






1. 输入系统应用编程
1.1 输入系统介绍
常见的输入设备有键盘、鼠标、遥控杆、书写板、触摸屏等。用户经过这些输入设备与Linux系统进行数据交换。这些设备种类繁多,如何去统一它们的接口,Linux为了统一管理这些输入设备实现了一套能兼容所有输入设备的框架叫做输入系统。
1.1 输入系统框架
输入框架主要由输入系统的驱动层,输入系统核心层,输入系统时间层以及用户空间tslib, libinput等组成。
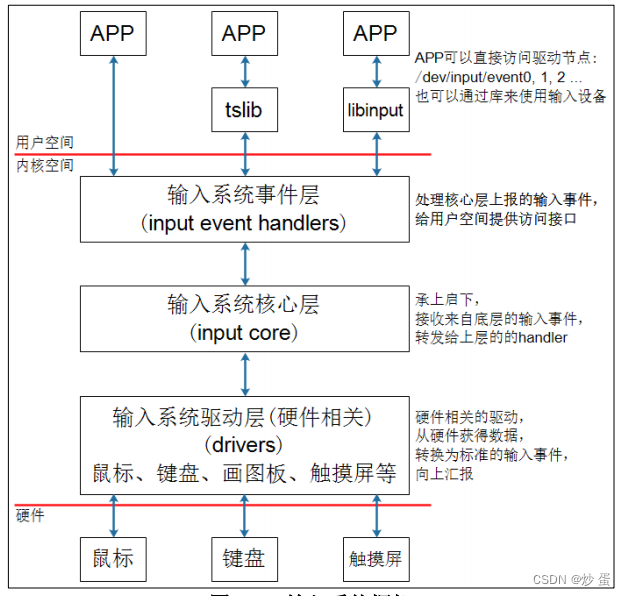
输入系统驱动层:负责从硬件处获取数据,转换为标准的输入事件,常见的硬件有鼠标、键盘、画图板和触摸屏等。
输入系统核心层:接收硬件驱动层的输入,将硬件获取的数据转换为统一的格式并发送给系统事件层。
输入系统事件层:用于给用户空间提供接口
用户空间APP: APP可以直接打开驱动节点访问,也可以通过库tslib或libinput等使用输入设备。
数据的流程
1 APP发起读操作,若无数据则休眠;
2. 用户操作设备,硬件上产生中断
3. 输入系统驱动层对应的驱动程序处理中断:
读取到数据,转为标准的输入事件,并向核心层汇报
4. 输入系统核心层决定将输入事件转发给哪个handler处理。
5. 时间层的handler接收到事件后根据谁调用了他就唤醒哪个APP,对应的APP就可以返回数据了。
6. APP 获 得 数 据 的 方 法 有 2 种 :
直 接 访 问 设 备 节 点 比如/dev/input/event0,1,2,...
通过 tslib、libinput 这类库来间接访问设备节点。这些库简化了对数据的处理。
1.2 编写APP需要掌握的知识
APP得到的一些列输入事件本质是一个个"struct input_event",它的定义如下: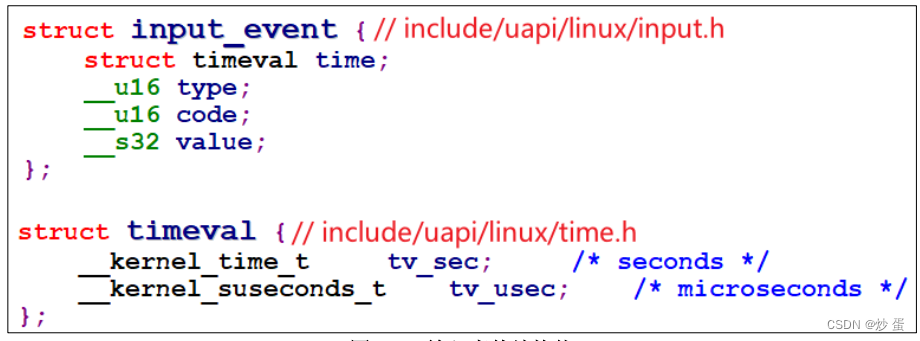
每个输入事件都含有timeval结构体,表示的是“自系统启动以来过了多少时间”, 它是一个结构体,含有“tv_sec、tv_usec"两项(即秒、微秒)。
驱动程序上报数据含义的三项重要内容:
type: 代表类, 比如EV_KEY,按键类
code: 哪个, 比如KEY_A
value: 值,比如0-按下,1-松开
1.3 调试技巧
1.确定设备信息
输入设备的设备节点名为/dev/input/eventX(也可能是/dev/eventX, X表示0、1、2等数字)
ls /dev/input/* -l
或
ls /dev/event* -l可以看到下面的图 
如何知道这些设备节点对应什么硬件呢?
cat /proc/bus/input/devices
1. I: 设备ID
2. N: 设备名称
3. P: 系统层次结构中设备的物理路径
4. S:位于sys文件系统的路径
5. U:设备的唯一标识码
6. H: 与设备关联的输入句柄列表
7. B:位图, 如B: EV=B 用来表示该设备支持那类输入事件, B: ABS=2568000 3表示该设备支持EV_ABS这一类事件的哪些事件。

2. 使用命令读取数据
调试输入系统时,直接执行类似下面的命令,然后操作对应的输入设备即可读出数据:
hexdump /dev/input/event0
3 APP访问硬件的四种方式
查询方式:
APP调用open函数时,传入"O_NONBLOCK"表示“非阻塞”, APP调用read函数读取数据的时候,如果驱动程序中有数据,那么APP的read函数会返回数据否则会立即返回错误。
休眠-唤醒方式:
APP调用open函数的时候,不传入"O_NONBLOCK"。
APP调用read时,如果驱动中有数据,那么read会返回数据,否则APP就在内核态休眠,当有数据时驱动会把APP唤醒,read函数恢复指向并返回数据给APP。
POLL/SELECT方式
POLL 机制、SELECT 机制是完全一样的,只是 APP 接口函数不一样。他们就是定一个闹钟,在调用poll、select函数可以传入“超时时间”。在这段时间内,条件合适时(比如有数据可读、有空间可写)就会立刻返回,否则等到“超时时间”结束时返回错误。调用poll或select后如果有人操作了硬件,驱动程序获得数据后就会把APP唤醒,导致poll或select返回,如果在超时时间内无人操作硬件,则 时间到后 poll 或 select 函数也会返回。APP 可以根据函数的返回值判断返回 原因:有数据?无数据超时返回?
14 int main(int argc, char **argv)
15 {
16 int fd;
26 struct pollfd fds[1];
……
61 fd = open(argv[1], O_RDWR | O_NONBLOCK);
……
94 while (1)
95 {
96 fds[0].fd = fd;
97 fds[0].events = POLLIN;
98 fds[0].revents = 0;
99 ret = poll(fds, nfds, 5000);
100 if (ret > 0)
101 {
102 if (fds[0].revents == POLLIN)
103 {
104 while (read(fd, &event, sizeof(event)) == sizeof(even
t))
105 {
106 printf("get event: type = 0x%x, code = 0x%x, val
ue = 0x%x\n", event.type, event.code, event.value);
107 }
108 }
109 }
110 else if (ret == 0)
111 {
112 printf("time out\n");
113 }
114 else
115 {
116 printf("poll err\n");
117 }
118 }
119
120 return 0;
121 }
122
步骤:
1. APP先调用open函数
2. 设置pollfd结构体
3. 设置查询的文件
4. 设置查询的事件
5. 清除“返回的事件”
6. 使用poll函数查询事件,指定超时时间
7. APP根据poll的返回值判断有数据之后,就调用read函数读取数据。
异步通知方式
所谓异步通知,就是 APP 可以忙自己的事,当驱动程序用数据时它会主动给APP 发信号,这会导致 APP 执行信号处理函数。
驱动程序通知APP时,它会发出“SIGIO”这个信号,表示有“IO事件”要处理。而APP要想处理SIFIO信息需要提供信号处理函数,并且要跟SIGIO挂钩,可以通过一个signal函数来“给某个信号注册处理函数”用法如下:
#include <signal.h>
typedef void (*sighandler_t)(int); // 1.编写函数
sighandler_t signal(int signum, sighandler_t); // 2. 注册内核里有那么多驱动,你想让哪一个驱动给你发SIGIO信号?
APP首先要打开驱动程序的设备节点,然后把进程ID高速驱动程序,并使用FASYNC位为1使能异步通知。
// 编写驱动程序
static void sig_func(int sig)
{
int val;
read(fd, &val, 4);
printf("get button : 0x%x\n", val);
}
// 注册信号处理函数
signal(SIGIO, sig_func)
// 打开驱动
fd = open(argv[1], O_RDWR);
//把进程ID告诉驱动
fcntl(fd, F_SETOWN, getpid());
// 使能驱动的FASYNC功能
flags = fcntl(fd, F_GETFL);
fcntl(fd, F_SETFL, flags | FASYNC);
2. 网络编程
2.1 网络通信基础知识
大部分的网络应用系统可以分为两个部分:客户和服务器,网络服务程序架构有CS模式或者BS模式。
CS即Client/Server(客户机/服务器)结构:C/S结构的主要特点是交互性强、具有安全的存取模式、网络通信量低、响应速度快、利于处理大量数据。该结构的程序是针对性开发,变更不够灵活,维护和管理的难度较大。并且,由于该结构的每台客户机都需要安装相应的客户端程序,分布功能弱且兼容性差,不能实现快速部署安装和配置,因此缺少通用性,具有较大的局限性。
BS即Browser/Server(浏览器/服务器)结构:只安装维护一个服务器(Server),客户端采用**浏览器**运行软件。B/S结构应用程序相对于传统的C/S结构应用程序是一个非常大的进步。 B/S结构的主要特点是分布性强、维护方便、开发简单且共享性强、总体拥有成本低。但数据安全性问题、对服务器要求过高、数据传输速度慢、软件的个性化特点明显降低,这些缺点是有目共睹的,难以实现传统模式下的特殊功能要求。
OSI七层网络协议
七层网络参考模型(OSI参考模型)是国际标准化组织指定的一个用于计算机或通信系统间互联的标准体系。

- 物理层:定义物理设备标准,如网线的接口类型、光纤的接口类型、各种传输介质的传输速率等。它的主要作用是传输比特流。(数据为比特)
- 数据链路层:建立逻辑连接、进行硬件地址寻址、差错校验等功能。定义了如何让格式化数据以帧为单位进行传输,以及如何让控制对物理介质的访问。
- 网络层:进行逻辑地址寻址,在位于不同地理位置的网络中的两个主机系统之间提供连接和路径选择。Internet的发展使得从世界各站点访问信息的用户数大大增加,而网络层正是管理这种连接的层。
- 传输层:定义了一些传输数据的协议和端口号( WWW 端口 80 等),如:TCP(传输控制协议,传输效率低,可靠性强,用于传输可靠性要求高,数据量大的数据),UDP(用户数据报协议,与TCP 特性恰恰相反,用于传输可靠性要求不高,数据量小的数据,如 QQ 聊天数据就是通过这种方式传输的)。 主要是将从下层接收的数据进行分段和传输,到达目的地址后再进行重组。常常把这一层数据叫做段。
- 会话层:通过传输层(端口号:传输端口与接收端口)建立数据传输的通路。主要在你的系统之间发起会话或者接受会话请求。
- 表示层:数据的表示、安全、压缩。主要是进行对接收的数据进行解释、加密与解密、压缩与解压缩等。
- 应用层:网络服务与最终用户的一个接口。这一层为用户的应用程序(例如电子邮件、文件传输和终端仿真)提供网络服务。
TCP/IP四层模型
TCP/IP 协议在一定程度上参考了 OSI 的体系结构

- 应用层:它是体系结构中的最高层,直接为用户的应用进程提供服务。在因特网中的应用层协议很多,如支持万维网应用的 HTTP 协议,支持电子邮件的 SMTP 协议,支持文件传送的 FTP 协议,DNS,POP3,SNMP,Telnet 等等。
- 运输层:负责向两个主机中进程之间的通信提供服务。主要使用以下两种协议TCCP和UDP。
- 网络层:负责将被称为数据包(datagram)的网络层分组从一台主机移动到另一台主机。
- 链路层(网卡层):因特网的网络层通过源和目的地之间的一系列路由器路由数据报。
- 物理层(硬件层):在物理层上所传数据的单位是比特。物理层的任务就是透明地传送比特流。
2.2 TCP
TCP协议是面向连接的通信协议,即传输数据之前,在发送端和接收端建立逻辑连接,然后再传输数据,它提供了两台计算机之间可靠无差错的数据传输。

- 32位序号:TCP将要传输的每个字节都进行了编号,序号是本报文段发送的数据组的第一个字节的编号,序号可以保证传输信息的有效性。比如:一个报文段的序号为300,此报文段数据部分共有100字节,则下一个报文段的序号为401。
- 32位确认序号:每一个ACK对应这一个确认号,它指明下一个期待收到的字节序号,表明该序号之前的所有数据已经正确无误的收到。确认号只有当ACK标志为1时才有效。比如建立连接时,SYN报文的ACK标志位为0。
- 4位首部长度(数据偏移): 表示该TCP头部有多少个32位bit(有多少个4字节),所以TCP头部大长度是15 * 4 = 60。根据该部分可以将TCP报头和有效载荷分离。TCP报文默认大小为20个字节。
- 6位标志位:
URG:它为了标志紧急指针是否有效。
ACK:标识确认号是否有效。
PSH:提示接收端应用程序立即将接收缓冲区的数据拿走。
RST:它是为了处理异常连接的, 告诉连接不一致的一方,我们的连接还没有建立好,要求对方重新建立连接。我们把携带RST标识的称为复位报文段。
SYN:请求建立连接; 我们把携带SYN标识的称为同步报文段。
FIN:通知对方, 本端要关闭连接了, 我们称携带FIN标识的为结束报文段。
TCP建立连接需要三次握手
(1)Client首先向Server发送连接请求报文段,同步自己的seq(x),Client进入SYN_SENT状态。
(2)Server收到Client的连接请求报文段,返回给Client自己的seq(y)以及ack(x+1),Server进入SYN_REVD状态。
(3)Client收到Server的返回确认,再次向服务器发送确认报文段ack(y+1),这个报文段已经可以携带数据了。Client进入ESTABLISHED状态。
(4)Server再次收到Client的确认信息后,进入ESTABLISHED状态。

TCP断开连接需要四次握手
(1)Client向Server发送断开连接请求的报文段,seq=m(m为Client最后一次向Server发送报文段的最后一个字节序号加1),Client进入FIN-WAIT-1状态。
(2)Server收到断开报文段后,向Client发送确认报文段,seq=n(n为Server最后一次向Client发送报文段的最后一个字节序号加1),ack=m+1,Server进入CLOSE-WAIT状态。此时这个TCP连接处于半开半闭状态,Server发送数据的话,Client仍然可以接收到。
(3)Server向Client发送断开确认报文段,seq=u(u为半开半闭状态下Server最后一次向Client发送报文段的最后一个字节序号加1),ack=m+1,Server进入LAST-ACK状态。
(4)Client收到Server的断开确认报文段后,向Server发送确认断开报文,seq=m+1,ack=u+1,Client进入TIME-WAIT状态。
(5)Server收到Client的确认断开报文,进入CLOSED状态,断开了TCP连接。
(6)Client在TIME-WAIT状态等待一段时间(时间为2*MSL((Maximum Segment Life)),确认Client向Server发送的最后一次断开确认到达(如果没有到达,Server会重发步骤(3)中的断开确认报文段给Client,告诉Client你的最后一次确认断开没有收到)。如果Client在TIME-WAIT过程中没有再次收到Server的报文段,就进入CLOSES状态。TCP连接至此断开

2.3 UDP
用户数据报协议(User Datagram Protocol)。UDP协议是一个面向无连接的协议。传输数据时,不需要建立连接,不管对方端服务是否启动,直接将数据、数据源和目的地都封装在数据包中,直接发送。每个数据包的大小限制在64k以内。它是不可靠协议,因为无连接,所以传输速度快,但是容易丢失数据。日常应用中,例如视频会议、QQ聊天等。

- 16位UDP长度表示整个数据报(UDP首部+UDP数据)的长度
- 如果校验和出错,就会直接丢弃(UDP校验首部和数据部分)
TCP和UDP的区别?
1. TCP是面向连接而UDP是无连接的
2. TCP是提供可靠的服务,保证无差错无丢失,不重复且按序到达,UDP则是尽最大的努力进行交付,不保证可靠交付。
3. TCP是面向字节流的,而UDP是面向报文的,UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低,常用于实时通信。
4. 每一条的TCP只能是点到点的,UDP支持一对一,一对多,多对一和多对多的交互通信
5. 头部开销TCP位20字节,UDP为8字节
6. TCP的逻辑通信的信道是全双工的可靠信道,而UDP则是不可靠信道。
为何存在UDP协议?
既然 TCP 提供了可靠数据传输服务,而 UDP 不能提供,那么 TCP 是否总是首选呢?
答案是否定的,因为有许多应用更适合用 UDP ,举个例子:视频通话时,使用 UDP ,偶尔的丢包、偶尔的花屏时可以忍受的;如果使用 TCP ,每个数据包都要确保可靠传输,当它出错时就重传,这会导致后续的数据包被阻滞,视频效果反而不好。所以需要传输时效好的时候应该采用UDP。
2.4 网络编程的主要函数
(1) socket()函数: 用于创建套接字, 同时指定协议和类型。
#include <sys/types.h>
#include <sys/socket.h>//需要引入的头文件
int socket(int domain, int type, int protocol);
参数:
domain: 指明所使用的协议族,通常为AF_INET,表示互联网协议族(TCP/IP协议族)
type: 参数指定socket的类型。
SOCK_STREAM: 使用TCP。
SOCK_DGRAM: 使用UDP。
SOCK_RAW: 允许程序使用底层协议原始套接字允许对底层协议如IP或ICMP
进行直接访问,功能强大但使用较为不便,主要用于一些协议的开发。
protocol: 通常赋值为“0”, 代表选择type类型对应的默认协议
返回值:
成功返回非负套接字描述符,失败返回-1
(2) bind()函数: 用于绑定IP地址和端口号到socket
int bind(int sockfd, const struct sockaddr *addr,socklen_t addrlen);
参数:
sockfd: 是一个socket描述符。
addr:是一个指向包含有本机IP地址及端口号等信息的sockaddr类型的指针,指向要绑
定给sockfd的协议地址结构。这个输入可以在#include <sys/socket.h>里的
sockaddr所赋值,但是他的sa_data把目标地址和端口信息混合了,可以将其
变成#include<netinet/in.h>或#include <arpa/inet.h>中定义的sockaddr_in结构体
该结构体解决了sockaddr的缺陷,把port和addr 分开储存在两个变量中,可以
可以将其赋值后然后强制类型转换为sockaddr。
addrlen: 地址的长度,一般用于sizeof(struct sockaddr_in)表示。
返回值:
成功返回0, 失败返回-1.

(3) listen()函数 监听被绑定的端口,维护两个队列,一个是未完成连接队列,等待完成TCP三次握手(SYN_REVD),另一个是已完成连接队列,表示已完成三次握手的客户端,这些套接字处于ESTABLISHED状态。
int listen(int sockfd, int backlog);
参数:
sockfd:socket系统调用返回的服务端socket描述符
backblog:指定在请求队列 中允许的最大请求数,大多数系统默认为5.
返回值:
成功返回0, 失败返回1
(4) accept()函数,该函数由TCP服务器调用,用于从已完成连接队列对头返回下一个已完成连接,如果已完成连接队列为空,那么进程被投入睡眠。
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
参数:
sockfd:是socket系统调用返回的服务器端socket描述符
addr:用来返回已连接的对端(客户端)的协议地址
addrlen:客户端地址长度,注意需要取地址
返回值:
accept 调用时,服务器端的程序会一直阻塞到有一个客户程序发出了连接。 accept 成功时返回最后的服务器端的文件描述符,这个时候服务器端可以向该 描述符写信息了,失败时返回-1 。
(5)connect()函数, 该函数用于绑定之后的client端(客户端),与服务器建立连接
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
参数:
sockfd: 创建的socket描述符
addr: 服务端的ip地址和端口号的地址结构指针
addrlen:地址的长度,通常被设置为sizeof(struct sockaddr)
返回值:成功返回0,遇到错误时返回-1,并且errno中包含相应的错误码。
(6) send()、recv() 函数只能对于连接状态函数只能对处于连接状态的套接字进行使用,参数sockfd为已建立好连接的套接字描述符, 这是用于TCP发送和接收信息。
ssize_t send(int sockfd, const void *buf, size_t len, int flags);
参数:
sockfd: 为已建立好连接的套接字描述符即accept函数的返回值
buf: 要发送的内容
len:发送内容的长度
flags:设置为MSG_DONTWAITMSG时表示非阻塞,设置为0时,功能和write一样。
返回值:
成功返回实际发送的字节数,失败返回-1.
ssize_t recv(int sockfd, const void *buf, size_t len, int flags);
参数:
sockfd: 在哪个套接字接
buf:存放要接收的数据的首地址
len:要接收的数据的字节
flags:设置为
MSG_DONTWAITMSG时 表示非阻塞,设置为0时 功能和read一样返回值:成功返回实际发送的字节数失败返回-1.
(7) sendto()、recvfrom()函数(UDP发送、接收消息)
int sendto(int s, const void *buf, int len, unsigned int flags, const struct sockaddr *to, int tolen);
参数:
s:socket描述符
buf: UDP数据报缓冲区
len:UDP数据报的长度
flags:调用方式标志位(一般设置为0),设置为
MSG_DONTWAITMSG时 表示非阻塞
to:指向接收数据的主机地址信息的结构体(sockaddr_in需类型转换);
tolen:to所指结构体的长度;返回值:成功则返回实际传送出去的字符数,失败返回-1,错误原因会存于errno 中。
int recvfrom(int s, void *buf, int len, unsigned int flags,struct sockaddr *from, int *fromlen);
参数:
s: socket描述符;
buf: UDP数据报缓存区(包含所接收的数据);
len: 缓冲区长度。
flags: 调用操作方式(一般设置为0),设置为MSG_DONTWAITMSG 时 表示非阻塞
from: 指向发送数据的客户端地址信息的结构体(sockaddr_in需类型转换);
fromlen:指针,指向from结构体长度值。返回值:成功则返回实际接收到的字符数,失败返回-1,错误原因会存于errno 中。
2.5 TCP/UDP的socket通信流程


网络字节序的定义:将收到的第一个字节的数据当做高位来看待,这就要求发送端的发送的第一个字节应该是高位。而在发送端发送数据时,发送的第一个字节是该数字在内存中起始地址对应的字节。可见多字节数值在发送前,在内存中数值应该以大端法存放。
uint16_t htons(uint16_t hostshort);//将16位主机字节序数据转换成网络字节序数据
uint32_t htonl(uint32_t hostlong);//将32位主机字节序数据转换成网络字节序数据
将网络字节序转换主机字节序函数
uint16_t ntohs(uint16_t netshort);//将16位网络字节序数据转换成主机字节序数据
uint32_t ntohl(uint32_t netlong);//将32位网络字节序数据转换成主机字节序数据
2.6 TCP/UDP例程
服务器端
#include <stdio.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <errno.h>
#include <arpa/inet.h>
#include <sys/types.h>
#include <unistd.h>
#include <string.h>
int main()
{
int s_fd;//socket 返回的套接字,服务器端
int c_fd;//accept函数返回的客户端的套接字
int ret;
int c_len;//客户端结构体的大小
int readSize;
int quit_flag = 0;
pid_t pid;
char readBuf[128] = {'\0'};//存放读取的客户端内容
char writeBuf[128] = {'\0'};//存放发往客户端的内容
char ipBuf[32] = {'\0'};
struct sockaddr_in s_addr;//设置本机ip地址及端口的结构体
struct sockaddr_in c_addr;//接收的客户端的ip地址及端口的结构体
//1.创建套接字(socket)
s_fd = socket(AF_INET,SOCK_STREAM, 0);
if(s_fd<0){
perror("creat socket fail");
return -1;
}
s_addr.sin_family = AF_INET;
s_addr.sin_port = htons(8989);//绑定端口号,并将端口号变为网络字节序
ret = inet_aton("192.168.109.137",&s_addr.sin_addr);//绑定本机IP地址,并将其转换为二进制IP地址
if(ret == 0){
perror("inet_aton fail");
return -1;
}
//2.将socket与IP地址和端口绑定(bind)
ret = bind(s_fd,(struct sockaddr*)&s_addr,sizeof(struct sockaddr_in));//注意将struct sockaddr_in*强制转换为struct sockaddr*
if(ret < 0){
perror("bind fail");
return -1;
}
//3.监听被绑定的端口(listen)
listen(s_fd,5);
c_len = sizeof(struct sockaddr_in);
while(1){
//4.接收连接请求(accept)
c_fd = accept(s_fd, (struct sockaddr*)&c_addr, &c_len);
if(c_fd < 0){
perror("accept error");
}else{
memset(ipBuf,'\0',32);
strcpy(ipBuf,inet_ntoa(c_addr.sin_addr));
printf("get connect:%s\n",ipBuf);//将客户度链接的地址转换为十进制打印
pid = fork();
//创建子进程对接每个客户端
if(pid == 0)
{
pid_t pid;
pid = fork();
if(pid > 0){
while(1){
printf("message to the IP :%s:",ipBuf);
memset(writeBuf,'\0',128);
scanf("%s",writeBuf);
write(c_fd,writeBuf,strlen(writeBuf));
}
}else if(pid == 0){
while(1){
//从socket中读取客户端发送来的信息(read)进程
memset(readBuf,'\0',sizeof(readBuf));
readSize = read(c_fd,readBuf,128);
if(readSize < 0){
perror("read fail");
}else if(readSize == 0){
printf("client quits\n");
break;
}else{
printf("IP %s :%s\n",inet_ntoa(c_addr.sin_addr),readBuf);
}
}
//发送信息到客户端
}
}
}
}
//7.关闭socket(close)
close(c_fd);
close(s_fd);
return 0;
}
客户端
#include <signal.h>
#include <sys/types.h>
#include <stdio.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <errno.h>
#include <arpa/inet.h>
#include <sys/types.h>
#include <unistd.h>
#include <string.h>
#include <stdlib.h>
int main(int argc,char *argv[])
{
int c_fd;//客户端套接字
int ret;
int readSize;
pid_t pid;
char readBuf[128] = {'\0'};//存放读取的服务器内容
char writeBuf[128] = {'\0'};//存放发往服务器的内容
struct sockaddr_in addr;//想要连接的目标地址
if(argc < 3){
printf("the param is not good! Please in put ip and port\n");
exit(-1);
}
//1.创建套接字(socket)
c_fd = socket(AF_INET,SOCK_STREAM,0);
if(c_fd<0){
perror("creat socket fail");
return -1;
}
addr.sin_family = AF_INET;
addr.sin_port = htons(atoi(argv[2]));//设置目标端口
inet_aton(argv[1],&addr.sin_addr);//设置目标IP地址
//2.连接指定计算机的端口(connect)
ret = connect(c_fd,(struct sockaddr*)&addr,sizeof( struct sockaddr_in));
if(ret<0 ){
perror("connect error");
return -1;
}
pid = fork();
if(pid > 0){
while(1)
{
//3.从socket中读取服务端发送过来的消息(read)
memset(readBuf,0,sizeof(readBuf));
readSize = read(c_fd,readBuf,128);
if(readSize == -1)
{
perror("read");
}
printf("get %d from the sever:%s\n",readSize,readBuf);
}
}else if(pid ==0){
while(1){
//4.向服务区中发送数据
printf("Please input:");
memset(writeBuf,'\0',128);
scanf("%s",writeBuf);
write(c_fd,writeBuf,strlen(writeBuf));
if(strstr(writeBuf,"quit")!=NULL){
kill(getppid(),9);
kill(getpid(),9);
}
}
}
return 0;
}
3 进程
3.1 进程简介
概念:程序的一个执行实例,正在执行的程序。
进程=对应的代码和数据+进程对于的PCB控制块
内核观点:担当分配系统资源(CPU时间,内存的实体)
当我们双击可执行程序运行的时候本质上是将这个程序加载到内存中,然后CPU对其进行逐行的语句执行,一旦程序加载到内存后,严格意义上应该将其称为进程。

描述进程-PCB
操作系统如何获得进程信息?
进程信息被放在一个叫做进程控制块的数据结构中,可以理解为进程属性的集合,简称为PCB。操作系统将这些PCB以双链表的形式组织在一起,那么操作系统只要拿到双链表的头指针便可以访问到所有的PCB。

Linux中描述PCB的结构体
由于Linux是用C语言进行编写的,那么Linux中的进程控制块必定是用结构体来实现的。Linux中的PCB叫做task_struct,当进程创建的时候它会被装载到RAM内存里。
task_struct的内容
标示符(pid):描述本进程的唯一标识符,用来区别其他进程
状态:任务状态
优先级:相对于其他进程的优先级
程序计数器: 程序中即将被执行的下一条指令的地址
内存指针:包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块指针
上下文数据:进程执行时处理器的寄存器中的数据
I/O状态信息:包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表
记账信息:可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等
上下文数据的理解:上下文数据是指具体的上下文信息,它包括了程序或者系统的状态、寄存器值、内存映射、文件描述符、信号处理器等具体数据。CPU在怕跑一个进程时,没有跑完就开始切换其他进程,为了下次继续跑完这个进程,会保留这个进程的上下文数据,当这个进程回来时,会把上下文数据移动到CPU内部继续执行。

Linux中如何查看进程
1. 在根目录下有一个名为proc的系统文件夹,文件夹中包含大量的进程信息,其中有些子目录的目录名为数字,这些数字其实就是某一进程的PIC,如果要查看对应进程的信息直接ls /proc/<pid> 即可。

2. 通过ps命令查看, 集合grep搜索可以只显示需要查看的进程的信息。
ps aux
Linux如何获取标识符
#include <stdio.h>
#include <unistd.h>
int main()
{
while(1)
{
printf("PID: %d, PPID: %d\n", getpid(), getppid());
sleep(1);
}
return 0;
}getpid()是获取当前进程的标识符,getppid() 是获取父进程的标识符,这两个都是系统调用函数。
Linux如何创建子进程
fork是使用系统调用级别的函数创建一个子进程。
fork函数的返回值:
1. 如果子进程创建成功,在父进程中返回子进程的PID, 而在子进程中返回0
2. 如果子进程创建失败,则在父进程中返回-1
注意: fork函数被调用之前的代码被父进程执行,而fork函数之后的代码,则默认情况下父子进程都可以执行,父子进程虽然代码共享,但是父子进程的数据各自开辟空间。
fork函数到底做了什么?
fork函数创建子进程并不是在内存中重新拷贝一份代码和数据,而是在内存中以父进程为模板创建一个新的PCB结构,其实父子进程是PCB不一样,但是他们指向的代码和数据是同一份。

fork函数为什么能够实现父子进程代码和数据的独立性?
写时拷贝(copy-on-write, COW)就是等到修改数据时才真正分配内存空间,这是对程序性能的优化,可以延迟甚至是避免内存拷贝,当然目的就是避免不必要的内存拷贝。维护一个开辟的4个字节的空间,用来记录有多少个指针指向这片空间。 当我们父子进程尝试去修改数值的值时,便会触发写时拷贝,写时拷贝会给我们复制一份当前数据的值,让我们的父子进程去其他位置修改数据。

fork为什么有两个返回值?
fork 系统调用函数在执行 return 语句之前,子进程就已经创建完成甚至已经被操作系统调度了,所以当执行 return 语句返回结果的时候,OS自动触发写时拷贝,分别把结果传入两者的备份空间中。
3.2 进程的状态
理论上的进程状态
创建状态: 当一个进程被创建时,它处于创建状态。在这个阶段,操作系统为进程分配必要的资源(将代码和数据拷贝到内存,创建PCB结构体等),并为其分配一个唯一的进程标识符(PID)。
就绪状态:进程就绪状态是指进程已经满足了运行的条件,进程PCB被调度到CPU运行队列中,排队等待系统分配CPU资源来执行的状态。
运行状态:进程PCB被调度到CPU运行队列中且已被分配CPU资源,就叫做运行态。在这个阶段,进程的指令会被执行,它可以访问CPU和其他系统资源。只有运行状态下的进程才能占用CPU资源。
阻塞状态:当一个进程无法继续执行,因为它需要等待某些非CPU资源就绪时,它会进入阻塞状态。这些事件可能包括等待用户输入、等待磁盘I/O操作完成等。在阻塞状态下,进程会被调度到阻塞队列,不会占用CPU资源。
挂起状态:当内存不足时,如果一个进程长时间不执行或者处于低优先级状态,操作系统可能会将其代码和数据置换出内存并存储到磁盘上的swap分区中。其PCB(进程控制块)仍然存在于进程表中。
终止状态:当进程完成其任务或被操作系统终止时,它进入终止状态。在这个阶段,进程可以释放所有已分配资源,并从系统中移除。
进程转换流程:

3.3 Linux进程状态
R状态:进程被调度到CPU运行队列中,分配到CPU资源的进程是运行态,没有分配到的是就绪态。
S状态:可中断睡眠状态(阻塞、挂起),即睡眠状态可以通过发送信号等方式被动唤醒,或由操作系统直接中断。
D状态:磁盘睡眠状态(IO阻塞、IO挂起),不可被动唤醒,不可被中断
T状态:信号暂停状态,表示进程被暂停,并且可以通过信号来暂停或恢复进程的执行:-19暂停,-18继续。
t状态:调试暂停状态,表示进程被调试器(如gdb)跟踪调试,并且暂停了进程的执行。通常是由于调试器设置了断点或执行了单步调试操作而进入的状态。
Z状态:僵尸状态(终止),是指一个已经终止的子进程,但其父进程尚未获取子进程的退出状态。僵尸进程不会占用系统资源,因为它们已经终止并释放了大部分资源。僵尸进程只在进程表中保留一条记录,以便父进程在需要时获取子进程的退出状态。
X状态:终止状态,瞬时性非常强。

深度睡眠和浅度睡眠
S状态标识可中断睡眠状态,它表示进程正在等待某个事件的发生,例如等待I/O操作完成、等待信号量等,在这种状态下,进程是可以被调度的。
D状态标识不可中断睡眠状态,标识通常情况下D状态是由于进程等待磁盘I/O操作完成而引起的,在这种状态下,进程是不可被调度的,即操作系统无法将其切换到其他任务上执行。
example: 当服务器压力过大时,OS会通过一定的手段终止一些进程,起到节省资源的作用,此时如果为S状态会被OS杀掉从而导致数据丢失,所以,为了防止进程异常终止而造成的数据丢失等问题的出现,该进程会被设置D状态。D状态下的进程不能被OS终止,只能等该进程得到磁盘读写结果后自动唤醒。
僵尸进程(Z)和孤儿进程
僵尸进程是子进程退出父进程还在运行,但是父进程没有读取到子进程的退出状态,子进程就会进入Z状态。
孤儿进程是父进程提前退出,但是此时未退出的子进程就会被称为孤儿进程,孤儿进程会被1号init进程领养,需要init进程回收。
僵尸进程的危害:
1. 僵尸进程的PCB不能回收:因为僵尸进程的退出状态需要被维护下去,维护退出状态需要数据维护。
2. 内存泄露:由于PCB不能及时回收会造成内存泄漏。
3. 创建进程有限:用户创建的进程是有限的,僵尸进程过多会导致创建新的子进程失败等诸多问题。
4. 需要及时回收:僵尸进程本身不会占用系统资源,但是会占用一定的进程表项和内核资源。
孤儿进程需要注意的地方: 子进程变为孤儿进程后,会从前台进程转为后台,所以此时的
Ctrl c无法终止子进程。
3.4 进程地址空间

进程地址空间: 进程地址空间本质是内存中的一种内核数据结构,在Linux中式由mm_struct实现的。在32位系统中,一个进程通常会被分配4GB的虚拟内存空间,地址范围为0x00000000~0xFFFFFFFF。这4GB中大约有1GB的内核空间会被操作系统所保留,用于存储操作系统本身的代码和数据,剩下的3GB空间才是该进程的用户空间。

特点:
1. 操作系统为每个进程都分配一个地址空间和对应的映射页表
2. Linux内核中的地址空间本质上是一个mm_struct的结构,其中就包括了地址空间的区域划分及其他属性。
3. 地址空间中数据区域的变化,实际上是对区域的边界start或end值进行调整。
4. task_struct中记录了指向mm_struct结构体指针struct mm_struct *mm, *active_mm, 可以通过PCB找到进程对应的地址空间。
为什么要有进程地址空间?
1. 防止地址随意被访问,保护物理内存及其他进程
2. 将进程管理和内存管理进行解耦合,保证了进程独立性的特点,每个进程都需要有独立的进程地址空间及页表,一个进程数据的改变并不回影响另一个进程。
3. 使得进程的内存管理分布有序化。
4 多线程编程
4.1 线程简介
线程概念
所谓线程就是操作系统所能调度的最小单位。普通的进程,只有一个线程在执行对应的逻辑。相比多进程编程而言,线程享有共享资源,即在进程中出现的全局变量, 每个线程都可以去访问它,与进程共享“4G”内存空间,使得系统资源消耗减少。

Linux中并没有单独地为线程创建相应地结构去管理,而是复用了进程的结构, 每一个线程都有自己的task_struct结构体,同时他们指向相同的虚拟空间mm_struct.
Linux下并不存在真正的多线程而是用进程模拟的!
1.严格上来说是没有的,Linux是用进程PCB来模拟线程的,是一种完全属于自己的一套线程方案。
2.站在CPU的视角,每一个PCB,都可以称为轻量级进程。
3.Linux线程是CPU调度的基本单位,而进程是承担分配系统资源的基本单位
4.进程用来整体申请资源,线程用来伸手向进程要资源
5.Linux中没有真正意义的线程。通过进程模拟。
6.进程模拟线程的好处:PCB模拟线程,为PCB编写的结构与算法都能进行复用,不用单独为线程创建调度算法,降低维护成本,复用进程的那一套.可靠高效
线程的优点
创建一个新线程的代价要比创建一个新进程小得多
与进程之间的切换相比,线程之间的切换需要操作系统做的工作要少很多
进程间切换,需要切换页表、虚拟空间、切换PCB、切换上下文
线程间切换,线程都指向同一个地址空间,页表和虚拟地址空间就不需要切换了,只需要切换PCB和上下文,成本较低
少的多体现在,线程切换不需要更新太多cache(存储大量经常使用的数据),进程切换要全部更新
线程的缺点
1. 性能损失:一个很少被外部事件阻塞的计算密集型线程往往无法与共它线程共享同一个处理器。如果计算密集型线程的数量比可用的处理器多,那么可能会有较大的性能损失,这里的性能损失指的是增加了额外的同步和调度开销,而可用的资源不变。
2. 健壮性降低:编写多线程需要更全面更深入的考虑,在一个多线程程序里,因时间分配上的细微偏差或者因共享了不该共享的变量而造成不良影响的可能性是很大的,换句话说线程之间是缺乏保护的,一个线程崩可能影响另一个线程。
3. 缺乏访问控制:进程是访问控制的基本粒度,在一个线程中调用某些OS函数会对整个进程造成影响。
4. 编程难度提高:编写与调试一个多线程程序比单线程程序困难。
线程的异常
单个线程如果出现除零,野指针问题导致线程崩溃,
进程也会随着崩溃
线程是进程的执行分支,线程出异常,就类似进程出异常,进而触发信号机制,终止进程,进程终止,该进程内的所有线程也就随即退出
4.2 Linux线程和进程
进程是承担分配系统资源的基本实体,线程是调度的基本单位
线程共享进程数据,但也拥有自己的一部分数据:
线程ID、一组寄存器(存储每个线程的上下文信息)、栈(线程的临时数据)、errno、信号屏蔽字、调度优先级
Linux进程线程的父子控制的关系
进程不对任何子进程进行控制,进程的线程可以对同一进程的其他子进程加以控制。子进程不能对父进程施加控制,进程中所有线程都可以对主线程施加控制。
Linux 进程和线程的通信
父进程和子进程之间使用进程间通信机制,同一进程的线程通过读取和写入数据到进程变量来进行通信。
4.3 Linux线程控制
1. 线程的标识pthread_t
每一个进程都有一个唯一对应的PID号表示该进程,而线程的标识为tid号,本质是一个pthread_t类型的变量。线程号与进程号是表示线程和进程的唯一标识,但是对于线程号而言,其仅仅在其所属的进程上下文中才有意义。
2. 获取线程号
#include <pthread.h>
pthread_t pthread_self(void);
成功:返回线程号3. 线程的创建
#include <pthread.h>
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,void *(*start_routi
ne) (void *), void *arg);功能:创建一个新的线程
thread:线程ID
attr:设置线程的属性,attr为NULL表示使用默认属性start_routine:是个函数地址,线程启动后要执行的函数
arg:传给线程启动函数的参数
返回值:成功返回0;失败返回错误码

1.线程函数处进行return。
2.线程可以自己调用pthread_exit函数终止自己。
3.一个线程可以调用pthread_cancel函数终止同一进程中的另一个线程。
void* thread_run(void* args)
{
while(true)
{
cout << "new thread running,thread id: " << pthread_self() << endl;
sleep(1);
}
return nullptr;
}
int main()
{
pthread_t t;
pthread_create(&t,nullptr,thread_run,nullptr);
return 0;
}
使用pthread_exit函数:
using namespace std;
void* thread_run(void* args)
{
int cnt = 5;
while(cnt--)
{
cout << "new thread running,thread id: " << pthread_self() << endl;
sleep(1);
}
pthread_exit((void*)2023);//将线程退出码设为2023
}
int main()
{
pthread_t t;
pthread_create(&t,nullptr,thread_run,nullptr);
void* ret = nullptr;
pthread_join(t,&ret);//pthread_join表示线程等待,主线程执行完后还需等待其他线程
//这里会把线程退出码信息通过该函数给ret
cout << "new thread exit code is : " << (int64_t)ret << endl;
//这里使用int64_t强制转换是因为平台下Linux的指针是8字节的。
return 0;
}
pthread_cancel函数:线程是可以取消自己的,甚至新线程也可以取消主线程,取消成功的线程的退出码一般是 -1
void* thread_run(void* args)
{
int cnt = 5;
while(cnt--)
{
cout << "new thread running,thread id: " << pthread_self() << endl;
sleep(1);
}
pthread_exit((void*)2023);
}
int main()
{
pthread_t t;
pthread_create(&t,nullptr,thread_run,nullptr);
sleep(3);
pthread_cancel(t);//取消新线程
void* ret = nullptr;
pthread_join(t,&ret);//pthread_join表示线程等待,主线程执行完后还需等待其他线程
cout << "new thread exit code is : " << (int64_t)ret << endl;
return 0;
}
4. 线程资源回收
阻塞方式
#include <pthread.h>
int pthread_join(pthread_t thread, void **retval);该函数为线程回收函数,默认状态为阻塞状态,直到成功回收线程后才返回。第一个参数为要回收线程的tid号,第二个参数为线程回收后接受线程传出的数据。
非阻塞方式
#define _GNU_SOURCE
#include <pthread.h>
int pthread_tryjoin_np(pthread_t thread, void **retval);该函数为非阻塞模式回收函数,通过返回值判断是否回收掉线程,成功回收则返回 0 ,其余参数与 pthread_join 一致。
互斥锁

信号量
















 26万+
26万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









