









深入 YOLOv8:探索 block.py 中的构建块
YOLOv8,作为最新和最先进的对象检测模型之一,其核心架构由多个精心设计的构建块组成。这些构建块在 block.py 文件中定义,它们共同构成了 YOLOv8 的骨架。在本文中,我们将深入探讨这些构建块的原理和作用。

第一到第四个模块:1-4的模块
第五到第八个模块:5-8的模块
9. RepC3, RepCSP, RepNCSPELAN4
RepC3、RepCSP和RepNCSPELAN4是深度学习中用于构建高效神经网络结构的组件,特别是在目标检测领域。
RepC3
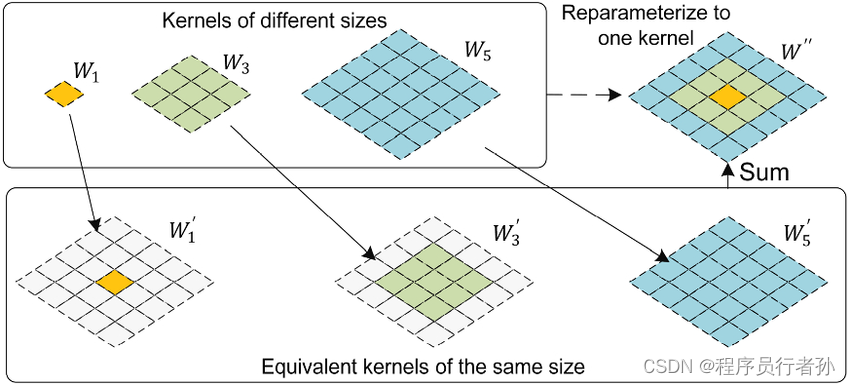
原理:
RepC3是一种重参化卷积(Reparameterization Convolution)模块,它允许网络在训练和推理阶段使用不同的结构。在训练阶段,RepC3可以表示为一个标准的卷积层,但在推理阶段,它可以被重参化为一个更高效的结构,从而减少计算量和提高推理速度。这种技术特别适用于需要实时处理的目标检测模型,如YOLO系列。
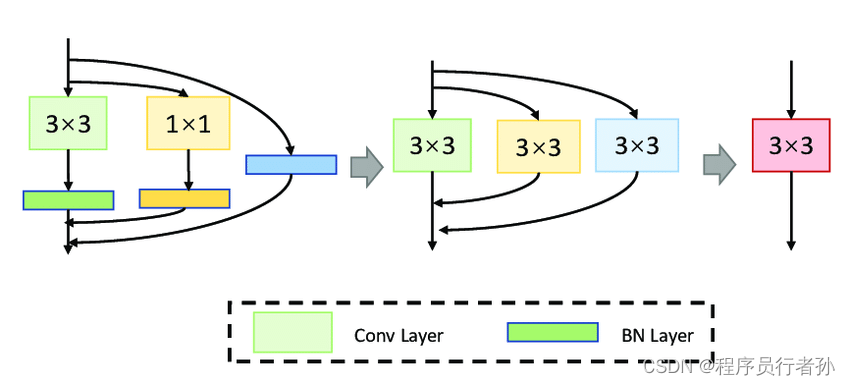
作用:
- 在训练时保持模型性能。
- 在推理时通过减少参数和计算量提高速度。
代码分析:
class RepC3(nn.Module):
def __init__(self, c1, c2, n=1, stride=1, dilation=1):
super(RepC3, self).__init__()
self.act = nn.SiLU()
self.conv = nn.Conv2d(c1, c2, 3, stride, dilation, bias=False)
# 可能包含额外的重参化逻辑
def forward(self, x):
x = self.act(x)
x = self.conv(x)
return x
在上述代码中,RepC3模块首先通过激活函数(如SiLU)处理输入,然后通过卷积层。
RepCSP
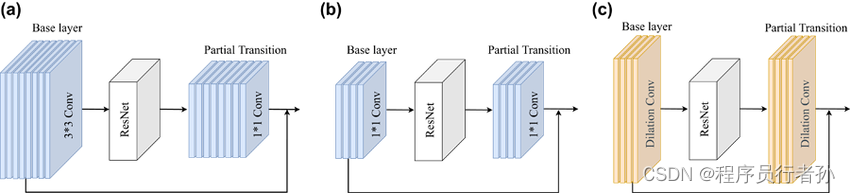
原理:
RepCSP(Reparameterized Cross Stage Partial Network)是一种用于减少计算量的技术,它通过在网络的不同阶段间共享卷积层来实现。这种方法可以减少模型的参数数量和计算量,同时保持网络性能。
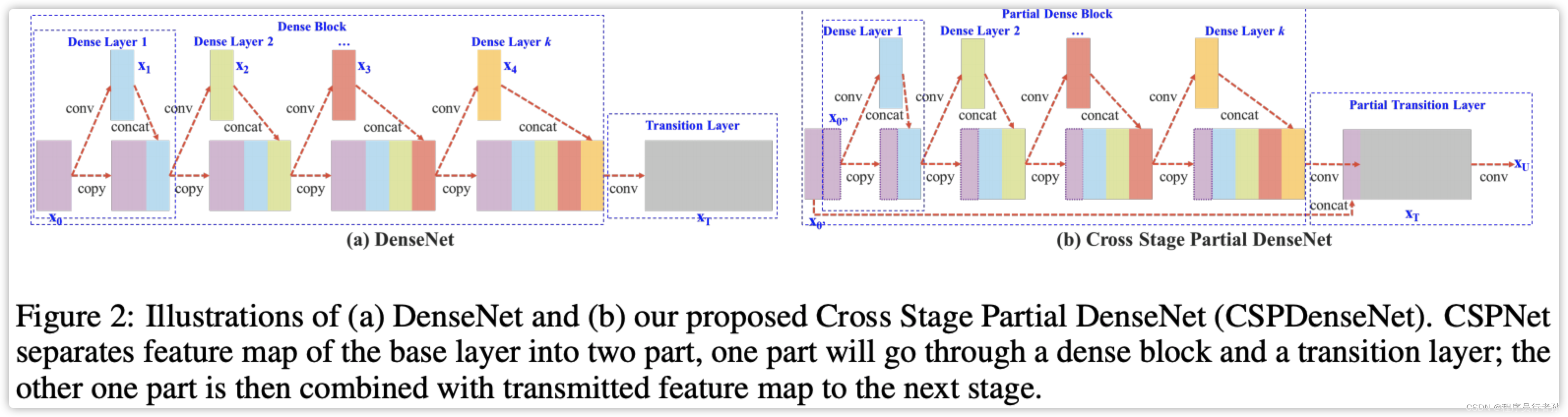
作用:
- 减少模型的参数数量和计算量。
- 在多尺度特征融合时保持计算效率。
代码分析:
RepCSP的具体实现可能会根据具体的网络设计有所不同,但核心思想是在网络的不同阶段重用相同的卷积层。以下是RepCSP思想的一个简化示例:
class RepCSP(nn.Module):
def __init__(self, c1, c2):
super(RepCSP, self).__init__()
self.conv = nn.Conv2d(c1, c2, 1, 1, 0, groups=c1, bias=False)
def forward(self, x):
res = self.conv(x)
return x + res # 使用残差连接
RepNCSPELAN4
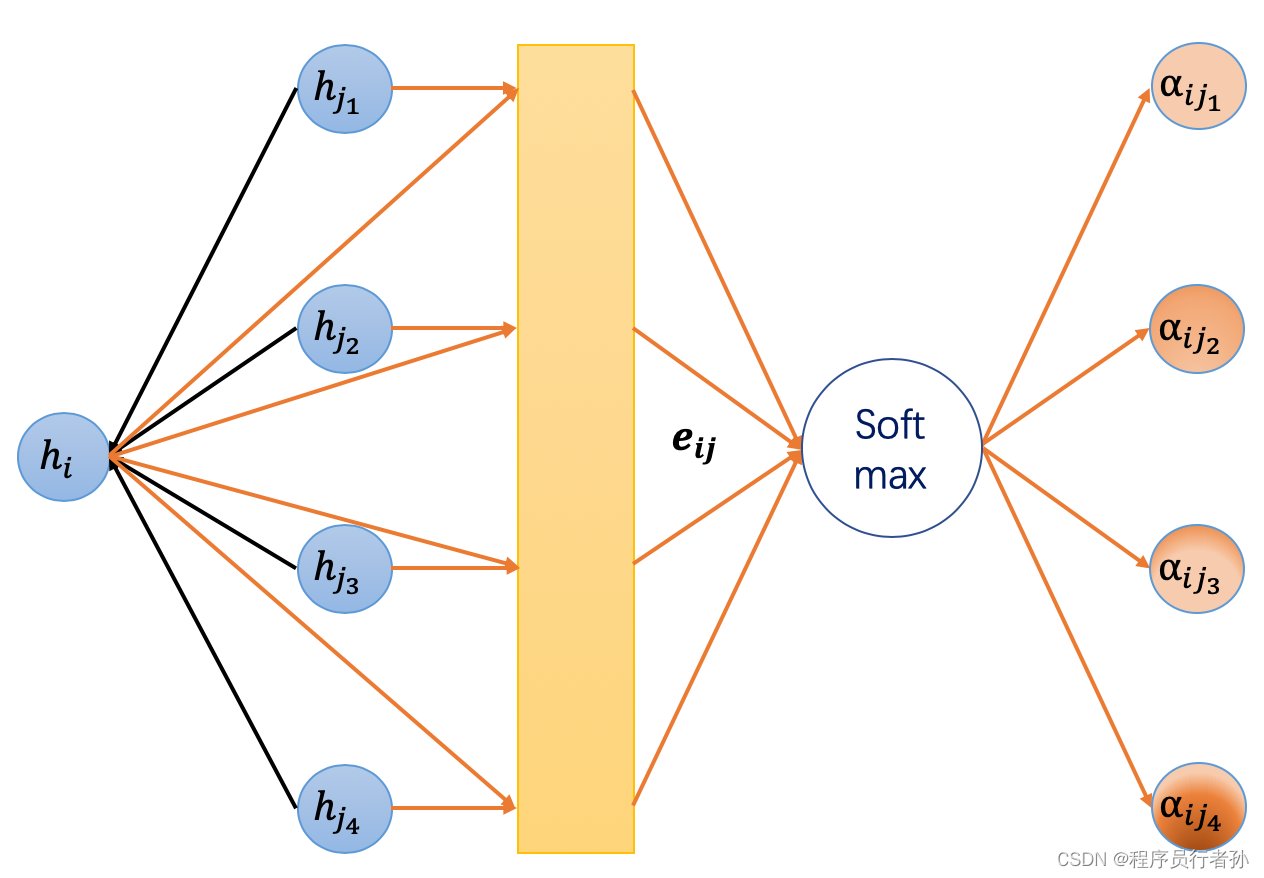
原理:
RepNCSPELAN4可能是一个特定于某个网络结构的组件,它可能是ELAN(Efficient Layerwise Attention Network)的一个变种,并结合了重参化技术。ELAN是一种用于提高深度网络性能的注意力机制,它通过在层内和层间引入注意力机制来增强特征表示。
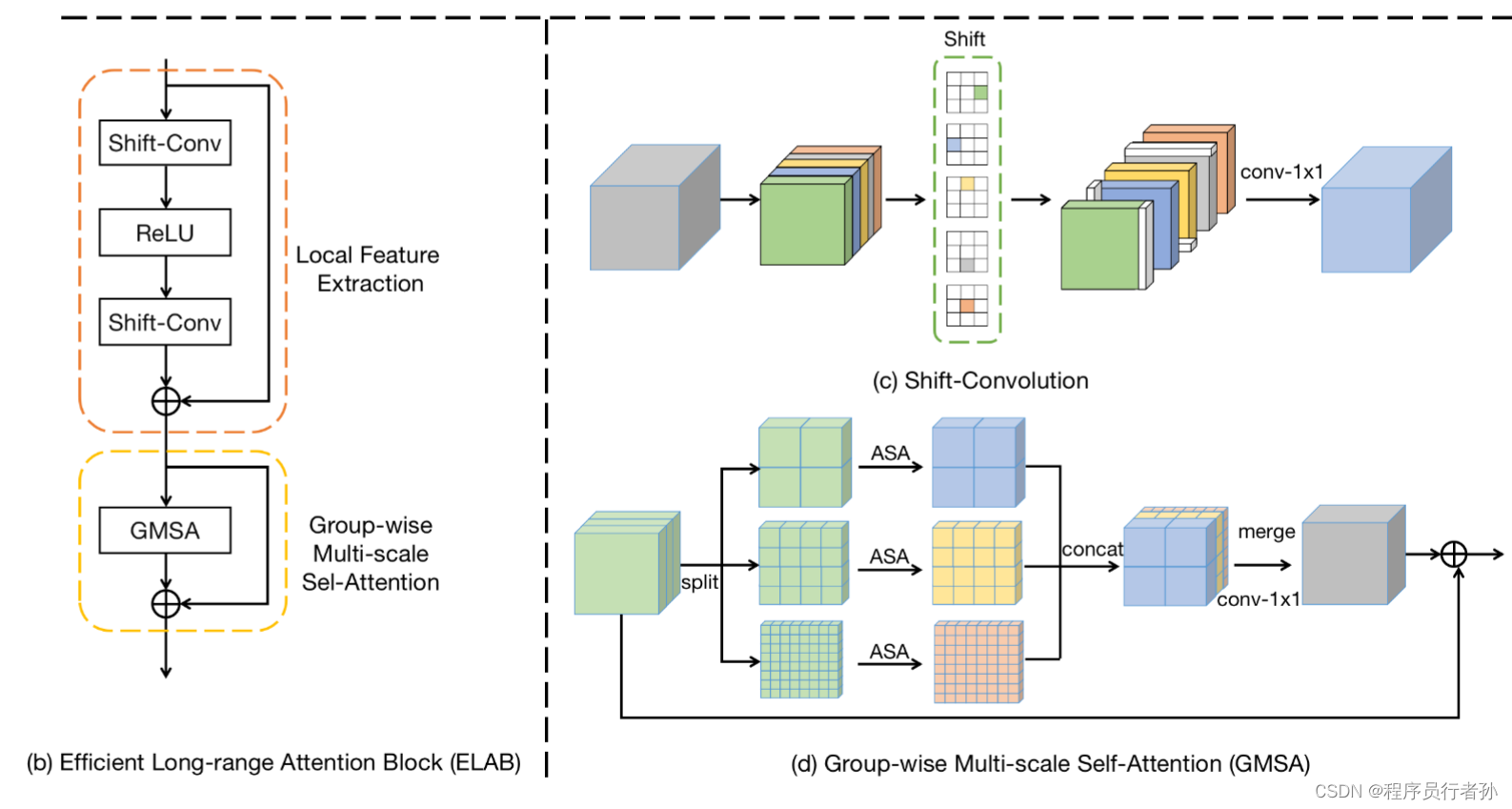
作用:
- 通过注意力机制提高特征的表达能力。
- 结合重参化技术以提高推理效率。
10. Downsampling
下采样(Downsampling)的原理和作用:
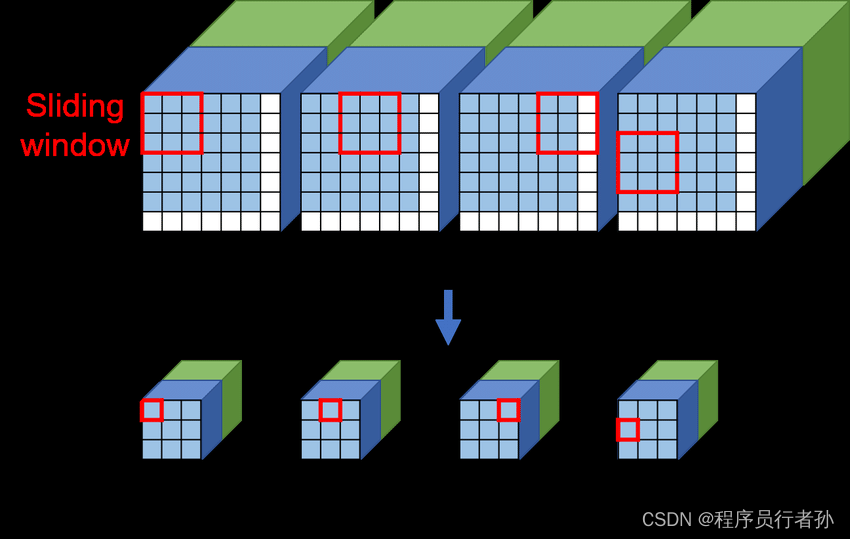
原理:
下采样是一种在神经网络中减少数据空间维度(例如,图像的宽度和高度)的技术,同时尝试保留最重要的特征。在卷积神经网络(CNN)中,这通常通过使用步长大于1的卷积核(例如,stride=2的3x3卷积核)来实现。步长卷积在减少特征图尺寸的同时,仍然通过卷积操作保持了一定程度的空间信息。
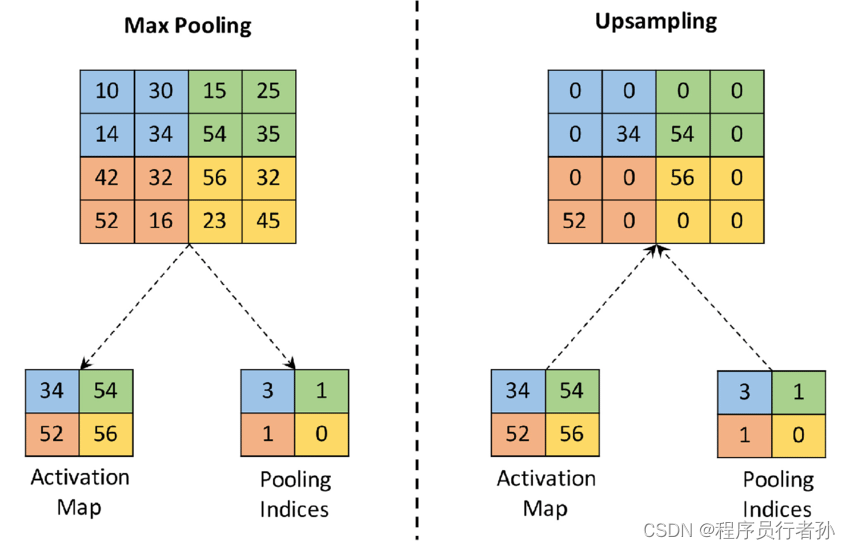
作用:
- 减少计算量:通过减少网络中的数据尺寸,可以显著降低模型的计算负担。
- 提高感受野:在不增加网络深度的情况下,下采样可以帮助网络更快地获得更大范围的感受野。
- 特征抽象:在深层网络中,下采样有助于从低层次的细节中抽象出高层次的特征。
代码分析:
在PyTorch框架中,一个步长卷积的下采样层可能看起来像这样:
import torch.nn as nn
class DownsamplingLayer(nn.Module):
def __init__(self, in_channels, out_channels):
super(DownsamplingLayer, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels,
kernel_size=3, stride=2, padding=1)
def forward(self, x):
return self.conv(x)
在这个例子中,DownsamplingLayer通过一个3x3的卷积核,步长为2,来实现下采样。
注意力机制(Attention Mechanism)的原理和作用:
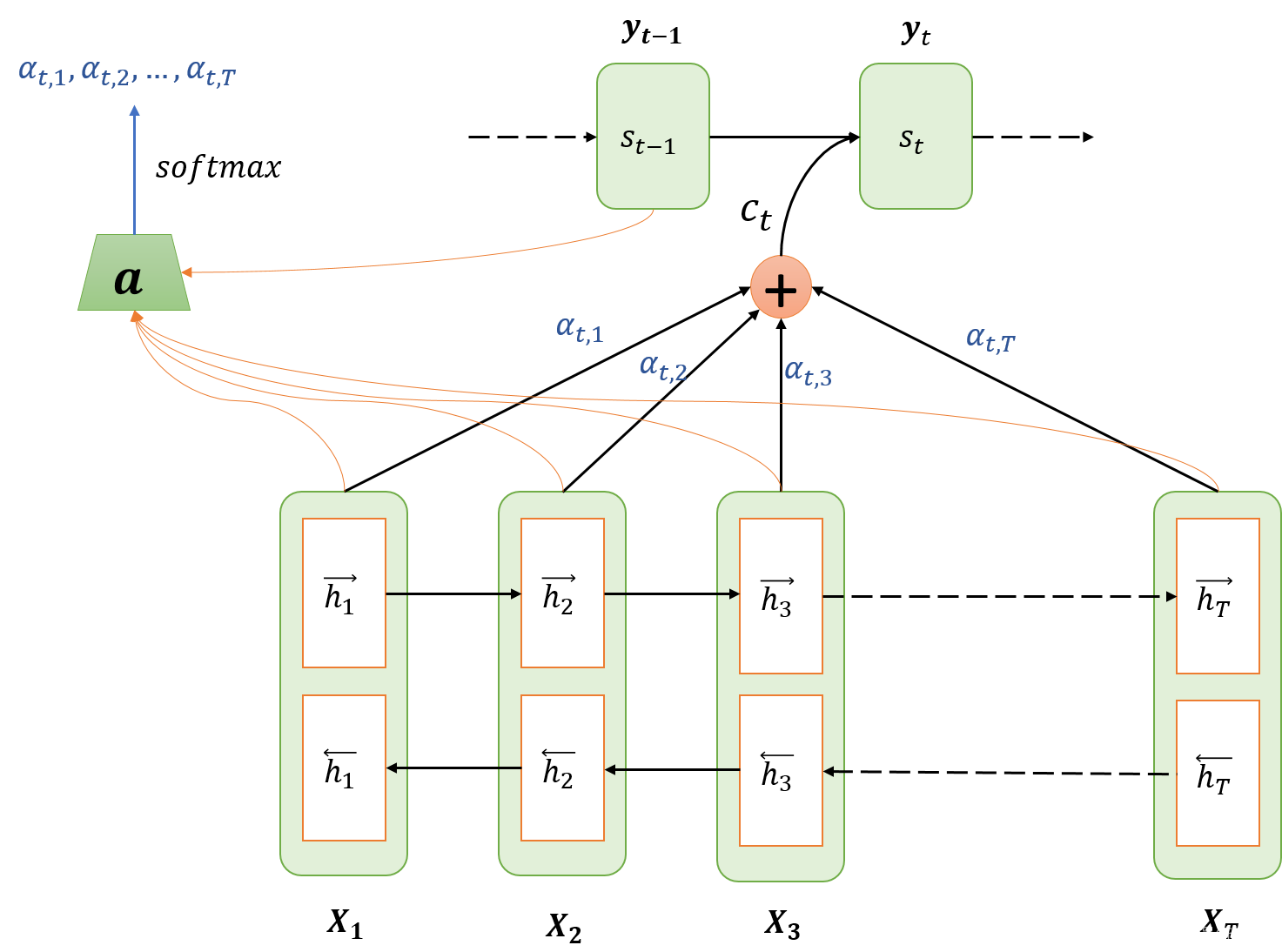
原理:
注意力机制是一种资源分配策略,它允许模型动态地聚焦于输入序列中最相关的部分。在视觉任务中,这可以帮助模型识别图像中最重要的区域。
作用:
- 增强特征表示:注意力机制可以提升模型对关键特征的感知能力。
- 提高模型性能:通过关注最相关的特征,可以提高模型在复杂任务上的性能。
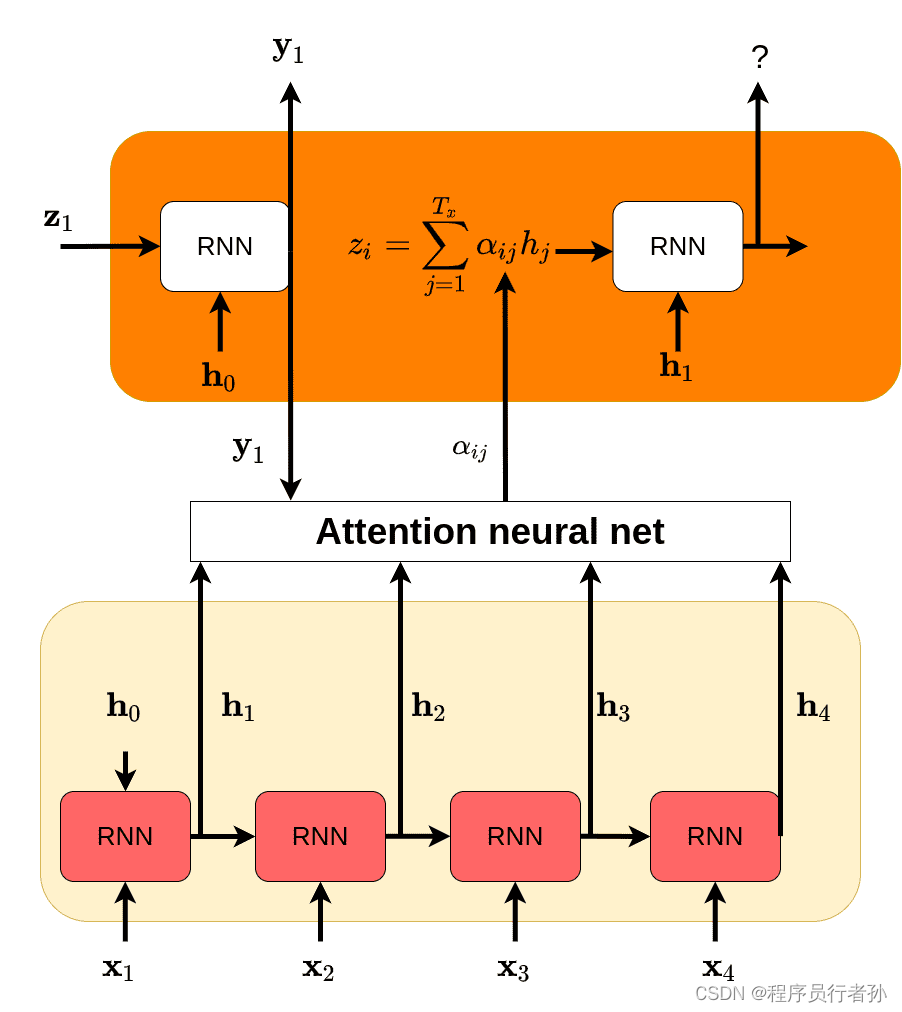
代码分析:
注意力机制的实现可以非常多样,以下是一个非常基础的注意力层的示例:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SimpleAttention(nn.Module):
def __init__(self, embed_size, heads):
super(SimpleAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.fc_out = nn.Linear(heads * self.head_dim, embed_size)
def forward(self, values, keys, query, mask):
N = query.shape[0]
value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]
# Split the embedding into 'heads' number of heads
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
queries = query.reshape(N, query_len, self.heads, self.head_dim)
values = self.values(values)
keys = self.keys(keys)
queries = self.queries(queries)
# Einsum does matrix multiplication for query*keys for each training example
# with a specific head
attention = torch.einsum('nqhd,nkhd->nhqk', [queries, keys])
if mask is not None:
attention = attention.masked_fill(mask == 0, float('-1e20'))
# Apply softmax activation to the attention scores
attention = F.softmax(attention / (self.embed_size ** (1 / 2)), dim=3)
out = torch.einsum('nhql,nlhd->nqhd', [attention, values]).reshape(
N, query_len, self.heads * self.head_dim
)
# Combine the attention heads together
out = self.fc_out(out)
return out
在这个例子中,SimpleAttention模块实现了多头注意力机制,它将输入分割成多个“头”,每个头学习不同的表示子空间。
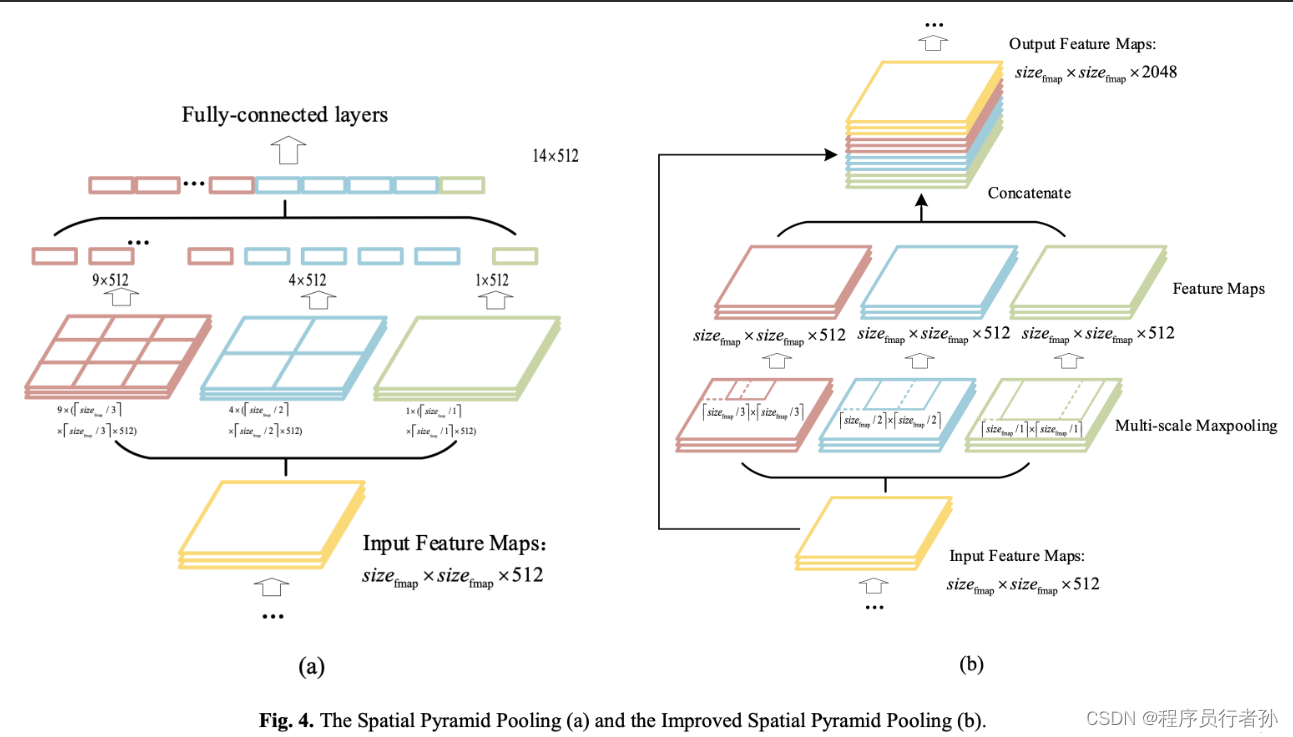
11. SPPELAN
SPPELAN是一种深度学习网络结构,它结合了空间金字塔池化(Spatial Pyramid Pooling, SPP)和高效局部聚合网络(Efficient Local Aggregation Network, ELAN)的特点。这种结构旨在提升目标检测模型的性能,尤其是在处理不同尺寸的目标时。
SPPELAN的原理和作用:
空间金字塔池化(SPP):
- 原理:SPP是一种池化技术,它允许网络在不同的尺度上进行特征提取,从而使得模型能够同时检测到不同大小的目标。SPP通过在不同的窗口大小上应用最大池化(MaxPooling)来实现这一点,这些窗口可以是1x1、3x3和5x5等。
- 作用:SPP使得模型在进行目标检测时对尺度变化更加鲁棒。
高效局部聚合网络(ELAN):
-
原理:ELAN是一种轻量级的注意力机制,它通过对局部特征进行聚合来增强模型对输入图像中重要区域的感知能力。ELAN通常由一系列操作组成,包括分组卷积(Group Convolution)、深度可分离卷积(Depthwise Separable Convolution)和逐点卷积(Pointwise Convolution)。
深度可分离卷积(Depthwise Separable Convolution):
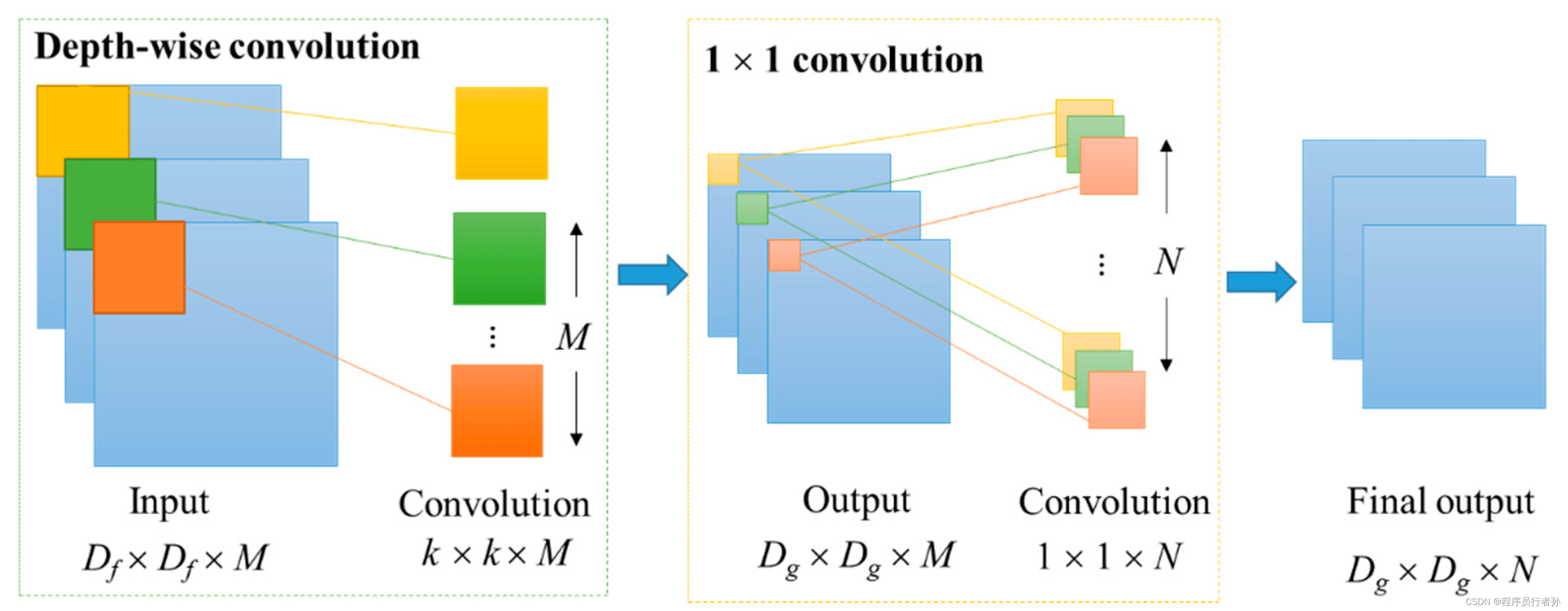
分组卷积(Group Convolution):
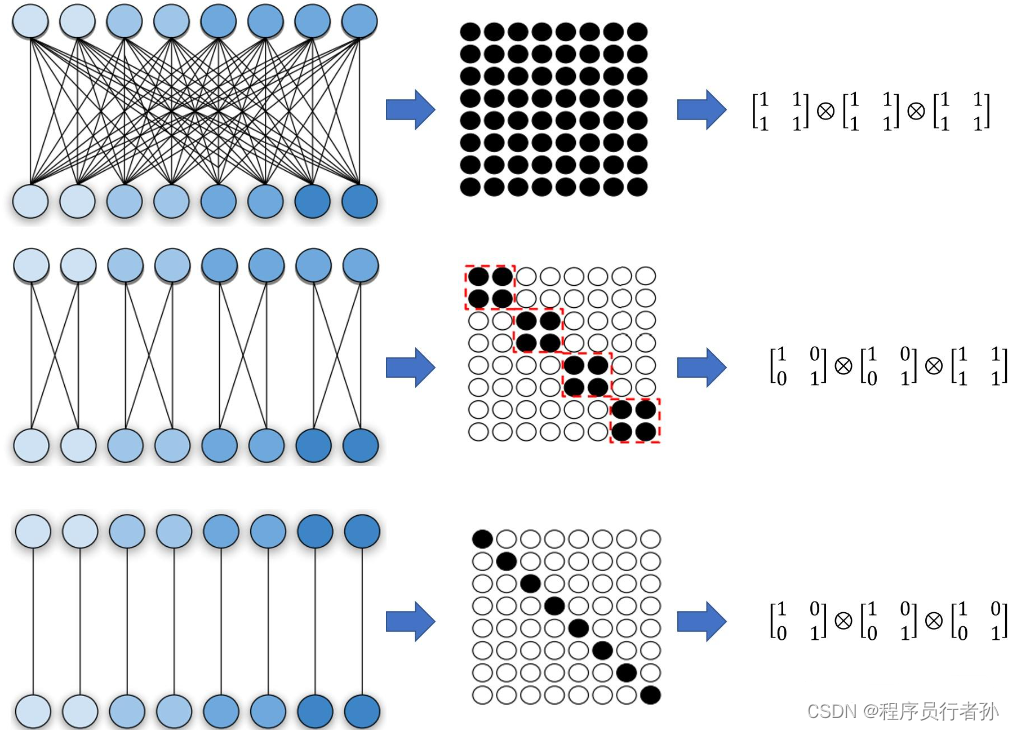
逐点卷积(Pointwise Convolution):
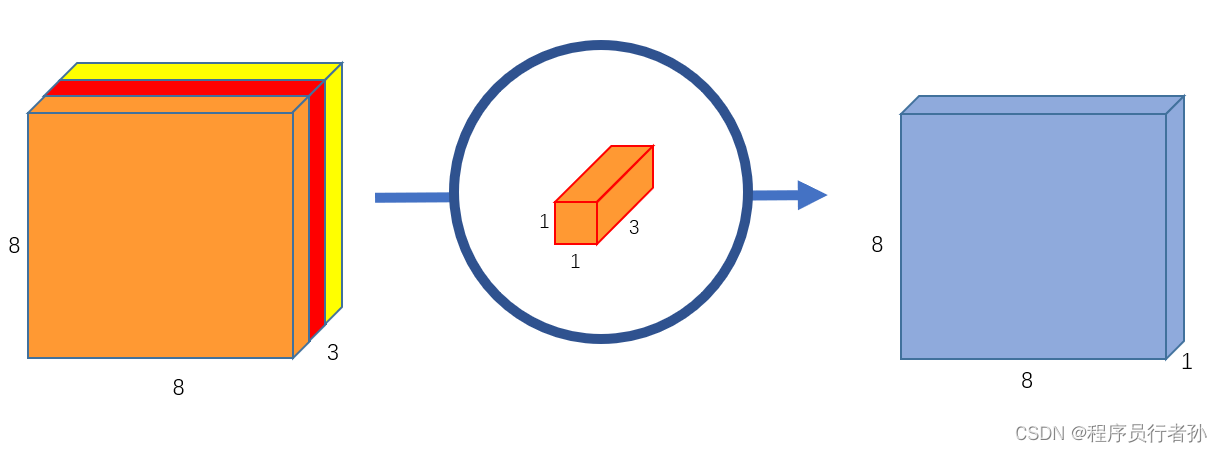
-
作用:ELAN通过局部特征的聚合提高了模型的表示能力,尤其是在特征图的局部区域内。
SPPELAN结合SPP和ELAN:
- 原理:SPPELAN结合了SPP的多尺度特征提取能力和ELAN的局部特征聚合能力。它首先使用SPP在不同尺度上提取特征,然后通过ELAN对这些特征进行局部聚合,以增强模型对关键信息的捕捉。
- 作用:SPPELAN通过这种结合,旨在提高模型对不同尺寸目标的检测能力,同时保持对图像中重要局部特征的敏感性。
代码分析:
根据搜索结果,SPPELAN的具体实现代码没有直接给出,但是可以根据其原理和作用来推测其可能的实现方式。以下是一个简化的伪代码示例,用于说明如何将SPP和ELAN的概念结合起来:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SPPELAN(nn.Module):
def __init__(self, in_channels, out_channels):
super(SPPELAN, self).__init__()
# 定义SPP层,这里简化为最大池化
self.spp = nn.MaxPool2d(kernel_size=[1, 1], stride=[1, 1], padding=0)
# 定义ELAN层
self.elan = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 1, 1, 0, groups=in_channels),
nn.Conv2d(out_channels, out_channels, 3, 1, 1, groups=out_channels)
)
def forward(self, x):
# 应用SPP
x_spp = self.spp(x)
# 应用ELAN
x_elan = self.elan(x_spp)
return x_elan
# 假设输入特征图
x = torch.randn(1, 512, 64, 64) # (batch_size, channels, height, width)
# 创建SPPELAN模块
sppelan = SPPELAN(in_channels=512, out_channels=256)
# 前向传播
output = sppelan(x)
在上述代码中,SPPELAN模块首先通过MaxPool2d实现SPP操作,然后通过一个简化的ELAN结构对特征图进行局部聚合。
12. Silence
在深度学习模型中,尤其是在目标检测模型YOLOv9中,"Silence"是一个特殊的模块。根据搜索结果,Silence模块位于YOLOv9网络的第一层,其作用主要是作为一个直通层(pass-through layer),它简单地将输入传递到下一个网络层而不进行任何操作。
Silence的原理和作用:
原理:
Silence模块的设计基于一个简单的概念,即在网络的某些部分不执行任何计算,而是直接将输入数据传递给后续层。这种设计可以用于简化网络结构,尤其是在构建具有多个输入和输出的复杂网络时。
作用:
- 简化网络结构:Silence作为一个直通层,可以简化网络的构建,尤其是在需要多尺度特征融合或多路径网络结构时。
- 保持数据流:它可以保持数据流在网络中的连续性,尤其是在多分支或多尺度处理的网络中,Silence可以帮助维持数据的完整性。
- 灵活性:在某些情况下,Silence层可以作为占位符使用,方便后续根据需要添加或替换操作。
代码分析:
根据搜索结果中提供的信息,Silence模块的代码实现非常简单:
class Silence(nn.Module):
def __init__(self):
super(Silence, self).__init__()
def forward(self, x):
return x
在这个PyTorch的实现中,Silence继承自nn.Module,其构造函数不执行任何操作,forward方法简单地将输入x返回,不做任何处理。
这种设计在实际中可能用于以下情况:
- 特征传递:在特征金字塔网络中,Silence可以帮助将低层次的特征直接传递到高层次,而不经过任何修改。
- 网络调试:在开发过程中,Silence可以用作临时层,以便于观察在移除某些操作后网络性能的变化。
- 结构兼容性:在集成不同模块或与其他网络结构结合时,Silence可以作为一个适配层,以确保数据维度和流程的一致性。
Silence模块的具体作用可能依赖于它在网络中的位置和整个网络的设计。在YOLOv9中,Silence模块可能用于处理输入图像,为后续的卷积层提供直接的图像数据输入。



















 1617
1617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











