






十七、卷积网络可视化
至此,不管是分类任务还是检测任务还是生成任务,我们都已经学了各个任务中的经典网络。那为什么这些架构有效呢?其中可视化是最直观的解释,所以本章讲讲可视化。 可视化可以让我们人类直观的看到卷积网络中到底发生了什么:
1、神经网络第一层卷积层的卷积核组的可视化: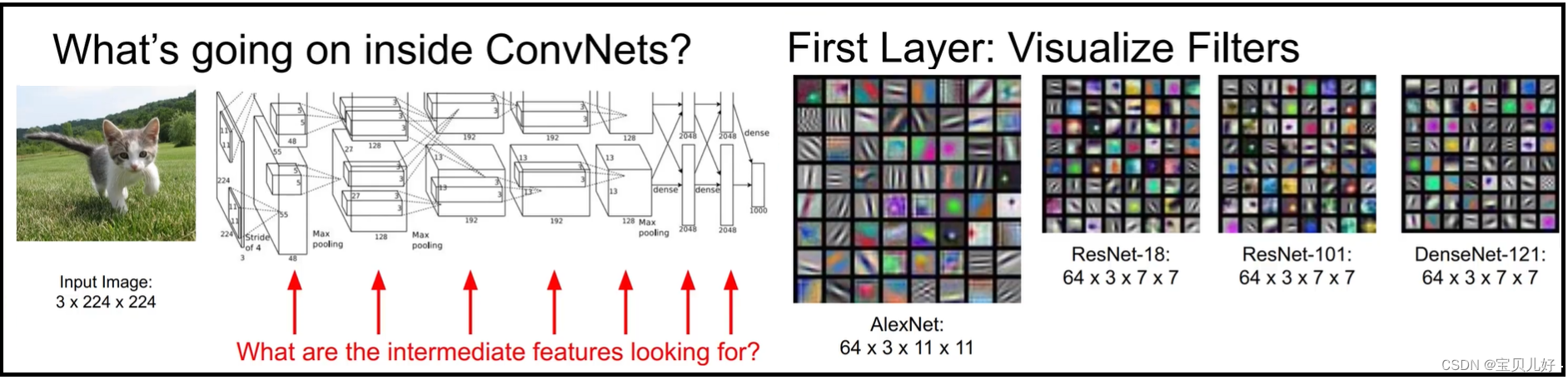
从上图可以看出,不管是简单的alexnet还是复杂的densenet,它的第一层学的模板(卷积核组)都是一些简单的基元,比如点、线、斑、带状等这些简单的东西。也就是第一层卷积层是从输入的原图上抽取了原图的一些基元。也就是第一层卷积层的卷积核组都是自适应的从训练图像中获取了和训练图像的基元特征相匹配的基元信息,这比我们人为自己去设计的卷积核组更加贴合训练数据,因为它就是从训练数据中来的嘛。
2、神经网络中间层和最后一层的卷积核组的可视化:
因为一般我们的训练图像都是三通道的彩色图像,所以第一个卷积层的卷积核组也是3通道的,所以我们可以轻松把第一个卷积层的卷积核可视化。但是往后的卷积层,由于通道都是大于3的,甚至几十几百的通道数,所以我们就无法可视化后面层的卷积核,上图左图是我们一个个单通道逐个拿出来的可视化,所以似乎也看不到什么。
但是我们先看看最后一层,最后一层是一个4096维的输出。当我们随便拿一张图片,用像素对像素计算两张图片之间的距离时,我们发现最近邻的图片之间似乎也没有太多的相似(A)。当我们拿这个4096维的向量去图片库用最近邻搜索的时候,我们会惊奇的发现,居然最近邻的都是同类啊(B)!这也说明我们网络生成的这个4096维向量确实是能够表达出原始图片的特征的!
说明:一些很难可视化的中间层以及最后的输出层,我们还可以采取降维的方式去给它可视化,具体的比如用PCA降维,或者用t-SNE降维
3、从正向传播角度看,神经网络对图像中的哪些区域感兴趣:
我用遮挡的方式看神经网络最后判别的结果的可信度: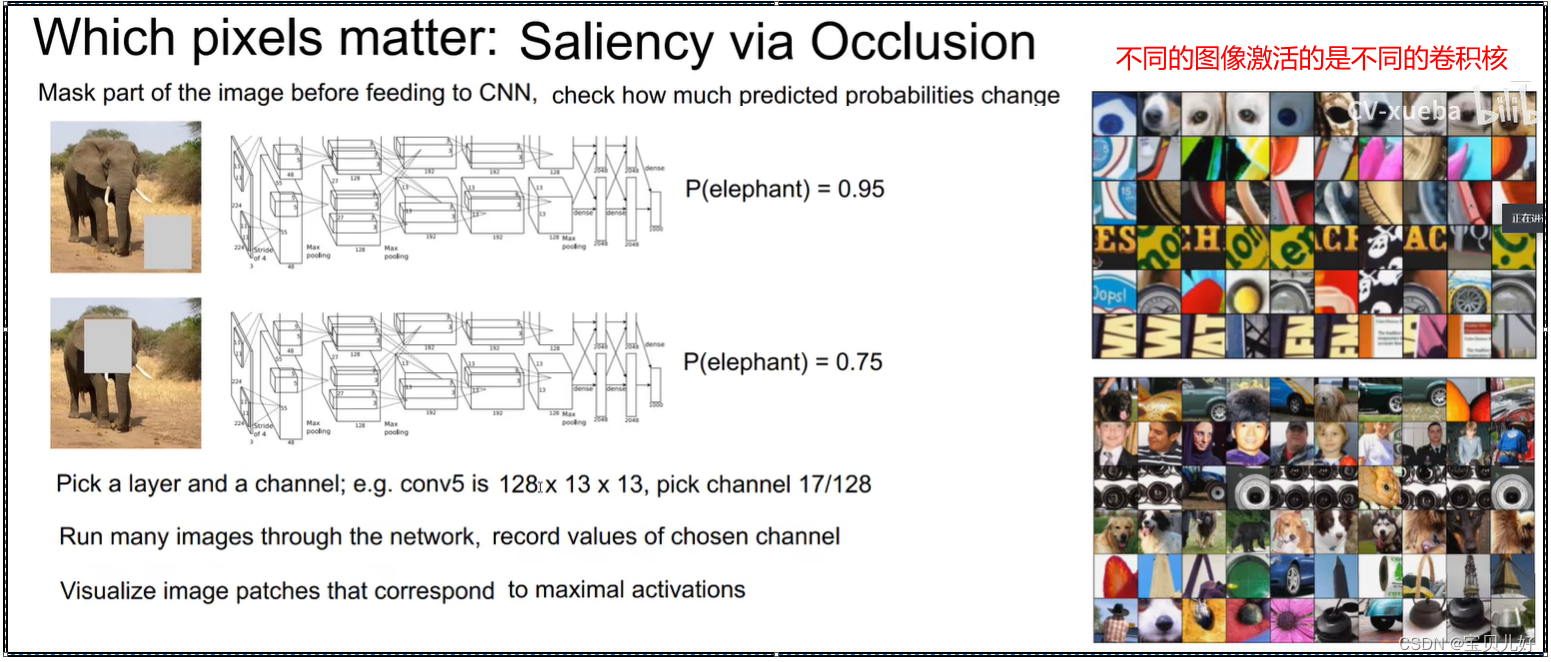
从上图左图看,神经网络在分类的时候,它和人眼一样,也是找目标的关键点的。
上图右图说明,不同的卷积核对不同的区域的相应是不一样的。比如这个卷积核对人脸的相应最大,那你给这个卷积核看一片天空,那这个卷积核是没有相应的,就是不能激活这个卷积核。同时也说明不同卷积关注的图像也是不一样的,越往上的卷积核重点关注的是局部纹理等基元信息,越往下的卷积核更加关注的是轮廓语义等高级信息。
4、从反向传播角度看,原图中哪些像素点对神经网络判别的贡献最大?
我们在训练神经网络的时候,都是先把训练图片喂入网络,然后正向传播产生一个输出,然后把这个输出了标答做loss,然后从loss开始反向求导,用导数更新网络参数。这个训练过程中,我们是把训练数据看作已知的、求得的是网络参数的导数。但是现在的情况是:我们已经训练完毕了一个效果非常好的网络,现在我们是想看看这个网络之所以效果这么好,它到底是关注了训练数据中的哪些像素,才能判断得如此正确?所以此时我们的已知就是网络的参数,我们随意一张训练图片喂入网络,正向传播后,反向求导,我们就求图片各个像素点的导数!这也叫反向可视化技术。由于喂入的训练图片是3通道的图片,那每个像素点就会求出3个导数值,然后我们选取最大的那个导数作为输出,就是下面图的右边的效果:
从上图可以看出,神经网络之所以能把狗判别为狗,也是人家重点关注了狗区域位置的像素点,而不是其他位置的像素点。所以从这个角度看,这个网络还是一个非常有效的网络的。这种反向可视化技术后来也被经常被用于检测模型优劣的方法之一。
- Saliency Maps: 让判别网络指引我们进行图像分割

Saliency是显著性的意思,saliency maps就是显著性区域。所以不管你是通过上面第3小标题那样找出原图中最重要的区域,还是像上面第4小标题那样,通过反向可视化找到原图中最感兴趣的区域,当我们只要得到了一个最显著性的区域,那我们就可以拿着这个区域去做图像分隔了。其中传统图像分割领域中的GrabCut算法就是这种做法:【OpenCV】第十七章: 图像分割与提取_bgdmodel = np.zeros-CSDN博客 这是我opencv系列中的一篇文章,其中有部分是描述这个算法的接口函数的,感兴趣的同学可以看看。
A:是原图
B:是通过已经训练好的神经网络先反向求导判断一下原图中的显著性像素点
C:是根据原图中的显著性像素点(显著性像素点就是告诉分割器哪些像素点是前景,哪些像素点是背景),分割器对原图进行前景和背景进行分割
D:就是分割的效果
也就是说,假如我们现在已经有一个非常强大的神经网络分类器,比如在image数据集上训练的resnet或者googlenet等效果非常好的判别器。那此时我们就可以用这个判别器指导我进行图像分割了。这就是grabcut的实现过程。
事实上,grabcut算法本身其实效果也不是很好。所以也不是很有名,但是有没有发现,其实grabcut的思想是伟大的!就跟GAN的对抗思想一样,这种思想是永垂不朽的!如果把思想看成"道",那目前的问题只是我们还没有找到更好的“术”去践行这个道而已。
5、Guided BP可视化: 反向传播网络中间某个特征层的某个响应值比较大的特征点,看这个特征点对应的原图是什么样的
上面第4小标题是从最后的的loss开始反向传播,一直反向到原图像素点的梯度,我们发现4中的显著性都不是非常强了。就是效果不是很好。那现在我们从网络的中间特征层开始反向传播,反向到原图像素点,看看是什么情况: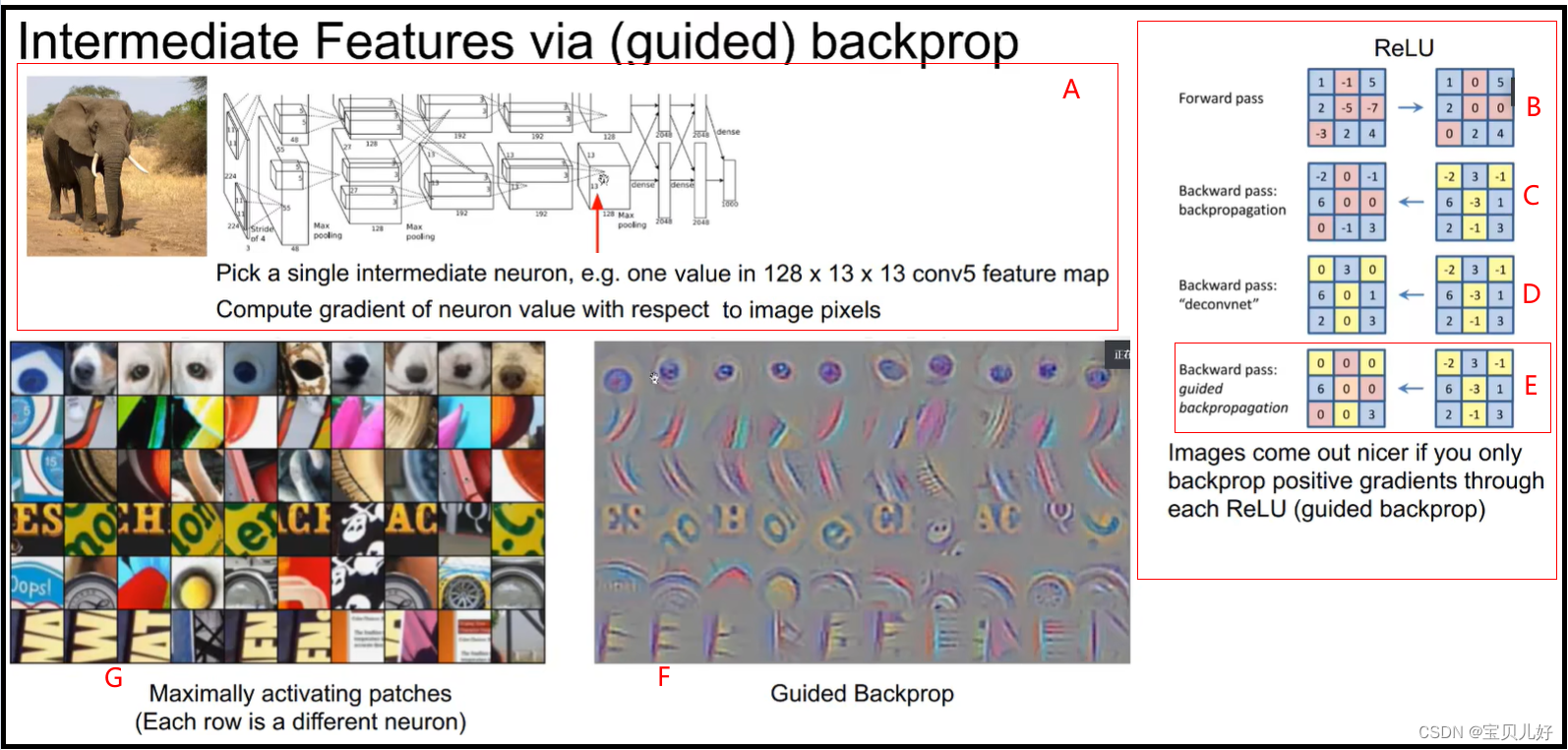
先看上图的A区域,A区域表示,我们从这个已经训练好的Alexnet的第5层的第7个通道特征图上取一个3x3小区域(当然你要尽量让这个区域中的9个数的值要大一点,别是9个0的那种就可以),然后我们从这个小区域(9个像素点)开始反向传播,看反向到原图时,这个区域(3x3区域)对应原图感受野上的像素的梯度值。
那我们开始反向传播求梯度的时候,也是和小标题4一样,已知的是训练图片的数据,求得是网络参数的梯度,也就是求的是卷积核组的梯度。但是反向求梯度时,我们有一个环节是relu操作,在relu环节我们反向求梯度时,一般我们有这三种方法:
(1)我们小标题4的求法是上图的C方法。
上图的B表示9个像素点正向传播一次。上图的C表示反向传播时小标题4的做法,它是将那些正向传播经过relu时被relu置为0的那些像素点,在反向传播时,其梯度也直接置为0。仔细想想,其实这样操作也是正常的,但是也是有点欠妥的。正常是因为:本来正向传播时,这些负值的像素点就是被relu成了0,那反向求梯度时,这些像素点是没有梯度的,就是是不存在梯度值的,那我就把这些像素点置为0也是可以的。欠妥是因为:反向求梯度时,所有像素点的梯度可是有正有负的,那你把不存在梯度的像素点置为0,似乎在说这些点的梯度比负值的梯度还大?!这是不合理的,也是欠妥的,因为负梯度其实和正梯度是对等的,负值很小的梯度说明也是象素差很大的地方啊。也所以小标题4的效果就不是很好。
(2)上图D的做法:我不管正向传播,我只简单粗暴的把梯度值都是负值的像素点的梯度都置为0。就是即使正向传播时没有梯度的像素点我也可以给它一个梯度。就是我不管它正向传播有没有被relu毙掉,只要梯度传到到这里是有值的,而且不是负值,我就强制也给你一个梯度值。这种做法叫反卷积!
(3)上图E的做法,就是我们现在讲的Guided Backprop,也是反卷积的一种,但是它综合了C、D二者,它一方面把梯度都是负值的梯度都置为0,另一方面它把正向传播时没有梯度值的点的梯度也置为0。此时反向传播到原图,我们把梯度可视化出来就是F图,对应在原图的区域就是G图。此时我们发现:只要我们给Alexnet输入比如G图中第1行的10种图片,Alexnet的第5层的第7个通道特征图上的那个3x3小区域反应就很大。同理,当我们给Alexnet输入比如G图中第2行的10种图片,那Alexnet的其他某个层的某个通道的某个小区域就有很大的相应。同理G图的其他行。
所以,通过Guided Backprop我们可以发现,神经网络的不同卷积核组其实学习的是图像的不同纹理。比如有的卷积核学的是狗鼻子,有的卷积核学的是条纹,而有的学的则是字母,,当你那不同的图片喂入网络时,只有当图片和卷积核学习的东西一样的时候,这个卷积核就被激活了,产生很大的响应。比如你给学狗鼻子的卷积核一个类似狗鼻子的图片,这个卷积核就有很大的响应,但是你给他一个字母,它就没反应。同理你给一个学字母的卷积核一个狗鼻子,它也没反应,但是你给它一个字母,它立马就有响应。
上图的G、F是浅层特征图Guided Backprop后的效果,下图是深层特征图的效果:
可见,浅层网络学习的都是局部的、基元的信息,深层的网络学习的都是全局的、高层语义的信息。
6、梯度上升法可视化卷积网络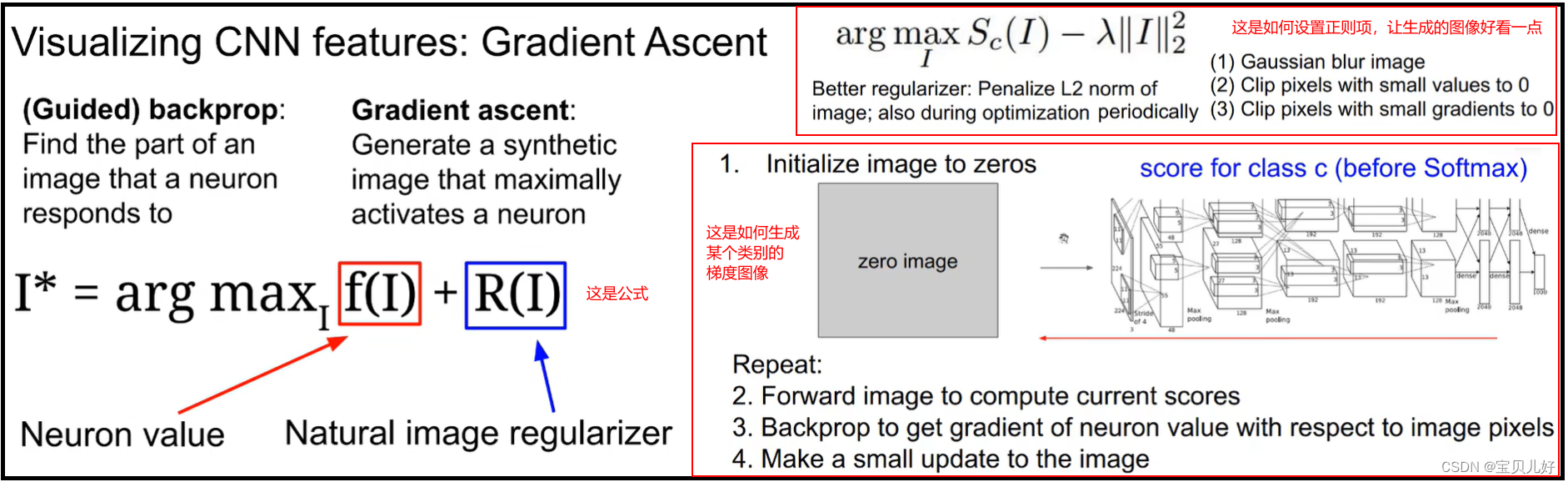
Guided BP是我们输入原图的部分区域,然后看哪些神经元响应最大;或者我们挑一个响应最大的神经元,然后看是原图的哪个区域。那梯度上升法gradient ascent则是:我们要生成一张图像,这张图像可以让某个神经元响应最大。上图左边公式中f(I)就是我们生成的图像,R(I)是一个正则约束项,让图像I更平滑一些。也就是上图右边的步骤:
第一步是我们先生成一张全黑的图片(每个像素都是0嘛);
第二步是将这个图片喂入神经网络,正向传播,传播到最后的分类输出,假如是1000个输出,假如第三个输出的类别是dumbell,那我们就选择从第三个输出的神经元开始反向传播;
第三步是从最后一层的第三个神经元反向传播求梯度,直到反向传到原图的感受野区域,求出感受野中像素的三个通道的梯度值;
第四步是把求得的三个通道的梯度值分别加到黑色的图像的三个通道上,让这张图片再正向传播,再反向求梯度(就是一个更大的梯度了),再加回到黑色图的三个通道上,再正向传播,,,如此反复,就是梯度上升法,就会得到如下的梯度图:
可见我们梯度上升法反向生成的类别梯度图中,全部都是各种各样的该类别的图形。也就是说当我们把dumbbell图像喂入神经网络,那网络最后一层的第三个神经元就会有极大的响应。
如果我们还想让生成的类别图更漂亮一点,那就用上图右上角的正则方法,就会呈现下面的视觉效果:
上图都是从神经网络的最后一层反向传播得到的梯度图,我们也可以从神经网络的中间层的神经元开始反向传播,不断把梯度加到黑色图像上,也是可以得到中间神经元的梯度图的: 
可见,用梯度上升法可视化的卷积网络和Guide bp可视化的结论是一样的:浅层神经元关注的都是局部的基元信息,深层神经元关注的都是全局的语义信息。当然深层神经元都是浅层神经元级联后的效果。
下图是一些效果展示:
下图是在神经网络第6层,也就是输出层上加上一些正则项后的效果,会更加逼真一些:
7、生成对抗样本,愚弄神经网络
那我们如何加一点点东西来愚弄网络,也就是给上图的右图第1列图像添加一点点东西变成第2列图像。我们人类肉眼是可以分辨出第1列和第2列图像都是一样的,但神经网络就被骗了,会把大象判为考拉,把帆船判为ipod。那如何加这一点点的东西呢?看下面的例子: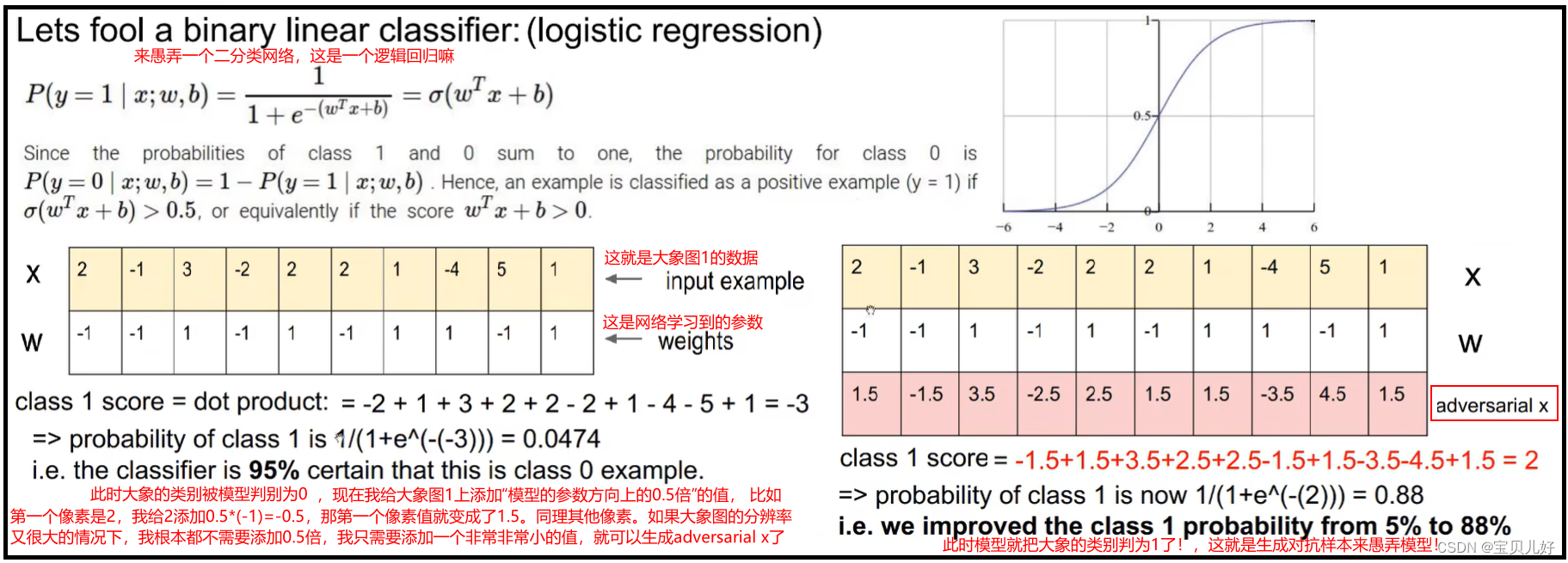
可见,我们如何来愚弄神经网络呢?比如我们想让网络把大象判为考拉,我们只需要从考拉那个类别的输出神经元开始反向传播求出原图所有像素的梯度,然后把这个梯度乘以一个很小的系数,加到大象图上,大象就很容易被神经网络判为考拉了。这也是神经网络的脆弱性的地方。
- 愚弄神经网络的应用————deepdream生成艺术品

DeepDream就是你先选择网络中某个层的某个神经元,然后你正向传播,传播到这个神经元后就停止,开始反向传播求这个神经对应的像素的梯度,然后把这个梯度 添加到原图对应的像素。那原图对应的位置像素就被加强了,你再正向传播这个原图,传到那个神经元后,那个神经元就有了较大的响应,然后你再反向传播继续添加梯度到原图,继续正向传播,,,如此反复,那个神经元的特征就被合成到原图中了。此时的效果看着就像一副艺术图。
由于我们的分类网络在学习过程中,是训练(或者说是学习)了数十万张或者数百万张图片,最后收敛的分类模型,所以这个模型它是记忆了训练数据集中的所有图片的特征了。当你输入一张天空的图片,网络中只有学天空的神经元才对这个图片有强烈响应,其他神经元(比如学动物的神经元)是没有响应或者很弱的响应的。当你把学动物的这个神经元的梯度不断的添加到天空图中,而且是一遍比一遍强化,那原图就会逐渐有了动物的图案,学动物的这个神经元也会逐渐加强响应。
8、特征的可逆性feature inversion
就是从特征还原原图,也叫原图重建。
从最后输出的特征和网络能不能恢复出数据集?从上图可以看出,如果你仅仅只有最后的特征,你想恢复输入的图像也是不太可能的。所以你可大胆的把你的特征和网络公开,别人只有这些信息是恢复不了原图的。
9、纹理合成 Texture Synthesis
纹理合成就是通过一个小图片去生成一个大图片:

上图是用近邻法生成图像纹理。但是对于一些简单的纹理,近邻法的效果还可以,但是对于复杂的纹理,用近邻法效果就非常差,所以我们现在一般都不用最近邻了,都用神经网络来合成纹理。
而神经网络合成纹理的关键点就是生成GRAM矩阵。gram矩阵的生成过程下面的1234步骤是正常的计算过程,下图右下角的计算过程是一个巧妙地过程,总之都可以算得gram矩阵。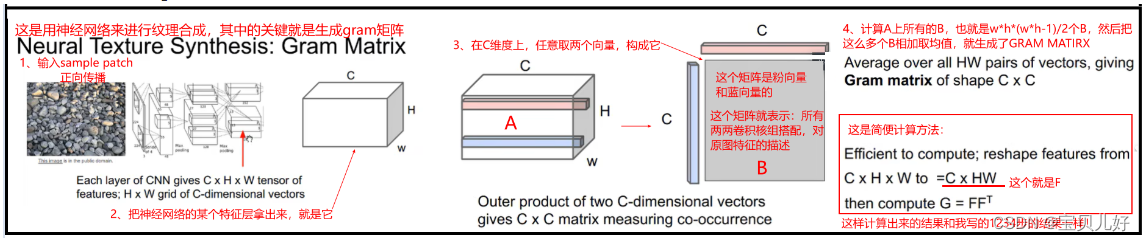
说明1:步骤3中,在A上任意取两个像素,这两个像素的通道可都是C,就是取两个长度是C的向量,然后计算这两个向量的外积B。意思就是说:在网络的第3层卷积层,有C个卷积核组,每个卷积核组学习的纹理都不一样,当我把A转换成B后,B中哪个位置的值较大,就说明哪两个卷积核组在联合响应原图的。所以当我把所有的B都表示出来就表示该层所有卷积核都是谁和谁经常在一起联合响应原图纹理的,或者说原图中的纹理经常会激发哪些卷积核响应。所以此时我再把所有的B对应位置相加再取个平均数,就是该层卷积层对原图纹理的响应最频繁的卷积核组的组合,就是该层卷积层对原图提取的最频繁的信息。
所以,如果这个特征层我是从浅层网络中取得的,那这个gram矩阵就是对于原图局部信息的响应矩阵,如果是从深层网络中取得的特征层,那算得的gram矩阵就是对原图轮廓信息的响应矩阵。所以Gram矩阵就是不同粒度的原图的风格信息!,或者说gram矩阵描述了原图的纹理!或者说gram矩阵是记录了网络中各个卷积核组直接的相关性信息的矩阵!
说明2:从上面生成gram矩阵的步骤看,这个gram矩阵是不是和输入图像的WH没有关系啊,只和C有关系,WH只是影响上图B的厚度,但是后面B还得取均值呢。所以gram矩阵之和C有关,所以我们是可以给网络输入一个小patch,计算这个小图片的gram矩阵。
有了GRAM矩阵,我们就可以生成纹理图像了: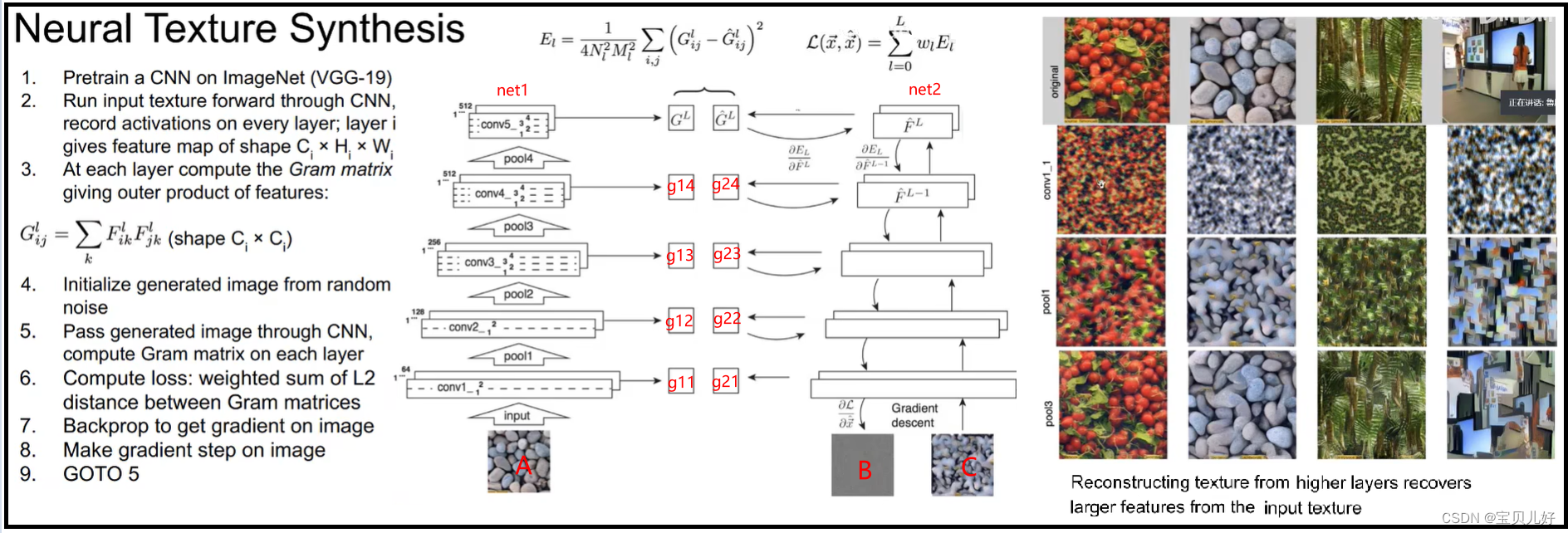
我们可以给net1喂入的纹理图片是一个小图片patch image, 因为网络的每个特征层计算出来的gram矩阵和wh没有关系,只和通道数有关。所以net1可以生成g11,g12,g13,g14,GL这5个gram矩阵。现在我们用这5个gram矩阵中的任意一个作为监督标签。我们再搭建一个网络net2,先给net2喂入一个大尺寸的随机图B,让B在net2中正向传播后,也计算出g21,g22,g23, g24, GL尖,我们把net2的loss设置成net2的gram矩阵和net1对应层的gram矩阵直接的差异。而这个差异用对应位置的平方差即可。让net2回传的梯度当作B继续正向传播,再回传,如此反复,图片B就被迭代成C了,就是生成了图像C。
上图右边表示用不同特征层的gram矩阵来监督net2,就生成不同颗粒度的风格信息。
10、风格转移Neural Style Transfer
上面小标题9我们讲了如何从图片中提取纹理信息(gram metrix),小标题8又讲了神经网络每层的特征图信息,那我们是不是就可以既保留原图的特征、又加入其他图片的纹理信息?是的,可以的,这就是风格转移:
风格转移的效果和做法是: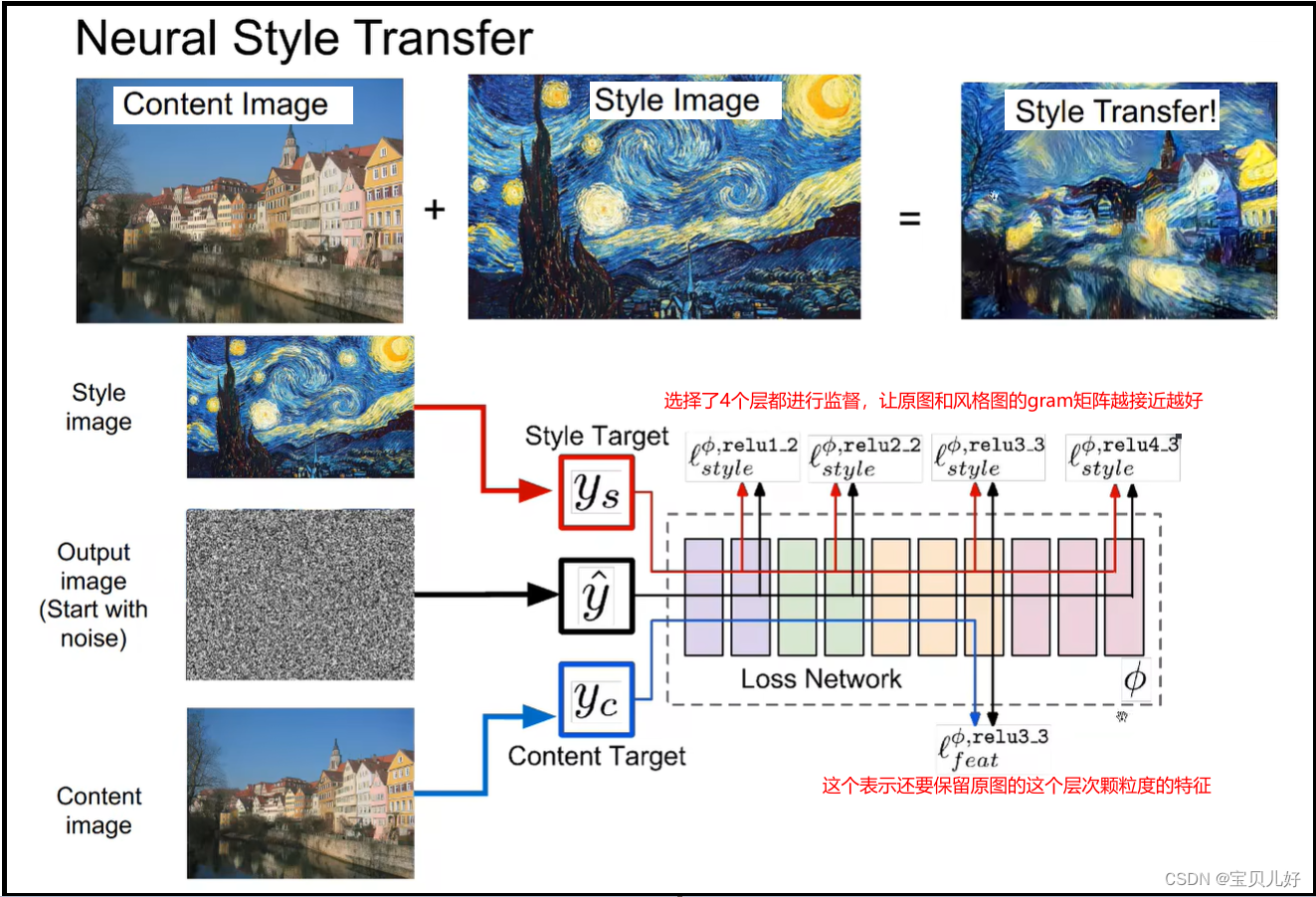
就是损失分了两部分,一部分是风格损失,另一部分是内容损失。我们可以调整两部分损失的比例,如果内容损失更小,那风格迁移后的图像更像原图一点,如果风格损失更小,那风格迁移后的图像更具风格图的画风: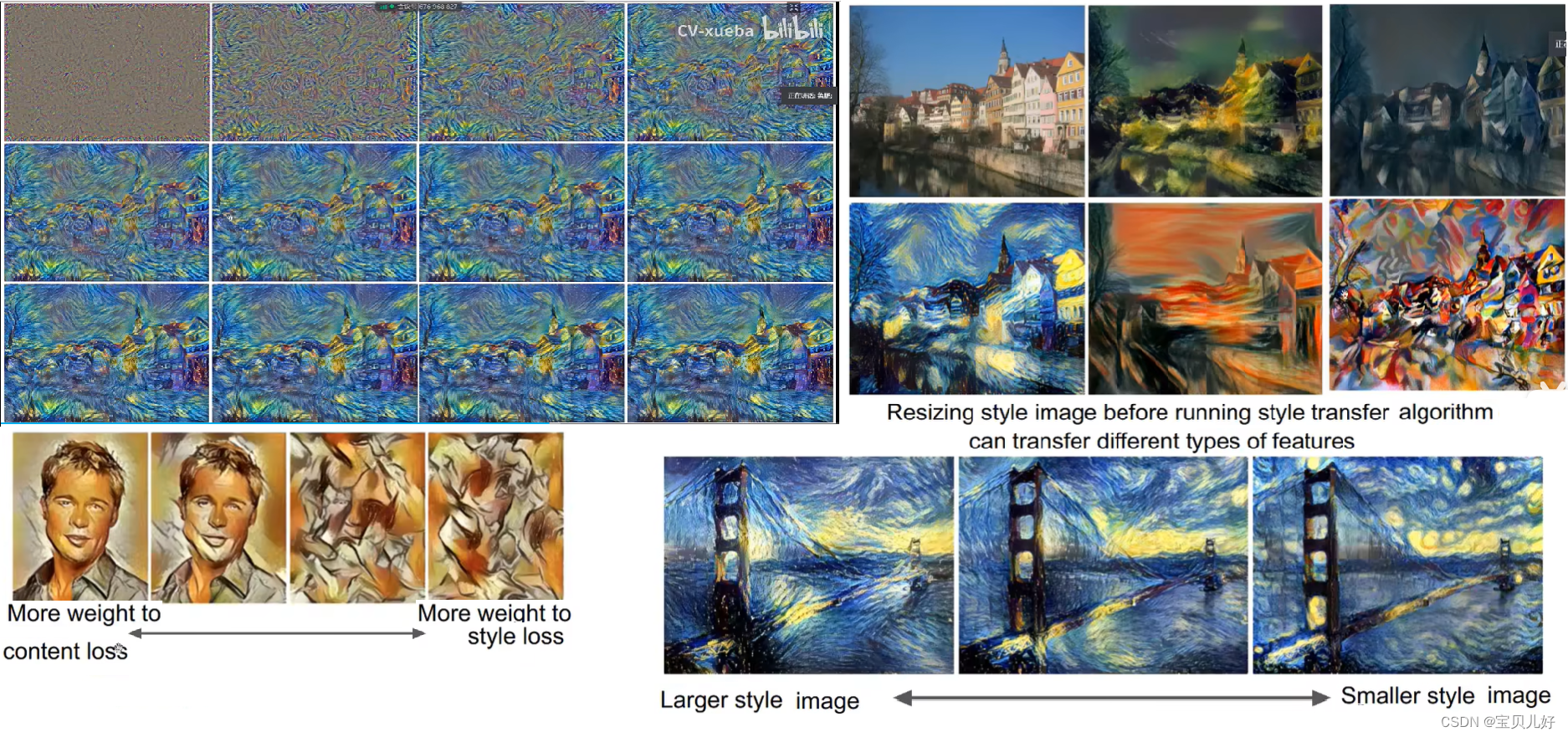
11、快速风格转移
由于我们输入的都是一个随机数图片,然后不断往返迭代才能生成风格图,这种做法效率很低,所以就出现了fast style transfer: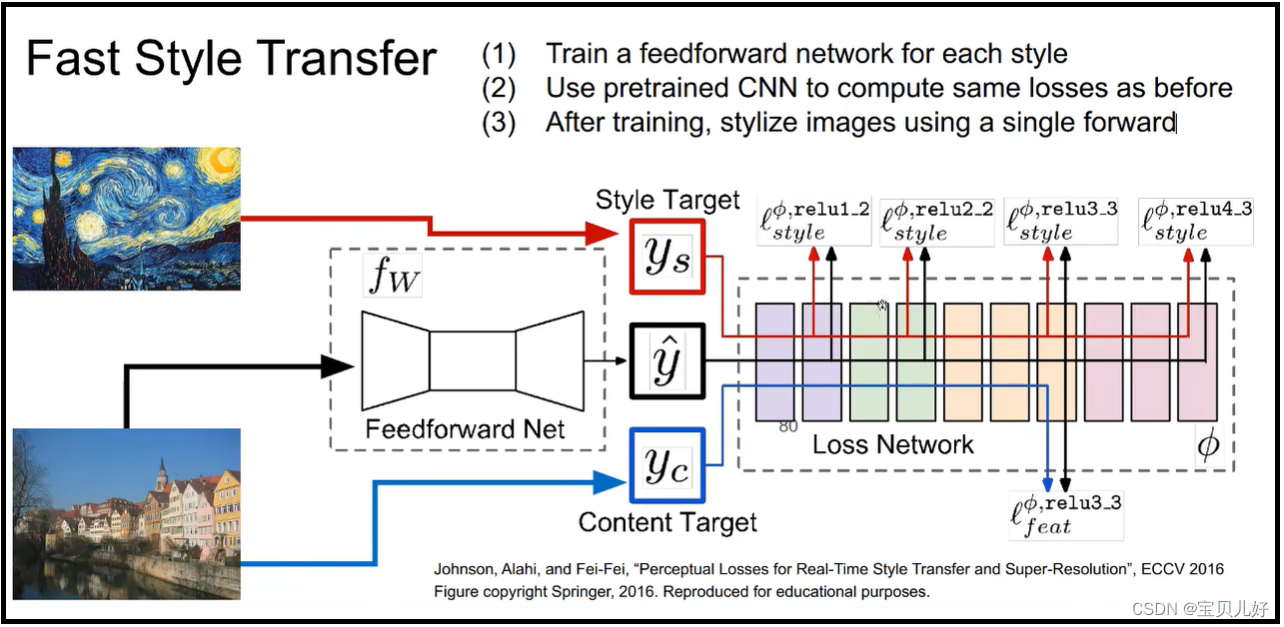
就是我不用通过上图右边的网络一次次回传迭代来生成风格图。我另其炉灶,我再搭建一个Feedforward net,我们训练这个feedforward net,让输入这个网络的原图,正向传播到输出图y尖,然后把y尖再送入后面的网络,正向传播一下,计算一下所有的损失,然后根据这个损失我feedforward net的参数,让feedforward net网络的参数迭代到,它输出的y尖,这个歌y尖在后面网络中的风格损失+内容损失最小。当训练完毕,我就只保留feedward net,这样我输入一个原图,就立马给我风格转移了。但这样做的坏处是,一个网络只能训练一种风格。你想生成多种风格的图片,你得训练多个feedforward net。
下面是效果图:
12、混合风格转移
fast style transfer 虽然快,但是就是只能转移一种风格,如果我想转移多种风格混合呢?首先我们要了解一下归一化方法: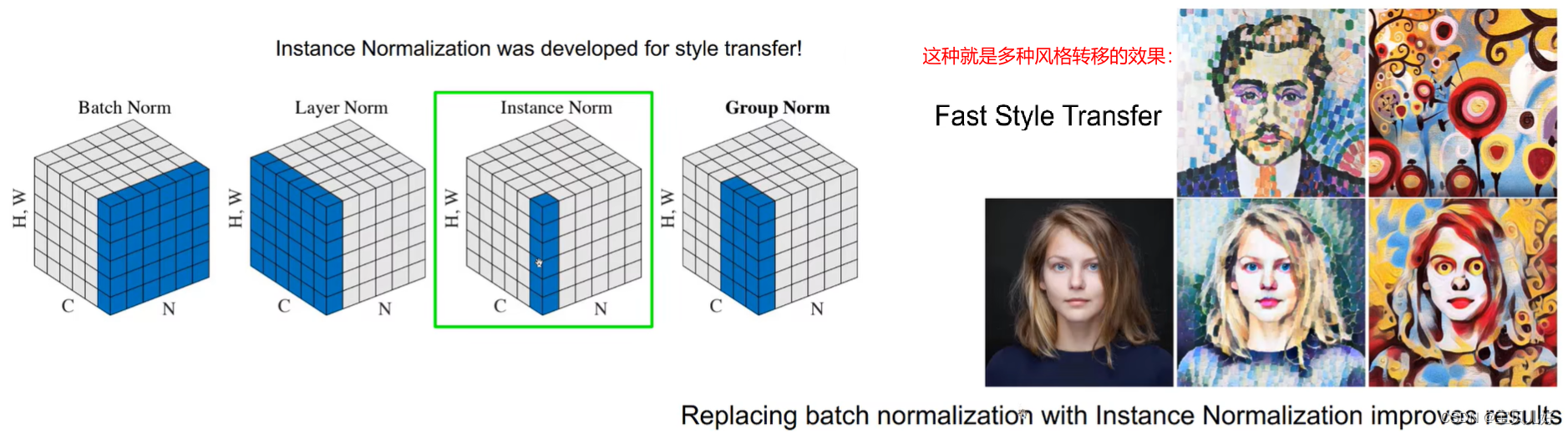
batch norm是对所有样本做归一化,是在样本空间中的归一化操作,是和样本个数有关系的,也叫批归一化。是一个卷积核对所有样本的输出要符合正态分布。
layer norm是对一个样本的所有层做归一化,和样本量没有关系。是一个样本的所有卷积核的输出要符合正态分布。
instance norm是对一个样本的一个卷积核的输出进行归一化。简单理解就是对一个通道的特征图进行归一化。比如某个隐藏层输出是128个通道图,我只对这128个通道图中其中一张通道图进行归一化。
group norm是只考虑一个样本的多个卷积核的输出进行归一化。
归一化的目的都是避免神经网络正反传递过程出现衰减的情况。
我们在多风格转移中一般用的都是实例归一化,因为在风格化中其实是没有batch的概念的,我们是希望不同通道特征层是有不同的风格的,所以如果使用了batch norm就会把不同风格又混合了,我们其实是想各风格是各风格的,互不相干的,所以我们尽量不要用batch norm,要用instance norm,性能就能提高。
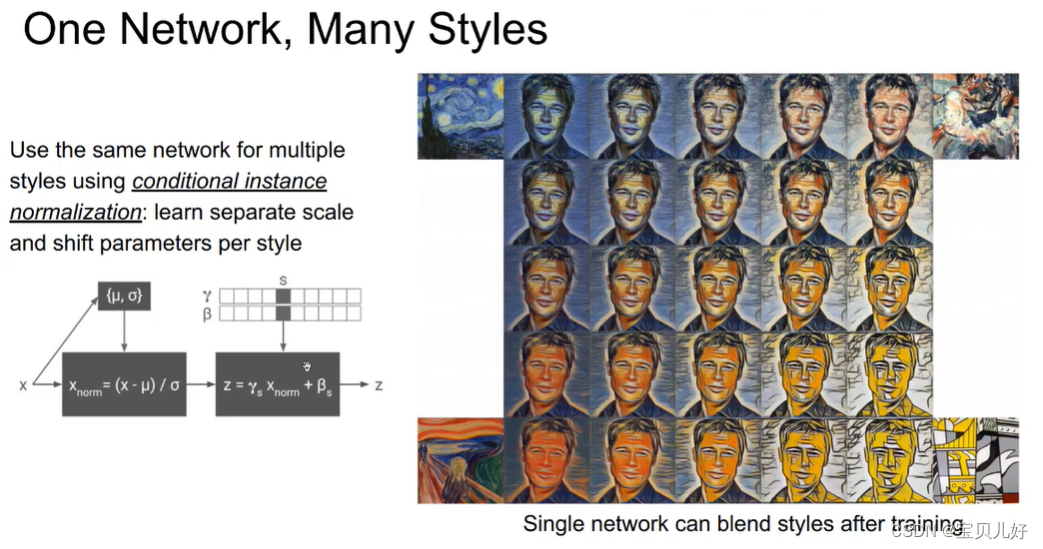
我们还发现不同风格的占比只和实例归一化的γβ有关,所以只要我们调整γβ的不同值,我们就可以在风格之间随意转换,如下图所示:
















 2536
2536

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









