






 语音模块TX引脚接串口RX,语音模块IO1旁边引脚接串口TX
语音模块TX引脚接串口RX,语音模块IO1旁边引脚接串口TX
学习过程记录:
步骤:
1.天问先初始化语音模块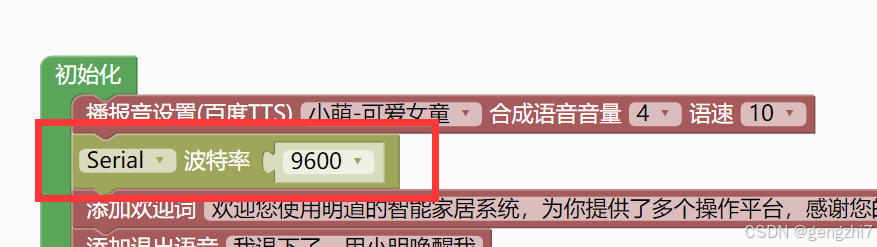
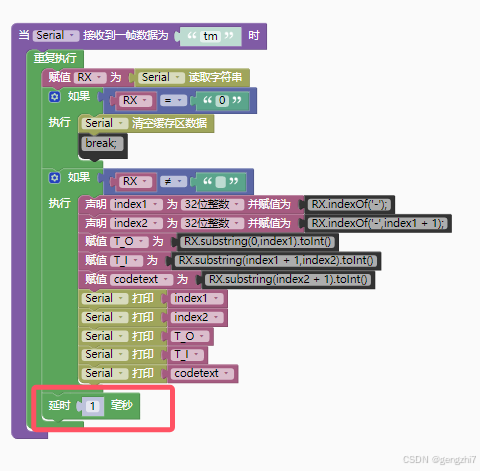
2.ASR_CODE应该是循环函数,在这里判断如果有语音ID语音模块的TX引脚就输出16进制68 01.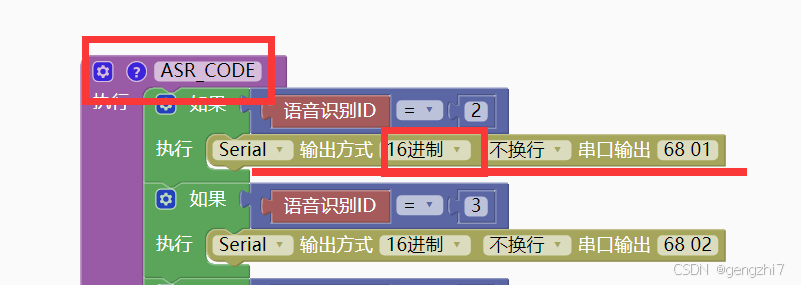
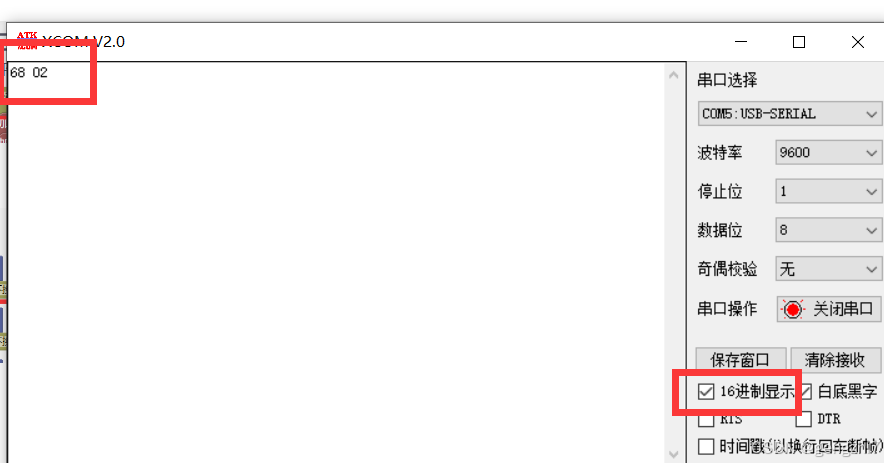
3.当语音模块的RX(IO1旁边)引脚接收到16进制01时就立马唤醒播报语音

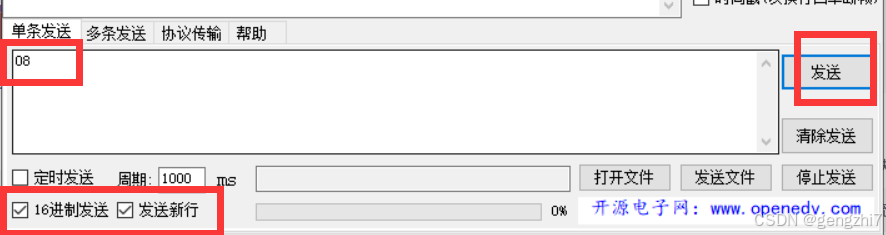
4.通过测试,最终要实现单片机串口输出数到语音模块的时候不能加换行符号!!!!!
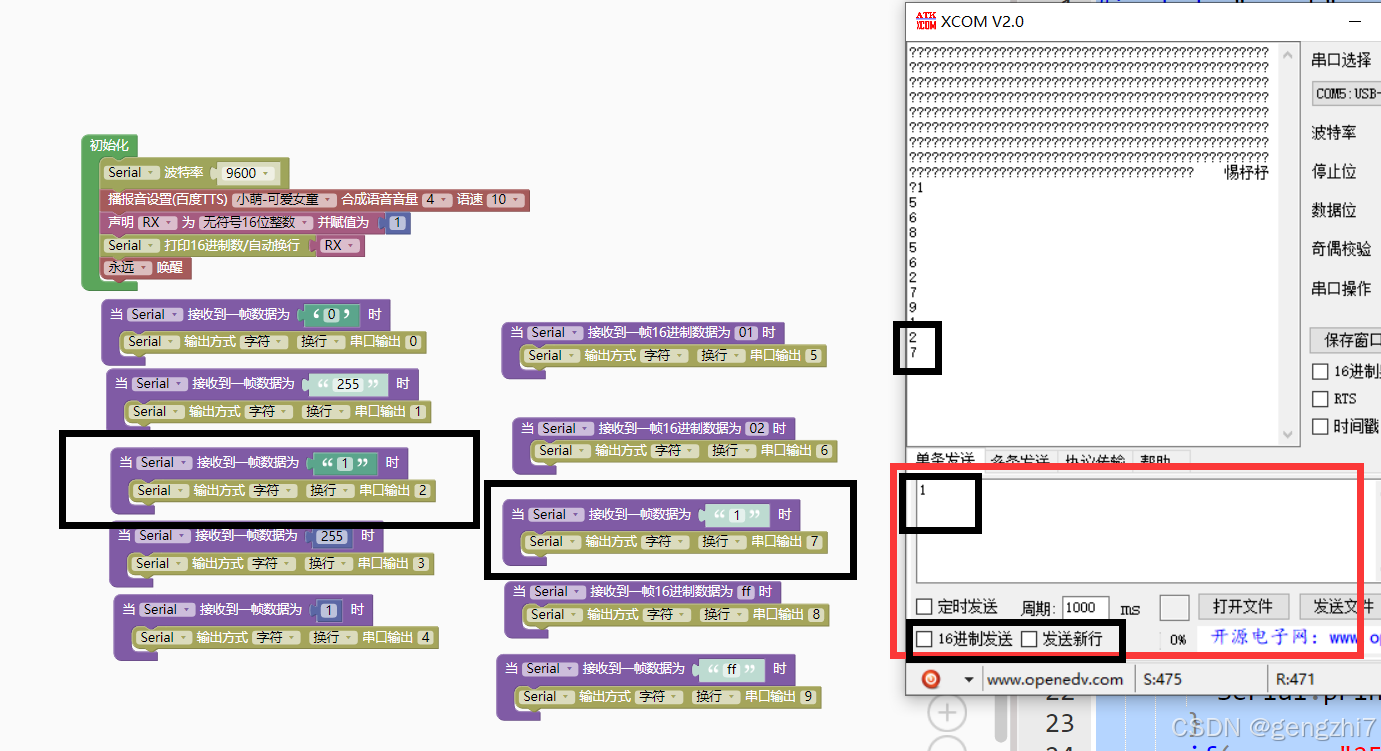
5.最终单片机测试:
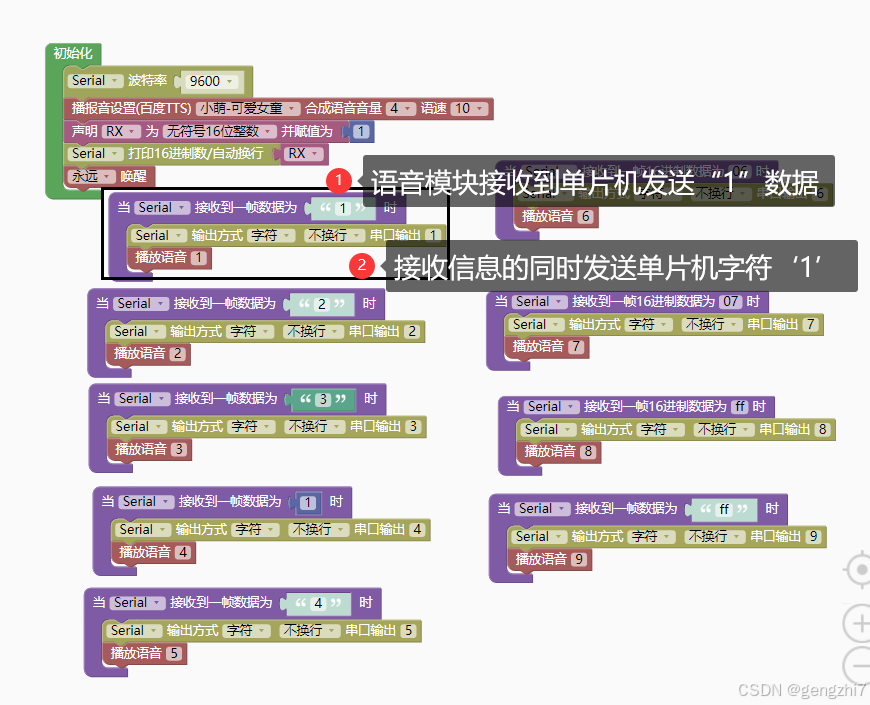
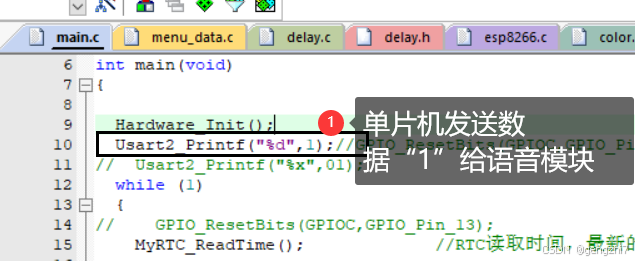
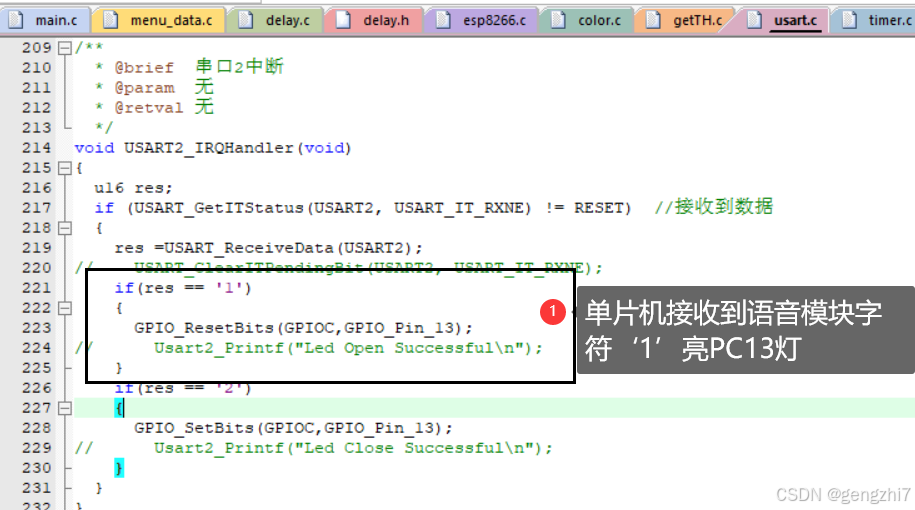
测试结果完成!!!!!正确
在测试语言模块的时候,接收数据执行重复命令需要加入延时1ms,否者语音模块会卡死机(12-17号总结)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









