






LiMoE: Mixture of LiDAR Representation Learners from Automotive Scenes
论文地址:https://arxiv.org/pdf/2501.04004
论文主页:https://ldkong.com/LiMoE
摘要
LiDAR 数据预训练提供了一种很有前途的方法,可以利用大规模、现成的数据集来提高数据利用率。然而,现有方法主要关注稀疏体素表示,忽略了其他 LiDAR 表示提供的互补属性。在这项工作中,我们提出了 LiMoE,这是一个将专家混合 (MoE) 范式集成到 LiDAR 数据表示学习中的框架,以协同组合多种表示,例如范围图像、稀疏体素和原始点。我们的方法包括三个阶段:(i) 图像到 LiDAR 预训练,将先验知识从图像转移到不同表示之间的点云;(ii) 对比混合学习 (CML),它使用 MoE 自适应地激活来自每个表示的相关属性,并将这些混合特征提炼成统一的 3D 网络;(iii) 语义混合监督 (SMS),它结合来自多种表示的语义逻辑来提高下游分割性能。在 11 个大型 LiDAR 数据集上进行的大量实验证明了我们的有效性和优越性。代码和模型检查点已公开。
1. Introduction
LiDAR 感知是现代自动驾驶系统的基石,可提供对导航和安全至关重要的精确 3D 空间理解 [26, 41, 56, 62]。然而,开发准确且可扩展的 3D 感知模型通常依赖于大规模、人工注释的数据集——这个过程既昂贵又耗费人力 [10, 24, 80]。这种依赖性在扩展自动驾驶系统方面造成了重大瓶颈,尤其是考虑到在现实世界的驾驶环境中产生的大量传感器数据 [52]。
最近,数据表示学习(data representation learning)已成为解决这一挑战的一种有希望的解决方案。通过利用大规模、易于访问的数据集,表示学习能够提取有意义的数据属性,而无需严重依赖人工注释 [3, 90]。这项研究的其中一条思路 [82, 94] 将点云扩展到不同的视图中,并在这些视图之间采用对比学习来确保特征一致性。另一条思路 [48, 50, 68, 85] 将知识从图像 [19, 27] 迁移到 LiDAR 空间 [15],促进跨模态学习以理解大规模 LiDAR 场景。然而,这些方法仅依赖于稀疏体素 [15],无法充分探索 LiDAR 场景中存在的互补信息。
LiDAR 数据可以转换成各种表示形式,即距离视图、稀疏体素和原始点,每种表示形式都有其独特的优势。距离图像提供了一种紧凑的 2D 表示形式,非常适合捕捉动态元素和中距离物体 [38, 55, 86]。原始点保留了精细的几何细节,可以精确建模复杂的结构 [32, 87]。稀疏体素可以有效地表示静态物体和稀疏区域,使其成为大规模环境的理想选择 [15, 30, 98]。利用这些表示形式的互补优势是实现稳健而全面的基于 LiDAR 的感知的关键。
在本文中,我们提出了 LiMoE,这是一种新颖的框架,它将三种 LiDAR 表示协同集成为一个统一的表示,用于特征学习。该框架分为三个阶段:1 图像到 LiDAR 预训练,其中来自预训练图像主干的知识被转移到每个表示的 LiDAR 点 [68, 85],初始化各种特定于表示的特征;2 对比混合学习 (CML),将跨表示的预训练特征融合为一个统一的表示,利用它们的互补优势;3 语义混合监督 (SMS),通过组合多个语义逻辑来增强下游性能。
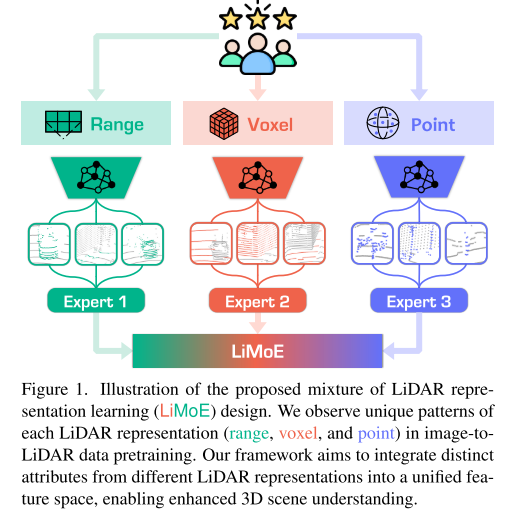
我们观察到,具有不同 LiDAR 表示的预训练模型会捕获不同的数据属性(见图 1)。距离图像主要关注中间的激光光束和距离,稀疏体素强调上光束和较长的距离,而点则捕捉下光束和近距离。为了有效地将这些互补的属性集成到统一的表示中,CML 采用了混合专家 (MoE) 层,可在预训练期间动态激活相关数据属性。通过将组合特征提炼为单一表示特征,CML 鼓励预训练网络包含来自各种表示的综合属性。
在下游阶段,我们观察到不同的表示模型捕获不同的对象属性。距离图像主要关注动态对象,稀疏体素强调静态背景结构,而点保留细粒度细节。为了进一步提高下游性能,我们将 MoE 层扩展到 SMS,它可以动态激活来自各种表示的相关语义特征。在语义标签的监督下,SMS 建立了一个强大且可扩展的框架,通过利用每个 LiDAR 表示中的互补语义特征来增强 3D 场景理解。
总而言之,这项工作的贡献如下:
• 我们提出了 LiMoE,这是一个通过 MoE 范式动态集成多个 LiDAR 表示的新型框架。据我们所知,这是第一项探索用于 LiDAR 表示学习的 MoE 的工作。
• 我们引入了一个三阶段管道来增强 LiDAR 场景理解,包括从图像到 LiDAR 的知识转移、单一表示预训练的数据属性混合以及下游任务的语义属性集成,这为 LiDAR 表示学习提供了一个强大的解决方案。
• 大量实验验证了我们方法的有效性,在 11 个数据集上取得了比最先进方法更大的进步,为开发可扩展、强大且可推广的汽车系统铺平了道路。
2. Related Work
LiDAR 数据表示。LiDAR 点云不规则且非结构化,对场景理解构成重大挑战 [24, 31, 52]。最近的方法试图通过将点云转换为结构化表示来解决此问题。基于点的方法 [32, 71, 87] 直接处理点云,保留其完整结构并能够捕获细粒度的细节。基于范围视图的方法 [18, 38, 55, 83, 86] 和基于鸟瞰图的方法 [11, 93, 96] 将点云转换为 2D 表示,利用图像处理技术有效识别动态或重要物体。基于体素的方法 [15, 30, 98] 将点云离散化为规则体素网格,并使用稀疏卷积 [17, 75, 76] 有效处理数据中的稀疏区域,使其适用于大规模环境。
多表示 LiDAR 分割。为了从各种 LiDAR 表示中获取全面的信息,最近的研究结合了多种表示来探索它们的互补优势 [49, 63]。AMVNet [46] 和 RPVNet [84] 采用后期融合策略,其中每个表示的特征被独立处理并在最后阶段融合。GFNet [64] 通过在不同阶段组合来自多个视图的特征引入了一种更先进的融合方法。UniSeg [47] 使用分层融合将低级特征与高级语义信息集成在一起。相比之下,我们的方法利用了混合专家 (MoE) 框架,该框架根据任务上下文动态激活来自多个表示的最相关特征。
图像到 LiDAR 数据预训练。受图像领域自监督学习成功的启发 [12, 28, 29],最近的研究探索了 3D 数据表示学习 [6, 69, 82, 94],但仅限于小规模场景的单模态学习。SLidR 框架 [68] 通过使用对比学习将 2D 图像知识转移到 3D LiDAR 模型,引入了多模态自监督学习。后续研究通过类平衡 [53]、混合视图蒸馏 [92]、VFM 辅助超像素 [48]、时空线索 [85] 等扩展了该框架。我们的工作在此基础上,将图像到 LiDAR 预训练扩展到多个 LiDAR 表示,从而捕获全面的 LiDAR 属性。
专家混合。专家混合 (MoE) 框架由多个子模型组成,这些子模型共同增强了模型的容量 [8, 21, 54]。MoE 根据输入动态选择要激活的专家子集,从而提高了处理各种任务的可扩展性和灵活性。这种方法在大型语言模型 (LLM) 中取得了广泛的成功 [20, 22, 45, 95, 97]。最近,MoE 已应用于视觉任务,包括图像分类 [14, 66, 70]、物体检测 [13, 33, 78] 和分割 [35, 61]。然而,MoE 在 3D 感知中仍未得到充分探索。在这项工作中,我们将 MoE 扩展到 3D 数据表示,实现多个 LiDAR 表示的动态融合,以改善场景理解。
MoE
MoE 全称
MoE 的全称是 Mixture of Experts(混合专家模型),是一种神经网络架构,其核心思想是:
- 多个专家(Experts):由多个子网络(即“专家”)组成,每个专家专门处理特定类型的数据。
- 门控/路由机制(Gating/Routing):通过一个路由网络(Router)动态决定每个输入应该分配给哪些专家,并加权组合它们的输出。
MoE 的目标是 提高模型的容量和效率,因为并非所有专家都需要对每个输入进行计算,从而可能减少计算量。
MoE 的典型应用
MoE 在以下场景表现优异:
- 大规模语言模型(LLM):如 Google 的 Switch Transformer、Meta 的 FairSeq-MoE,用于高效扩展模型参数。
- 多模态学习:不同专家可以处理不同模态(如文本、图像、点云)。
- LiDAR 数据处理(如您提到的场景):不同专家可以分别处理距离图像、稀疏体素、点云等不同表示。
如何优化 MoE 的速度?
如果 MoE 速度较慢,可以考虑:
- 调整专家数量:太多专家会增加路由开销,太少会降低模型容量。
- 优化 Top-K 选择:通常 K=1 或 K=2(只激活 1-2 个专家)能平衡速度和性能。
- 负载均衡:使用 辅助损失(Auxiliary Loss) 确保专家被均匀使用。
- 硬件优化:使用高效的 MoE 实现(如 DeepSpeed-MoE)减少通信开销。
3. Methodology
这项工作通过利用多种数据表示来捕获互补信息并增强 3D 场景理解来解决基于 LiDAR 的感知问题。我们首先描述三种常见的 LiDAR 表示并分析它们的优势(第 3.1 节)。然后,我们详细介绍了 LiMoE 框架的组件,如图 2 所示。这包括三个阶段:1 从图像到 LiDAR 数据的跨传感器知识转移(第 3.2 节);2 用于预训练的 LiDAR 数据属性的混合(第 3.3 节);3 由人工注释标签监督的语义属性的混合,用于下游分割任务(第 3.4 节)。
3.1. LiDAR Representation
令 P = {pi | i = 1, . . . ,N} 表示由 N 个点组成的 LiDAR 点云,其中每个点 pi ∈ R3+L 包括 3D 坐标 (xi, yi, zi) 和 L 维特征(例如强度、伸长率)。为了利用非结构化和不规则的点,各种方法将点云转换为中间表示,包括范围图像 Pr、稀疏体素 Pv 和原始点 Pp。
范围视图。范围图像方法将点云 P 投影到球面坐标中的 2D 网格上。每个点 pi 被映射到范围图像中的 2D 网格 (uri, vri),如下所示:
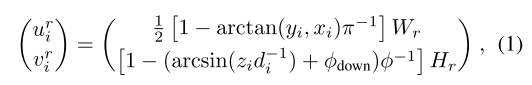
其中 di 表示点的深度;φ 表示传感器的垂直视场;φdown 是向下方向的倾斜角;Hr 和 Wr 是距离图像的高度和宽度。此投影产生距离图像 Pr ∈ RHr×Wr×(3+L),从而可以使用基于图像的技术进行高效处理。距离图像提供 3D 场景的紧凑 2D 表示,可捕捉几何和基于强度的特征 [38, 55]。它们在处理场景中的动态或重要物体时特别有效 [43, 86]。
稀疏体素。基于体素的方法将点云 P 离散化为规则体素网格 Pv,其中每个体素代表 3D 空间的一小部分。对于每个点 pi,其位置映射到相应的体素网格索引,即 [vxi, vy i, vz i] = [⌊xi/sx⌋, ⌊yi/sy⌋, ⌊zi/sz⌋],其中 (sx, sy, sz) 是沿 x、y 和 z 维度的体素大小。这种离散化导致稀疏体素网格 Pv ∈ RM×C,其中 M < N 是非空体素的数量。为了有效处理稀疏体素,采用了稀疏卷积 [15, 17, 75, 76],与规则体素网格相比,计算复杂度显著降低。稀疏体素特别适合表示大面积、人口稀少的区域,但由于量化效应,可能会丢失密集区域的细节[15,98]。
原始点。基于点的方法处理点云(即 Pp = P),而无需转换为其他表示形式。这些方法通常涉及三个关键步骤:1)从点云中采样一组中心点(质心);2)邻居搜索,其中根据空间接近度识别每个质心附近的点;3)特征聚合,其中 MLP 用于组合相邻点的特征并将其传播到质心。虽然原始点保留了场景的细粒度结构,但由于需要逐点操作,因此计算成本很高 [32, 87]。
3.2. Image-to-LiDAR Pretraining
图像到 LiDAR 预训练旨在将知识从图像转移到 LiDAR 数据,即使在没有大量 LiDAR 标签的情况下也能帮助学习有效的 3D 表示。先前的研究 [48, 53, 68, 85] 主要侧重于稀疏体素表示,因为它们可以为大规模 LiDAR 数据提供高效的处理。
给定一组 V 幅同步图像 I = {Ii | i =1, …, V} 及其对应的 LiDAR 点云 P,其中每个图像 I ∈ RH×W×3 具有高度为 H、宽度为 W 的空间分辨率。每个 LiDAR 点 pi 可以投影到相应的图像平面 (ui, vi) 上,如下所示:
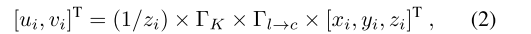
其中 Γl→c 是从 LiDAR 到相机坐标系的变换矩阵,ΓK 是相机本征矩阵。该预训练过程涉及两个关键步骤,如图 2 左侧(阶段 #1)所示。
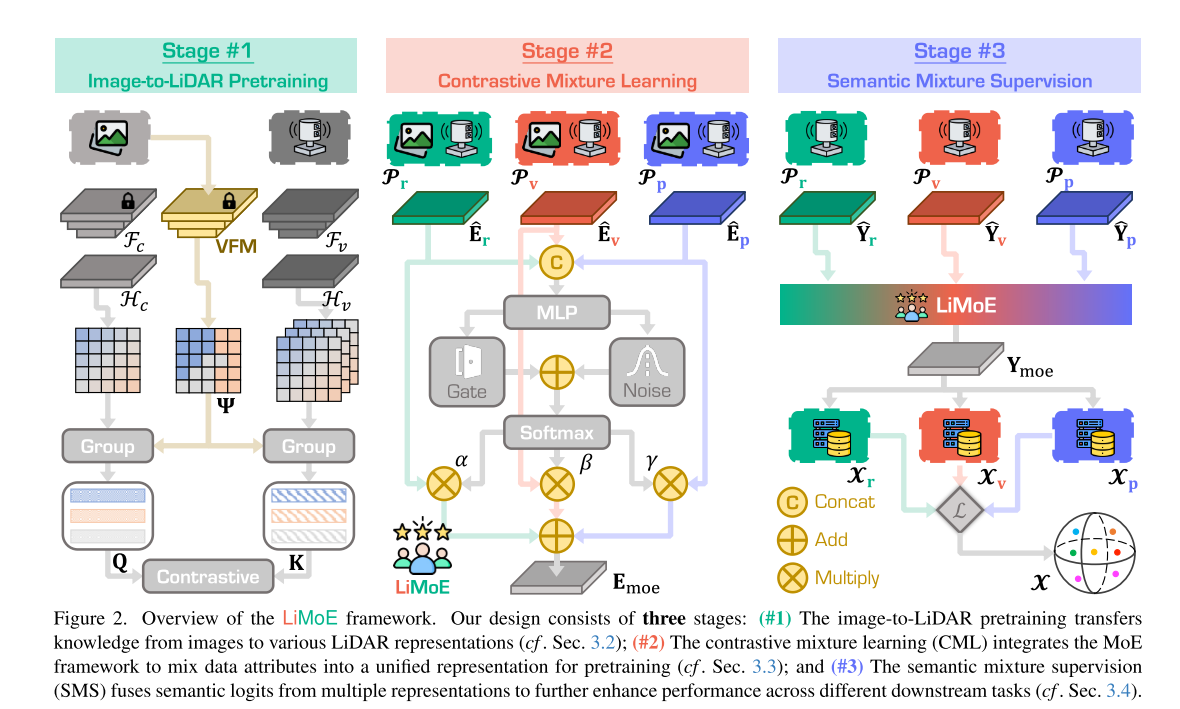
超像素和超点生成。为了建立图像和点云之间的相关性,先前的研究使用无监督 SLIC 算法 [1] 或视觉基础模型 (VFM) [36, 91, 99, 100] 为每幅图像生成一组 S 个超像素,表示为 Ψ = {ψi | i = 1, . . . , S}。然后通过使用等式 (2) 中的变换将这些超像素投影到点云上,得出相应的超点集 Ω = {ωi | i = 1, . . . , S}。
对比目标。为了将知识从图像转移到 LiDAR,图像和稀疏体素数据都会通过各自的主干:图像的 2D 预训练主干 Fc 和稀疏体素的 3D 体素主干 Fv。这将生成相应的图像和体素特征。然后,这些特征由线性投影头 Hc 和 Hv 处理,它们对齐特征空间并产生 D 维特征嵌入。然后根据超像素 Ψ 和超点 Ω 对图像和体素特征进行分组,从而得到超像素嵌入 Q ∈ RS×D 和超点嵌入 K ∈ RS×D。最后,应用对比损失以确保每个超点嵌入与其对应的超像素嵌入紧密相关:
其中 ⟨·, ·⟩ 表示超像素和超点嵌入之间的点积,τ > 0 是温度。
然而,基于稀疏体素的预训练在充分利用 3D 场景的详细几何和外观特征方面的能力有限。事实上,LiDAR 点云可以以多种形式表示,每种形式都强调场景内的不同属性,例如激光束、距离和静态/动态物体 [84]。为此,我们提出了一种新颖的预训练范式,该范式集成了 LiDAR 点云的多种表示形式。这种方法通过捕获不同表示中的几何和详细信息,可以更全面地理解场景,最终构建更丰富、更详细的 3D 环境表示。
3.3. CML: Contrastive Mixture Learning
我们通过为每个表示独立训练三个独立的 3D 网络来扩展图像到 LiDAR 的预训练方法:范围图像、稀疏体素和原始点。这些网络是我们 CML 方法的基础。如图 2 中间所示,每个网络以各自的表示形式处理点云:
继混合专家 (MoE) 方法 [45, 95] 取得成功之后,我们引入了一个 MoE 层,可以动态地选择和组合来自每个点的不同表示的相关特征。
特征对齐。如公式 (4) 所示,由于表示属性不同,从每个表示生成的特征存在很大差异。为了对齐这些特征,我们将范围图像和稀疏体素特征投影到点云空间中。
MoE 层。此层以 bEr、bEv 和 bEp 作为输入。为了结合这三种表示的特征,我们首先将它们连接起来,然后应用 MLP 层来减少通道维度。MoE 层由两个关键组件组成:门模块(动态选择每个点的激活表示)和噪声模块(引入扰动以防止过度拟合)。此过程可以表述如下:
这里,Zg∈RD×3 和 Zn∈RD×3 分别是门控和噪声模块的可训练权重。变量 χ 表示随机噪声分布,应用于噪声模块,为特征选择过程引入可变性。函数 σ 表示 Softplus 激活 [57],确保扰动保持正值且平滑。操作 [·,·] 表示特征串联。然后将 softmax 函数应用于门控值 G,得到选择分数 bG∈RN×3。然后,将这些分数分别拆分为每个表示的 α、β 和 γ,表示每个表示对每个点的重要性。通过对每个表示中的特征进行加权和求和,可以得到最终的输出特征:Emoe = αbEr+βbEv+γbEp。这些特征捕捉了每个表示的动态贡献,使模型能够自适应地优先考虑 LiDAR 点云中每个点的最相关特征。这种选择性特征融合使网络能够根据上下文利用每个表示的优势,从而提高其捕获详细场景属性的能力。
训练目标。在此阶段,目标是将来自多个表示的 MoE 特征提炼为单个 LiDAR 表示(范围、体素或点)。为此,我们使用 3D 学生网络提取相应的学生特征 Esl = Hs l (Fs l (Pl)) (l ∈ {r, v, p})。然后,根据超点对 MoE 特征和学生特征进行分组,以生成超点嵌入 Kmoe 和 Kl。然后在它们之间应用对比损失,如下所示
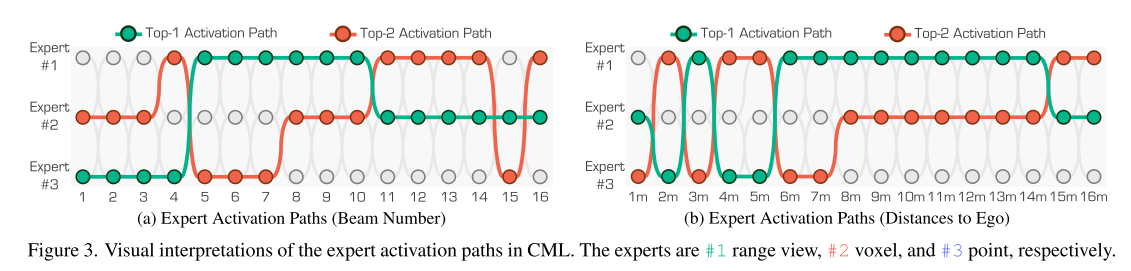
对比损失鼓励学生特征与 MoE 特征保持一致,从而使单个 3D 学生网络能够有效地从所有不同的表示中捕获信息结构。如图 3 所示,CML 鼓励 MoE 框架关注来自激光束和距离的数据属性。
3.4. SMS: Semantic Mixture Supervision
为了进一步提高下游语义分割性能,我们将 MoE 层扩展到下游任务中,如图 2 右侧所示。这种集成使模型能够从每个表示中动态选择和优先处理最相关的对象属性,从而根据任务的特定上下文定制特征融合。基于第 3.3 节中的预训练表示,每个主干独立处理点云以生成每个表示的语义逻辑:
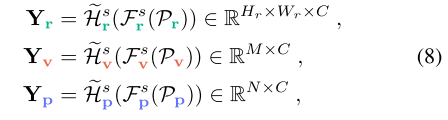
其中 C 是语义类别的数量。Hes r、Hes v 和 Hes p 是线性头,它们将骨干特征投影到每个表示的语义逻辑中。为了跨表示对齐逻辑,我们将它们投影到点云空间中,得到 bYr、bYv 和 bYp,每个都有 RN×C 的形式。
MoE 层由一个门控模块和一个噪声模块组成,门控模块动态选择每个点的激活表示,噪声模块在训练期间对特征引入扰动以减轻过度拟合。与等式 (5) 不同,噪声门仅在训练期间处于活动状态。整个过程可以表述为:
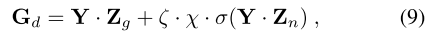
其中 ζ = 1 用于训练,ζ = 0 用于推理,Y = MLP([ bYr, bYv, bYp])。将 softmax 函数应用于门值 Gd 后,我们得到系数 αd、βd 和 γd,它们表示每个表示对每个点的相对重要性。最终的语义 logit 由每个表示的 logit 的加权和获得:Ymoe = αd bYr + βd bYv + γd bYp。
训练目标。让 X ∈ RN 表示点云 P 的语义标签。对于每个表示,这些标签可以按如下方式投影:范围图像的 Xr ∈ RHr×Wr,稀疏体素的 Xv ∈ RM,原始点的 Xp ∈ RN。每个表示都使用监督损失独立微调,将预测的 logit 与相应的投影语义标签对齐。此外,我们在输出端应用基于 MoE 的监督损失,通过从每个表示中选择最相关的特征来进一步优化模型。总体损失为:
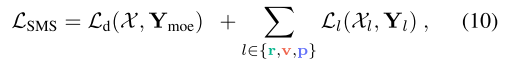
其中每个 Ll (l ∈ {d, r, v, p})都是交叉熵、Lovasz-Softmax [4] 和边界损失 [65] 的加权组合,有助于全面优化所有表示的分割性能。
4.3. Ablation Study
路线激活。在图 5 中,我们展示了在 CML 阶段由每个表示加载的光束数量和距离的分布。距离图像主要捕捉中光束和距离,稀疏体素聚焦于上光束和较长的距离,而点则集中在下光束和近距离。这种分布突出了这些表示的互补性,当在 MoE 层中组合时,它们可以提供更全面的 LiDAR 数据表示。在图 6 中,我们展示了在 SMS 阶段由每个表示加载的语义类的分布。距离图像对动态物体更敏感,稀疏体素突出显示背景物体,原始点捕捉具有复杂结构的更详细的物体。这些结果证明了每个表示如何有助于特征融合。
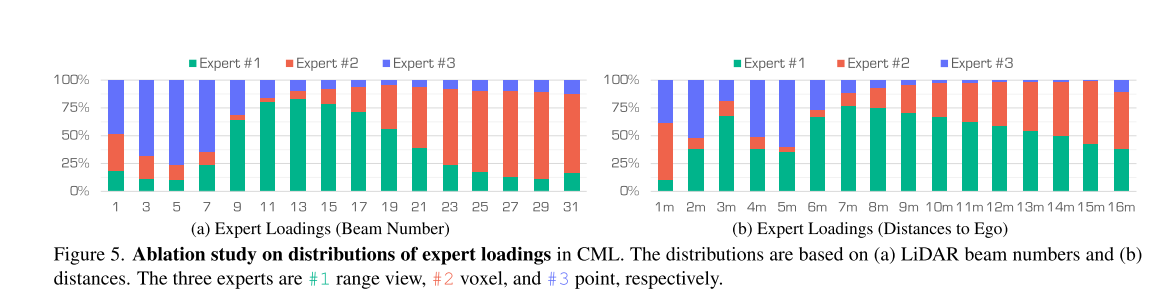
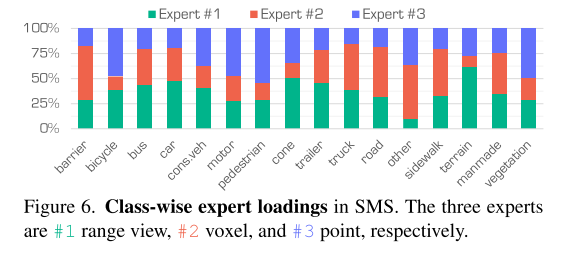
根据您提供的图片信息和描述,“路由激活”(Routing Activation)在混合专家模型(MoE)中的理解可以结合图5和图6的分布规律进行如下解释:
- 路由激活的核心机制
- 在MoE架构中,"路由"指动态分配输入数据到不同专家(Expert)的决策过程,而"激活"表示特定专家对当前输入数据的处理权重。
- 图5和图6展示的分布差异正是路由网络学习到的分配策略的直观体现。
- CML阶段的路由特征(图5)
- 距离图像专家(#1):被激活处理中等距离(4-15m)和中段光束(如7-15号光束),说明路由网络会优先将具有这些特征的点云数据分配给它
- 稀疏体素专家(#2):主要激活在上部光束(>15号)和远距离(>15m),体现对远距离稀疏特征的捕获优势
- 点专家(#3):集中激活在近距离(<4m)和下部光束(<7号),适合处理高精度近场细节
- SMS阶段的路由特征(图6)
- 动态物体偏好:距离图像专家对汽车、行人等动态物体激活频率更高(路由权重更大)
- 背景建模:体素专家在道路、障碍物等静态背景上激活更显著
- 细节捕捉:点专家在交通锥等小物体上表现出更高的激活比例
- 互补性体现
当三个专家的激活模式组合时:
- 空间覆盖:通过不同距离/光束的激活互补实现全场景覆盖
- 特征融合:动态物体+背景+细节的激活组合形成完整语义理解
- 资源优化:路由网络通过非均匀激活(如远距离时主要激活体素专家)提高计算效率
- 技术实现启示
- 路由决策应同时考虑几何特征(距离/光束)和语义特征
- 理想的激活分布应呈现这种非重叠的互补模式
- 可通过可视化这些分布来诊断路由网络是否学习到有效的专家分工
这种基于传感器特性和任务需求的路由激活机制,正是MoE模型相比传统单网络结构的优势所在。
5. 结论
在这项工作中,我们引入了 LiMoE,这是一种新颖的框架,旨在利用多种 LiDAR 表示来增强 LiDAR 场景中的特征学习。通过混合专家框架结合范围图像、稀疏体素和原始点,我们的方法可以从不同的表示中捕获互补信息,从而实现更强大的场景理解。我们提出了一个三阶段的特征学习过程,包括图像到 LiDAR 预训练、对比混合学习 (CML) 和语义混合监督 (SMS)。大量实验表明,我们的设计在多个基准测试中均优于现有方法。我们希望这项工作为更具可扩展性和鲁棒性的基于 LiDAR 的感知系统铺平道路,以用于现实世界的应用。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









