







卷积核的特征
grad-cam:通过梯度可视化网络的注意部分
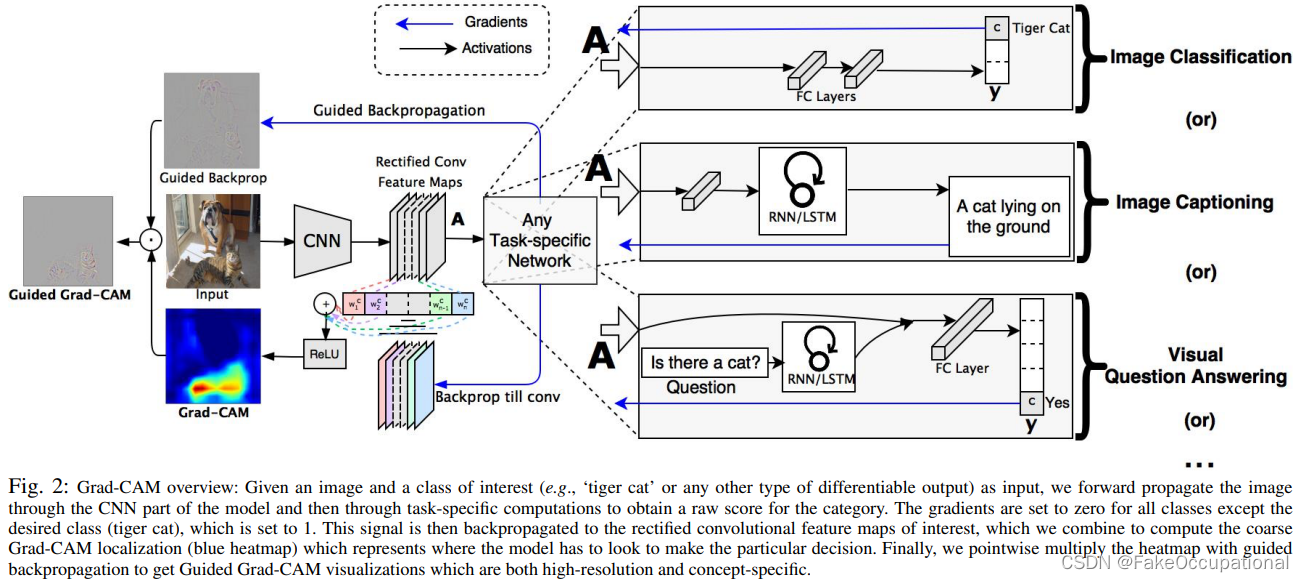
我们介绍了一种使用梯度信号组合特征图的新方法,该方法不需要对网络结构进行任何修改。这使得我们的方法可以应用于现有的基于CNN的架构,包括用于图像字幕和视觉问答的架构。对于完全卷积结构,CAM是Grad CAM的特例。



github的例子
# https://github.com/jacobgil/pytorch-grad-cam
from pytorch_grad_cam import GradCAM, ScoreCAM, GradCAMPlusPlus, AblationCAM, XGradCAM, EigenCAM, FullGrad
from pytorch_grad_cam.utils.model_targets import ClassifierOutputTarget
from pytorch_grad_cam.utils.image import show_cam_on_image
from torchvision.models import resnet50
model = resnet50(pretrained=True)
target_layers = [model.layer4[-1]]
input_tensor = # Create an input tensor image for your model..
# Note: input_tensor can be a batch tensor with several images!
# Construct the CAM object once, and then re-use it on many images:
cam = GradCAM(model=model, target_layers=target_layers, use_cuda=args.use_cuda)
# You can also use it within a with statement, to make sure it is freed,
# In case you need to re-create it inside an outer loop:
# with GradCAM(model=model, target_layers=target_layers, use_cuda=args.use_cuda) as cam:
# ...
# We have to specify the target we want to generate
# the Class Activation Maps for.
# If targets is None, the highest scoring category
# will be used for every image in the batch.
# Here we use ClassifierOutputTarget, but you can define your own custom targets
# That are, for example, combinations of categories, or specific outputs in a non standard model.
targets = [e.g ClassifierOutputTarget(281)]
# You can also pass aug_smooth=True and eigen_smooth=True, to apply smoothing.
grayscale_cam = cam(input_tensor=input_tensor, targets=targets)
# In this example grayscale_cam has only one image in the batch:
grayscale_cam = grayscale_cam[0, :]
visualization = show_cam_on_image(rgb_img, grayscale_cam, use_rgb=True)
参考与更多
arxiv : Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization
Grad-CAM 原理和实现(这里作者是用hook实现的)
在最高的层中,我们开始识别类似于网络被训练分类的对象中发现的纹理,例如羽毛,眼睛等
一个值得注意的观察结果:许多这些过滤器是相同的,但通过一些非随机因子(通常为90度)旋转。这意味着我们可以通过找到一种方法使卷积滤波器旋转不变,从而有可能将卷积中使用的滤波器数量压缩一个大因子。我可以看到一些可以实现这一点的方法这是一个有趣的研究方向。
令人震惊的是,旋转观察结果即使对于相对高级的滤波器(例如 中的滤波器)也成立
















 8106
8106











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









