的位置,Part A的文本该维度全部为0,需要注意的是,GLM-130B并不是使用的这种位置编码策略,下文会详细介绍;
图中d部分可以看出GLM的attention策略,可以看出Part A部分的文本完全是个双向的attention结构,Part B部分则是从左到右的单向attention结构,就是说A部分的文本之间可以互相看到,但看不到B部分的文本,B部分的文本可以看到全部A部分的文本以及当前token之前的文本,但看不到当前token之后的文本。
在GLM中span 的类型主要有三种,一类的比较短的短语,一类的相对长的句子,还有一类是比较长的段落或文章,在GLM-130B中只有两类,短的一类,长段落或文章一类。
GLM-130B的模型结构基本基于GLM结构,但在layer-norm、位置编码和FFN部分都略有改变,下面会一一介绍。
layer normalization
一个适合的层标准化有助于大预言模型训练的稳定性,本文分别实验了Post-LN【2】(会导致transformer收敛慢且脆弱)、Pre-LN【3】(与Post-LN相比会降低最终的模型性能) 、Sandwich-LN【4】,不幸的是这些都不能提高GLM-130B训练的稳定性,如下图所示。
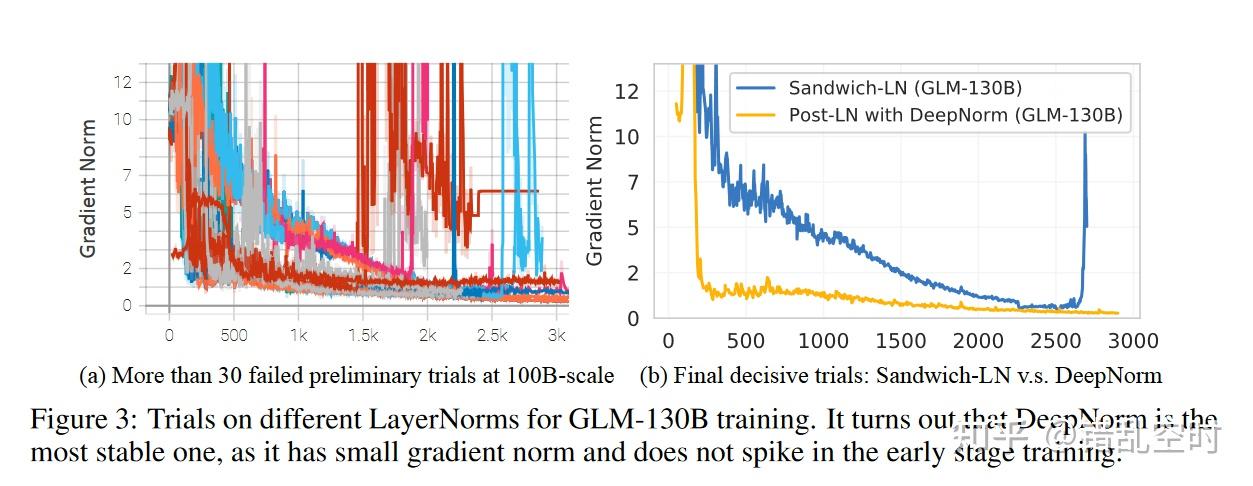 本文重点关注了Post-LN ,因为其有更好的下游性能,幸运的是,结合DeepNorm【5】方法(并且所有的bias都初始化为0),提高了模型训练的稳定性,公式如下所示:
本文重点关注了Post-LN ,因为其有更好的下游性能,幸运的是,结合DeepNorm【5】方法(并且所有的bias都初始化为0),提高了模型训练的稳定性,公式如下所示:
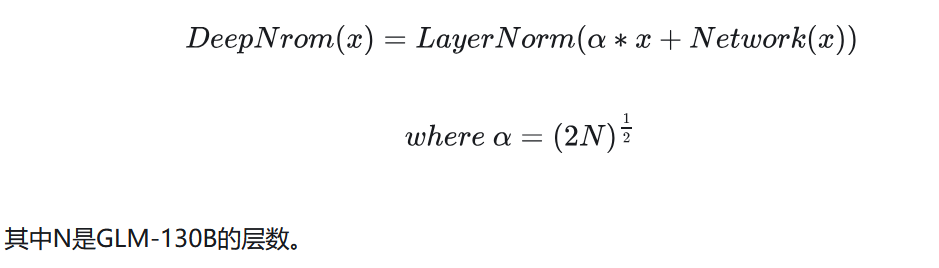
位置编码和FFN
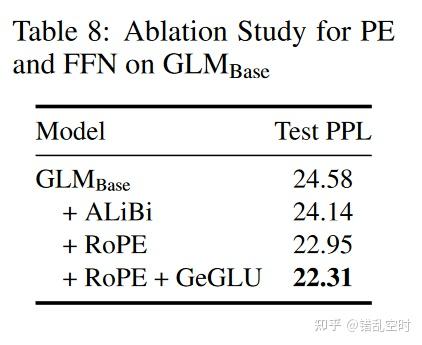
相比于绝对位置编码,相对位置编码能更好地抓住词之间的关系,本论文采用的RoPE【6】,则一是种使用绝对位置编码实现的相对位置编码,如下表所示,可以获得更好的模型性能。论文也尝试使用ALiBi的方式实现相对位置编码,但效果差于RoPE ,且运行效率更低。
在GLM-130B中为了实现RoPE,放弃了原始GLM 模型中的第二维位置编码,后来发现RoPE也是适用于二维编码的,但模型已经训练就没有改回来。
GLM-130B的FFN实现方式则如下公式所示,使用了带有GeLU的GLU【7】:

并行策略
GLM-130B有60天时间在96个DGX-A100(8*40G)的集群上训练,之前有研究表明,当前大部分大预言模型都是严重欠拟合的,所以主要目标就是让模型尽可能训练更多的token数。 论文最终采用的3维并行的策略:数据并行、张量模型并行和流水线模型并行策略。
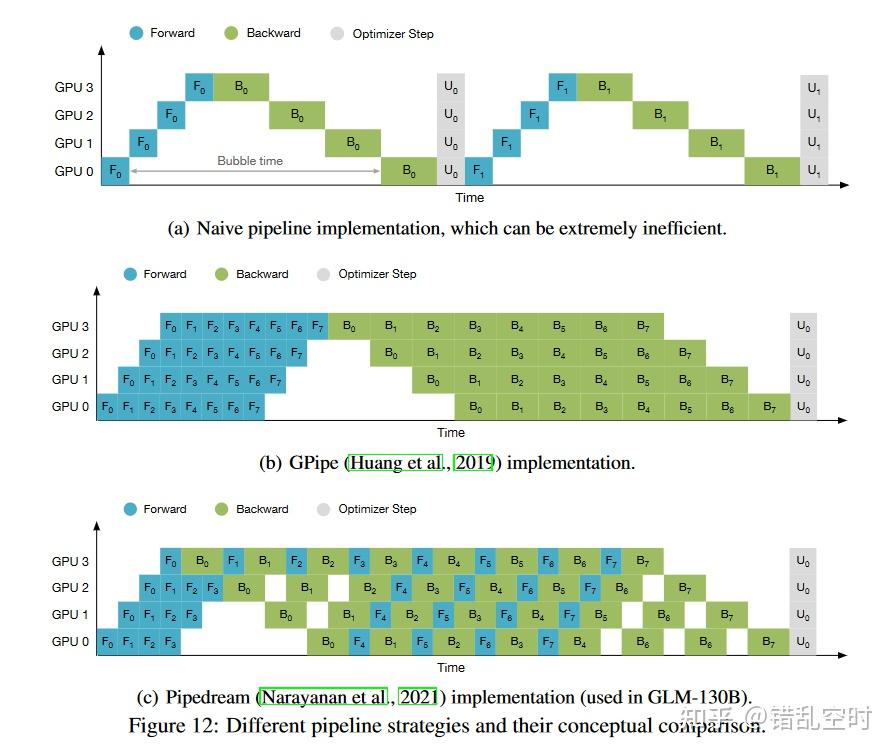
如上图所示,在pipline中有3种操作:前向计算(F表示)、后向计算(B表示)和优化步骤(U表示),原始的实现会导致大量的空泡;后续有研究者将数据切分为更小的batch,如图中b 所示;再之后有研究人员将前向和后向过程交织进行,进一步降低显存使用情况,如图c所示。原论文附录中有该部分内容更详细的介绍。
训练稳定性
训练稳定性和训练token的数量都是影响模型质量的重要因素,因此需要平衡训练效率和训练稳定性:低精度的浮点格式(如FP16)可以提高效率但也容易出现溢出错误而使训练崩溃。
混合精度训练:本论文采取了常规的混合精度训练【10】,前向和后向使用FP16,优化时和重要权重使用FP32。 采用混合精度,就会和OPT-175B/BLOOM-176B相似,在训练过程中会频繁遇到loss激增(如下图所示),OPT通过跳过一些数据和调整超参数来修复,BLOOM则通过embedding norm【21】技术来解决。
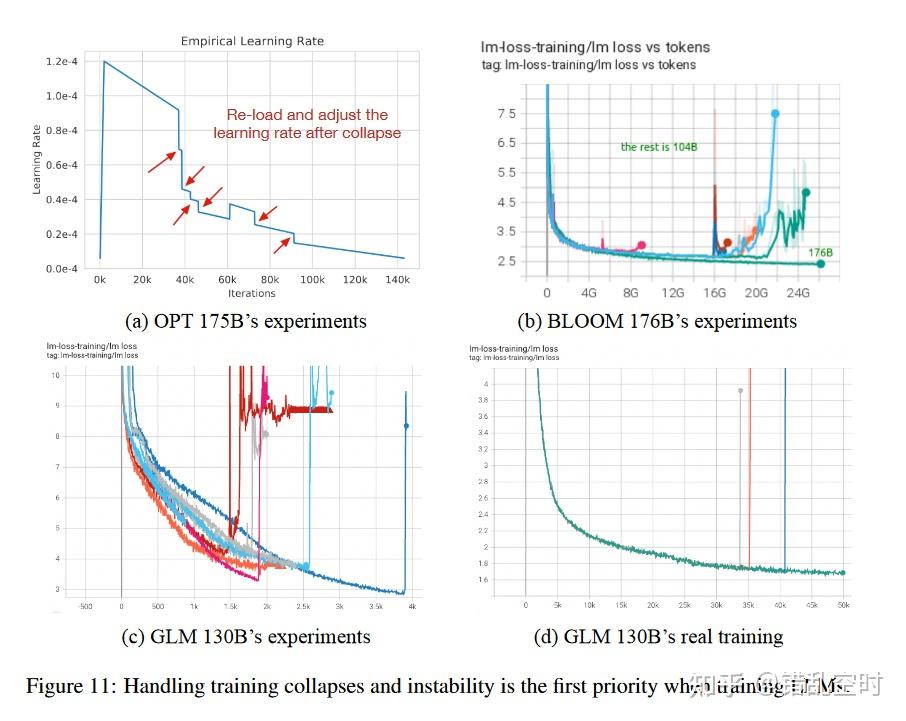
本文对loss激增的现象的研究发现,随着transformer类模型规模提高,一些问题出现了。
一是:如果使用Pre-LN,模型更深的层中有些参数值会变得极其大,本文通过DeepNorm和Post-LN 避免了这个问题。二是:注意力得分会随着模型规模增加而增加,以至于超过了FP16的范围,CogView【4】模型通过去除注意力计算中的极值来处理这个问题,但对GLM-130B不行,因为GLM注意力中的极值相对较多且比较重要;OPT【12】 模型使用BF16 格式,该格式在NVIDIA中有更宽的范围,但它比FP16多要15%的显存,且该格式在其他的一些GPU平台上并不能运行;BLOOM【13】通过使用BF16和embdding norm技术来处理,但这牺牲了模型的性能。
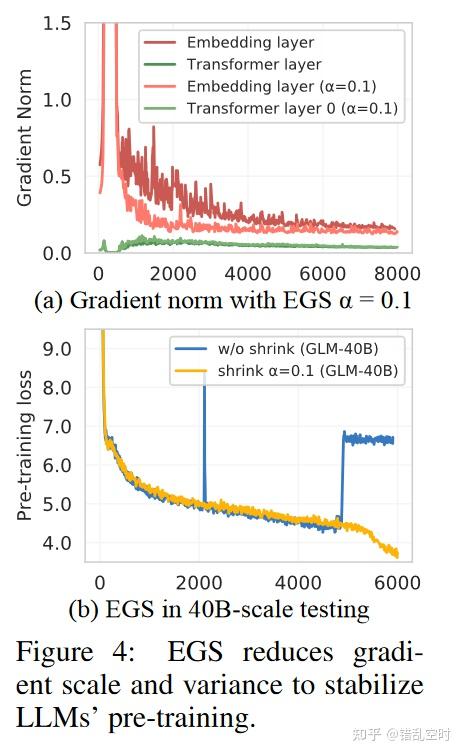
emb层梯度收缩:本文发现emb层梯度的暴增就会预示着loss的激增,并且在训练初期就会急剧增加,最终发现使用梯度缩减可以克服loss激增的情况,从而稳定模型的训练,其效果可见下图。后续的训练中,也只遇到了3次loss发散的问题(当然硬件问题也导致了很多次的失败),通过进一步缩减emb层梯度仍然可以帮助稳定模型的训练。
预训练设置
数据:预训练的数据包括1.2T的Pile【8】英文数据和1T的悟道中文数据【9】,以及从网页爬取的250G中文数据(包括在线论坛、百科全书和 QA)。
目标函数包含两个:自监督填空、多任务学习。
自监督填空:95%的token是这个任务内容,同时使用了[MASK]和[gMASK]两个形式。 [MASK]占比30%,空格的长度服从λ=3 的泊松分布,直至达到输入长度的15%(在论文【1】中表示,15%的量是能够保证下游任务效果的占比)。其他70%的token使用[gMASK],被遮蔽的长度服从均匀分布。
多任务提示预训练:占5%的总token数,输入如下表所示。有研究表明,在预训练中进行多任务学习比微调更有效果,所以本文也包含了大量的提示学习数据。
模型配置
为了能让模型以FP16的精度在单个DGX-A100(40G)上运行,隐藏状态维度采用GPT3的12288维,所以最终的模型参数量不能超过130B,因此得到了本论文模型:GLM-130B。其他的参数配置见下表:

推断
量化
本文也利用FasterTransformer【14】实现了GLM-130B,想进一步优化,就得进行量化操作。通常会将模型的权重和激活层进行int8量化,比如OPT-175B和BLOOM-176B 。这两个模型虽然激活层中也有极端值存在,但只有0.1%的特征维度有,可以通过矩阵乘法分解【15】来解决。但是GLM-130B的激活层中极端值比较多,大概有30%,这时候就上述方式就不好解决了。
因此本文只将模型线性参数进行量化,激活层仍然保持着FP16的精度;本论文使用训练后的absmax量化方式(能保持模型的性能效果,又比zeropoint量化方式计算高效);激活层保存时仍然保存量化结果,会在推断时动态还原回FP16精度,减少保存时的显存消耗。
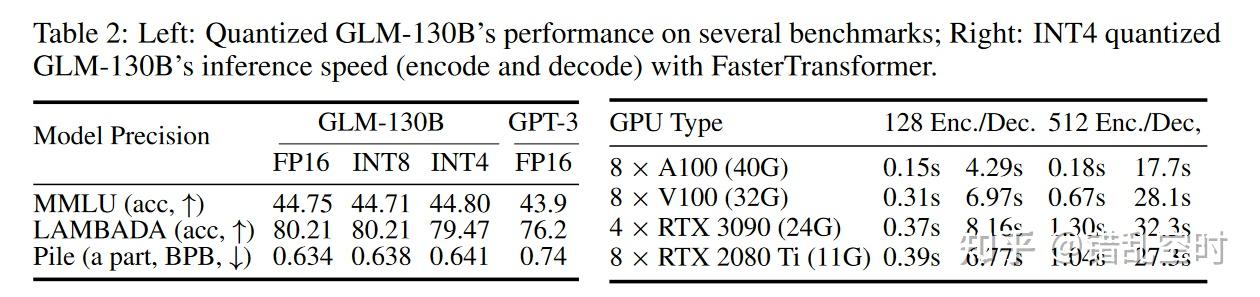
令人兴奋的是,本文还实现了int4量化,且没有需要进行后训练,如上表所示,显示了GLM-130B模型在各个精度下的模型效果与运行速度。显存上,int4比int8几乎可以减少一半显存,可以在43090Ti(24G)或者82080Ti(11G)上运行;性能上,int4版本的性能减少很少,基本保持了与GPT3类似的水平。
对权重矩阵量化时,只使用一个缩放因子往往会导致更多的错误,因为一个极端值就导致其他所有元素的精度下降。所以通常对矩阵的行或列进行单独量化,下表显示了不同大小模型不同量化方式的效果。
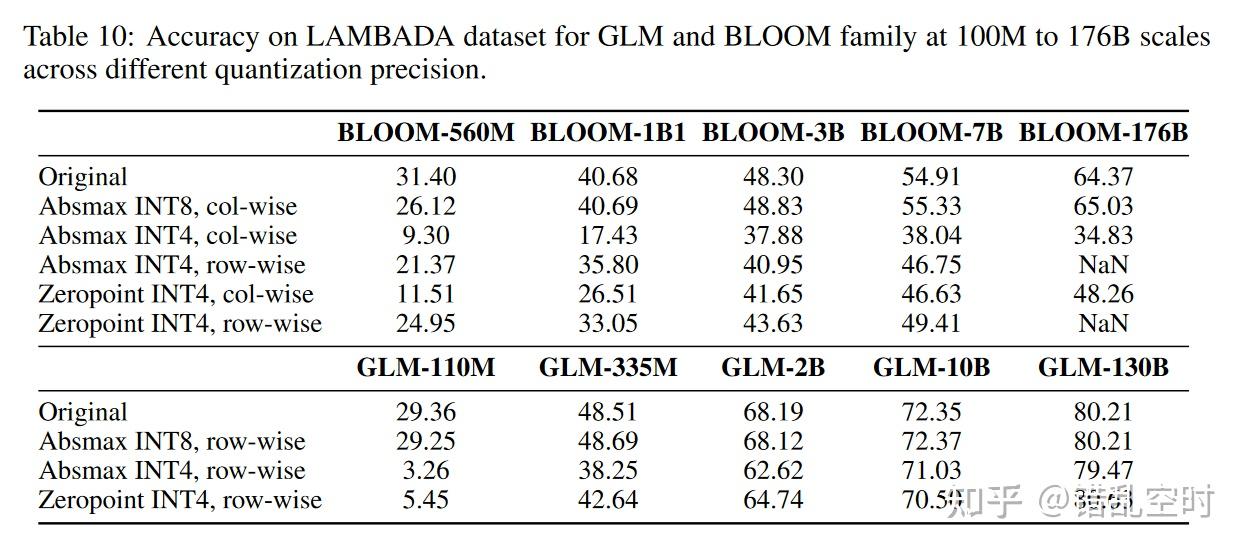 int4量化的规模效应
int4量化的规模效应
随着模型增加int4量化的性能损失逐渐降低,与BLOOM模型相比,损失就更少。论文也对此进行了研究,发现线性层参数分布得越宽,量化时就需要更多位数,导致模型的损失就越大,由下图可以看出GLM的分布宽度要远小于BLOOM。
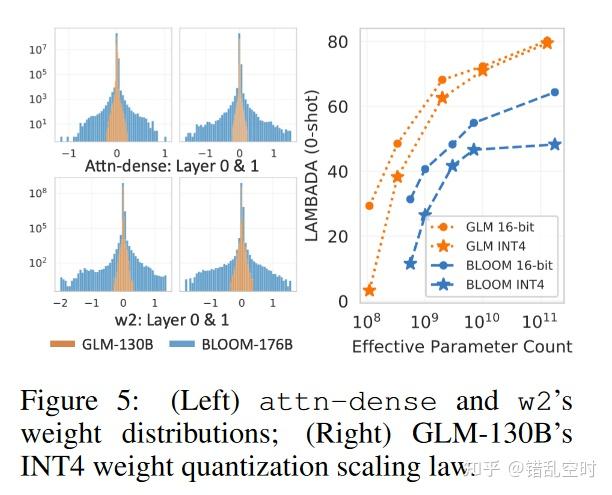
评估
论文分别在英文(LAMBADA, Pile, MMLU, BIG-bench)和中文(CLUE, and FewCLUE【16】)上进行了评估,以及道德评估(CrowS-Pairs, StereoSet, ETHOS, RealToxicPrompts)。评估内容这里不详细展示了,感兴趣的同学可以看专门的评估文章【17】,可能会更加客观。
ChatGLM
在GLM-130B开源之后,该团队又开源了ChatGLM-6B,该模型支持中英双语,是GLM【1】架构的,有62亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。
ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答,更多信息请参考他们的博客【18】。
后续,他们又继续发布VisualGLM-6B,一个支持图像理解的多模态对话语言模型;之后又发布WebGLM,支持利用网络信息生成带有准确引用的长回答;ChatGLM-130B也在测试中,在本文发布之时还没有完全公开。
ChatGLM-6B的开源,为中文大语言模型社区带来了新的活力,出现了很多基于ChatGLM-6B的开源项目,如:
JittorLLMs:最低3G显存或者没有显卡都可运行 ChatGLM-6B FP16, 支持Linux、windows、Mac部署。
InferLLM:轻量级 C++ 推理,可以实现本地 x86,Arm 处理器上实时聊天,手机上也同样可以实时运行,运行内存只需要 4G。
langchain-ChatGLM:基于 langchain 的 ChatGLM 应用,实现基于可扩展知识库的问答。
LLM_Custome【19】:在中文开源大模型的基础上进行定制化的微调,拥有自己专属的语言模型。
参考
https://zhuanlan.zhihu.com/p/617115816
论文之外
GLM-130B论文真的是yyds,建议原论文“全文背诵”,全文都是干货,与一些测评技术报告比起来,这种开源精神实在让人敬佩。之后开源的ChatGLM-6B也是为中文大语言模型社区注入了无限活力。希望以后有更多类似的论文,希望中文开源社区越来越好。
参考
【1】GLM: General Language Model Pretraining with Autoregressive Blank Infilling
【2】Attention is all you need
【3】On layer normalization in the transformer architecture
【4】Cogview: Mastering text-to-image generation via transformers
【5】Deepnet: Scaling transformers to 1,000 layers
【6】Roformer: Enhanced transformer with rotary position embedding
【7】Palm: Scaling language modeling with pathways
【8】The pile: An 800gb dataset of diverse text for language modeling
【9】Wudaocorpora: A super large-scale chinese corpora for pre-training language models
【10】Mixed precision training
【12】Opt: Open pre-trained transformer language models
【13】What language model to train if you have one million GPU hours?
【14】Accelerated inference for large transformer models using nvidia triton inference server
【15】Llm. int8 (): 8-bit matrix multiplication for transformers at scale
【16】Fewclue: A chinese few-shot learning evaluation benchmark
【17】Holistic Evaluation of Language Models
【18】https://chatglm.cn/blog
【19】https://github.com/wellinxu/LLM_Custome
【20】https://github.com/THUDM/ChatGLM-6B/blob/main/PROJECT.md
【21】8-bit optimizers via block-wise quantization


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









