







Helix 算法流程和思考
1、动机
-
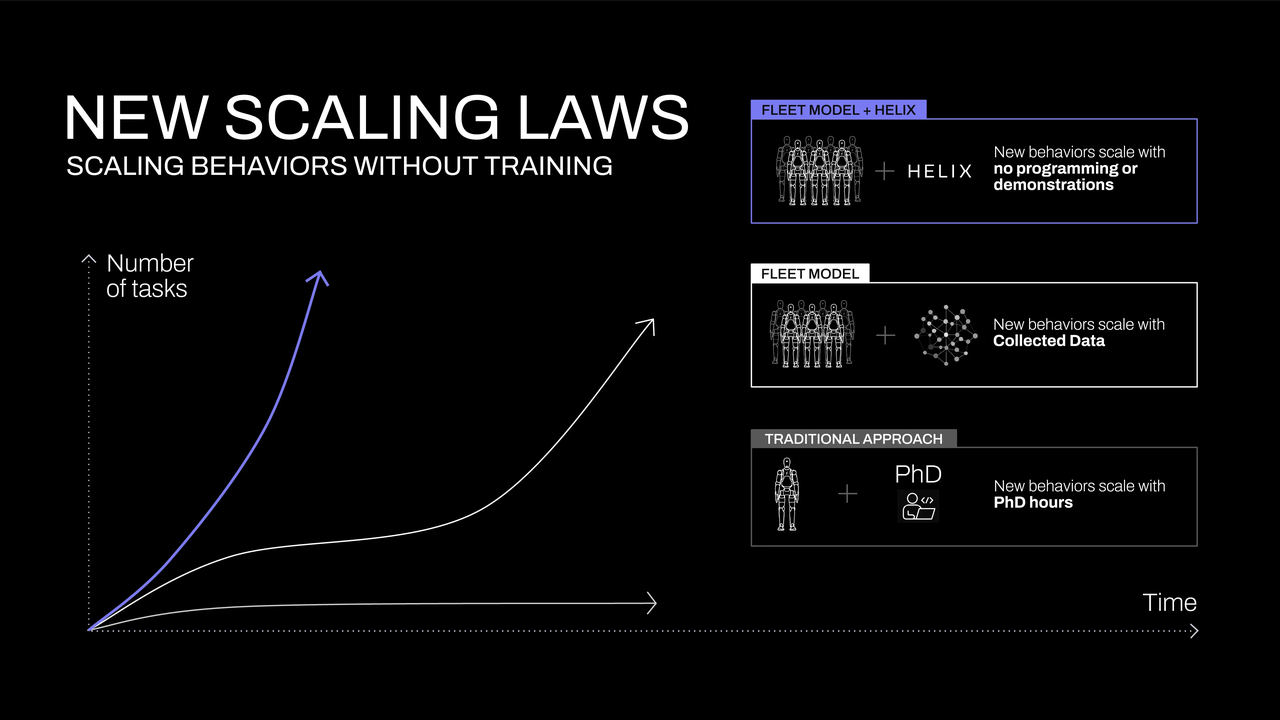
家庭环境的显著特点在于其高度的非结构化特性,这导致机器人学习和训练过程面临效率瓶颈,并直接推高了经济成本。 与高度受控的工业环境形成鲜明对比,典型的家庭空间内包含着品类繁多且物理特性各异的物体,例如易碎的玻璃器皿、形态不规则的织物以及随意散落的玩具等。 构成挑战的是,这些物体在几何形状、尺寸、色彩及纹理特征等方面均呈现出高度的不可预测性。 为了使机器人能够在家庭场景中有效运作,它们必须具备根据环境需求自主生成智能化的新行为模式的能力,尤其需要针对此前未曾见到的全新物体展现出适应性。 然而,当前机器人行为学习范式在很大程度上依赖于密集型的人工干预:具体而言,一种新行为的习得往往需要领域专家投入数小时进行精细的手动编程,或依赖于数千次行为演示所构成的数据集。考虑到家庭环境中任务类型的广泛性和复杂性,上述两种方法均显示出经济性上的显著劣势,其高昂的成本使其难以在实际家庭应用中被广泛采纳。
-
机器人控制的实时性需求与大型模型推理周期之间存在固有的矛盾性。在典型的工业应用场景中,轮式机器人导航控制的频率通常在10-50Hz范围内;而工业机械臂的典型控制频率则在50~200Hz范围内。尽管利用大型模型赋能传统机器人能够显著提升其语义理解和环境感知能力,但大型模型的推理时间会成为制约机器人控制实时性的关键因素,进而可能导致机器人运动的迟缓。因此,如何在保证机器人智能化水平的同时,兼顾其运动控制的实时性,是当前研究面临的一项重要挑战。
2、Helix的解决思路:快慢系统融合思考
Helix is a first-of-its-kind “System 1, System 2” VLA model for high-rate, dexterous control of the entire humanoid upper body。 Helix首创了“系统 1,系统 2”VLA 模型,用于对整个人形上半身进行高速、灵活的控制。(但事实上,清华大学在2024年提出了类似的架构,HiRThttps://arxiv.org/abs/2410.05273?login=from_csdn)
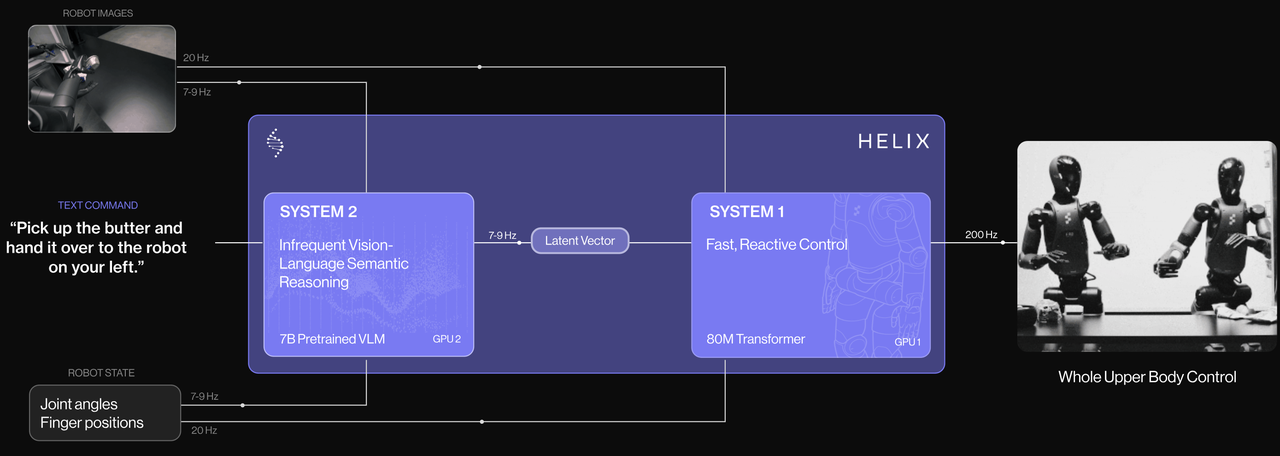
System 2:7B的预训练模型,一个在 7-9 Hz 频率下运行的预训练VLM,用于场景理解和语言理解,能够实现跨对象和情境的广泛泛化。S2 建立在互联网规模数据上预训练的开源、开放权重的 VLM
之上。它将单目机器人图像和机器人状态信息(包括手腕姿态和手指位置)投影到视觉语言嵌入空间后进行处理。结合指定所需行为的自然语言命令,S2
将所有与语义任务相关的信息提炼成一个单一的连续潜在向量,传递给 S1 以条件其低级动作。
INPUT:
- 图像(7~9Hz)
- 关节电机位置编码器信息(7~9Hz)
- 灵巧手位置信息(7~9Hz)
- 语音指令
OUTPUT:- 单一的连续潜在向量(7~9Hz)
- System 1:快速反应的视觉运动策略, 一个 80M 参数的交叉注意力 Transformer,处理低级控制。它依赖于一个全卷积、多尺度视觉骨干进行视觉处理,从完全在模拟中进行的预训练中初始化。虽然 S1 接收与S2 相同的图像和状态输入,但它以更高的频率处理它们,以实现更响应的闭环控制。从 S2 的潜在向量投影到 S1 的标记空间,并沿序列维度与S1 视觉骨干的视觉特征连接。S1 以 200Hz输出完整的上半身人形控制,包括所需的腕部姿势、手指屈曲和外展控制,以及躯干和头部朝向目标。
INPUT:
- 单一的连续潜在向量(7~9Hz)
- 图像(20Hz)
- 关节电机位置编码器信息(20Hz)
- 灵巧手位置信息(20Hz)
OUTPUT:- 35个自由度控制指令(200Hz)
- 物流场景下小模型的架构
在特定场景下,System1的小模型架构是可以发生改变的。例如在物流分拣场景中,S1由一个30M的视觉感知网络和50M的Transformer网络串联而成。- 30M的立体视觉骨干网络。头部两颗摄像头首先进入参数为30M的视觉骨干网络,在立体空间中结合多尺度特征提取网络来捕捉丰富的空间层次,不再独立地从每个摄像头中提取图像特征标记,而是在多尺度立体网络中将两个摄像头的特征合并,然后再进行标记。
- 50M的Transformer网络。该模块融合视觉骨干网络的3D视觉特征,结合手部、头部、躯干的传感器感知能力,以200Hz的频率输出动作。
![[图片]](https://i-blog.csdnimg.cn/direct/991723dd720b460aa9713e907b9d8cc6.png)
mark:
- S1和S2中,对于灵巧手的位置信息,从目前描述来看,尚不知道是灵巧手每个关节的绝对位置,还是灵巧手和目标之间的相对位置信息。如果S1和S2能从图像中学习到灵巧手和目标之间的相对位置信息,那么在控制中则实现了双位置环,能够实现更加准确的运动控制。
- S2系统接收指令的速度为7~9Hz,图像采集频率为20Hz,指令输出频率为200Hz,因此在指令接收和数据采集阶段,可能采用了多模态数据融合方法进行数据同步。
这种解耦架构允许每个系统在其最佳时间尺度下运行。S2 可以“慢思考”关于高级目标,而 S1 可以“快思考”以实时执行和调整动作。Helix 的设计相较于现有方法具有几个关键优势:
- 速度和泛化:Helix 匹配了专用单任务行为克隆策略的速度,同时将零样本泛化到数千个新的测试对象。
- 可扩展性:Helix 直接输出高维动作空间中的连续控制,避免了先前 VLA 方法中使用的复杂动作标记化方案,这些方案在低维控制设置(例如二进制并行夹爪)中已显示出一些成功,但在高维人形控制中面临扩展挑战。
- 架构简洁性:Helix 使用标准架构——为 System 2 使用开源、开放权重的 VLM,以及为 S1 使用基于简单变换器的视觉运动策略。
- 解耦性:解耦 S1 和 S2 使我们能够分别迭代每个系统,无需受寻找统一观察空间或动作表示的约束。
S2 作为一个异步后台进程运行,消耗最新的观察(机载摄像头和机器人状态)和自然语言命令。它持续更新一个共享内存的潜在向量,该向量编码了高级行为意图。
S1 作为一个独立的实时进程执行,维持着对平滑全身动作至关重要的 200Hz 控制循环。它同时采用最新的观测数据和最近的 S2 潜在向量。S2 与 S1 推理之间的固有速度差异自然导致 S1 在机器人观测上以更高的时间分辨率运行,从而为反应性控制创建更紧密的反馈循环。
3、模型训练
Helix收集了一个高质量、多机器人、多操作员的数据集,包含多样化的远程操作行为,总计约 500 小时。为了生成自然语言条件下的训练对,使用自动标注的 VLM 来生成事后指令。VLM 处理来自机载机器人摄像头的分割视频片段,提示为:“你会给机器人什么指令才能得到这个视频中看到的动作?”在训练期间处理的所有项目都排除在评估之外,以防止污染。
Helix 完全端到端训练,将原始像素和文本命令映射到连续动作,使用标准回归损失。通过用于调节 S1 行为的潜在通信向量,将梯度从 S1 反向传播到 S2,允许联合优化这两个组件。Helix 无需针对特定任务进行适应;它保持单个训练阶段和一组神经网络权重,无需单独的动作头或针对每个任务的微调阶段。
Helix的运行流程可能是这样的:
- 机器人做某事的视频
- (o1 或某些其他更大模型)“非常精确地描述机器人被赋予的任务”
- o1 output -> 7B model -> small model -> loss 输出->7B 模型->小型模型->损失
在训练过程中,我们在 S1 和 S2 输入之间添加一个时间偏移。此偏移校准以匹配 S1 和 S2 的部署推理延迟之间的差距,确保部署期间的实时控制要求在训练中得到准确反映。
Helix 的训练设计使得在 Figure 机器人上高效部署模型并行成为可能,每个机器人配备双低功耗嵌入式 GPU。推理管道分为 S2(高级潜在规划)和 S1(低级控制)模型,每个模型都在专用的 GPU 上运行。
同时,在测试中采用了一种简单但有效的加速技术,该技术产生的行为比训练数据的行为更快:插值策略动作块输出(我们称之为“运动模式”)。我们的 S1 策略输出动作“块”,代表 200Hz 的机器人动作序列。在实践中,通过线性重采样动作块[T x action_dim]——代表 T 毫秒轨迹——到更短的[0.8 * T x action_dim]轨迹,然后在原始 200Hz 控制率下执行较短的块,从而在不修改训练过程的情况下实现 20%的测试时速度提升。
mark:
- 本质上来说Helix类似模仿学习,学习数据由更大的模型进行标记
- 依赖于VLM进行动作规划,尚没有考虑世界模型的概念
4、多机器人部署
部署单一策略到多个机器人需要解决由于小型机器人硬件差异导致的观察和动作空间中的分布偏移。这包括传感器校准差异(影响输入观察)和关节响应特性(影响动作执行),如果不适当补偿,可能会影响策略性能。特别是在高维全身动作空间中,传统的手动机器人校准无法扩展到机器人编队。因此,Helix训练一个视觉自体感觉模型,从每个机器人的机载视觉输入中估计末端执行器的 6D 姿态。
- 猜测校准方法为,根据机器人正运动学,通过关节电机编码器估计末端6D位姿,通过视觉自体感觉模型计算末端6D位姿。以其中一个位姿计算结果为标准对另一个模型进行动态特性的校准,得到关节特性和传感器特性模型。
5、效果
Helix以200Hz的频率对35个自由度进行调度,控制从单个手指运动到末端执行器轨迹、头部注视和躯干姿势的一切。头部和躯干控制带来了独特的挑战——随着它们的移动,它们会改变机器人可以触及的范围和可以看到的范围,从而产生历史上导致不稳定的反馈循环。
- 多智能体协作。在我们将在具有挑战性的多智能体操作场景中将 Helix 推至极限:两个 Figure 机器人之间的协作零样本杂货存储。视频 1 展示了两个基本进展:机器人成功操作了全新的杂货——这些物品在训练期间从未遇到过,展示了跨不同形状、大小和材料的强大泛化能力。此外,两个机器人使用相同的 Helix 模型权重运行,消除了对机器人特定训练或明确角色分配的需求。它们通过自然语言提示如“将饼干袋递给右侧的机器人”或“从左侧的机器人那里接收饼干袋并将其放入敞开的抽屉”来实现协调。这标志着首次使用 VLA 在多个机器人之间展示灵活的扩展协作操作,尤其是在它们成功处理完全新颖的物体方面具有重要意义。
- 仓储分拣。实现在流水线中,将包裹从一个输送带转移到另一个输送带,同时确保运输标签正确定位以便扫描。https://www.figure.ai/news/helix-logistics


















 317
317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











