







Zynq-7000 采用可扩展式处理平台架构(Extensible Processing Platform、EPP),是 Xilinx 用 28nm HKMG工艺制成的低功耗,高性能,高扩展性的新型芯片,这款新品里面集成了ARM CORTEX-A9 MPSOC 硬核以及相应的SOC系统。
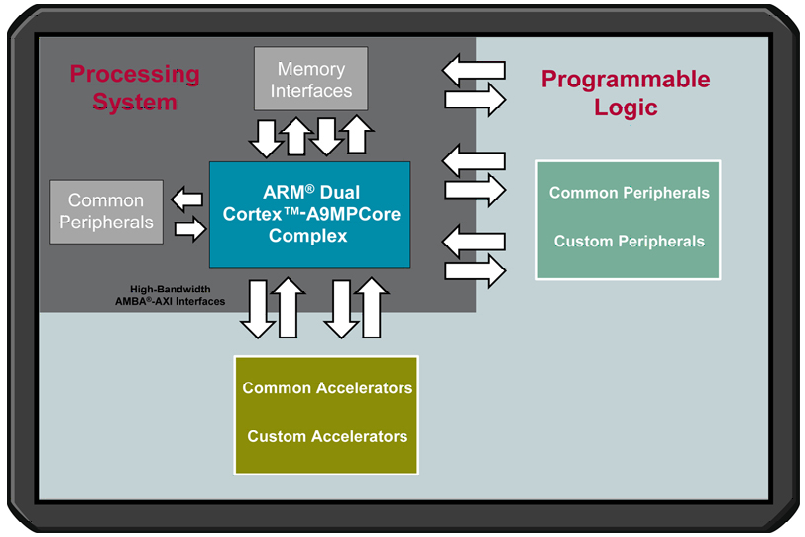
PS: 处理系统(Processing System),与FPGA无关的ARM的SOC的部分。
PL: 可编程逻辑 (Progarmmable Logic),FPGA部分。
APU: 应用处理器单元(Application Processor Unit)。位于PS里面的中心位置。
SCU: Snoop Control Unit,用来保持双核之间的数据Cache的一致性。也就是说,第一个A9 处理器写存储时,只是写在了缓存里,没有进主存,如果第二个A9读操作,涉及到第一个写脏了的数据段,SCU要保证第二个A9的缓存里是最新的数据。如果第二个A9写同样数据段的数据,需要在第一个中体现出写的内容。SCU的存在,才使得两个核成互相联系的 “双核”,才能成为MPsoc。
1、正确规划单板上 FPGA 的定向并将信号分配给特定的引脚,这样可以显著改进系统整体性能、功耗和设计周期。可视化 FPGA 器件与印刷电路板 (PCB) 之间的物理和逻辑互动方式,使您可以优化通过器件的数据流。未正确规划 I/O 配置则可能导致系统性能下降和设计收敛时间延长。单板上 FPGA 器件的布局与其它组件的互动会对 I/O 规划产生巨大影响。
2、首先应确定 FPGA 器件在 PCB 上的定向。还要考虑固定 PCB 组件的位置,以及内部 FPGA 资源。例如,使 FPGA 封装的 GT 接口尽量靠近在 PCB 上与其连接的组件,这样可以缩短 PCB 走线长度,同时减少 PCB 过孔数量。
3、赛灵思建议您设计时首先选择时钟资源,然后再选择管脚。您的时钟选择不仅可以确定特定的管脚,而且还可以支配逻辑布局。正确的时钟选择可以产生非常好的效果。
4、赛灵思 7 系列器件包含 32 个全局时钟缓冲器 (BUFG)。其中 16 个全局时钟缓冲器位于 FPGA 器件水平方向中心的上半部分,而另外 16 个则位于水平方向中心的下半部分。芯片上半部的 PLL 和 MMCM只能连接到水平方向中心以上的 16 个 BUFG 上。而芯片下半部的PLL 和 MMCM 只能连接到水平方向中心以下的 16 个 BUFG 上。选择 PLL 或 MMCM 时,请尽量使用 PLL,因为其具有更严格的抖动控制。在如下情况下也可以使用 MMCM :(1) PLL 已用尽 ; (2)MMCM 可提供所需的高级功能,但 PLL 则不能。
BUFG 组件可以满足设计的大多数时钟要求,但对以下要求不高 :
• 时钟数量
• 设计性能
BUFG 组件易于通过综合调用,并且限制较少,支持大多数普通时钟。
5、使用存储器接口生成器 (MIG) 生成管脚。
千兆位收发器 (GT) 具有特定的管脚要求。假如 GT 采用相同或邻近的 quads,则您可以在多个 GT之间共享参考时钟。赛灵思建议您使用 GT 向导生成内核。有关管脚建议,敬请参阅产品指南。
HP(高性能)和 HR(大范围)Bank在收发信号的速度上存在差异。根据所需的 I/O 速度,在 HP或 HR Bank 间做出选择。
6、从加电到断电,FPGA 器件要经过多个电源阶段,并伴有不同的功率需求 :
• 加电功率
加电功率是 FPGA 器件首次加电时发生的瞬时峰值电流。电压不同时,该电流强度也会发生变化且电流强度取决于 FPGA 器件的结构、电源上升到额定电压的能力,以及器件的工作条件(比如温度以及不同电源之间的排序)。在新型 FPGA 器件架构中,不用担心峰值电流的问题,因为它遵循了适用的上电顺序指南。
• 配置功率
配置功率是指在器件配置期间所需的功率。配置功率通常低于有效功率,因此,除非您的使用过程功耗极低,否则该瞬态不会影响供电需求
• 待机功率
待机功率(又称“设计静态功率”)是器件按设计配置后未对其施加任何外部活动或者未产生任何内部活动时提供的功率。待机功率是设计运行时电源应提供的最小连续功率。
• 有功功率
有功功率(又称“设计动态功率”)是器件运行应用程序时所需功率。有功功率包括待机功率(全部静态功率)以及因设计活动(设计动态功率)产生的功率。有功功率是瞬时发生的,且根据输入数据模式以及设计内部活动的不同每个时钟周期变化一次。
7、配置指的是将特定应用数据加载到 FPGA 器件的内部存储器的过程。
赛灵思 FPGA 配置数据储存在 CMOS 配置锁存(CCL)中,因此配置数据很不稳定,且在每次FPGA 器件断电后都必须重新加载。赛灵思 FPGA 器件可通过来自外部非易失性存储器件的配置引脚自行加载配置数据。而且还可以用外部智能源配置器件。赛灵思 FPGA 配置模式接口涵盖从带有2 引脚的基础串行模式接口到带有50 引脚的高性能主 BPI(同步)模式接口。
8、DMA moves data from a source to a destination location. Memory is often used asdata buffers to match the differences in rate of data source, processing, or data sink, therefore ensuring that the processing stage can achieve maximum throughput.
Off-chip data buffer location can be implemented using off-chip memory attached to customizableMIO orEMIO pins. The memory characteristics affect the performance of moving large buffers, such as file systems onSD cardsor network-attached storage over the GigE controller.
For on-chip buffering, the OCM(片上存储), L2 cache, and DDR controller are the three main sources of sharable buffer space within the PS. The L2 cache and DDR controller provide excellent buffer-access latency for sharing data between the processor and ACP(加速器链接接口) port. Only the ACP can access the L2 cache from PL.
For high-bandwidth accesses to DDR, the HP ports are better suited than ACP. The OCM can be used by software applications as a 256 KB scratchpad accessible by all masters in the PL. A benefit to using OCM is its excellent random-access latency, whereas the L2 cache and DDR memory benefit from memory-access locality.
9、System Monitoring
A rich tool ecosystem exists for monitoring the ARM processors. In a Zynq device, full system-level performance monitoring also uses blocks available in the PS and PL. These are:SCU Global Timer (PS). ARM Performance Monitoring Units (PS). L2 Cache Event Counters (PS). GigE Controller (PS). AXI Performance Monitor (PL). AXI Timer (PL). AXI Traffic Generator (PL).
</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 4893
4893











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









