






论文:Fish-Speech: Leveraging Large Language Models for Advanced Multilingual Text-to-Speech Synthesis
论文地址:https://arxiv.org/abs/2411.01156
代码地址:https://github.com/fishaudio/fish-speech
摘要
文本转语音 (TTS) 系统在处理复杂的语言特征、处理复音表达以及生成自然的多语言语音方面面临着持续的挑战——这些能力对于未来的人工智能应用至关重要。本文提出了 Fish-Speech,这是一个新颖的框架,它实现了一个串行快慢双自回归 (Dual-AR) 架构,以增强分组有限标量矢量量化 (GFSQ) 在序列生成任务中的稳定性。该架构在保持高保真输出的同时提高了码本处理效率,使其在人工智能交互和语音克隆方面尤为有效。Fish-Speech 利用大型语言模型 (LLM) 进行语言特征提取,无需传统的字素到音素 (G2P) 转换,从而简化了合成流程并增强了多语言支持。此外,我们通过 GFSQ 开发了 FF-GAN,以实现卓越的压缩比和接近 100% 的码本利用率。我们的方法解决了当前 TTS 系统的关键局限性,同时为更复杂、更具上下文感知的语音合成奠定了基础。实验结果表明,Fish-Speech 在处理复杂语言场景和语音克隆任务方面显著优于基线模型,展现了其在 AI 应用领域推进 TTS 技术的潜力。该实现已开源,网址为 https://github.com/fishaudio/fish-speech。
1 Introduction
过去十年,文本转语音 (TTS) 系统取得了显著进步,将应用程序从虚拟助手转变为教育工具。当前的 TTS 架构,例如 VALL-E [Wang et al. [2023]]、VITS [Kim et al. [2021]] 和 FastSpeech [Ren et al. [2020]],通常依赖于字素到音素 (G2P) 转换 [Klatt [1987]] 将文本转换为语音表示,然后再进行合成。虽然这种方法有效,但由于复杂的语音规则,它在处理上下文相关的复音词和跨语言泛化方面存在困难。零样本语音转换方面的最新进展,例如 YourTTS [Casanova et al. [2022]] 和统一语音生成模型 UniAudio [Yang et al. [2023]],已经展示了神经架构在处理各种语音任务方面的潜力。此外,基于流的模型,例如 CosyVoice[Du et al. [2024]、MatchaTTSMehta et al. [2024]],在自然语音合成中展现出了良好的效果。然而,大多数解决方案为了提高稳定性,将语义特征和声学特征分离,从而降低了语音克隆的理解能力。
随着多语言 TTS 系统需求的增长,基于 G2P 方法的局限性愈发明显。由于需要特定语言的语音规则和词汇,系统可扩展性受到限制,维护也变得复杂。近期研究探索了使用大型语言模型 (LLM) 直接提取语言特征,从而消除显式 G2P 转换的需要。[Betker [2023]]。
我们推出了 Fish-Speech,这是一个新颖的 TTS 框架,采用串行快慢双自回归 (Dual-AR) 架构。这种设计提高了分组有限标量矢量量化 (GFSQ) 在序列生成中的稳定性,同时保持了高质量的输出。通过将 LLM 融入 TTS 流程,Fish-Speech 简化了合成过程,并更好地处理复音字符和多语言文本。该模型基于 72 万小时的多语言音频数据进行训练,使其能够学习多样化的语言模式和发音变化。
为了提高合成质量,我们开发了 Firefly-GAN (FFGAN),这是一种基于分组有限标量矢量量化 (GFSQ) 的新型声码器架构。FFGAN 结合了有限标量量化 (FSQ) [Mentzer 等人 [2023]] 和分组矢量量化 (GVQ),以优化压缩比和码本使用率。我们的评估显示码本利用率为 100%,代表了该领域最先进的性能。
本研究的主要贡献如下:
• 我们引入了 Fish-Speech,这是一个新颖的 TTS 框架,它利用 LLM 和 Dual-AR 架构取代传统的 G2P 转换,提供稳健且可扩展的多语言语音合成。
• 我们提出了 FFGAN,这是一种先进的声码器,它集成了多种矢量量化技术,可实现高保真语音合成,并优化压缩比和码本利用率。
• 我们开发了 fish-tech 加速方法,该系统在消费级 NVIDIA RTX 4060 移动平台上实现了约 1:5 的实时性,在高性能 NVIDIA RTX 4090 配置上实现了 1:15 的实时性。延迟为 150 毫秒,远低于其他使用 DiT 和 Flow 结构的 TTS 系统。
• 我们鼓励读者试听 fish-speech 1.4 版本的样本。我们也强烈建议您访问我们的在线合成网站 fish.audio,试用社区合成的不同说话者的音频。
2 Related Work
2.1 Text-to-Speech Systems
文本转语音 (TTS) 系统已从基于音素的基本模型显著发展到复杂的端到端神经网络方法,可直接将文本转换为语音 [Tan 等人 [2021]]。在深度学习的进步和计算能力的提升的推动下,这一转变已显著提升语音的自然度、韵律控制和跨语言能力 [Ren 等人 [2019]]。现代 TTS 系统现已服务于各种应用,从智能助手到无障碍工具以及人机界面 [Capes 等人 [2017]]。
2.2 Neural Vocoders
神经声码器在提高语音合成质量方面发挥了关键作用。WaveNet [Van Den Oord 等人 [2016]] 首先引入了用于音频生成的自回归模型,随后出现了更高效的架构,如 WaveRNN [Kalchbrenner 等人 [2018]] 和 WaveGrad [Chen 等人 [2020]]。HiFi-GAN [Kong 等人 [2020]] 后来引入了对抗性训练,为音频质量和计算效率树立了新标准。EVA-GAN 是由 NVIDIA [Liao 等人 [2024]] 开发的全新 GAN 结构声码器,它使用上下文感知模块 (CAM) 以最小的计算开销提高性能。EVA-GAN 在客观和主观指标方面都表现出优于现有最先进声码器的性能,尤其是在频谱连续性和高频重建方面。
2.3 Vector Quantization in Speech Synthesis
矢量量化 (VQ) 已成为现代语音合成中的关键技术。VQ-VAE [Van Den Oord 等人 [2017]] 证明了离散潜在表征在音频生成中的有效性,而 SoundStream [Zeghidour 等人 [2021]] 和 EnCodec [Défossez 等人 [2022]] 进一步改进了这些技术,实现了高质量的音频压缩和合成。
2.4 Large Language Models in Speech Processing
大型语言模型 (LLM) 在语音处理中的重要性日益凸显。目前,越来越多的模型使用 BERT、huBERT 作为 TTS 的中间结构,例如 Parler TTS [Lacombe et al. [2024]]、Melo TTS [Zhao et al. [2023]]、E3-TTS [Gao et al. [2023]]、XTTS [Casanova et al. [2024]] 等,并取得了较好的合成效果。
2.5 Multilingual Speech Synthesis
多语言语音合成在保持不同语言语音质量一致性方面面临着独特的挑战。近期的解决方案包括统一多语言模型 [Liu and Mak [2019]]、跨语言迁移学习 [Nekvinda and Dušek [2020]] 以及语言无关表征 [Li et al. [2019]]。
3 Methods
Fish-Speech 是一个新颖的文本转语音 (TTS) 框架,旨在解决当前非字素音素 (non-G2P) TTS 系统的关键局限性。该框架专为处理多情感和多语言语音合成而设计,重点满足高级 AI 对话代理的需求。
基于矢量量化和条件表示领域的最新进展 [Kumar 等人 [2024]、Chen 等人 [2023]、Wang 等人 [2019]],我们引入了一种分组有限标量矢量量化 (GFSQ) 技术。该方法能够高效地对潜在条件进行编码,从而更好地捕捉和再现细微的语音变化。我们的方法实现了 100% 的码本利用率,最大限度地提高了量化空间的有效性。
我们还开发了一种双自回归(dual-AR)架构,解决了当前 TTS 系统中的两大挑战。首先,它提高了代码生成的稳定性,这是现有框架中常见的问题。其次,与扩散变换器 (DiT) 相比,它提供了更高的生成效率,使其非常适合实时应用。最后,也是最重要的一点,它已为 Voice Agent 做好准备,我们将在不久的将来发布。
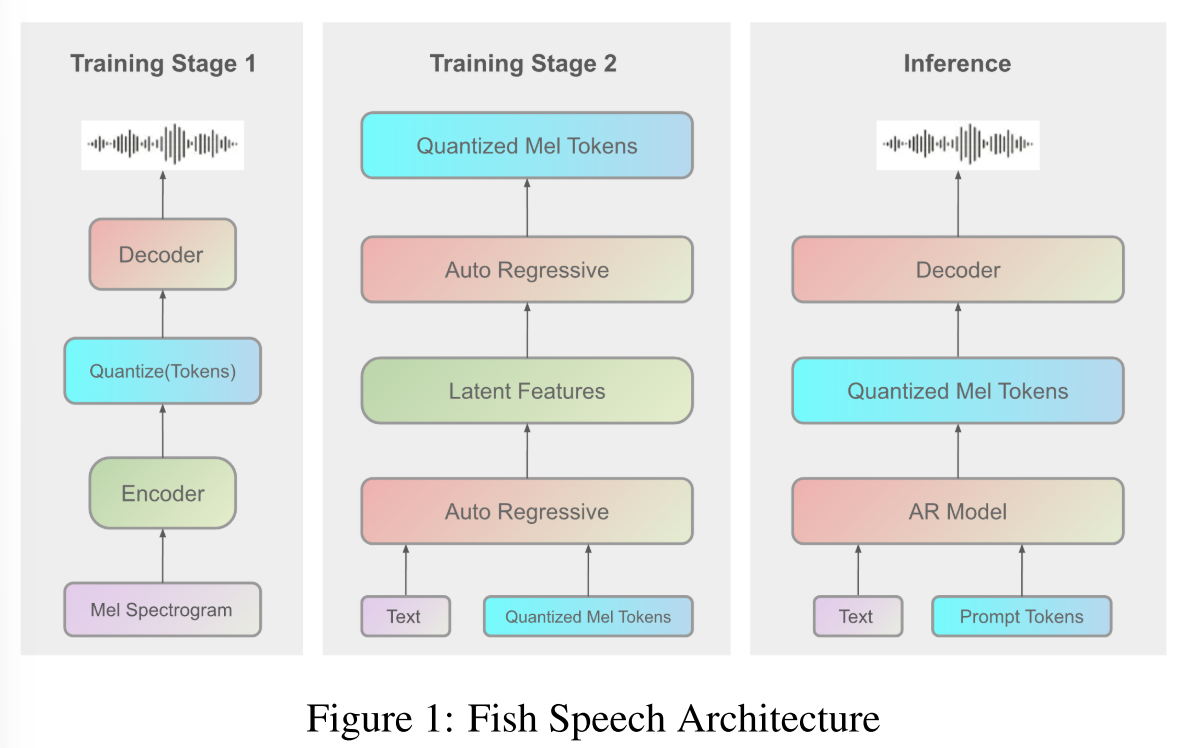
3.1 Dual Autoregressive Architecture in Fish-Speech
本节介绍 Fish-Speech 的双自回归 (Dual-AR) 架构 [图 2],Fish-Speech 是一种 TTS 系统,旨在处理复杂的语言特征、复音词和听起来自然的多语言合成。Dual-AR 架构提高了序列生成过程中码本处理的稳定性和计算效率,尤其是在使用分组有限标量矢量量化 (GFSQ) 时。
3.1.1 Overview of the Dual-AR Architecture
Dual-AR 架构由两个连续的自回归变压器 [Vaswani [2017]、Subakan 等人 [2021]] 模块组成:一个慢速变压器和一个快速变压器 [Yang 等人 [2023]]。该设计能够高效地处理语音合成的高级和细节方面。
Slow Transformer
Slow Transformer 处理输入文本嵌入,以捕捉全局语言结构和语义内容。它生成中间隐藏状态并预测语义标记。
Slow Transformer 的抽象层级更高,处理输入文本嵌入,以编码全局语言结构和语义内容。该模块负责生成中间隐藏状态并以高精度预测语义标记。

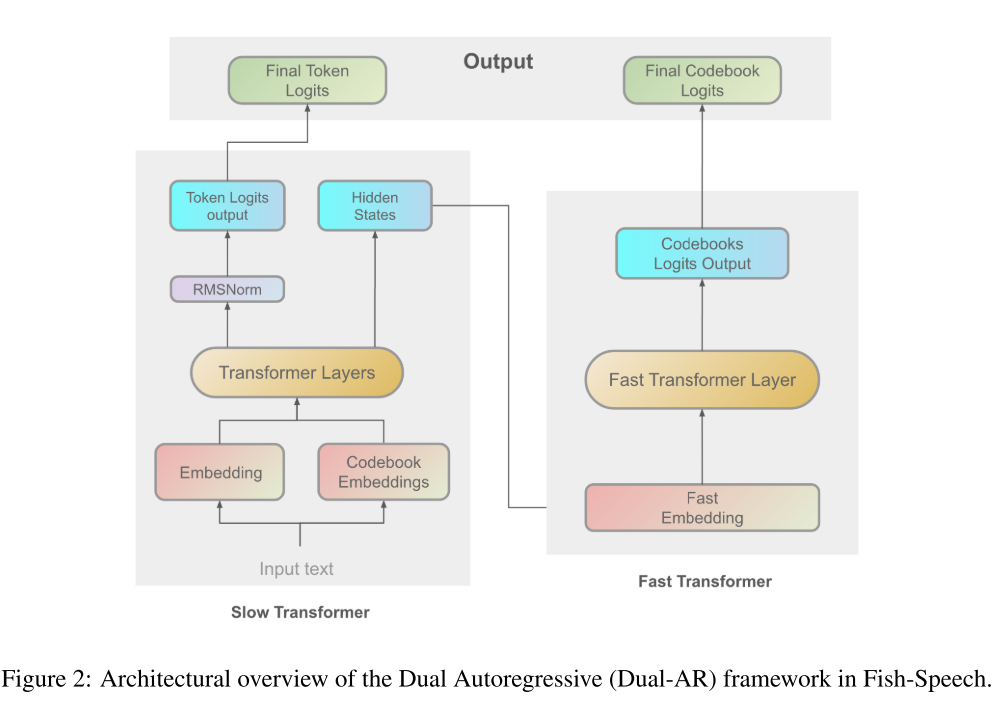
快速 Transformer
快速 Transformer 通过码本嵌入处理来细化慢速 Transformer 的输出,从而捕捉自然语音所需的详细声学特征。它处理残差信息并优化码本的使用。
快速 Transformer 将隐藏状态 h 和码本嵌入 c 的连接序列作为输入,具体如下:
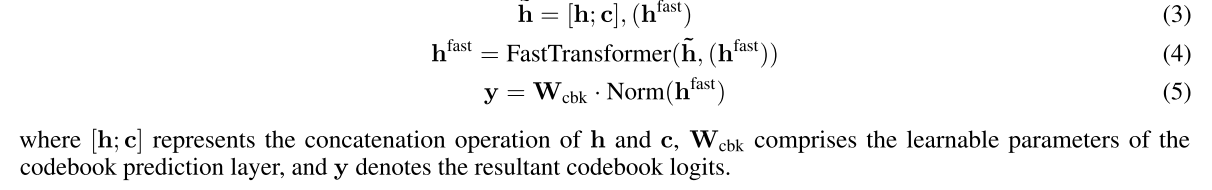
3.1.2 Advantages of the Dual-AR Architecture
Fish-Speech 中的 Dual-AR 架构展现出多项显著优势:
- 增强的序列生成稳定性:全局和局部信息的分层处理显著提升了 GFSQ 在序列生成任务中的稳定性。
- 优化的码本处理:快速 Transformer 实现了一种高效的码本嵌入处理机制,能够在不显著增加计算开销的情况下提升性能,尤其适用于 7B 或更大规模的模型。
- 卓越的语音合成质量:慢速 Transformer 和快速 Transformer 之间的协同作用,实现了能够处理复杂语言现象的高保真语音合成。
- 先进的多语言处理:与大型语言模型 (LLM) 集成用于语言特征生成,消除了传统的字素到音素转换依赖性,从而简化了合成流程并增强了多语言处理能力。通过混合文本数据,理解能力将得到进一步增强。
3.2 Firefly-GAN
Firefly-GAN (FF-GAN) 是 EVA-GAN 架构的增强版,具有显著的结构改进。它用更高效的设计取代了 HiFi-GAN [Kong et al. [2020]] 的传统卷积组件,采用 ParallelBlock 代替多感受野 (MRF) 模块。通过结合分组有限标量矢量量化 (GFSQ),FF-GAN 实现了更好的序列生成稳定性和更好的语言变化处理能力,使其特别适用于 AI 应用中的多语言合成。
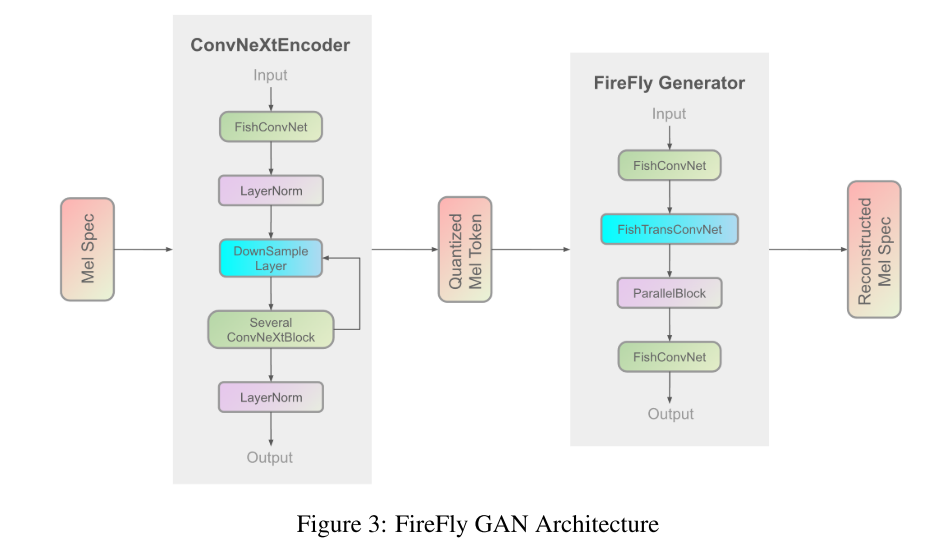
3.2.1 Firefly Generator
FF-GAN 使用增强型卷积结构,包括深度可分离卷积 Howard [2017] 和空洞卷积 Yu [2015],取代了传统的 Conv1d 层。这种架构改进增强了模型捕捉和合成复杂音频特征的能力。
在我们的架构中,传统的多感受野 (MRF) 模块被 ParallelBlock 取代,从而优化了 typo-codebook 输入的处理效率。ParallelBlock 实现了可配置的卷积核大小和扩张率,并利用堆叠平均机制来处理三个 ResBlock 的输出,而非直接进行加法运算。Liao 等人 [2024] 提出的 ParallelBlock 增强了感受野覆盖范围,提升了特征提取能力,并提高了可配置性,有助于实现更高质量的音频合成。
3.2.2 Quantization Techniques
为了适应 typo-codebook 任务,我们在系统中使用了分组有限标量矢量量化 (GFSQ) 作为 vq 码本。下文将详细介绍我们如何开发 GFSQ。

3.2.3 结论
我们使用 GFSQ 技术的实现实现了接近 100% 的码本利用率,并且在内部消融中获得比 RFSQ、RVQ 和 GRFSQ 等其他量化技术更好的客观和主观分数。FF-GAN 显著增强了错别码本操作的稳定性,并确保了多情感和多语言任务中全面的中间变量信息保留。FF-GAN 对错别码本稳定性的创新方法已经用于各种歌曲和音乐生成应用。该框架的性能和架构可以使其成为未来 AI 代理开发的参考模型。
4 Training and Inference
4.1 Training
Fish Speech 采用三阶段训练方法:首先使用大批量标准数据进行预训练,然后使用小批量高质量数据进行 SFT,最后使用手动标记的正负样本对进行 DPO 训练。
训练基础设施分为两个部分 图 1:AR 训练使用 8H100 80G GPU 进行一周,而声码器训练使用 84090 GPU 进行一周。请注意,这些时间表不包括 DPO 阶段。
4.2 Inference
我们的推理策略遵循图 1 所示的架构。借助包含 KV-cache [Pope et al. [2023]]、torch compile 和其他加速方法的 fish-tech,系统在消费级 NVIDIA RTX 4060 移动平台上实现了约 1:5 的实时性,在高性能 NVIDIA RTX 4090 配置上实现了 1:15 的实时性。这些架构优化显著改善了推理延迟,实现了 150 毫秒的首包延迟。
此外,该系统可以流式处理信息,从而可以轻松地与现代人工智能工具配合使用并在不同情况下使用它们。
5 Dataset
我们的训练数据包含大量语音样本,这些样本既来自公共来源,也来自我们自己的数据收集流程。该数据集包含约 72 万小时的语音,涵盖不同语言,其中英语和汉语普通话各占 30 万小时。此外,我们还纳入了其他语系各 2 万小时的语音:日耳曼语系(德语)、罗曼语系(法语、意大利语)、东亚语系(日语、韩语)和闪米特语系(阿拉伯语)。
我们精心平衡了不同语言的数据,以帮助模型同时学习多种语言。这种方法有助于模型在生成混合语言内容时表现良好。我们数据集的庞大规模和多样性显著提升了模型自然处理多种语言的能力。
6 Experimental Evaluation
我们对说话人克隆任务进行了评估,以评估我们的架构与基线模型相比的效果。评估方法涵盖客观和主观指标:用于评估清晰度的词错误率 (WER)、用于评估语音克隆保真度的说话人嵌入相似度度量,以及用于量化感知质量的平均意见得分 (MOS)。该评估框架旨在评估模型在保持高保真语音合成的同时保留说话人身份的能力。
6.1 Word Error Rate Analysis
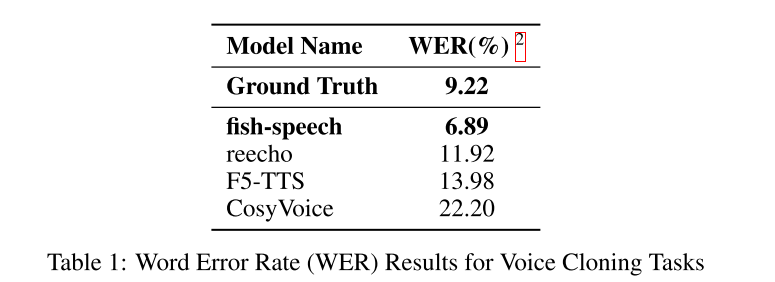
表 1 分析表明,我们的模型在语音克隆任务中实现了 6.89% 的字错误率 (WER),不仅远低于基线模型,也超过了真实录音 (9.22%)。这一表现有力地证明了我们的模型在语音克隆场景中的能力。我们模型与竞品模型之间的差距(范围从 11.92% 到 22.20%)凸显了我们方法在合成稳定性和内容保真度方面的提升。
6.2 Speaker Similarity Analysis
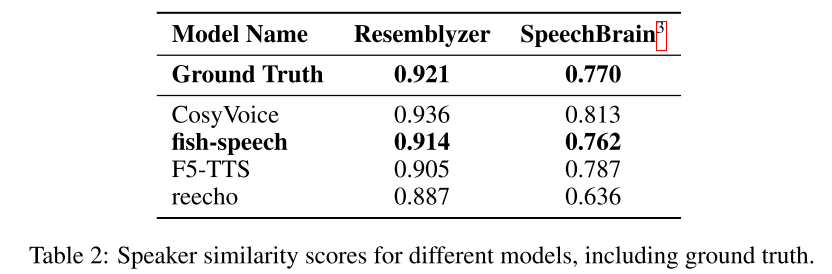 表 2 展示了我们的 Typography-Codebook 策略对说话人相似度指标的影响。我们的鱼语音模型在 Resemblyzer 和 SpeechBrain 上分别获得了 0.914 和 0.762 的相似度得分,非常接近真实值(0.921 和 0.770)。在 Resemblyzer 和 SpeechBrain 的评估中,与真实值之间的差距仅为 0.76%,而与真实值之间的差距仅为 1.04%,这充分表明我们的模型能够出色地捕捉自然语音特征。结果有力地表明,我们的 Typography-Codebook 架构能够更全面地捕捉声学状态,从而提升合成语音的音色保真度。我们的方法显著优于 F5-TTS(0.905 和 0.787)和 reecho(0.887 和 0.636)等基准模型。两个评估框架中的一致表现证明了我们的方法在保留说话人特征方面的有效性,这对于高质量的文本到语音合成和代理任务至关重要。
表 2 展示了我们的 Typography-Codebook 策略对说话人相似度指标的影响。我们的鱼语音模型在 Resemblyzer 和 SpeechBrain 上分别获得了 0.914 和 0.762 的相似度得分,非常接近真实值(0.921 和 0.770)。在 Resemblyzer 和 SpeechBrain 的评估中,与真实值之间的差距仅为 0.76%,而与真实值之间的差距仅为 1.04%,这充分表明我们的模型能够出色地捕捉自然语音特征。结果有力地表明,我们的 Typography-Codebook 架构能够更全面地捕捉声学状态,从而提升合成语音的音色保真度。我们的方法显著优于 F5-TTS(0.905 和 0.787)和 reecho(0.887 和 0.636)等基准模型。两个评估框架中的一致表现证明了我们的方法在保留说话人特征方面的有效性,这对于高质量的文本到语音合成和代理任务至关重要。
6.3 Perceptual Quality Assessment
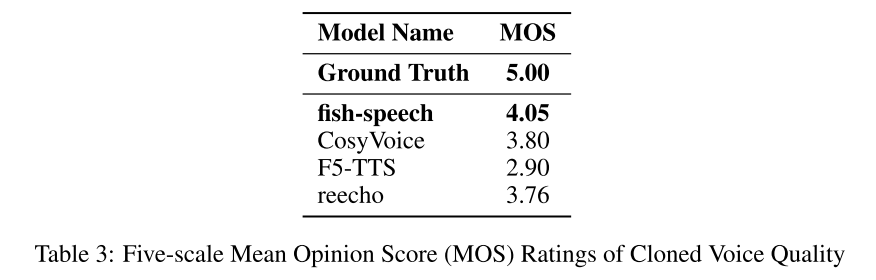
为了评估合成音频的感知质量,我们面向没有任何音频处理经验的初级听众进行了一项全面的“平均意见得分 (MOS)”听力测试。评估采用双盲随机方法,以确保评估结果的客观性。结果表明,鱼语模型的主观评分显著高于其他基线模型(p < 0.05),在语音自然度和说话人相似度方面表现出色。这项基于人类感知指标的评估结果有力地表明,鱼语模型能够更好地捕捉和再现人类语音的自然特征,尤其是在语音克隆任务中。
7 Conclusion
我们的研究通过引入一种新颖的多语言和多情感稳定解决方案,代表了文本转语音 (TTS) 领域的重大进展。核心创新在于我们开发了一种与双自回归 (dual-AR) 生成架构集成的打字码本声码器。这种架构组合在合成过程中展现了稳定性,同时保留了生成语音的声学特征。此外,我们的工作采用了非字素到音素 (non-G2P) 结构,这种方法有效地解决了传统基于音素的系统固有的局限性,并为跨语言和情感多样化的 TTS 应用奠定了坚实的基础,尤其是在 AI 代理交互的背景下。
8 Future Work
在此基础上,我们提出了几个未来研究的方向。我们计划通过整合强化学习技术来提升模型性能,重点提升跨语言泛化能力和情绪稳定性。我们还在开发 Fish Agent 应用程序,这是一个基于 Fish-Speech 框架的端到端语言模型。该系统的初步演示目前可在 fish.audio/demo/live 上找到。我们始终致力于开源社区,并将继续维护和扩展我们的代码库,为研究人员和开发者提供更广泛的使用这些技术的途径。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









