






文章目录
1.解决问题
1-1.DIMVMLC
- double incomplete multi-view multi-label classification issue
- 双重不完全多视图多标签分类问题
- 即多视图有缺失且多标签有缺失
1-2.具体
- 视图缺失时能更好进行多标签预测(通过权重解决)
2.算法特色
- 使用了DNN
- 使用了权重(即view和label的有效性数据,我猜是0/1)
3.缺陷
- 训练时要提前知道label标签是否有效
4.网络
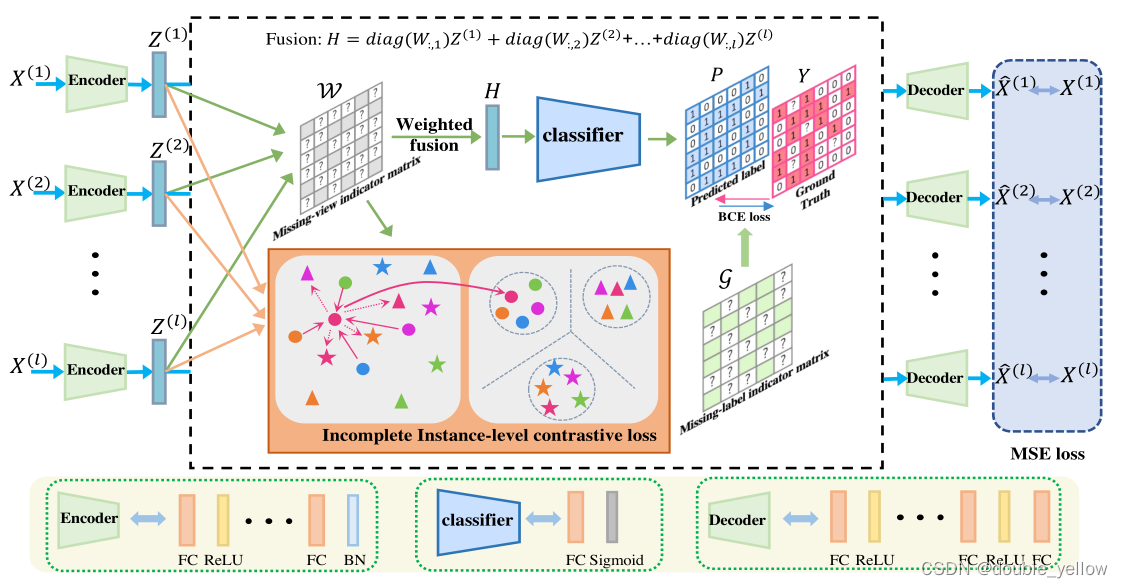
4-1.encoder
- 作用:提取深层特征(得到初步分类)
- 结构:
3层linear + relu提取深层特征,1层linear + batch_norm得到初步分类 - 维度变化:
(view_num, batch_size, 不全是0的列的数量(对每个iv都不同))
-> (view_num, batch_size, label总数)
4-2.分类器
-
作用:使用神经网络进行分类
-
预处理后的输入:batch中,每个sample有效label的总和除以有效label数量,即平均label(即z)

-
结构:relu,linear,sigmoid

-
维度变化:不变
(view_num, batch_size, label总数)
-> (view_num, batch_size, label总数)
4-3.decoder
- 作用:encoder提取的特征尽可能还原为X
- 结构:
3层linear + relu,2层蠢linear - 维度变化:
(view_num, batch_size, label总数)
-> (view_num, batch_size, 不全是0的列的数量(对每个iv都不同))
5.损失函数
5-1.loss_Cont对应文章中Lic
- 作用: 让同一sample的不同view特征更近,不同sample的特征更远
- 步骤:
1.对batch数据每次取两组不同view特征,得2组(batch, label总数)的数据
2.只保留2组中label都有效的,得2组(有效数据, label总数)的数据
3.对每个label进行L2-norm
4.连接2组数据,求sim_mat,得(2*有效数据, label总数)的sim矩阵
5.对每一组数据使用交叉熵损失
- 关键:
L2-norm后可以直接求S(sim)
使用nn.CrossEntropyLoss(reduction=“sum”)
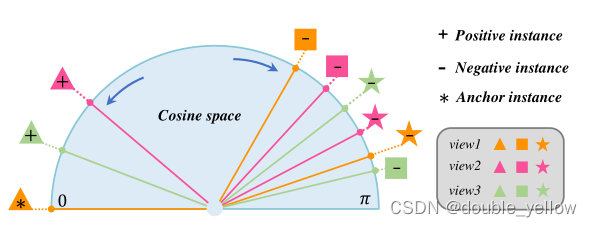

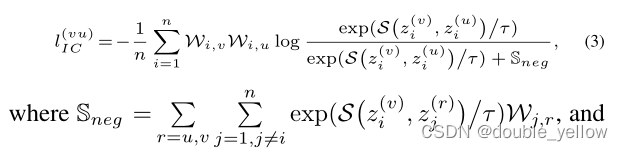

关于为什么要这个损失:



5-2.loss_CL
-
作用: 使分类器结果与真实类别更相似
-
步骤:直接一个交叉熵损失
-
关键:
torch中tensor的*和.mul相同,都是每个元素相乘(不是矩阵相乘)
交叉熵是让分布更相似,但是不懂为啥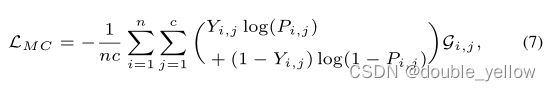
5-3.loss_AE
- 作用: 重新生成的X与原来更相似
- 步骤: 直接一个带权重的平均平方损失
- 关键: wmse是带权重的平均平方损失,这个很简单,权重不可训练
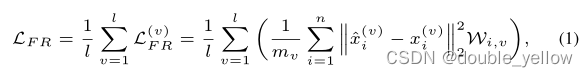
5-4.总loss
![]()















 1241
1241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









