







TCGA数据含义解析
目前的主要研究方向为病理图像的基础模型,所使用的代码中目前的病理图像均来自与TCGA。TCGA(The cancer genome atlas,癌症基因组图谱)由 National Cancer Institute(NCI,美国国家癌症研究所) 和 National Human Genome Research Institute(NHGRI,美国国家人类基因组研究所)于 2006 年联合启动的项目, 收录了各种人类癌症(包括亚型在内的肿瘤)的临床数据,基因组变异,mRNA表达,miRNA表达,甲基化等数据,是癌症研究者很重要的数据来源。
数据的地址在这里:GDC Data Portal Homepage
其中每个数据中都包含了丰富的多模态信息,除了图像之外,还包含了病人的基础信息以及对应的病理报告。这些内容在基础模型研究或者是在病理报告自动生成的任务中可以发挥重要的作用。
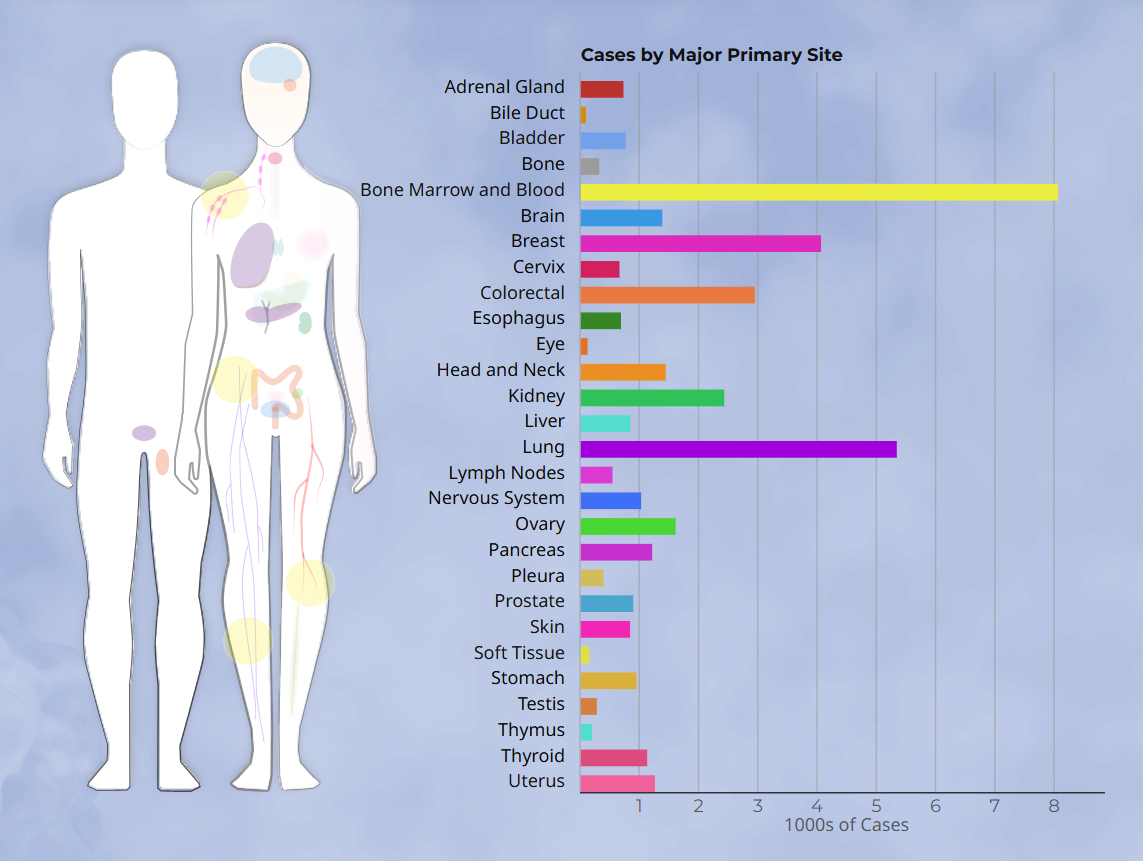
其中,这里的数据一共包含了人体28个不同的组织,在上面的网站中,你也可以通过点击对应部位的方式来查看这个部分中所有包含的数据。
考虑到病理的图像的像素都比较大,如果在全部的病理图像进行实验的话,大概又9000张图像,需要耗费巨大的算力来进行特征提取。前期的实验需要在部分的人体组织上进行实验,为了方便筛选,我这里从三个子集上进行筛选,我将下面每个项目对应的含义按照从多到少的顺序进行排列。
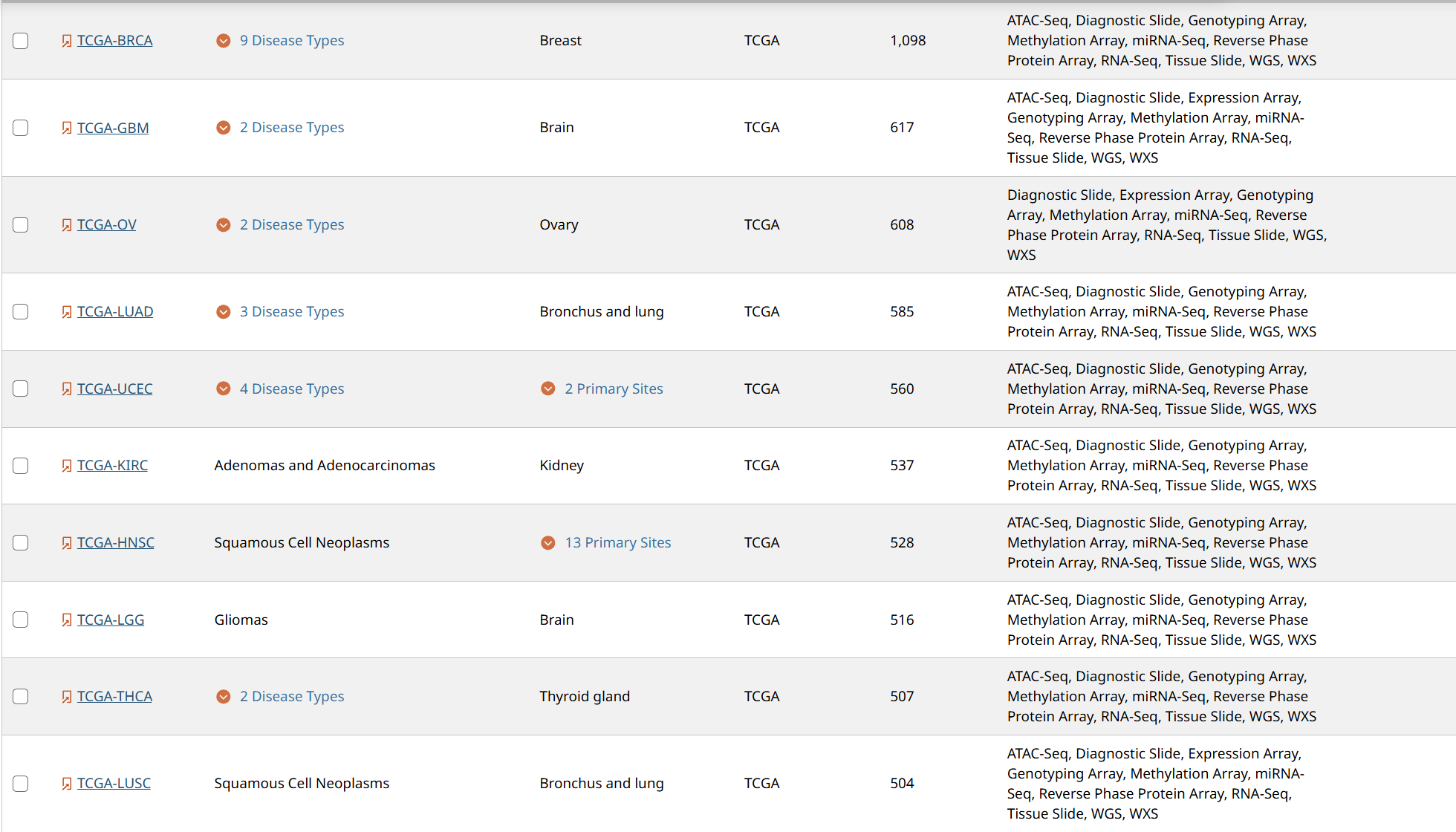
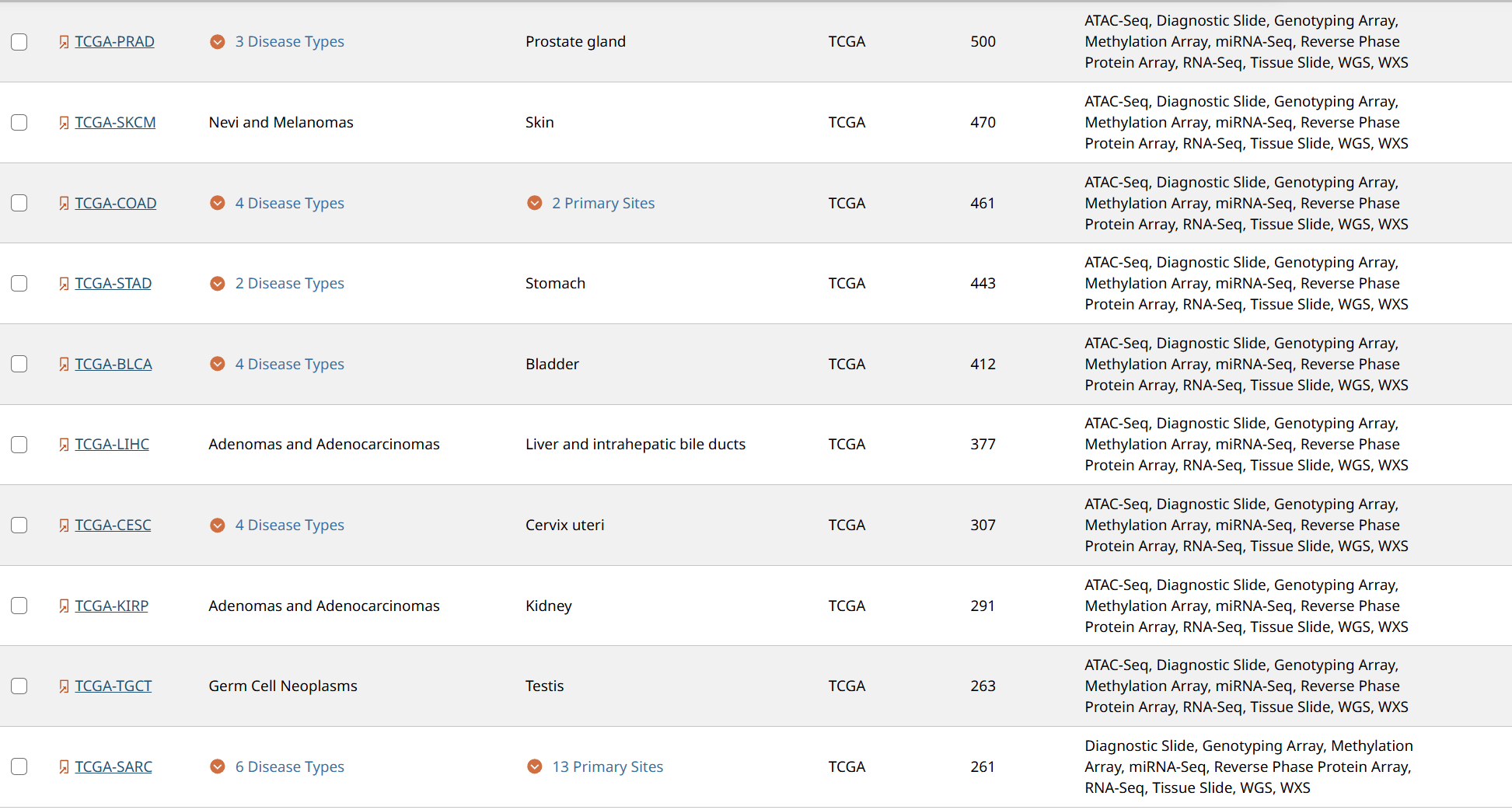
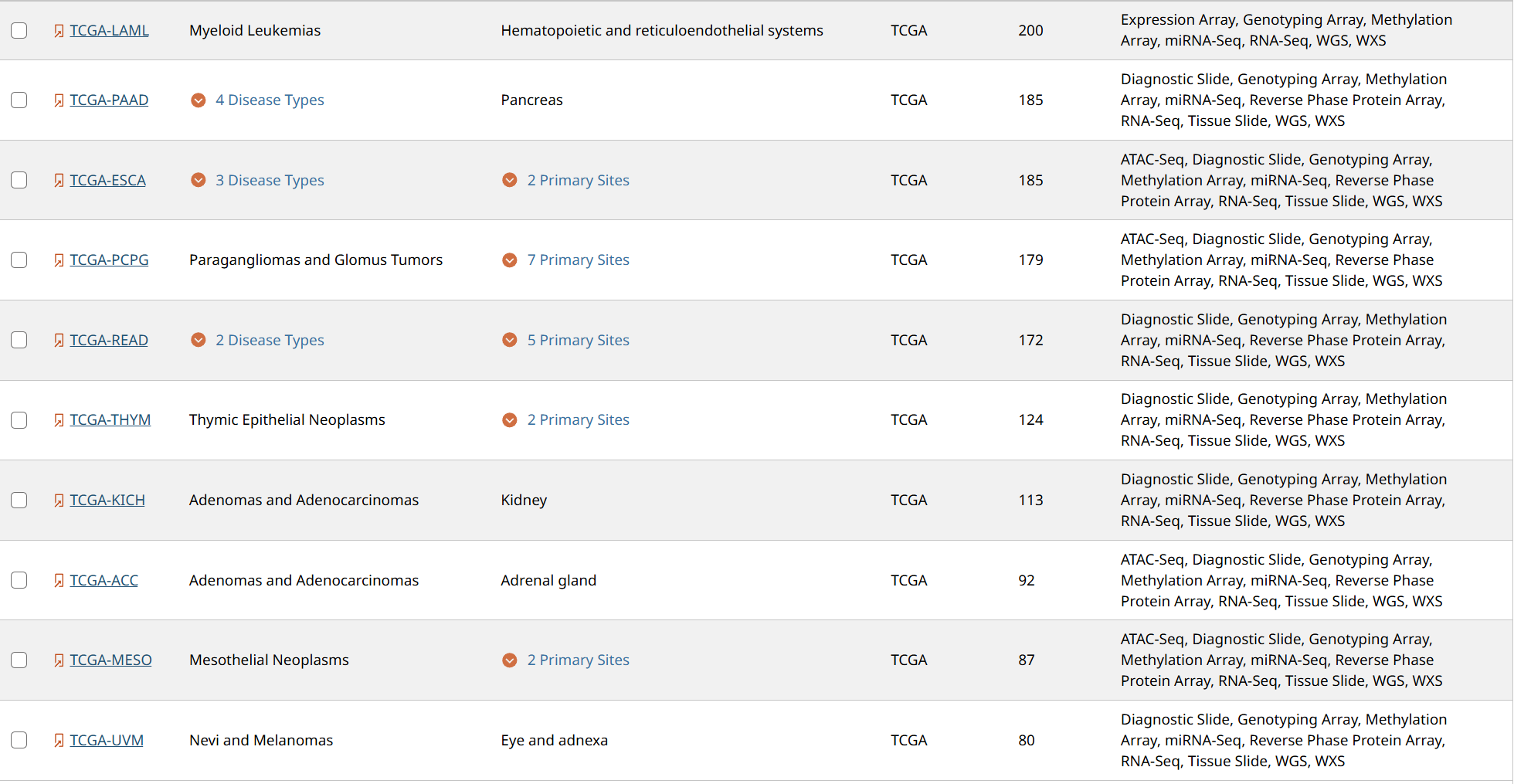



















 491
491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











