







概述
关于ToF传感器的真实数据的深度估计,在传统方法中使用成体系的pipeline对数据进行处理,整个过程中需要考虑到的因素很多,是一套精细又有些繁冗的过程。而《Joint Depth and Normal Estimation from Real-world Time-of-flight Raw Data》这篇文章则采用了深度学习端到端的方式,以ToF相机的Raw数据作为输入,深度和法向图作为输出,试图构建一个优雅的流程。
我们知道,ToF相机的真实数据GT并不好获取,在许多相关工作中,都采用了合成数据的方式,然而,采用合成数据,便难以避免与真实数据之间存在鸿沟的问题。针对该问题,该文章通过在机械臂上绑ToF相机和工业立体相机的方式,以工业立体相机数据所得到的三维点云作为GT,采集了超过2500张真实数据,构建了一个命名为ToF-100的数据集。至于网络中比较有意思的创新点,则正如文章名字所体现的“joint Depth and Normal…”,即深度与法向图的联合优化。引入法向图的原因是,文章认为法向图某种程度上是高频信息的一种体现,可以更好的帮助网络学习到漂亮的深度图。
论文链接:https://arxiv.org/pdf/2108.03649.pdf
代码链接: https://github.com/hkustVisionRr/JointlyDepthNormalEstimation
(实际上代码并不存在)
0. 数据
采集了超过2500张真实数据,采集方式见下图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-19w2dXfX-1645091259647)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/e7a9517c-c777-45d6-9f74-3c400270f848/Untitled.png)]](https://i-blog.csdnimg.cn/blog_migrate/78b24c4e98971e599c63c1bb6781a61b.png)
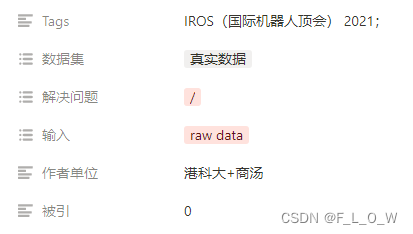
采集的真实数据与其他已有的ToF数据的对比如下表所示:
下图则为ToF-100数据集中采集内容的示意图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OqCq1HcT-1645091259650)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/97742b42-26b0-42e5-aaf4-276f93958655/Untitled.png)]](https://i-blog.csdnimg.cn/blog_migrate/eedaba85e2d363023f36a4f780903537.png)
预处理
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gCwEP61h-1645091259652)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/062d5c86-e51e-423a-8339-18fdb5274c69/Untitled.png)]](https://i-blog.csdnimg.cn/blog_migrate/67a33c09fadde0f1f662dba0920bb3c8.png)
1. 方法
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iEzb8h55-1645091259652)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/16d1ba22-4569-46ab-bd72-f36c164c8721/Untitled.png)]](https://i-blog.csdnimg.cn/blog_migrate/1d8e0d31ce0e71d3b757cbbaa11f752b.png)
输入是多通道的影像,其来源为ToF raw data解码的不同相位的偏移量,设为 I 1 − 8 {I_{1-8}} I1−8。以及ToF传感器提供的置信度和粗深度图。
过程中有三个网络,先分别走raw2depth和raw2normal,然后再联合过refinement网络。
1.1 raw2depth
使用U-Net作为骨干网络。由于不对齐以及输出的raw data和GT深度图之间的不匹配,简单的L1或L2损失会导致深度图的模糊。因此设计了一个分别在2D和3D空间都作用的损失函数,在2D空间使用smoothL1空间,在3D空间使用了鲁棒Chamfer损失。
-
reweighted smoothed L1:
期望通过error map来重新估计深度图,或者说通过置信度重新估计深度图。假设 e p , d p , d p ~ e_p,d_p,\tilde{d_p} ep,dp,dp~分别为对应的误差,预测的深度以及真实的深度,那么reweighted smoothed loss 可以表示为:
ℓ r s = { ∑ p λ 2 ∣ d p − d ~ p δ ∣ 2 if ∣ d p − d ~ p ∣ < δ ∑ p λ ( ∣ d p − d ~ p δ ∣ − 1 2 ) otherwise \ell_{r s}=\left\{\begin{array}{cc}\sum_{p} \frac{\lambda}{2}\left|\frac{d_{p}-\tilde{d}_{p}}{\delta}\right|^{2} & \text { if }\left|d_{p}-\tilde{d}_{p}\right|<\delta \\\sum_{p} \lambda\left(\left|\frac{d_{p}-\tilde{d}_{p}}{\delta}\right|-\frac{1}{2}\right) & \text { otherwise }\end{array}\right. ℓrs=⎩⎨⎧∑p2λ∣∣∣δdp−d~p∣∣∣2∑pλ(∣∣∣δdp−d~p∣∣∣−21) if ∣∣∣dp−d~p∣∣∣<δ otherwise
其中 λ = d ~ p e p + ϵ , ϵ = 0.001 \lambda=\frac{\tilde{d}_{p}}{e_{p}+\epsilon}, \epsilon=0.001 λ=ep+ϵd~p,ϵ=0.001, δ \delta δ是阈值,在此设置为20。
-
Robust Chamfer loss:
设x和y是对应的在ICP匹配过程后的对应点,则Robust Chamfer loss为:
ℓ c h = ∑ x ∈ P min y ∈ Q ∥ x − y ∥ 2 2 + ∑ y ∈ Q min x ∈ P ∥ x − y ∥ 2 2 \ell_{c h}=\sum_{x \in P} \min _{y \in Q}\|x-y\|_{2}^{2}+\sum_{y \in Q} \min _{x \in P}\|x-y\|_{2}^{2} ℓch=x∈P∑y∈Qmin∥x−y∥22+y∈Q∑x∈Pmin∥x−y∥22
鲁棒性通过jittering实现,具体地,对由预测深度图而恢复的点云沿着xyz轴,以及前后共5个方向移动一厘米,加上本身恢复的点云,共有6个点云。对这六个点云都求取Chamfer损失,并取最小的损失值作为鲁棒的Chamfer损失。
1.2 Raw2normal
以ToF raw data、置信度、ToF 传感器的深度作为输入,通过U-Net生成法向图。
- Cosine embedded loss: ℓ cos = 1 − n 1 ⋅ n 2 ∥ n 1 ∥ ∥ n 2 ∥ \ell_{\cos }=1-\frac{\mathbf{n}_{1} \cdot \mathbf{n}_{2}}{\left\|\mathbf{n}_{1}\right\|\left\|\mathbf{n}_{2}\right\|} ℓcos=1−∥n1∥∥n2∥n1⋅n2x
学习两个向量之间的角度相似性。
得益于ToF-100的高分辨率,可以直接通过网络得到高分辨率的法向图。
1.3 joint refinement
深度图和表面法向有着紧密的几何关系,表面法向可以由深度计算得到,也可以反过来用于帮助优化深度图(因为表面法向揭示了高频信息)。
类似于GeoNet,使用了一个交互(深度到法向、法向到深度)的refinement过程。
2 实验
- 深度图效果:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VhpbgUcE-1645091259653)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/2d642470-9c96-4160-b0aa-62f4e6d41264/Untitled.png)]](https://i-blog.csdnimg.cn/blog_migrate/d055cba637203d39cc2170ba9d207569.png)
- 法向图效果:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-397a8J24-1645091259654)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/05b29c22-5539-4993-9f2b-f7b7e706a575/Untitled.png)]](https://i-blog.csdnimg.cn/blog_migrate/711b3a46ffaa67cad548a169342a6755.png)
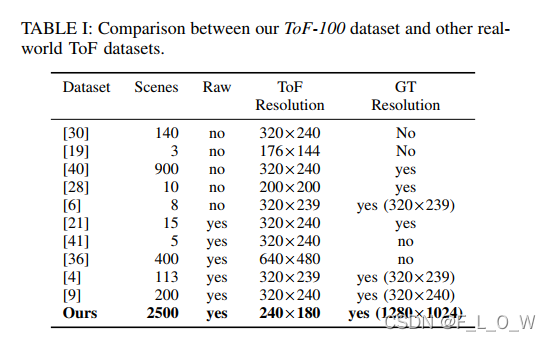
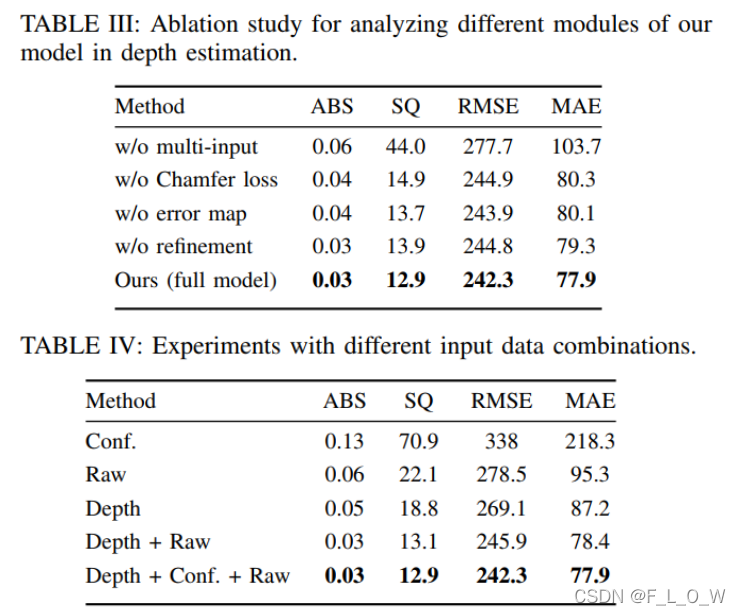
- 消融实验:
- MPI效应消除分析:
使用双频ToF作为输入,且GT深度是由立体相机得到的,在此几乎不存在MPI的问题,网络恢复效果看起来也是可以恢复细节的。
- 噪声消除分析:
在传统流水线中,噪声的消除基于随机的规则与假设,这在接收信号遭遇强度和场景变化时假设并不成立,这也是导致在低反射率区域噪声大量存在的原因。
不同于传统流水线,该方法直接通过网络来从raw data到高分的深度图,并不存在假设失效的问题。
相对于ToF的深度图来说,网络得到的深度图在平面物体上的表现更为光滑:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6BIgvFmC-1645091259658)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/cf5fd382-168d-42ac-bbfe-6a46f0439680/Untitled.png)]](https://i-blog.csdnimg.cn/blog_migrate/cd058e4acc27a4af8d70138c38db0926.png)
采取了两个方式来减少噪声的影响:
- 对于shot噪声,取了raw 测量的10个shot;
- 对于随机噪声,去了10次shot的平均深度作为GT深度。
参考文献
- GeoNet:
Xiaojuan Qi, Renjie Liao, Zhengzhe Liu, Raquel Urtasun, and Jiaya Jia. GeoNet: Geometric neural network for joint depth and surface normal estimation. In CVPR, 2018. 2, 5



















 9223
9223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











