






探索未来控制:基于模型预测控制的强化学习库 mpcrl
在机器学习领域,融合了经典控制理论与现代深度学习思想的技术不断推陈出新。今天,我们向您隆重介绍一个独特的开源项目——mpcrl,它是一个用于训练基于模型预测控制(Model Predictive Control, MPC)的强化学习(Reinforcement Learning, RL)代理的库。这个框架将两种强大的控制技术结合在一起,为解决复杂环境下的决策问题提供了新的途径。
项目简介
mpcrl 是由 Filippo Airaldi 制作的一个 Python 库,旨在实现模型预测控制与强化学习的整合,以创建数据驱动的智能控制器。它的核心理念是利用预测模型来预测环境的未来行为,并据此计算最优行动。同时,通过强化学习算法调整MPC参数,优化控制器性能,最终达到或接近最优策略。
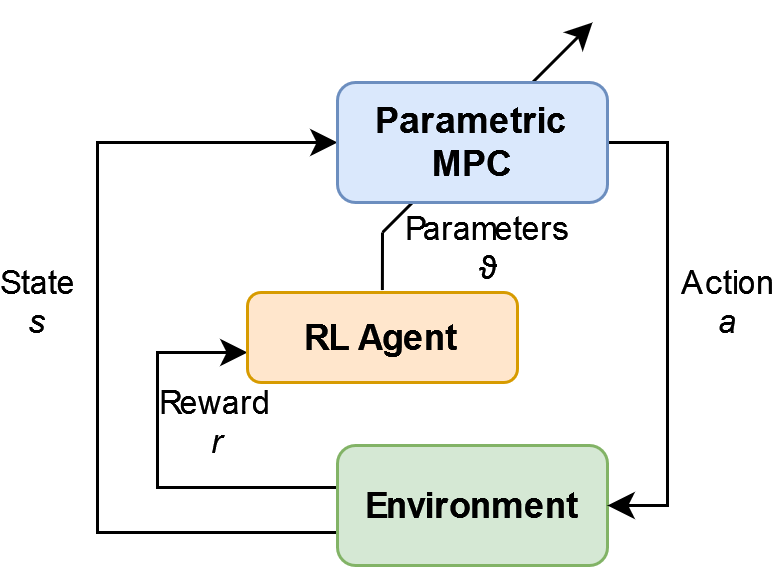
如图所示,MPC 控制器不仅提供当前状态下的行动建议,而且作为状态和动作价值函数的近似器。伴随着强化学习过程,控制器的参数被逐渐调整,进一步提升其效能。
技术分析
该项目依赖于多个强大的库,包括 csnlp、SciPy、Gymnasium、Numba 和 typing_extensions,并支持 Q-learning 和 Deterministic Policy Gradient (DPG) 等算法。通过安装 pip install mpcrl 即可轻松部署到您的环境中。
应用场景
mpcrl 的应用场景广泛,包括但不限于自动控制、机器人技术、能源系统、工业生产流程优化等。其提供的示例应用展示了如何在一个简单的线性时不变系统上运用该框架。
项目特点
- 集成性强:
mpcrl结合了经典的控制理论和现代的强化学习方法,创造了一种全新的控制策略。 - 易于使用:提供了清晰的 API 设计和详细的文档,开发者可以快速上手。
- 灵活性高:支持多种强化学习算法,能够适应各种复杂的动态环境。
- 高效优化:MPC 模型与 RL 算法相结合,能快速收敛至近优解。
- 可扩展性:设计开放源代码,鼓励社区贡献,持续进化。
资源与贡献
该项目遵循 MIT 许可证,欢迎开发者们参与贡献、改进和分享经验。作者 Filippo Airaldi 是 Delft 大学的一名博士候选人,他的研究工作使得这一创新库成为可能。
探索 mpcrl,开启您的强化学习与模型预测控制之旅,让智能控制更加精准、高效。立即安装,并查看项目中的例子,开始您的创新实践吧!
pip install mpcrl
或直接克隆仓库:
git clone https://github.com/FilippoAiraldi/mpc-reinforcement-learning.git
让我们一起见证智能控制的新纪元!


















 1436
1436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











