











在公众号「python风控模型」里回复关键字:学习资料
扣扣学习群:1026993837 领学习资料
介绍
无论机器学习模型多么强大,它们都无法完全击败您在那些“啊哈”中获得的感觉。通过丰富的视觉效果探索数据的时刻。但是,在你说“这真的变老了”之前,你可以创建很多直方图、散点图、热图。
在那些时刻,你需要一些东西来提醒你数据是多么的惊人和迷人。您需要从 FlowingData 或相关子版块中的杰作视觉效果中获得灵感,但您不必走那么远。最近,我有幸遇到了 UMAP——一个 Python 包,它以惊人的美丽方式可视化和聚类高维数据。这正是我需要记住的,为什么我两年前开始学习数据科学。
今天,我们将学习如何使用 Uniform Manifold Approximation & Projection (UMAP) 包通过如下可视化将多维数据集投影到 2D 来分析多维数据集:
什么是UMAP?
UMAP 是一个降维算法和强大的数据分析工具。
它在速度方面类似于 PCA(主成分分析),并且类似于 tSNE 来降低维度,同时尽可能多地保留数据集的信息。在 2018 年引入 UMAP 算法之前,PCA 和 tSNE 存在两个最显着的缺陷:
-
PCA 速度非常快,但代价是在缩减后丢失了数据的更精细细节
-
尽管 tSNE 保留了数据的底层结构,但它的速度非常慢。
稍后我们将更多地讨论这些差异。现在,是第一次体验 UMAP 的时候了,我们将立即从一个具有挑战性的数据集开始:
为 Kaggle TPS 九月竞赛生成的合成数据。
>>> tps.shape(957919, 119)
Kaggle TPS 9 月数据集包含约 100 万行和约 120 个具有二进制目标的特征。它们都是数字的,我们对在这个数据集上执行正确的 EDA 非常无能为力。我们的选项仅限于打印汇总统计数据和绘制每个特征的直方图。
让我们看看UMAP能为我们做什么。在使用它之前,我们将对数据集进行采样以避免过度绘制并填充缺失值:
在这里,目标代表客户是否要求保险。
安装和导入 UMAP后,我们初始化流形算法并将其拟合到X,y在熟悉的 Sklearnfit/transform模式中:
>>> X_reduced.shape(100000, 2)
默认情况下,UMAP 将数据投影到两个分量 (2D) 中。让我们创建一个由目标类着色的散点图:
>>> plt.scatter(X_reduced[:, 0], X_reduced[:, 1], c=y, s=0.5);

尽管看起来很有趣,但情节并没有显示出任何清晰的模式。这是因为我们在拟合 UMAP 之前没有对特征进行缩放。该算法使用距离度量对相似的数据点进行分组,并且具有更高尺度的特征会影响此类计算。
因此,我们将选择 Quantile Transformer 根据其分位数和中位数对特征进行缩放。这种缩放方法更适合数据集,因为它包含许多倾斜和双峰特征:
# 绘制结果plt.scatter(X_reduced_2[:, 0], X_reduced_2[:, 1], c=y, s=0.5);

现在,我们正在谈论。UMAP 成功地捕捉到了目标类之间隐藏的区别。我们还可以看到一些异常值(黄色斑点周围的点)。毕竟数据集并没有那么具有挑战性。
但是,这个情节与我向您展示的内容完全不同。它仍然被过度绘制以查看每个集群内的结构模式。为了更上一层楼,我们将使用具有更多功能的默认 UMAP 可视化包。我们将需要一个更好的数据集。
使用 UMAP 实现更好的可视化
本节将分析 Kaggle TPS May 的竞争数据,该数据根据约 75 个数字质量对约 200k 电子商务列表进行分类。让我们导入它并快速浏览一下:
为 Kaggle TPS 九月竞赛生成的合成数据。
目标包含九个类。
和以前一样,我们将缩放所有特征,但这次使用简单的对数转换。然后,我们拟合 UMAP 流形:
拟合完成后,我们将导入umap.plot包(单独安装)并绘制点云:
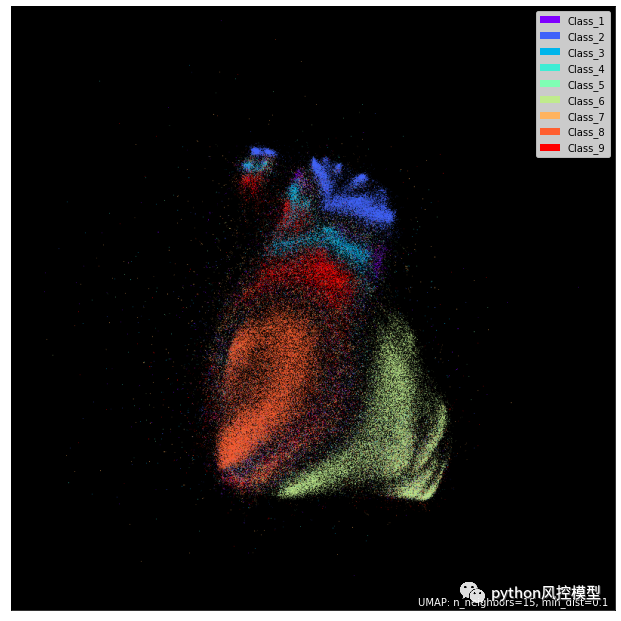
它不像来自太空的星云吗?我们可以清楚地看到 8 级在空间中占主导地位,并聚集在中心周围。第 6 类也明显区别于其他类。我们在第 8 类周围看到半圈混合数据点。关于单例数据点,它们可能被归类为异常值。
上面关于可视化的说明——我们只是将拟合的流形(不是转换的数据)传递给
points函数并指定颜色编码的标签。我也选择了fire作为一个黑暗的主题。
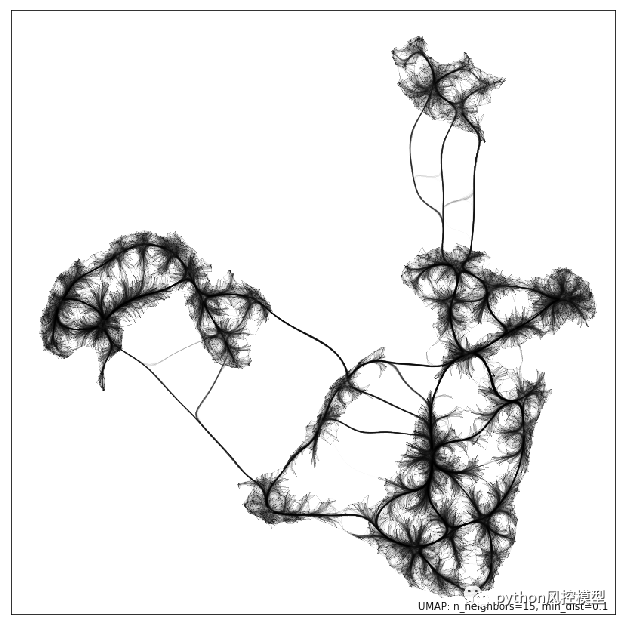
您还可以创建连接图umap.plot.connectivity用于诊断目的并更好地理解歧管结构。请注意,创建这些图非常耗时且需要大量计算/内存。

UMAP最重要的参数
底层缩减算法有许多参数可以显着影响流形,从而影响视觉效果。最重要的四个是:
-
n_components -
n_neighbors -
min_dist -
metric
正如您可能已经猜到的那样,n_components控制投影后的维数。为便于可视化,默认值为 2。但是,对于具有超过 100 个特征的数据集,2D 可能不足以完全保留数据的底层拓扑结构。我建议以 5 步尝试 2-20 之间的值,并评估不同的基线模型以查看准确性的变化。
接下来,我们有n_neighbors. 它控制 UMAP 在构建流形时为每个样本查看的本地邻域的区域。较小的值将关注点缩小到局部结构,考虑到特性和小模式,可能会失去全局。
较高的值可n_neighbors提供更大的灵活性,并允许 UMAP 专注于相应维度中数据的更广泛“视图”。当然,这是以丢失结构的细节为代价的。此参数的默认值为 15。
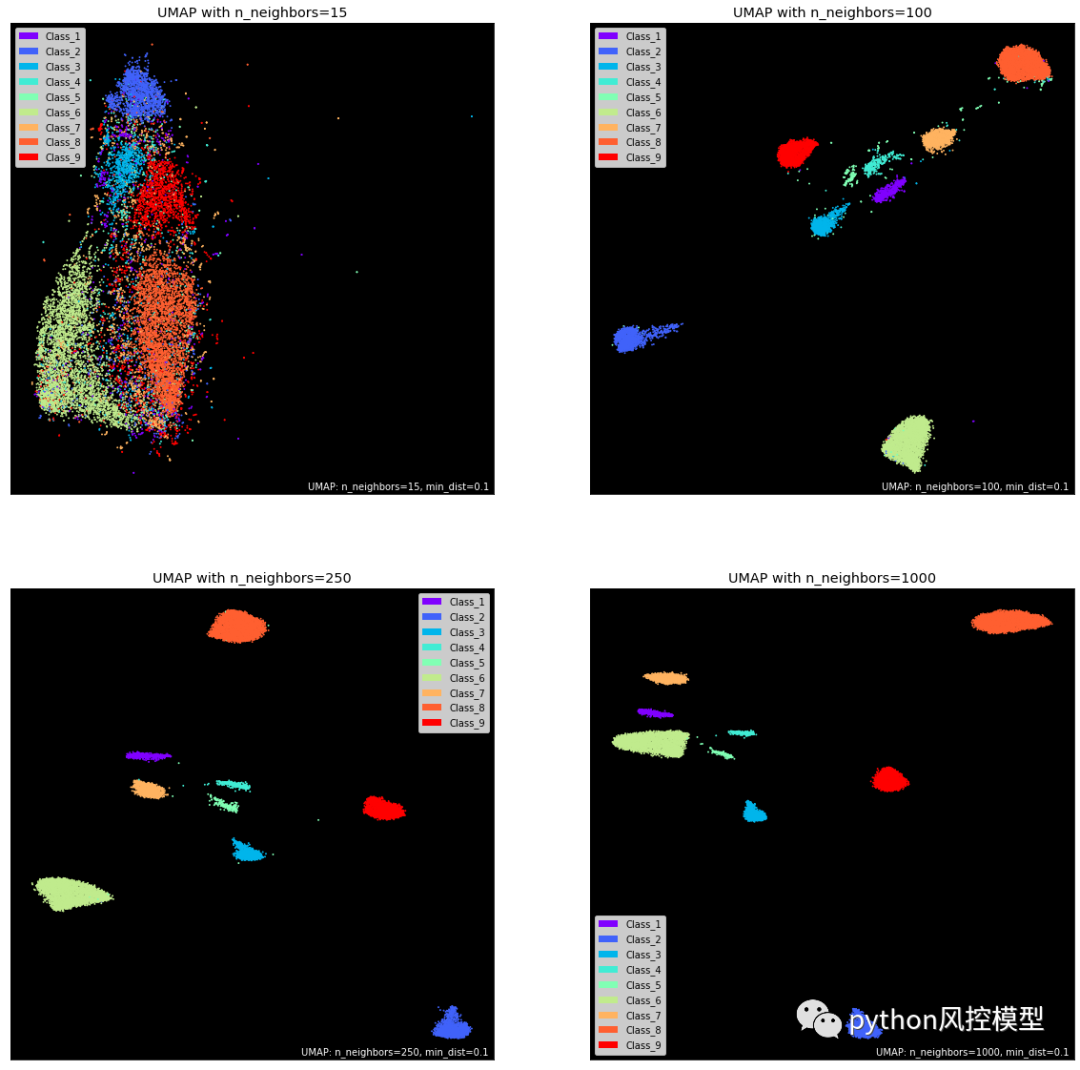
将具有不同 n_neighbors 的 UMAP 流形拟合到 TPS June 数据样本
另一个关键参数是min_dist控制数据点之间的字面距离。您可以调整默认值 0.1 以控制不同点云的紧密度。较低的值将导致嵌入更密集,让您更轻松地查看单个集群。这在聚类期间可能很有用。相比之下,接近 1 的值会给点更多的喘息空间,让您能够看到更广泛的拓扑结构。
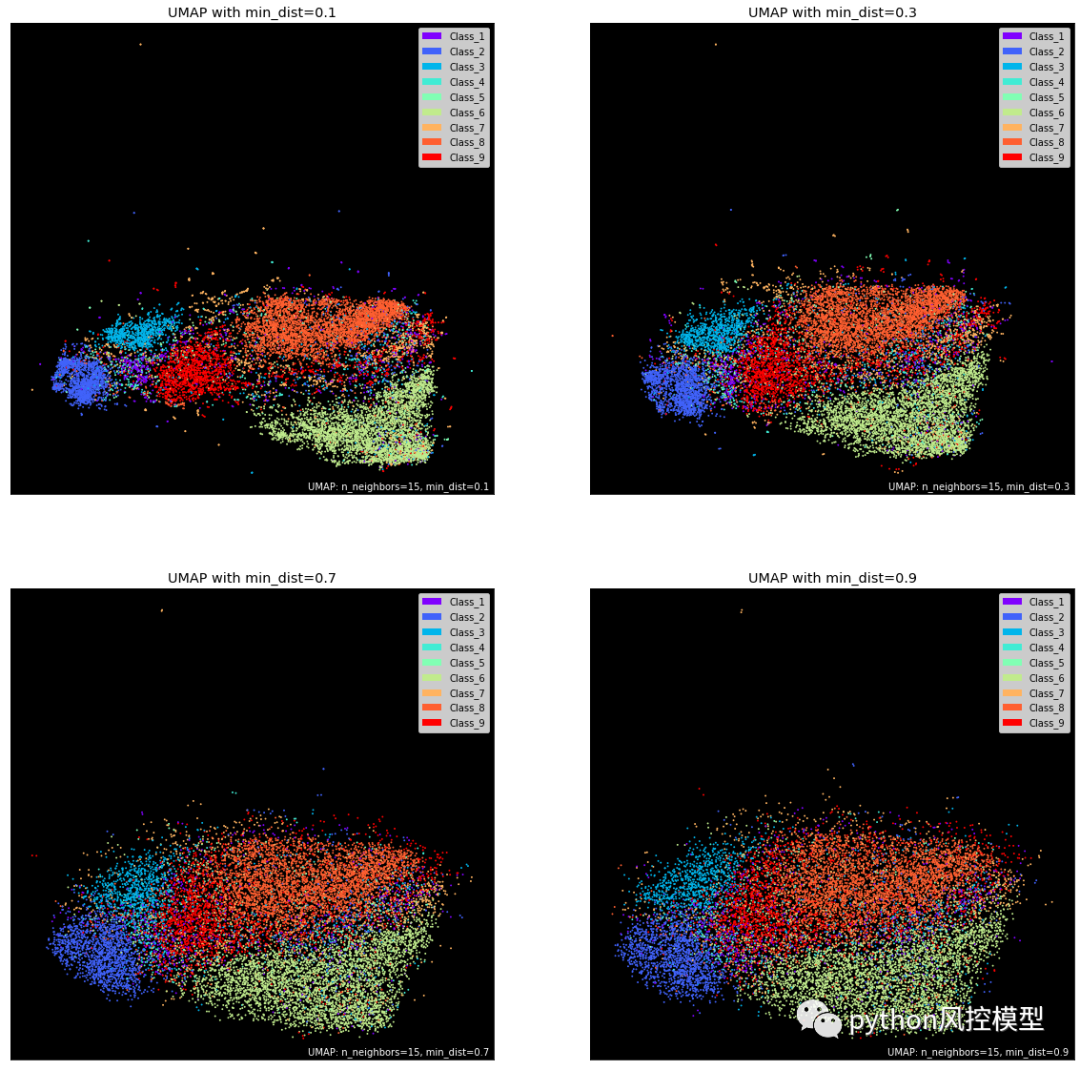
metric表示计算点之间距离的公式。默认值为euclidean,但您可以在许多其他选项中进行选择,manhattan包括minkowski和chebyshev。
使用 UMAP 的最佳实践
使用 UMAP 时首先考虑的是 RAM 消耗。在幕后,UMAP 会消耗大量内存,尤其是在拟合和创建连接图等图表的过程中。我建议在至少有 16GB RAM 的机器上运行 UMAP。
例如,即使是绘图部分的 200k 行数据集,在创建连接图时也会消耗约 18GB 的 RAM。文档建议设置low_memory为 True 作为可能的解决方法。此外,我建议通过使用 NumPy 将每一列转换为可能的最小子类型来减少数据集的内存使用量。我在上一篇文章中详细讨论了处理内存不足问题:
此外,不要忘记转换/缩放数字特征,因为它们默认具有不同的比例。我建议将 QuantileTransformer 用于双峰、三峰等疯狂分布。PowerTransformer 最适合偏斜特征。无论您选择哪种变压器,目标始终是使特征尽可能呈正态分布。
概括
今天,我们已经介绍了 UMAP 的基础知识,并且只了解了它的一小部分功能。为了进一步阅读,我建议查看包的文档。在那里,您将看到 UMAP 的不同用例以及 Google 等科技巨头如何在各种项目中使用它。
还有专门的部分用于将 UMAP 与其他降维算法进行比较。对于数学爱好者,您还可以阅读 UMAP 的工作原理及其公式的证明。感谢您的阅读

python实战因子分析和主成分分析(附代码)


















 668
668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











