







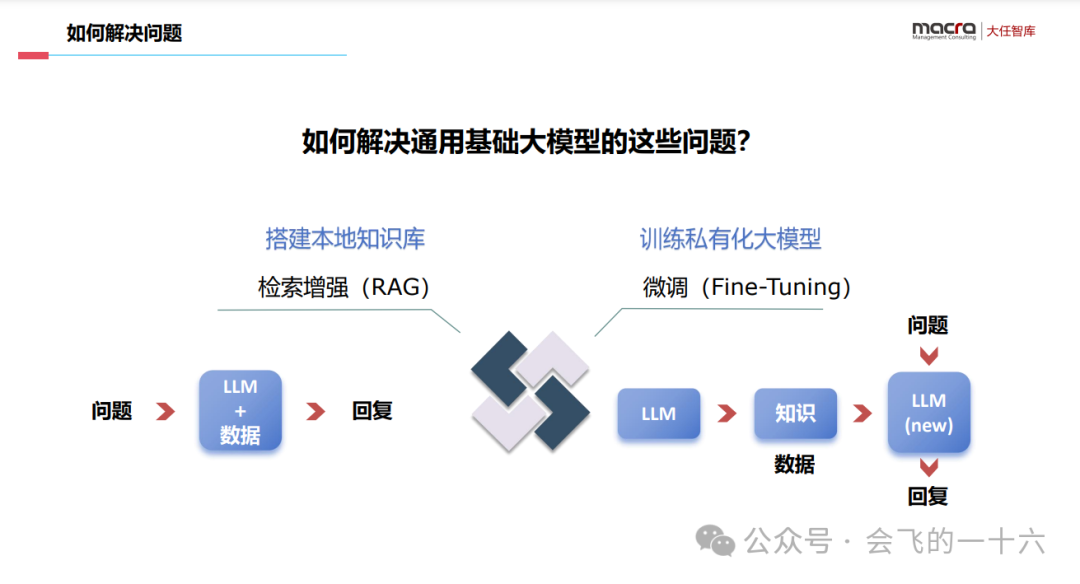
问题1:在企业生产环境为什么不直接使用通用基础大模型?
不专业:模型自身的知识完全源于它的训练数据(网络公开数据),实时性的、非公开的或离线的数据是无法获取到的
乱回答:AI模型的底层原理基于数学概率,当自身不具备某一方面的知识或不擅长的场景时,会一本正经地胡说八道
不专业:需要将企业自身的私域数据上传第三方平台进行训练,会有数据泄露的风险
问题2:什么是RAG?
RAG 检索增强生成(Retrieval Augmented Generation),融合了检索与生成两类模型的优势,最初源于2020年Meta(Facebook)的一篇论文——《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》。解决一个问题:如何让大语言模型使用外部数据进行生成
RAG是一种将大规模语言模型(LLM)与外部知识源的检索相结合,以改进问答能力的工程框架。
场景1:
大型语言模型(LLM)的训练依赖于网络上海量公开的静态数据,而某些特定领域(如企业内部资料、专有技术文档等)的数据通常不会作为公开的训练数据,导致模型在面对这些领域的查询时,可能因缺乏足够的信息而生成不准确甚至虚构的回复。
解决方案:
为了解决这一问题,RAG技术通过引入向量数据库(Vector Database)作为外部知识源,将模型缺失的知识以结构化的形式提供。
场景2:
随着 LLM 规模扩大,训练成本与周期相应增加。因此,包含最新信息的数据难以融入模型训练过程,无法及时反映最新的信息或动态变化。导致 LLM 在应对诸如“请推荐当前热门影片”等时间敏感性问题。
解决方案:提供联网搜索功能。
举例:
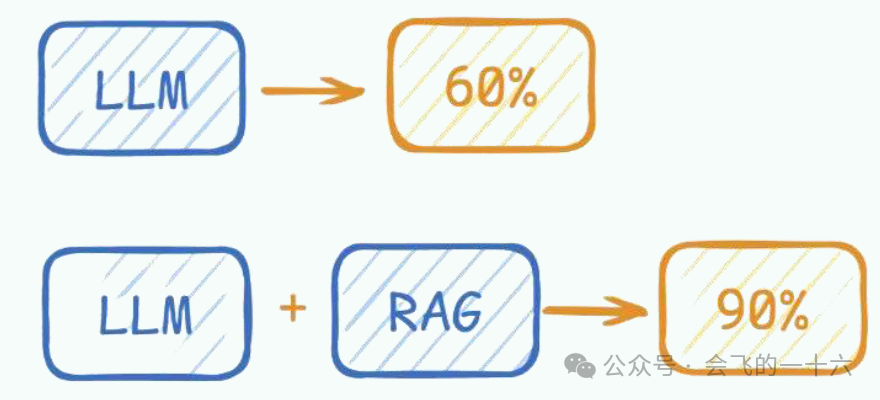
LLM在考试的时候面对陌生的领域,答复能力有限,然后就准备放飞自我了,而此时RAG给了一些提示和思路,让LLM懂了开始往这个提示的方向做,最终考试的正确率从60%到了90%!
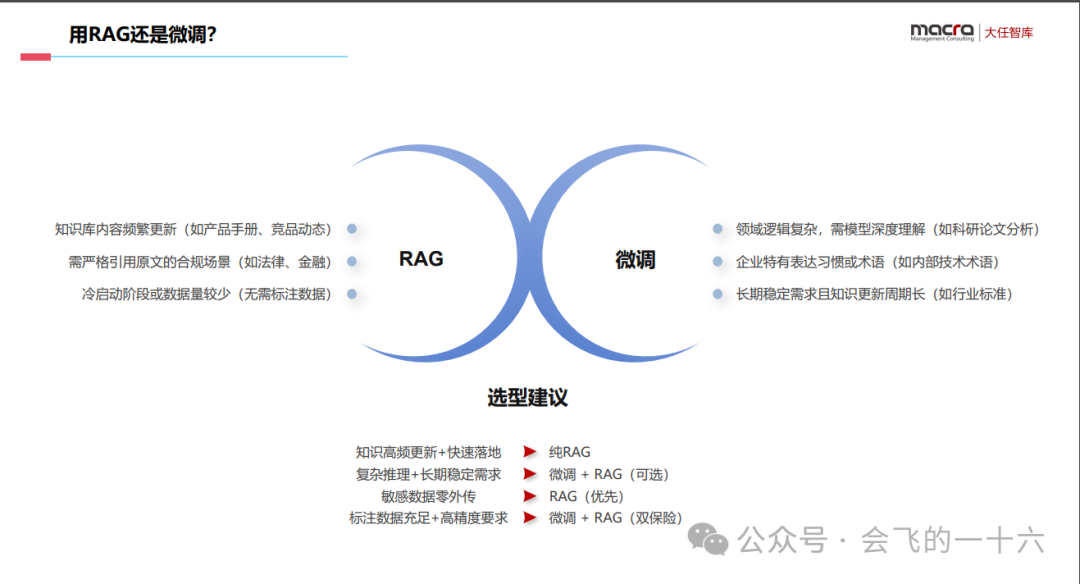
问题3:哪些人需要搭建个人知识库?
小型企业主或创业者:查阅和分享文件、文档、客户反馈、市场分析,大大提升你的工作效率。
职场打工人或自由职业者:无论是写作、设计、开发,还是视频制作,知识库都可以管理大量的素材、创意和客户需求,通过知识库,你可以轻松存储和搜索这些资料,并通过大模型二次创作
教育工作者或学生:利用知识库管理教学资源、课程安排、教材资料等,学生则可以将课堂笔记、参考书目和作业整理在一起,随时复习和备考。
生活中的普通人:无论是旅行计划、兴趣爱好,还是学习笔记,全部都可以集中在知识库管理。






往期精彩
从O(n²)到O(n):基于累计求和模型的线性递归模式优化与多场景实战
华中科技大学-从DeepSeek到Manus AI如何重塑企业价值【文末附下载链接】


















 2506
2506

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









