






论文地址:https://www.ijcai.org/proceedings/2024/0160.pdf
Abstract
DETR 存在训练动态不稳定的问题。与基于 CNN 的检测器相比,它需要消耗更多数据和训练周期才能收敛。本文旨在通过在线蒸馏技术来稳定 DETR 训练。它利用一个由指数移动平均 (EMA) 积累的教师模型,并从以下三个方面将其知识蒸馏到在线模型中。首先,教师模型中目标查询与真实值 (GT) 框之间的匹配关系被用来指导学生模型,因此学生模型中的查询不仅根据自身的预测分配标签,还会参考教师模型的匹配结果。其次,教师模型的初始查询被提供给在线学生模型,其预测直接受到教师模型相应输出的约束。最后,来自教师模型不同解码器阶段的目标查询被用来构建辅助组以加速收敛。对于每个GT,两个匹配成本最低的查询会被选入这个额外的组,它们会预测GT框并参与优化。大量实验表明,所提出的ODDETR成功地稳定了训练,并在不引入更多参数的情况下显著提升了性能。
1 Introduction
目标检测是计算机视觉领域的一项基础任务,数十年来一直受到业界的广泛研究。基于 CNN 的检测器可以分为基于锚框(Girshick, 2015; Liu et al., 2016)和无锚框(Tian et al., 2019; Yang et al., 2019)两种方法。前者基于滑动锚框,可以设计为单阶段、双阶段或多阶段;而后者仅基于网格点假设,通常为单阶段。尽管基于 CNN 的检测器取得了令人瞩目的性能,但它需要确定复杂的元参数,例如锚框形状和大小、正负样本阈值以及非最大抑制 (NMS) 后处理。
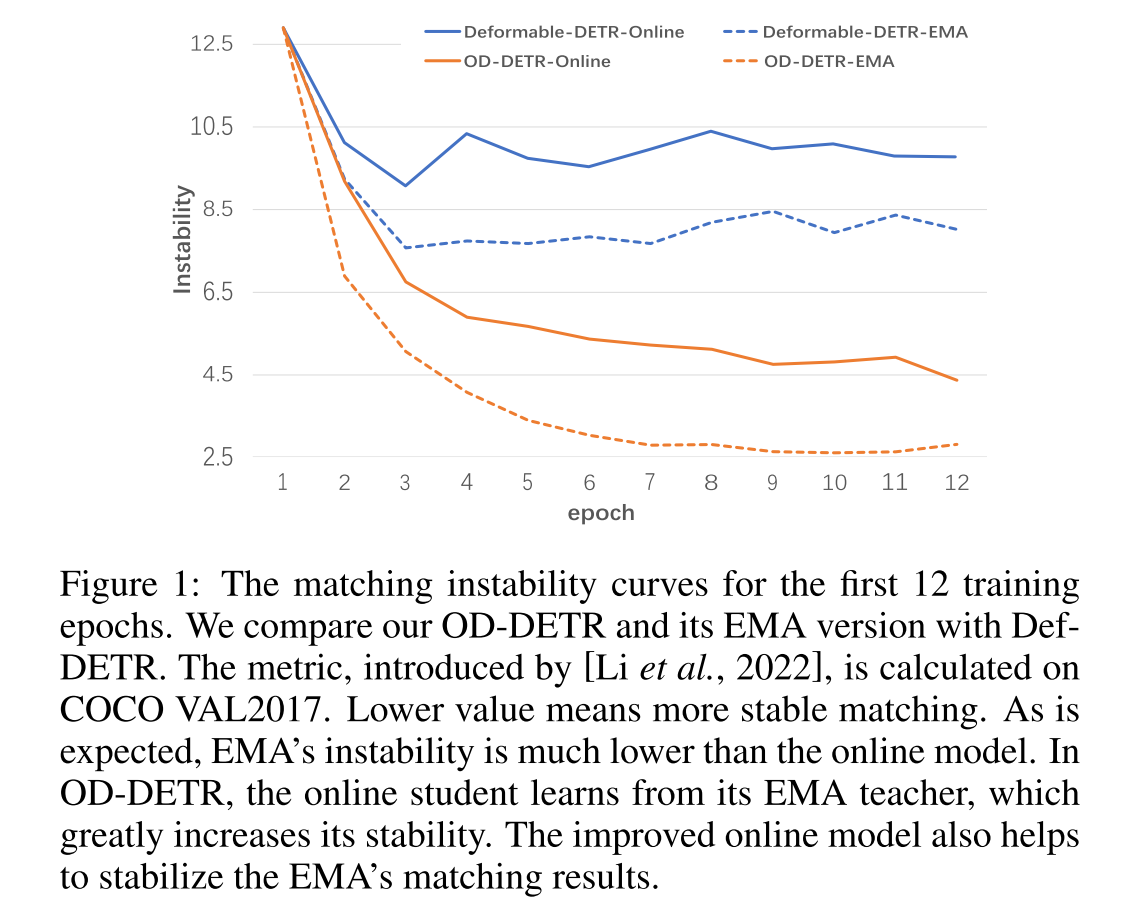
(DETR) 极大地简化了繁琐的设计。它利用编码器注意力机制来增强图像特征。同时,还加入了多个解码器注意力层,将可学习对象查询的初始参数转换为预测框。DETR 使用二分匹配来建立地面实况 (GT) 与查询预测之间的一对一关系,因此,一个 GT 分配给一个查询,反之亦然。一对一匹配方案减少了冗余预测,并减轻了非极大值抑制 (NMS) 对检测器的影响。然而,DETR 经常被指责训练不稳定、收敛速度慢。如图 1 所示,在训练过程中,查询的 GT 经常被切换。许多研究试图改进它,例如引入局部框先验 [Meng et al., 2021; Zhu et al., 2021; Liu et al., 2022] 或引入更多查询组 [Li et al., 2022]; Chen et al., 2022a; Jia et al., 2023]、初始阶段 [Yao et al., 2021; Zhang et al., 2023] 或改进的质量感知损失函数 [Liu et al., 2023; Cai et al., 2023]。
本文提出了一种名为在线蒸馏(OD-DETR)的解决方案,从另一个角度来稳定 DETR 的训练。受半监督分类 [Sohn et al., 2020] 和目标检测 [Liu et al., 2021] 的研究启发,我们利用指数移动平均线 (EMA) 作为教师模型,并将其知识以在线方式蒸馏到学生模型中。与传统蒸馏不同,教师模型也会随着学生模型的积累而不断改进。具体来说,我们利用教师模型的预测边界框、匈牙利匹配结果和更新的对象查询,设计了预测蒸馏、匹配蒸馏和在学生模型中构建辅助组的方案。对于匹配蒸馏,我们根据教师预测和 GT 框之间的成本矩阵,通过匈牙利匹配为每个对象查询分配另一个标签,并将其与原始匹配结果一起用于指导在线学生。为了使用两个可能匹配的 GT,我们提出了一种多目标 QFL 损失来容纳来自不同类别的两个标签,同时仅保留一个回归目标以避免歧义。同时,与同一 GT 相关的两个预测被赋予不同的回归损失权重,匹配成本较大的那个预测的权重被降低。
为了充分利用教师模型,其初始查询会被输入到在线学生模型中,从而给出可直接受教师模型相应输出约束的预测,无需重新匹配。我们将两个边界框之间的这种简单约束称为预测蒸馏。为了进一步加强教师模型和学生模型之间的联系,我们根据教师模型每个解码阶段的对象查询构建独立的增强组。在此,我们为每个目标框 (GT) 选择匹配成本最小的高质量查询,并将每个组输入到学生模型的解码器进行预测、与目标框重新匹配并计算损失。增强查询组主要用于加速训练收敛,因此在推理过程中会被舍弃。OD-DETR 的框架如图 2 所示。
指数移动平均模型(Exponential Moving Average Model,EMA)是一种用于平滑时间序列数据的技术。它通过对数据进行加权平均来减少噪音和波动,从而提取出数据的趋势。
在深度学习中,EMA 常常用于模型的参数更新和优化过程中。它可以帮助模型在训练过程中更稳定地收敛,并提高模型的泛化能力。
EMA 的计算公式如下:
E M A ( t ) = ( 1 − a l p h a ) ∗ E M A ( t − 1 ) + a l p h a ∗ v a l u e ( t ) EMA(t) = (1 - alpha) * EMA(t-1) + alpha * value(t) EMA(t)=(1−alpha)∗EMA(t−1)+alpha∗value(t)
其中,EMA(t) 是时间点 t 的指数移动平均值,EMA(t-1) 是上一个时间点的指数移动平均值,value(t) 是当前时间点的数值,alpha 是平滑因子(取值范围为 [0, 1]),决定了当前值在计算中的权重。
为了验证 OD-DETR 的有效性,我们在 MS-COCO [Lin et al., 2014] 上进行了大量实验。具体而言,OD-DETR 的实现支持 DETR 的不同变体,包括 Def-、DAB- 和 DINO。我们发现,我们的方法与所有这些变体兼容,并且性能显著提升。总而言之,本文的贡献在于以下几个方面:
. • 我们提出了一种基于 EMA 教师的在线蒸馏方案。具体而言,我们提出了教师和学生之间的匹配蒸馏。它根据教师预测的匹配结果,将每个查询分配到一个额外的 GT 框。此外,我们调整了损失函数,并提出了一种多目标 QFL 分类损失和一种成本敏感的回归损失。
• 我们进行预测蒸馏并构建增强查询组,以充分利用 EMA 教师。预测蒸馏是通过将 EMA 查询输入学生的解码器,并用老师的输出约束预测来进行的,而增强组则由老师内部不同解码阶段的高质量查询构建。
• 进行了大量的实验,结果表明,所提出的 OD-DETR 能够有效提升不同 DETR 变体的性能。
2 Related Work
2.1 Supervised Object Detection
现代目标检测模型主要使用卷积网络,近年来取得了巨大的成功。这些基于 CNN 的检测器分为两类:基于锚点 (anchor) 的检测器和无锚点 (anchor-free) 的检测器。[Girshick, 2015; Ren et al., 2015; Lin et al., 2017] 是一些著名的基于锚点的模型,而 [Tian et al., 2019; Yang et al., 2019; Duan et al., 2019] 则是无锚点模型。这两种模型都需要人工干预,例如非极大值抑制 (NMS) 和启发式标签分配规则。
DEtection Transformer (DETR) [Carion et al., 2020] 改变了这种情况。它是第一个端到端、基于查询的目标检测器,无需人工干预,例如锚点和 NMS。然而,DETR 的训练收敛速度较慢。最近的一些研究致力于加快 DETR 的训练速度。诸如 [Zhu et al., 2021; Gao et al., 2021; Gao et al., 2021; Sun et al., 2020; Zhao et al., 2023b; Zhao et al., 2023a; Liu et al., 2022] 等方法利用局部框先验来集中局部特征,从而缩小搜索空间。其他方法,例如 [Chen et al., 2022a; Jia et al., 2023; Li et al., 2022; Zhang et al., 2023],通过添加更多查询组来加速训练,为 ground truth 框提供额外的正样本。
2.2 EMA in SSOD and Distillation
使用 EMA 模型作为教师模型,将知识提炼给学生模型,这在基于半监督学习 (SSL) 的分类问题中一直被广泛应用,例如 [Zhu, 2005; Laine and Aila, 2017; Tarvainen and Valpola, 2017; Berthelot et al., 2019; Sohn et al., 2020]。SSL 的一个关键挑战是如何充分利用未标记图像,这可以通过自训练或一致性正则化来实现。基于 EMA 的教师方法的另一个应用领域是自监督学习,例如 [Grill et al., 2020; Gidaris et al., 2020; Caron et al., 2021] 等方法。自监督学习的关键还在于学生模型能够从教师模型在未标记数据上的输出中进行学习。
基于分类任务中的类似思想,许多半监督目标检测 (SSOD) 模型应运而生。例如,[Tang et al., 2021; Xu et al., 2021; Liu et al., 2021] 采用了 FixMatch 的原理 [Sohn et al., 2020],并使用从在线学生模型中积累的 EMA 来提供伪 GT 框。然而,对于目标检测中的知识蒸馏 (KD) 任务,当前方法通常使用固定的预训练模型作为老师模型输出标签,然后将其提供给在线学生模型进行学习,如 [Chen et al., 2017; Li et al., 2017; Chang et al., 2023; Chen et al., 2022b; Wang et al., 2022] 所示。与 SSOD 或 KD 中的工作不同,本文专注于在线监督学习检测,我们利用 EMA 模型作为老师以在线方式提供指导,而不需要预先优化的固定老师模型。
3 Method
3.1 Preliminaries on DETR and Its Adaptation
DETR 由一个主干网络、一个由多个自注意力层组成的编码器、一组可学习的对象查询和一个解码器组成,解码器后接一个检测头,用于将更新后的查询转换为具有类别预测的边界框。我们定义 Q = {qi|qi ∈ Rc} 为查询集。每个 qi 在开始阶段都是一个可学习的参数。为了使模型能够感知边界框的位置,DETR 的增强版本 [Liu et al., 2022; Zhu et al., 2021] 明确地将边界框 (x, y, w, h) 或仅将框中心 (x, y) 编码到位置嵌入中,指定一个与 Q 对应的集合 P = {pi|pi ∈ Rc}。P、Q 和图像特征 F 被输入到解码器 Dec,从而生成用于下一阶段的更新查询集 Q 和边界框集 B。
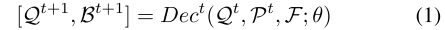
[Liu et al., 2022] Shilong Liu, Feng Li, Hao Zhang, Xiao Yang, Xianbiao Qi, Hang Su, Jun Zhu, and Lei Zhang. DAB-DETR: dynamic anchor boxes are better queries for DETR. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April, 2022. OpenReview.net, 2022.
[Zhu et al., 2021] Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable DETR: deformable transformers for end-to-end object detection. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May, 2021, 2021.
在等式(1)中,Dec 表示由 θ 参数化的解码器,上标表示解码器阶段。预测框集 B = {bi|bi = (x, y, w, h, c)} 不仅具有框坐标,还具有类别得分向量 c。除了检测头之外,DETR 的解码器还包含由 Q 中的查询元素 qi 之间的交互计算的自注意层、在 Q 和 F 之间交互的交叉注意层以及它们之间的前馈网络。在 Def-DETR [Zhu et al., 2021] 中,可以通过仅对参考点周围的特征进行采样并给出加权平均值来改进交叉注意,并且这种局部先验加速了其收敛速度。
更新后的 Q 会被提供给检测头进行分类和边界框回归。但在计算损失之前,查询的预测会根据匹配成本分配给 GT。DETR 采用匈牙利算法在查询集 Q 和所有 GT 之间建立一对一关系,这也是 DETR 能够避免 NMS 的关键原因。然而,这种动态的一对一匹配策略也会导致训练不稳定。[Li et al., 2022] 的研究发现,在两个训练周期之间,一些查询会被分配不同的 GT,如图 1 中的蓝色曲线所示,这导致 DETR 的收敛速度缓慢。
原始 DETR 的训练目标包括用于分类的焦点损失 Lcls [Lin et al., 2017],以及用于回归的 L1 和 GIoU 损失 LGIoU。一些研究表明,质量指标可以提升性能。值得注意的是,使用公式 (2) 中定义的质量焦点损失 LQFL [Li et al., 2020],分类和回归任务被绑定在一起。其中,t 是预测框 b 与其匹配的 GT 框之间计算的 IoU 目标。s 是来自 S 型函数的预测分数。
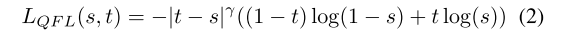
我们提出的 OD-DETR 是基于增强型 DETR 构建的,并添加了 QFL 分类损失。接下来,我们介绍三个关键组件:匹配蒸馏、预测蒸馏和辅助组,如图 2 所示。
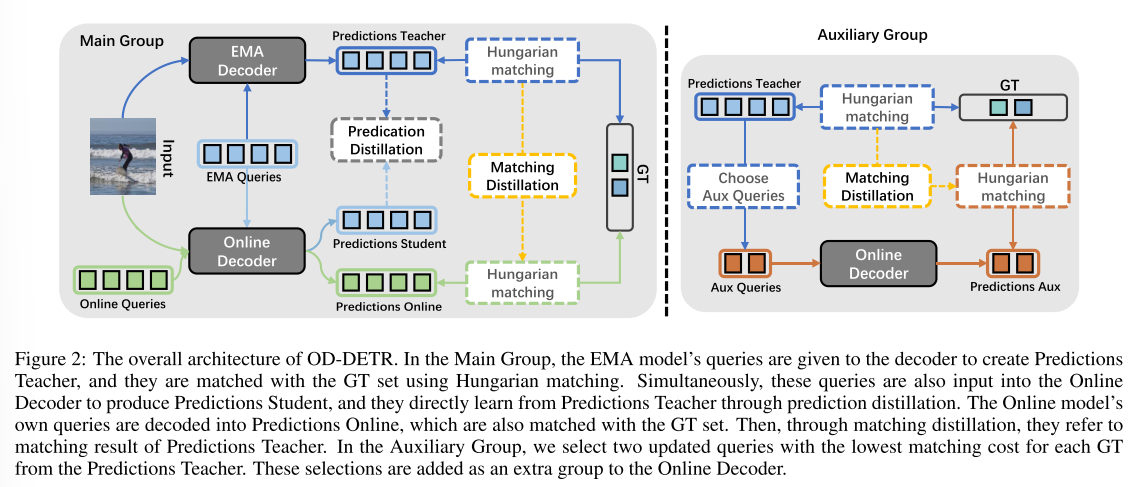
3.2 Matching Distillation
受 EMA 模型成功的启发,我们利用它来稳定 DETR 训练。我们首先验证了它在 Def-DETR 中的潜在应用。具体来说,我们训练了 12 个 epoch,并同时生成 EMA。我们根据 [Li et al., 2022] 中定义的不稳定性指标,将其与在线模型进行了比较。如图 1 所示,EMA 的行为比在线模型更稳定,表明它确实避免了两次 epoch 之间的标签切换,从而提供了稳定的匹配结果。考虑到 EMA 模型的匹配结果更稳定,我们打算将其提取到在线学生模型中。
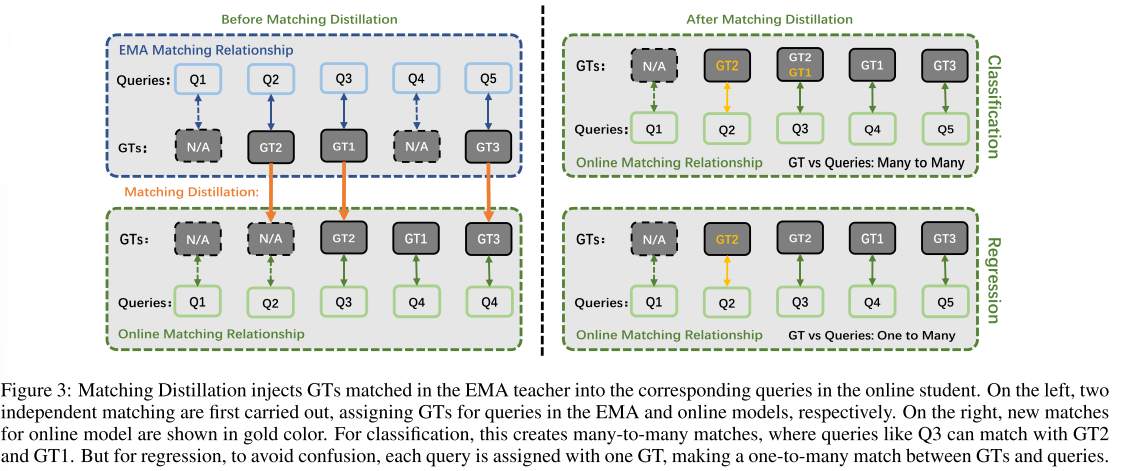
图3直观地展示了匹配蒸馏的原理。教师模型和学生模型的匹配结果被合并成分类和回归损失,用于训练在线模型。具体而言,给定教师模型的查询PE和图像特征Q′、P′和F′,教师模型的解码器(参数为θ′)可以输出预测框B′,如公式(1)所示。B′与GT集之间的匈牙利匹配结果被用作约束学生模型预测B的参考。需要注意的是,B也有一个匹配结果,这意味着qi及其EMA版本q′ i可能有不同的GT需要匹配。我们将在接下来的两节中分别阐述匹配蒸馏在分类和回归中的应用。
匹配蒸馏在分类中的应用。由于在线查询qi与q′ i紧密相关,我们设计了一个多目标QFL LMQF用于公式(3)中的类别预测,如果q′ i的匹配目标标签与原始目标不同,则使用q′ i的匹配目标标签。这里 s′ 是另一个预测的班级分数,t′ 是根据老师的匹配结果计算出的相应 IoU 目标。
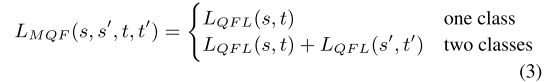
具体来说,如果两个匹配的 GT 来自同一类,则 LMQF 与公式 (2) 中定义的 LQFL 相同,由其原始 IoU 目标 t 计算得出。否则,如果两个 GT 属于不同类别,则两个 IoU 目标 t 和 t′ 分别对 s 和 s′ 施加约束。图 4 显示了如何为与两个不同类别 GT 匹配的查询预测设置多目标标签。在密集场景中,一个预测框通常包含多个不同类别的对象。因此,单类别的独热标签并不合适。我们的 LMQF 根据预测框和两个匹配 GT 之间的 IoU 动态设置不同类别的目标,为训练提供更丰富的语义信息。它还可以通过防止在线匹配结果发生变化时标签突然变化来提高训练稳定性。
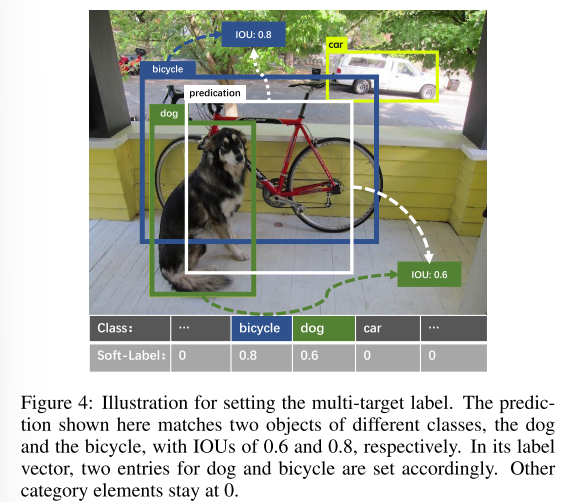
用于回归的匹配蒸馏。对于边界框回归,也会参考教师的匹配结果。但我们避免了由于两个不同的 GT 框与一个查询匹配而导致的歧义,仅使用在线匹配的结果作为计算 L1 和 LGIoU 的目标。此外,由于一个 GT 仍可能与两个查询匹配,因此我们只需降低匹配成本较大的查询的回归损失的权重。回归损失 Lr 定义如公式 (4) 所示。其中,b 和 bgt 分别是预测和匹配的 GT 框。wd 是一个超参数,其值为 0.51,遵循 [Cai et al., 2023] 中的思路。
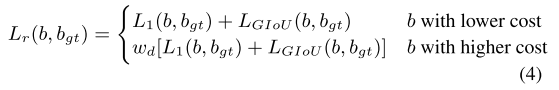
3.3 Prediction Distillation
除了匹配蒸馏之外,教师模型 B′ 的输出也可用于训练,我们称之为预测蒸馏。然而,由于在线预测已经受到匹配框的约束,要求它们接近另一组目标具有歧义性。
为了充分利用 B′,我们将 EMA 查询 Q′ 以及匹配框 P 和图像特征 F 一起输入学生解码器,并得到输出 Bˆ,如公式 (1) 所示。注意,B′ 与 Bˆ 不同。前者完全来自教师模型,作为目标集,而后者是需要约束的预测。此外,由于 B′ 和 Bˆ 都来自同一个 Q′,因此它们之间存在明确关联。因此,可以直接计算它们之间的预测蒸馏损失 Lpd。
这里一种简单的方法是采用公式 (1) 中定义的 LQFL。但是,将 IoU 目标 t 替换为老师的类别得分 c′,这是一种在固定老师的情况下进行蒸馏的策略 [Chen et al., 2022b]。然而,在我们的案例中,EMA 老师的预测并不十分准确,尤其是在训练初期。单纯地应用它会引入老师本身的许多错误,从而导致结果更差。我们对其进行了调整,使其适用于在线蒸馏。首先,由于 B′ 与 GT 框的结果匹配,因此可以推断出 B′ 中每个框的隐式类别标签索引 cg。然后,我们根据公式 (5) 修改相应条目处的预测得分向量 c′。
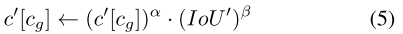
这里,IoU′ 是 B′ 中的边界框与其匹配的 GT 之间的计算值。α 和 β 是两个超参数。根据 [Feng et al., 2021],我们设定 α = 0.25 和 β = 0.75。更新 c′ 后,我们用它替换公式 (2) 中的 t,从而得到用于预测蒸馏的 Lcls 蒸馏值。对于回归任务,c′[cg] 也用作权重。在 Lr 蒸馏值和 Lcls 蒸馏值中使用 c′[cg] 被称为 TOOD 权重,该权重最初由 [Feng et al., 2021] 为单阶段检测器提出。注意,c′[cg] 是根据老师计算的,这与 [Feng et al., 2021] 是关键区别。因此,Lr 蒸馏值 = c′[cg](L1 + LGIoU)。Lcls 蒸馏值和 Lr 蒸馏值合并为公式 (2) 中的 Lpd。 (6)。

3.4 Auxiliary Group
为了更好地利用EMA教师模型并增强训练稳定性,我们在教师解码器的第t阶段从(Q′)t和(B′)t中选择一些更新的查询˜q及其对应的预测框˜b。然后,我们将它们用作PE的独立初始查询和锚点。它们被输入到在线模型的第一个解码阶段,为学习提供更多正例。为了减少辅助组的计算负载,我们在每个解码阶段仅选择与每个GT匹配成本最低的前两个查询。这种方法确保所选查询既包含正例,也包含具有挑战性的负例。需要注意的是,来自同一解码阶段的查询构成一个独立的组。每个组的预测与GT集一对一匹配。
每个辅助组也使用匹配蒸馏,就像我们在主组中所做的一样。这种方法将教师模型的原始匹配与新的匹配相结合,从而增强了辅助组的训练稳定性。因此,辅助组的损失可以表示为Laux = ˜LMQF + ˜Lr。综上所述,总的训练损失如公式(7)所示。
论文写的好难看~
5 结论
本文提出了一种 OD-DETR,这是一种在线蒸馏方法,用于稳定 DETR 的训练。我们发现,训练过程中积累的 EMA 模型不仅提供了高质量的预测框,还提供了查询-GT 匹配结果和额外的查询组。在 EMA 模型的帮助下,我们通过预测蒸馏、匹配蒸馏和辅助查询组改进了在线训练。我们证明了所提出的 OD-DETR 能够稳步提升不同 DETR 变体的性能。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









