







概述
论文名称: Deep Learning for Multi-Path Error Removal in ToF Sensors
论文链接: https://openaccess.thecvf.com/content_ECCVW_2018/papers/11131/Agresti_Deep_Learning_for_Multi-Path_Error_Removal_in_ToF_Sensors_ECCVW_2018_paper.pdf
作者单位: 意大利帕多瓦大学
期刊或会议: ECCV 2018
数据集链接: http://lttm.dei.unipd.it/paper_data/MPI_CNN.
无开源代码
被引: 18
这篇文章是ECCV 2018的文章,来自意大利帕多瓦大学的团队,他们提出了一个用于去除MPI和深度细化的ad-hoc网络。所需要的数据来自于多频ToF相机。
用于估计MPI的CNN主要由两个子网络构成,最后,在摄像机噪声模型的引导下,采用自适应双边滤波器消除零值误差。实验结果证明了该方法在合成数据和实际数据上的有效性。
这篇文章的任务目标是获得精确的深度数据,在这个过程中需要解决的最大挑战是去除MPI干扰以及由shot noise所带来的误差。
MPI的估计通过使用CNN的方式来去除,CNN的输入是多频ToF相机所捕捉得到的数据,而shot noise的方式则通过自适应双边滤波进行去除。
对于正弦波的调制来说,正弦波与调制信号相关的数学表达为:
c
(
θ
i
)
=
B
+
A
cos
(
θ
i
−
4
π
f
m
⋅
d
c
l
)
=
B
+
A
cos
(
θ
i
−
K
d
)
c\left(\theta_{i}\right)=B+A \cos \left(\theta_{i}-\frac{4 \pi f_{m} \cdot d}{c_{l}}\right)=B+A \cos \left(\theta_{i}-K d\right)
c(θi)=B+Acos(θi−cl4πfm⋅d)=B+Acos(θi−Kd)
然而,这种情况是比较理想的,只接收到一个返回信号的情况,显然,在MPI的左右下,上述的数学表达并不成立,而是会被改写为:
c
(
θ
i
)
=
B
+
A
d
cos
(
θ
i
−
K
d
d
)
+
∫
d
d
+
ϵ
∞
A
x
′
cos
(
θ
i
−
K
x
)
d
x
=
B
+
A
F
F
cos
(
θ
i
−
K
d
F
F
)
c\left(\theta_{i}\right)=B+A_{d} \cos \left(\theta_{i}-K d_{d}\right)+\int_{d_{d}+\epsilon}^{\infty} A_{x}^{\prime} \cos \left(\theta_{i}-K x\right) d x=B+A_{F F} \cos \left(\theta_{i}-K d_{F F}\right)
c(θi)=B+Adcos(θi−Kdd)+∫dd+ϵ∞Ax′cos(θi−Kx)dx=B+AFFcos(θi−KdFF)
方法
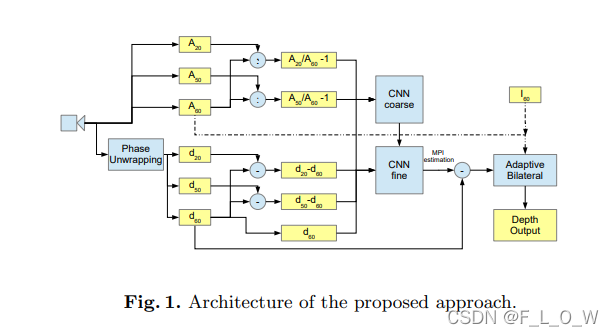
可以看到,整体的CNN架构可以分为两个部分,一个是粗网络,再一个是精网络。粗网络的输入是5个表达,输出是低分辨率的MPI数值,而精网络一样输入5个表达,但是额外会再输入粗网络的低分辨率MPI输出,最后估计得到一个全分辨率上的MPI值。CNN所估计得到的全分辨率上的MPI值将从ToF深度图上减掉,进而得到一个MPI纠正过的深度。
具体地,5个不同的表达包括:
5 different input channels containing the ToF depth extracted from the phase at 60 MHz, the difference between the depth maps at different frequencies and the ratio of the amplitudes also at different frequencies.
用于网络输入的ToF数据表达
调制频率分别为20、50、60MHz。
输入数据如何去选择?一个重要的考虑就是:输入数据的信息应当是对MPI问题的解决有益。
因此,设计了以下的输入:
- 第一个输入 C 1 = d 60 C_1=d_{60} C1=d60是ToF在60MHz频率下获得的深度图。其作用不仅仅是因为该深度图受了MPI的影响,还有其对于场景几何的失真影响几乎是最小的,换言之,这个频率得到的深度图相比起其他频率来说,对场景几何有着最好的刻画。
- 不同调制频率所得到的深度图之间的差值图。我们知道,通常来说,频率越高,MPI的影响越小,也就是说不同频率会对MPI造成影响。所以选择了第二个输入和第三个输入分别为: C 2 = d 20 − d 60 C_2 = d_{20}-d_{60} C2=d20−d60, C 3 = d 50 − d 60 C_3 = d_{50}-d_{60} C3=d50−d60。
- 不同调制频率接受的光的信号的幅度的比值。当MPI情况存在的时候,往往频率越高,接收到的信号幅度就会越低。由于这个原因,文章认为输入不同频率之间的幅度比值会有助于网络识得MPI是否存在以及其强度如何。具体地, C 4 = ( A 20 A 60 ) − 1 C_4 = (\frac{A_{20}}{A_{60}})-1 C4=(A60A20)−1以及 C 5 = ( A 50 A 60 ) − 1 C_5 = (\frac{A_{50}}{A_{60}})-1 C5=(A60A50)−1。
提出的CNN结构旨在估计在60MHz频率下的MPI影响值,具体地,参考真值为
d
60
d_{60}
d60与
d
G
T
d_{GT}
dGT之间的滤波版差值。
这些输入都可以由ToF相机内部的算法提供。
此外,实验表明,使用输入数据的subset会让实验结果变得更差。
数据集的深度仿真是通过Blender的渲染引擎实现的,数据已经开源。不同的场景包含了不同形状和纹理的物体,包括了一些墙角场景,探测范围从 50 c m 50cm 50cm到 10 m 10m 10m。
此外,还获取了一些真实场景的数据,目的是为了验证该文方法的有效性。
采集的系统为:SoftKinetic ToF相机以及一个主动双目系统。采集的数据非常非常少,只用于测试的目的,采集的对象为一个木盒子,见下图:

粗网络与细网络
基于上述原则,粗网络对输入的数据进行分析,网络结构包括5个卷积层的堆叠,所有的卷积层都是
3
∗
3
3 * 3
3∗3大小,且有32个核,接ReLU,除了最后一个卷积层直接出一个1/4分辨率的MPI误差,且不带ReLU。
估计的MPI值最后被双线性上采样至原本的分辨率,并加回至原本分辨率的深度图。然而,直接这样的操作,还是过于粗暴。因此,文章又引入了另一个所谓的细网络,该网络直接在全分辨率上进行处理,进而将MPI误差分配的更加细化。细网络同样包括5层
3
∗
3
3 * 3
3∗3的卷积,核数变为64,且没有池化的操作。细网络第一层的输入与粗网络一样,但第四层的输入,则不仅仅是第三层的输出,还加入了粗网络的上采样结果。粗网络和细网络的结合,则可以同时抓得全局结构和精细的细节。
下图为网络结构的具体示意图:
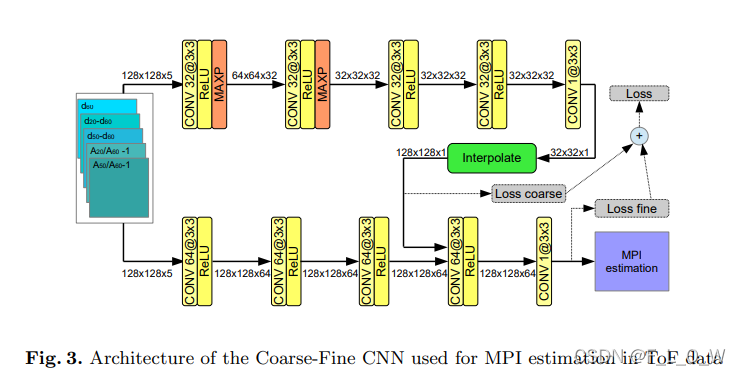
粗网络和细网络一起训练要比分开训练更好。
损失函数
结合粗网络和细网络的损失,对于粗网络而言,计算其插值后的结果与真值的差距,对于细网络,则直接计算其输出与真值的差距。
两个损失都是用L1 norm损失,在其实验中,结果证明该损失函数对于去噪来说效果很好。
网络训练
训练数据的数据增强
训练数据是合成数据,但是相比起其他的CNN任务来说,体量还是过少。文章采取了一些数据增强技巧:随机采样patches,随机旋转和翻转。
从40个场景中的每一张数据中都裁剪了
128
∗
128
128 *128
128∗128大小的10个随机patch,并进行正负5°的旋转以及垂直方向与水平方向上的旋转,最终获得大概
40
∗
10
∗
5
=
2000
40 *10 *5 = 2000
40∗10∗5=2000个patch用于训练。
训练细节
- ADAM优化器
- bs=16
- Xavier权重初始化
- 学习率初始为 1 0 − 4 10^{-4} 10−4,权重 L2正则: weighting factor = 1 0 − 4 10^{-4} 10−4
- 训练150轮,只训练了30分钟,环境为Intel i7-4790 CPU、NVIDIA Titan X GPU
- tensorflow框架
- 单张图的推理只需要9.5ms
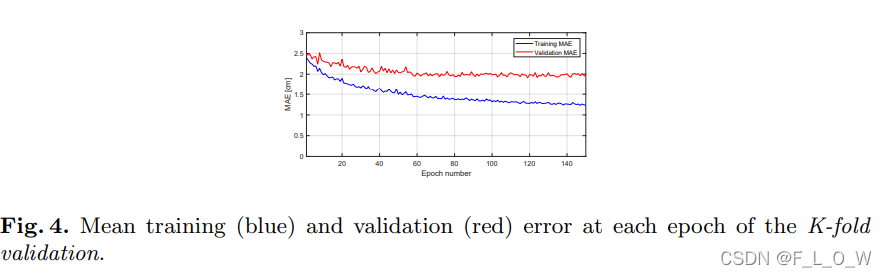
训练过程验证结果
在训练过程,使用5折交叉验证的方式的结果为:
实验验证
合成数据集结果
合成数据集测试集场景示意图:

方法效果,包括与BF后处理的结果的对比:

定量上,MAE从156mm减小到70mm。
粗网络输出与粗-细网络输出的对比:

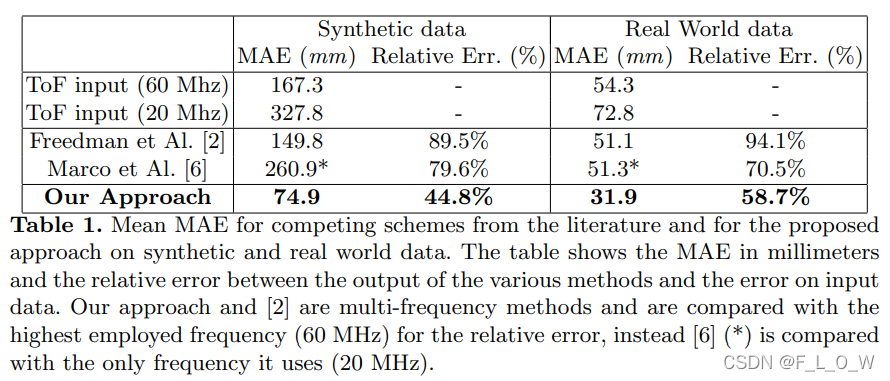
与其他方法的对比结果:
真实数据集结果
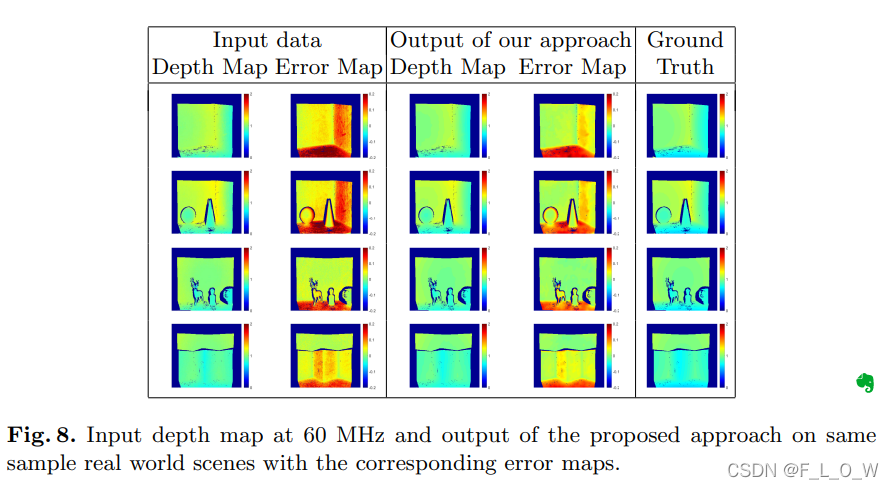
结论和下一步研究
结论: 有效地证明了影响MPI的有效信息,简单的CNN结构便可以有效地对MPI进行纠正。然而是由合成数据训练得到的模型,在真实数据上的结果有一些局限性。
下一步: 真实数据和合成数据混合训练,以期提高网络在真实场景下的适应水平;半监督的学习策略和GAN的思想或许能够被利用。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











