






Distinguishing Fact from Fiction: A Benchmark Dataset for Identifying
Machine-Generated Scientific Papers in the LLM Era.
Abstract
主要提出了目前存在机器代替人去写作的弊端,这样就导致很难确定科学出版物的研究贡献,为了更好的区分出来是人写的还是机器生成的,作者构造了数据集(包括人工写的和机器生成的),然后通过不同的模型进行预测。
Introduction
(1)提供了一个包含来自各种来源的人为编写和机器生成的科学文档的数据集:SCIgen、GPT-2)、GPT-3、ChatGPT(OpenAI,2022年)和Galactica(Taylor等人,2022年)所用到的数据。
(2)利用了四个模型预测,分别为roBERTa,Galactica,GPT-3,和DetectGPT
Method
作者的利用分类的方式进行判断是否是机器生成的科学版物。
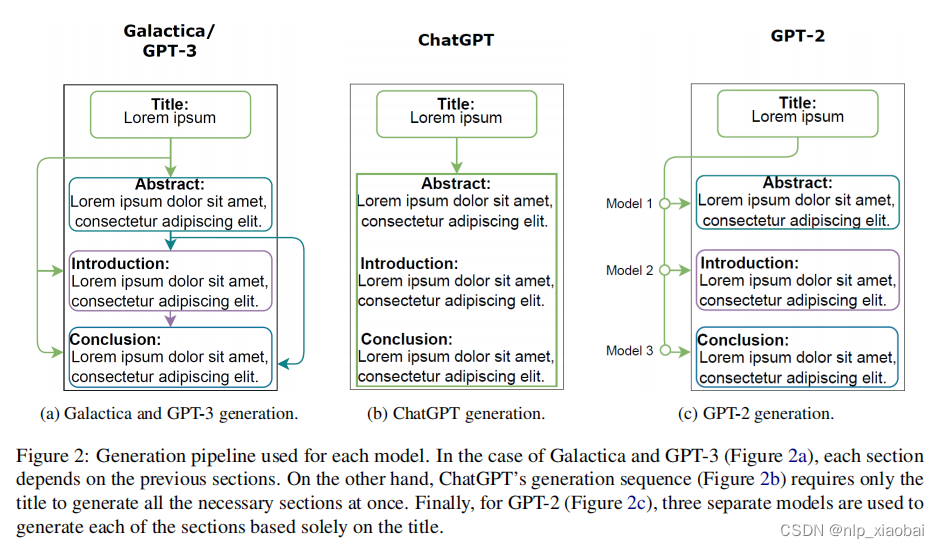
Benchmark Dataset
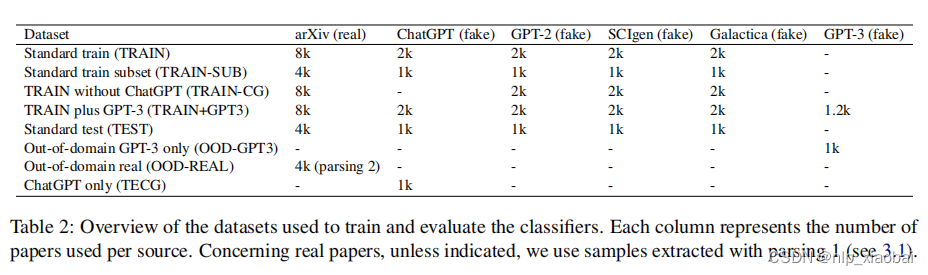
Result
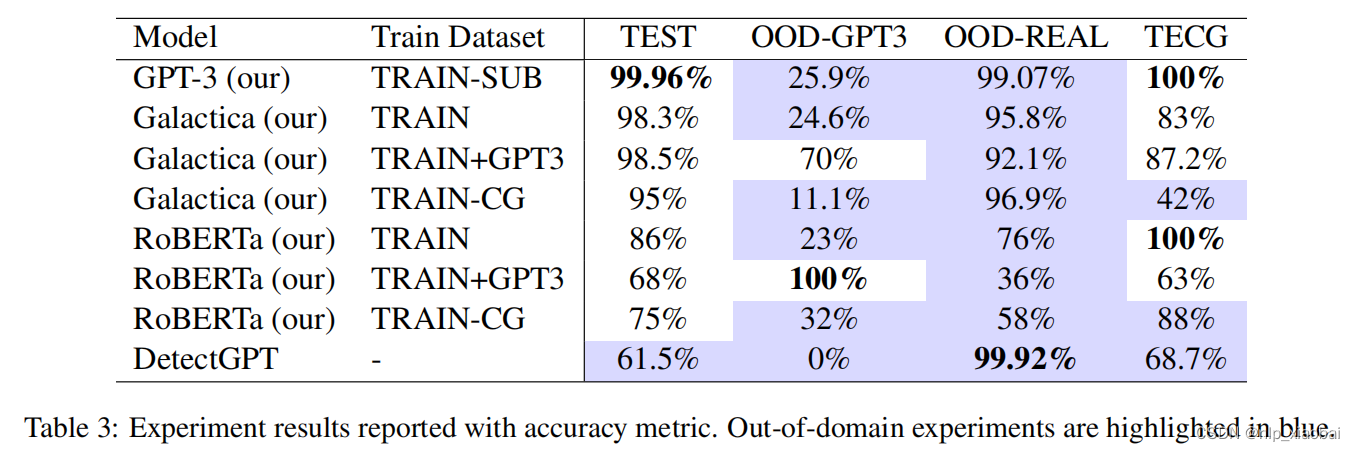
所有模型在GPT-3 curie(OOD-GPT3)生成的域外论文上都表现不佳(Shrestha和Zhou,2022)。这一结果支持了Bakhtin等人(2019)和Shrestha和Zhou(2022)之前的研究结果,这些研究表明,在特定生成器上训练的模型往往在训练分布之外的数据上表现不佳。然而,在用更多的GPT-3例子训练我们的卡拉狄加和RoBERTa模型后,模型获得了更高的精度(分别为70%和100%)。
总结:
主要产出了一个基准数据集,用于识别在LLM时代机器生成的科学论文,并且提出了4中不同的模型方法以及对应的基线,为后续的研究提供了良好的开始。















 4254
4254











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









