








自己一直在做企业内部的垂类大模型,但随着运营深入,发现光有企业内部的领域数据还不足以微调出一个健壮的领域大模型,因为泛化能力比较弱。
在领域数据中融入公共数据进行训练是公认的提升领域大模型泛化能力的方法,下面是我整理的面向大模型的六大类高质量语料集,共涉及20多个网上公开数据集(附有网址),希望对你有所帮助。
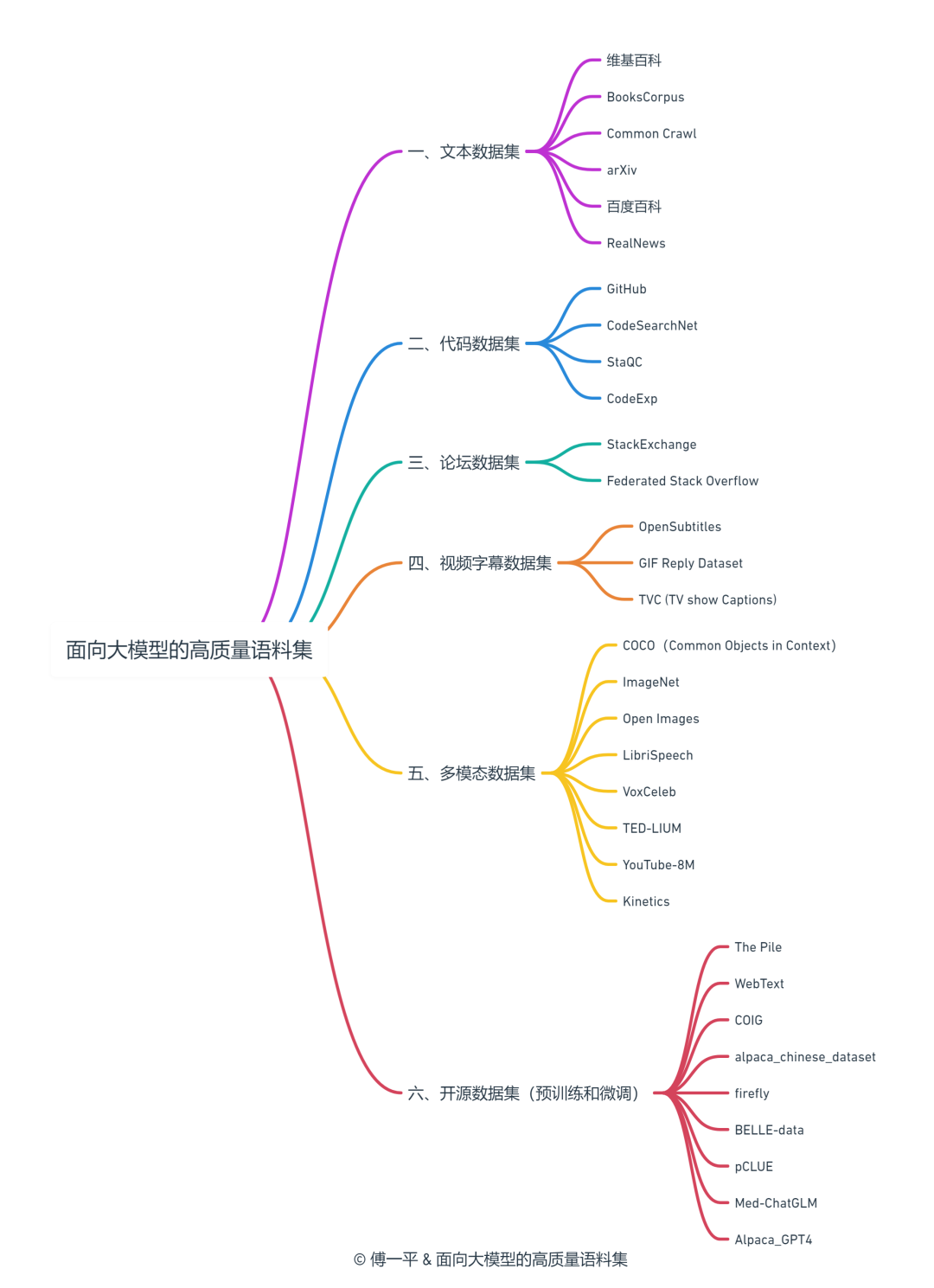
一、文本数据集
1、维基百科
简介:
免费的多语言协作在线百科全书,内容覆盖广泛,由志愿者社区编写和维护。
用途:
用于训练语言模型的基础知识库。
链接:
https://dumps.wikimedia.org/backup-index.html
范例:
Title: Machine Learning
Content:Machine learning (ML) is the study of computer algorithms that improve automatically through experience. It is seen as a part of artificial intelligence. Machine learning algorithms build a model based on sample data, known as "training data", in order to make predictions or decisions without being explicitly programmed to do so.
2、BooksCorpus
简介:
包含大量书籍文本,主要用于训练语言模型的故事讲述和反应能力。
用途:
语言模型训练。
链接:
https://paperswithcode.com/dataset/bookcorpus
范例:
Title: The Adventures of Sherlock Holmes
Content: To Sherlock Holmes she is always the woman. I have seldom heard him mention her under any other name. In his eyes she eclipses and predominates the whole of her sex.
3、Common Crawl
简介:
包含从2008年至今抓取的大量网页数据。
用途:
通用语言模型训练。
链接:
https://commoncrawl.org/
范例:
URL: http://example.com/article
Content: The global economy is facing a period of uncertainty. Various factors including geopolitical tensions and market volatility are contributing to this instability.
4、arXiv
简介:
ArXiv 是一个免费的分发服务和开放获取的网站,包含物理、数学、计算机科学、定量生物学、定量金融学、统计学、电气工程和系统科学以及经济学等领域的2,235,447篇学术文章。美国国家卫生研究院有各种生物医学和行为研究领域的论文。
用途:
学术论文数据集,用于训练语言模型。
链接:
https://www.kaggle.com/Cornell-University/arxiv
范例:
Title: A Survey on Machine Learning
Abstract: This paper provides a comprehensive survey of the current state of machine learning research. We cover various algorithms and their applications in different domains.
5、百度百科
简介:
中文在线百科全书,内容覆盖广泛。
用途:
中文语言模型训练。
链接:
https://baike.baidu.com/
范例:
Title: 机器学习
Content: 机器学习是一种通过数据和算法来改进性能和预测结果的人工智能方法。它包括监督学习、无监督学习和强化学习等类型。
6、RealNews
简介:
一个英文新闻文章数据集,包含大约130GB的文本数据。
用途:
通用语言模型训练。
链接:
https://paperswithcode.com/dataset/realnews
范例:
{"title":"Reynolds High School tragedy: more laws are not the answer","text":"by In the news\nby Dan Lucas\nOn Tuesday morning a 15-year-old killer murdered fellow student Emilio Hoffman, age 14, and wounded a teacher at Reynolds High School in Troutdale, Oregon. The killer brought an AR-15 type rifle, a semi-automatic pistol and enough ammunition to do far more harm......","summary":null,"authors":["In The News"],"publish_date":"06-13-2014","status":"success","domain":"oregoncatalyst.com","warc_date":"2016-12-11T13:48:31Z","split":"train"}
二、代码数据集
1、GitHub
简介:
一个大型的开源代码库,包含来自 GitHub 上的开源项目的代码和相关文档。
用途:
训练代码生成和理解模型。
链接:
https://www.kaggle.com/github/github-repo-dataset
范例:
Repository: example-repo
File: main.py
Content:
def greet(name):
print(f"Hello,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1784
1784

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











