







setup与hold timing互卡(conflict)现象的成因主要有哪些?如何解决?
成因上来说,setup&hold互卡主要有几种因素的影响:
a) 不同PVT条件下的cell delay variation较大
b) 某些cell的library setup time或library hold time特别大
c) setup与hold的uncertainty或者derate约束较为严格或悲观
d) launch, capture的clock common path很短,OCV因素导致setup和hold都很难收敛
有些path是某一种原因导致的,另外一些path可能是几种因素叠加而产生的互卡。
从path的类型上来说,主要有三种情况:
-
同一endpoint的setup&hold互卡,但startpoint不同
-
相同startpoint与endpoint的setup&hold互卡,但中间经过的data路径不同
-
相同startpoint与endpoint的setup&hold互卡,且经过的data路径完全相同
1, 2两种情况相对简单,只要仔细分析大概率可以找到有margin的点去修hold或者setup,最麻烦的是3)这种情况。在了解上面几种因素的基础上,我们可以看一条具体的path来分析这个问题。
例:假设下面的path在worst PVT条件下的setup slack如下所示:
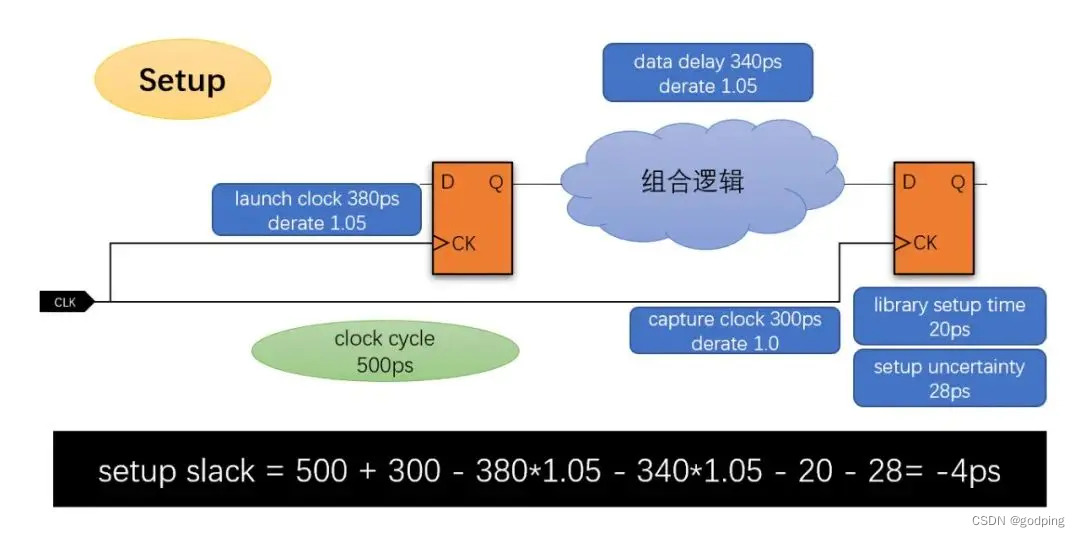
而对应的best PVT条件下的hold slack如下:
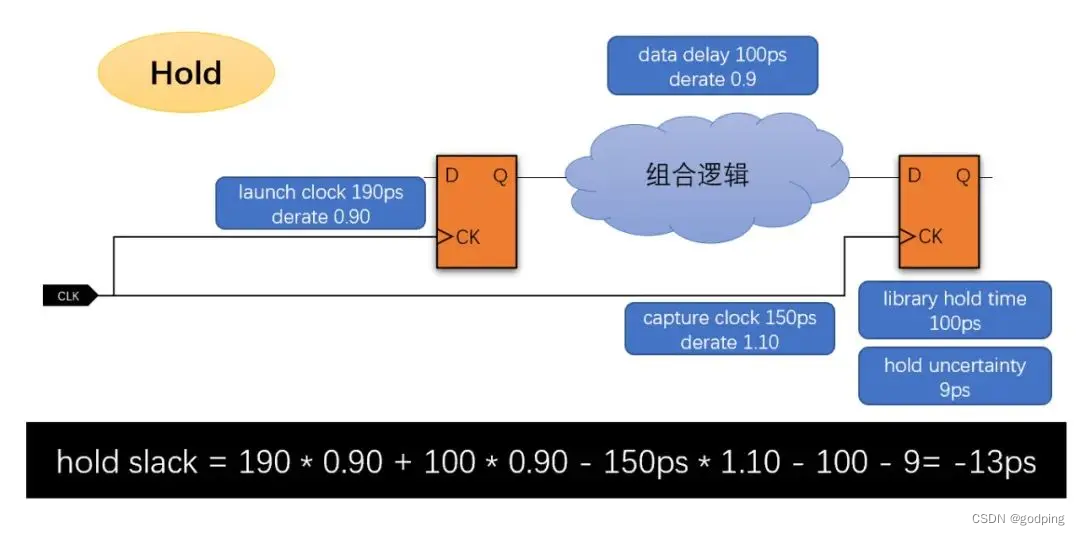
可以看到setup和hold的slack都是负的。仔细分析delay值可以发现,导致这种情况发生的原因是多样化的:
-
不同PVT条件下clock line的delay大概呈2倍比例,而data line的delay比例高达3.4
-
clock line完全没有common path,计算slack的时候没有任何CPPR的补偿
-
library hold time数值过大
-
hold corner的derate比setup更严格(悲观)
明白了上述原因,再想解决办法就相对简单了。library hold time本身如果lib没有问题,后端很难去改善,如果是sram的话设计早期还可以考虑换类型,但是到ECO基本就没有办法了;hold corner的derate属于signoff约束,一般也不能轻易改动,否则很难保证STA的准确性;因此我们能做的就是在原因1)与原因2)上想办法:
**对于1)**来说,就是很多人常说的某些cell在不同corner下的variation较大,我们可以去一一对比找出该cell的类型,将其替换成variation更小的cell;
**对于2)**来说,我们可以想办法增加两条timing path的common clock path,这样CPPR就可以扣掉部分悲观量,从而缓解setup与hold的slack。一般可能需要多管齐下才能很好地解决这种问题。非常建议大家对照上述公式计算一下考虑CPPR的情况下slack会有怎样的改变。
useful skew解setup violation的具体做法有哪些?分别有什么影响?
我们考虑下面一组timing path:
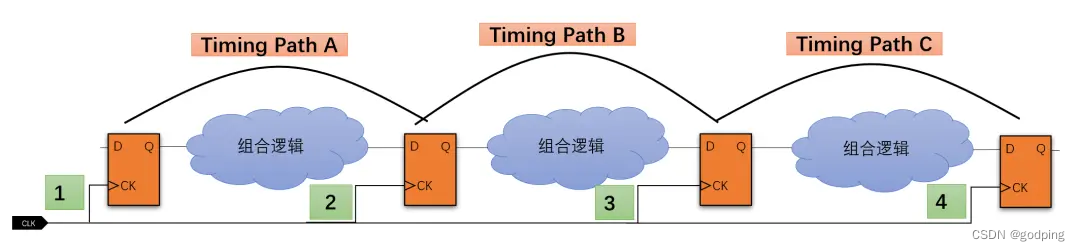
上图中有三条timing path: A, B和C,有4条clock路径到达各个DFF分别为1, 2,3和4。如果现在timing path B的endpoint上有setup violation,我们可以怎样调整clock可以修掉它呢?根据setup的定义可以知道,做短clock路径2和做长clock路径3都可以修掉B处的setup(不考虑实际情况是否允许做短和做长)。那么这两种方案分别有哪些影响呢?
方案一:做短clock路径2,也就是path B的launch clock。
其影响在于path B本身的hold会变差,同时path A的setup也会变差,因此需要分别检查二者是否有足够的margin支持将clock路径2做短。
方案二:做长clock路径3,也就是path B的capture clock。
其影响在于path B本身的hold会变差,同时path C的setup也会变差。因此需要分别检查二者是否有足够的margin支持将clock路径3做长。
其实这个问题的本质并不复杂,大家需要记住和理解的是:对同一条path来说,setup变好hold就要变差,反之亦然。同时capture变长对setup有利对hold有害,反之launch长对hold有利对setup有害。
做长common clock path 的方法
方法一:bounds法
将其他module(dpu模块)有timing path的寄存器摆放至Common clock gating那个位置来实现。粗暴的做法是给module做一个bounds或region来实现。根据实际情况需求,也可以再加一颗guide buffer避免工具出错。
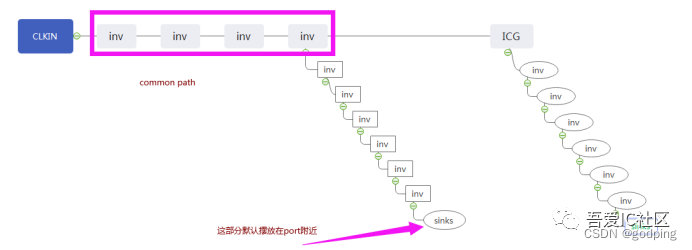
方法二:分步做tree思想
这个方法的提出主要目的是让大家体验下分段长tree的基本思想。在CLKIN port处加一颗guide buffer,然后在这颗buffer输出定义一个时钟。这样整条CLKIN的tree就被分成两部分:第一部分是从CLKIN port到guide buffer,第二部分是从guide buffer到所有的sink。
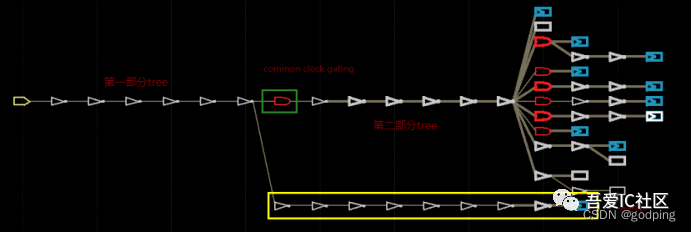
方法三(分步思想二):
在common clock gating的输出端定义时钟,并根据ICG后面的实际tree长度来调整分支N中寄存器的floating pin值。
采用这些方法后我们可以在ICC2中看到如下的clock tree。确实common clock path的级数变多了,符合我们的预期。
















 1255
1255











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









