







cellranger-atac -id=samplename 参数会指定输出目录samplename,samplename/out 下存储主要的分析结果
1. summary.csv 和 web summary
两个文件基本包含一样的内容,主要介绍web summary
1.1 sample 描述
1.2 测序数据质量。sequenced read pairs:样本测得读段数量;valid barcode:能够比对到barcode白名单比例(包含校正后的barcode 序列)。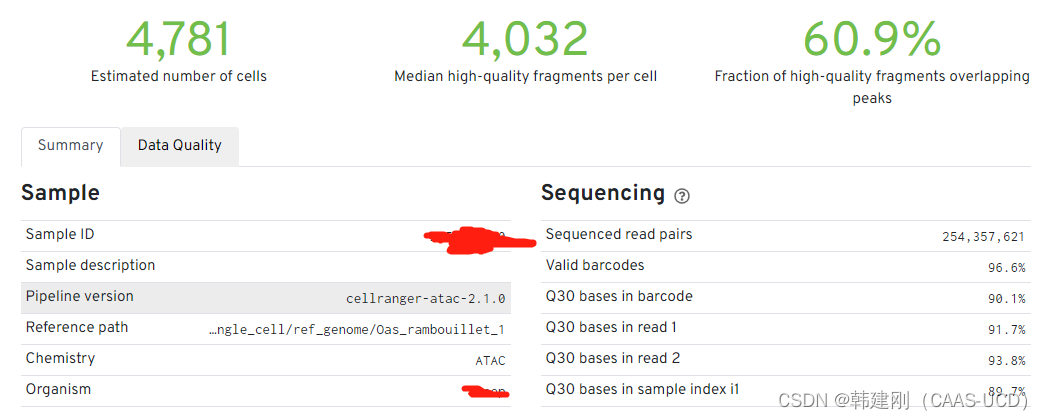
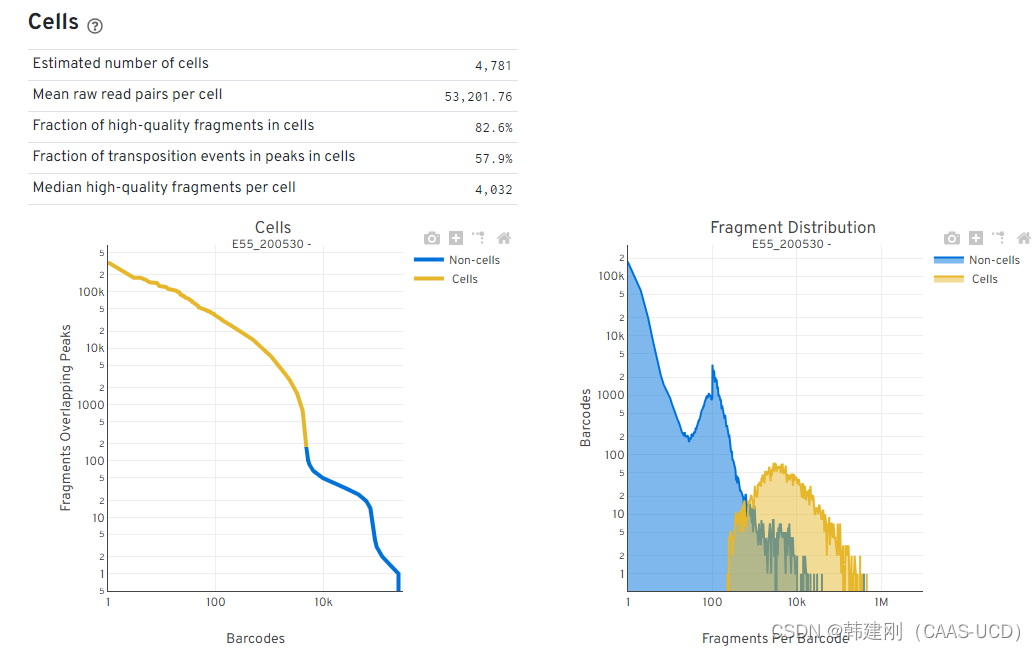
1.3 细胞计数/统计。
Estimated number of cell 和 mean raw read pairs per cell就是明面意思;
fraction of high-quality fragments in cells:首先 high-quality fragments 的定义是“有效的barcode,比对到细胞核基因组区域,比对质量大于30的片段”;
fraction of transposition events in peaks in cells:首先需要明白并不是所有的(转座酶)酶切事件都发生在peak中,会有一些随机酶切现象,这些酶切片段也就是背景噪音,但每一个peak绝对代表一个或多个酶切事件,这里统计的是酶切事件位于peak中的比例,个人理解为有生物学意义的酶切事件的比例;
median high-quality fragments per cell:高质量片段在细胞中的平均数量
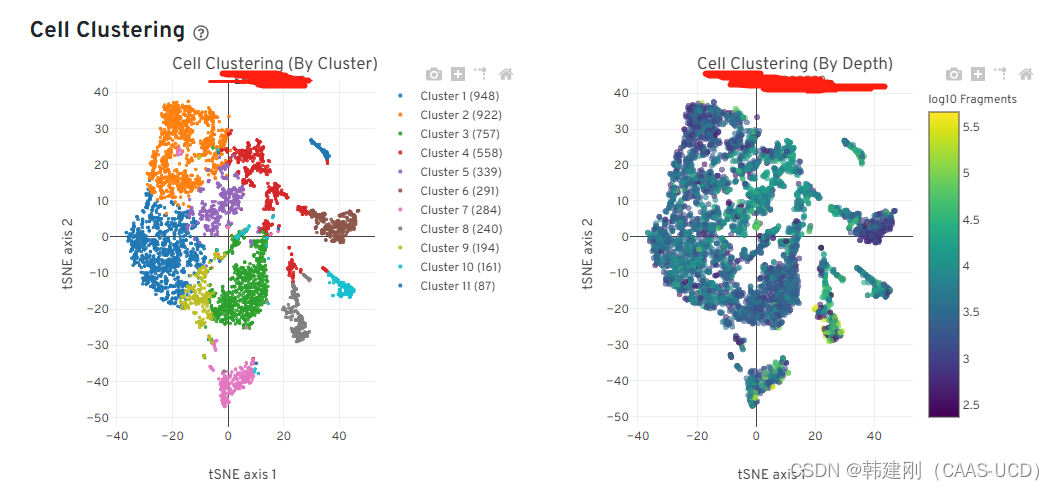
1.4 细胞聚类,基于各细胞peak中fragment数量进行聚类
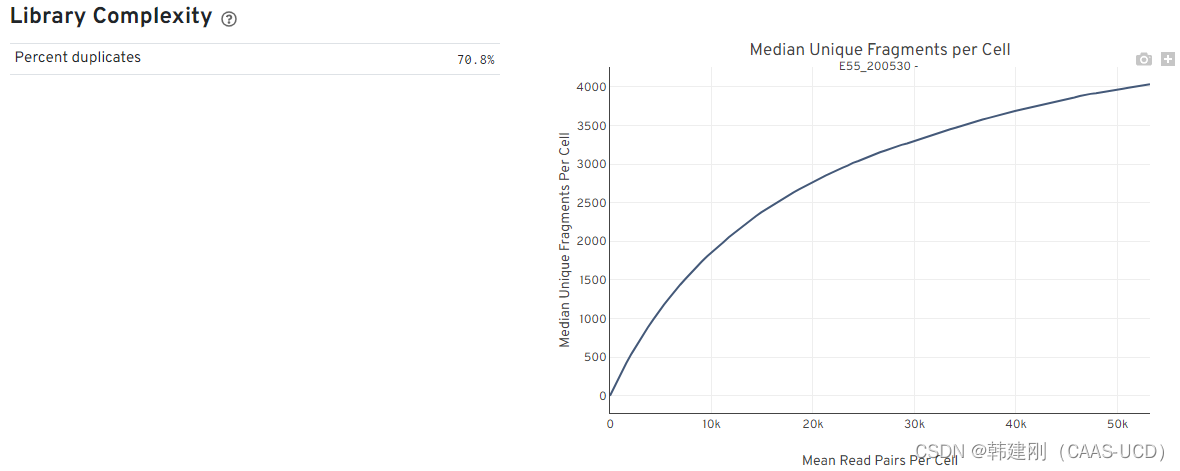
1.5 片段重复率:因为文库构建过程会进行PCR扩增,大部分片段无法避免的存在多个重复,在这些重复中只有一个是具有生物学意义的,剩下的重复都需要在分析中剔除掉
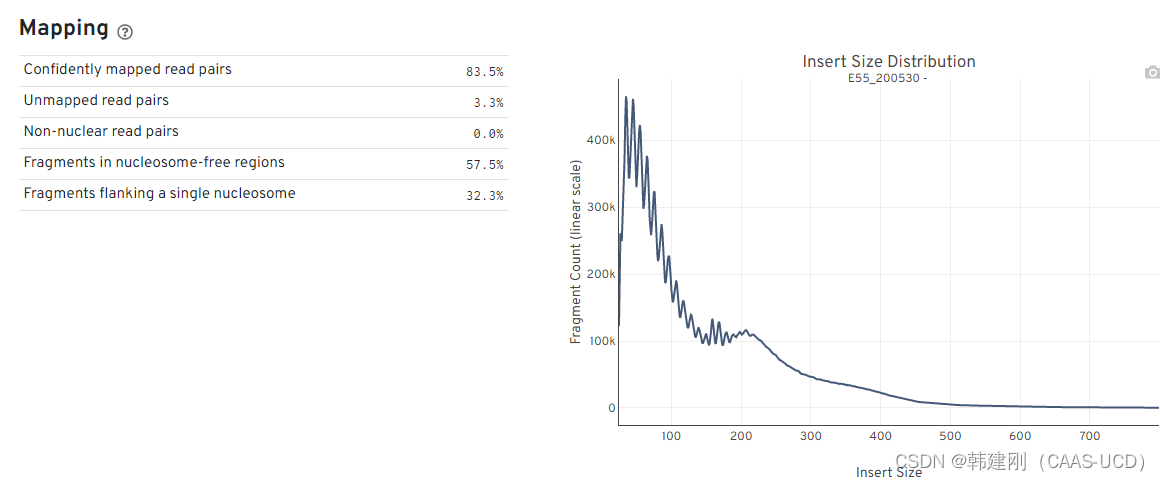
1.6 参考基因组比对质量
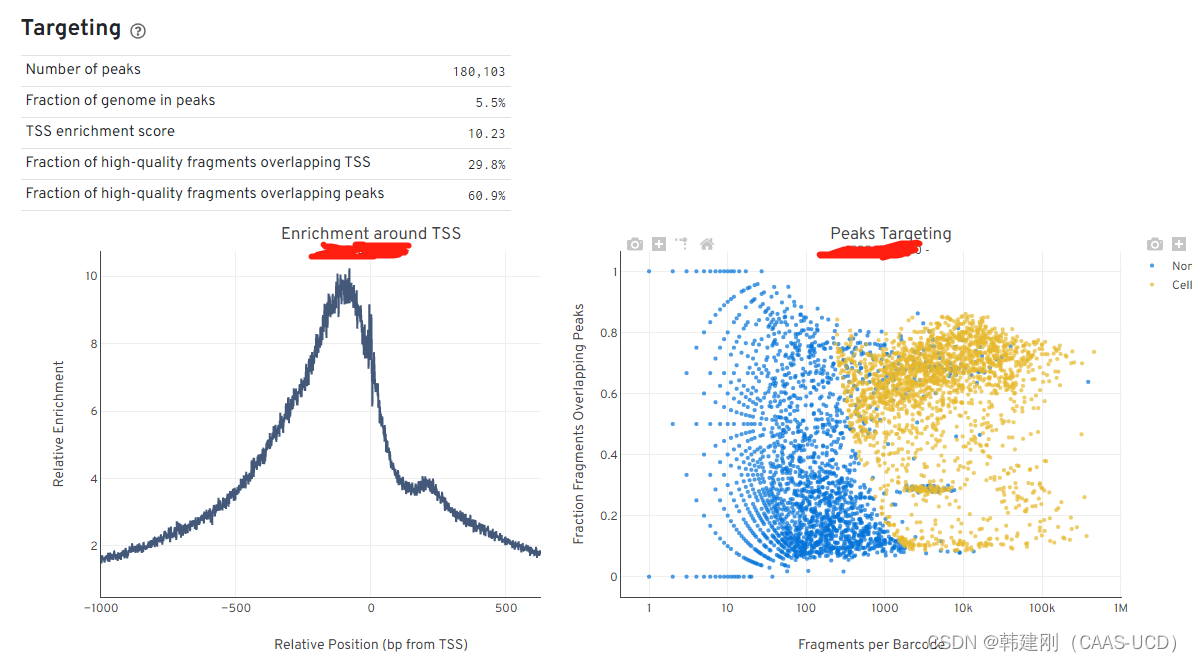
1.7 peak统计
Fraction of genome in peaks:被定义为peaks的原始contigs 比例
TSS enrichment score:TSS富集分数。首先需要理解什么是TSS profile,TSS profile 指的是在一个2000碱基的窗口中所有的TSS的可及性信号的总和,并用最小的信号对总和进行校正。TSS富集分数就是最大的TSS profile。
Fraction of high-quality fragments overlapping TSS or peaks:位于peaks或TSS的高质量fragments的比例。
2. Feature-Barcode 矩阵
feature 代表的peak及其对应位置,barcode表示细胞,在outs/ 文件夹中有三种类型 Feature-Barcode 矩阵,保存成两种格式,一种是 Market Exchange Format (MEX)格式,另一种是h5ad格式。

2.1 MEX格式的三种Feature-Barcode 矩阵包含的文件内容:
tree raw_peak_bc_matrix
raw_peak_bc_matrix
├── barcodes.tsv
├── matrix.mtx
└── peaks.bed
tree filtered_peak_bc_matrix
filtered_peak_bc_matrix
├── barcodes.tsv
├── matrix.mtx
└── peaks.bed
tree filtered_tf_bc_matrix
filtered_tf_bc_matrix
├── barcodes.tsv.gz
├── matrix.mtx.gz
└── motifs.tsvpeaks.pad 包含 peaks 在染色体位置
motifs.tsv 包含motifs的相关信息
barcodes.tsv 包含barcode信息
2.2 R 读取Feature-Barcode 矩阵
###Loading matrices into R
require(magrittr)
require(readr)
require(Matrix)
require(tidyr)
require(dplyr)
# peak-bc matrix
mex_dir_path <- "/opt/sample345/outs/filtered_peak_bc_matrix"
mtx_path <- paste(mex_dir_path, "matrix.mtx", sep = '/')
feature_path <- paste(mex_dir_path, "peaks.bed", sep = '/')
barcode_path <- paste(mex_dir_path, "barcodes.tsv", sep = '/')
features <- readr::read_tsv(feature_path, col_names = F) %>% tidyr::unite(feature)
barcodes <- readr::read_tsv(barcode_path, col_names = F) %>% tidyr::unite(barcode)
mtx <- Matrix::readMM(mtx_path) %>%
magrittr::set_rownames(features$feature) %>%
magrittr::set_colnames(barcodes$barcode)
# tf-bc matrix
mex_dir_path <- "/opt/sample345/outs/filtered_tf_bc_matrix"
mtx_path <- paste(mex_dir_path, "matrix.mtx", sep = '/')
feature_path <- paste(mex_dir_path, "motifs.tsv", sep = '/')
barcode_path <- paste(mex_dir_path, "barcodes.tsv", sep = '/')
features <- readr::read_tsv(feature_path, col_names = c('feature', 'common_name'))
barcodes <- readr::read_tsv(barcode_path, col_names = F) %>% tidyr::unite(barcode)
mtx <- Matrix::readMM(mtx_path) %>%
magrittr::set_rownames(features$feature) %>%
magrittr::set_colnames(barcodes$barcode)2.3 Python 读取Feature-Barcode 矩阵
### Loading matrices into Python
import csv
import os
import scipy.io
# peak-bc matrix
matrix_dir = "/opt/sample345/outs/filtered_peak_bc_matrix"
mat = scipy.io.mmread(os.path.join(matrix_dir, "matrix.mtx"))
peaks_path = os.path.join(human_matrix_dir, "peaks.bed")
peaks = [(row[0], int(row[1]), int(row[2])) for row in csv.reader(open(peaks_path), delimiter="\t")]
barcodes_path = os.path.join(human_matrix_dir, "barcodes.tsv")
barcodes = [row[0] for row in csv.reader(open(barcodes_path), delimiter="\t")]
# tf-bc matrix
matrix_dir = "/opt/sample345/outs/filtered_tf_bc_matrix"
mat = scipy.io.mmread(os.path.join(matrix_dir, "matrix.mtx"))
motifs_path = os.path.join(human_matrix_dir, "motifs.tsv")
motif_ids = [row[0] for row in csv.reader(open(motifs_path), delimiter="\t")]
motif_names = [row[1] for row in csv.reader(open(motifs_path), delimiter="\t")]2.4 Feature-Barcode 矩阵转换为CSV格式
# convert from MEX,这种转换方法报错,不知道为什么
cellranger mat2csv sample123/outs/filtered_peak_bc_matrix sample123.csv
# or, convert from H5
$ cellranger mat2csv sample123/outs/filtered_peak_bc_matrix_h5.h5 sample123.csv
# 转换后的格式:行-peaks位置,列:barcode序列

















 519
519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









