






- 作者:叶琪,张一乾,阮彤,杜渂
- 发表时间:2022-08-22
- 发表地点:《计算机工程》(中文核心期刊)
知识图谱通常由三元组(头实体,关系,尾实体)组成,所以对知识图谱的质量评估可以表示为对三元组的质量评估,同时为了量化知识图谱中三元组的质量,引入了置信度的概念,置信度是一个综合维度,描述了图谱中知识的可信度,该指标被广泛用于知识图谱的质量评估。基于知识表示学习的置信度评估方法已成为知识图谱质量评估的重要方法。方法的基本思想是:将三元组中实体之间的关系视为头尾实体的平移翻译,通过计算头尾实体间的距离来衡量三元组的合理性。
目前许多文献采用置信度评估策略来进行图谱质量的评估。
- 张晓明,孙维雅,王会勇.基于知识表示学习的知识可信度评估[J].计算机工程,2021,47(7):44-54.
- 叶琪,张一乾,阮彤,杜渂.基于语义和结构置信度的图谱质量校验方法[J/OL].计算机工程2022
- V. Jayawardene, S. Sadiq, M. Indulska. An analysis of data quality dimensions, ITEE Tech. Rep. 2015:1-32.
- Wang X, Chen L, Ban T, et al. Knowledge graph quality control: A survey[J]. Fundamental Research, 2021, 1(5): 607-626.
Introcuce

本文提出一种基于语义与结构双重置信度的三元组质量评估模型,(此模型由两个评估器组成,左边为三元组语义评估器,右边为三元组结构上的置信度评估器,左边把三元组通过关系-关系子句映射字典(三种映射规则)转换成句子,然后由bert-wwm模型度量三元组语义真实性,右边则通过表示学习模型首先获得实体和关系的向量表示,并且引入文献《Triple Trustworthiness Measurement for Knowledge Graph》的路径预测算法ResourceRank选取路径信息为特征,从知识表示、路径特征这两个层面上度量三元组的结构真实性,最后输出一个整体置信度来评估三元组质量)
知识图谱三元组置信度度量模型整体框架图
三元组记为(h,r,t),整体置信度的设计如下:
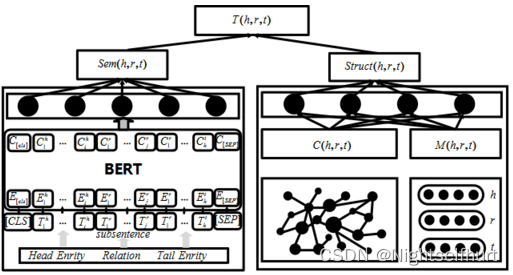
λ为权重值,λ∈[0,1],Sem(h,r,t)为语义真实性,Struct(h,r,t)为结构置信度。
三元组语义真实性
利用三元组中实体和关系的语义信息,将头实体、尾实体名称和关系组合在一起形成一个句子,将评估三元组语义真实性转换为一个自然语言处理的分类问题。
首先,针对不同情况的三元组按如下方式转换为语句
[1]关系为缩略语,或实体间关系与头尾实体语言不同的情况,引入关系类型对应的描述子句字典,用于统一语言并将关系映射成相应的子句结构。
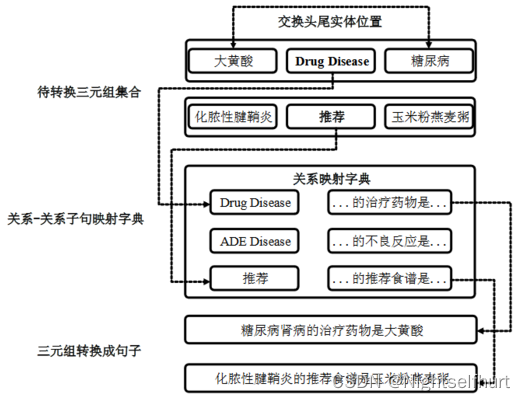
[2]**关系为有意义的单词或词组且实体关系语言相同的情况。三元组中实体和关系为英文单词且存在特殊字符,需先对单词进行预处理。**如将单词之间“”改为空格符,然后将关系名称头尾补充“is a”、“的......是”、“is the xxx of”,构造为有语义的句子。例如:['Sony_Ericsson_Xperia_arc_S', 'predecessor', 'Sony Ericsson_Xperia_Arc']转换为句子:“Sony Ericsson Xperia arc S is the predecessor of Sony Ericsson Xperia Arc”。
[3]**三元组中关系与头尾实体之间语言不同且关系语义表述不够明确的情况。**例如:['安达·山度士','leader4Name','法林明高竞赛会'],无法准确推断“leader4Name”的具体含义,且该关系不是一个正确的单词形式,因此在实体与关系之间加上空格符转换为“安达·山度士 leader4Name 法林明高竞赛”。
(BERT-WWM 模型)
BERT-WWM 模型是一个基于全词遮罩技术的预训练模型,更改双向编码器表示变换模型预训练阶段的训练样本生成策略,缓解了原模型中全字掩码的问题。一个完整的单词被 WordPiece 分词方式切分的多个子词时, 如果任意子词被屏蔽,强制屏蔽该单词的所有子词。 该模型在句子级的各类自然语言处理任务中取得很好的效果。本文以 BERT-WWM 模型来构建三元组语义真实性,用于评估三元组语义的置信度。
这部分(三元组语义真实性)的具体实现过程:
将模型最后一层隐藏层状态向量 C 作为序列表示用于计算三元组语义真实性,微调分类阶段添加一个 Dense 层,设置权重矩阵和偏移值,利用 sigmoid 函数得到元组的语义真实性。
首先,模型将三元组转换后的句子序列输入到一个嵌入层,然后通过一个Transformer得到一个上下文相关的表示。
然后,模型使用序列中最后一层隐藏层的状态向量C来表示这个序列,将这个向量C作为输入,加上一个Dense层,用sigmoid函数将输出压缩到0到1之间。这个输出就是输入的三元组的语义真实性得分,即表示这个三元组是否为真实存在的事实。sigmoid函数的值越接近1,表示这个三元组的语义真实性越高;sigmoid函数的值越接近0,表示这个三元组的语义真实性越低。
三元组图结构置信度
图结构置信度考虑了三元组的知识表示信息和实体关系间多层路径特征信息,融合待评估三元组所具有浅层结构和深层结构信息,体现了三元组在图谱结构中的真实可信度。三元组图结构置信度评估器由三元组可靠性和关系路径置信度两个评估模块组成。
三元组可靠性
首先利用知识表示学习(TransE)实现头尾实体和关系的分布式向量表示,然后计算三元组向量的距离,计算出三元组构成关系的概率,值越接近0,表示待评估三元组可信度越低,反之越接近1,则表示三元组可信度越高。
关系路径置信度(实体对之间可能存在关系吗?)
利用从头实体通过多条路径传递到尾实体的资源总量刻画两个实体之间的关联强度。
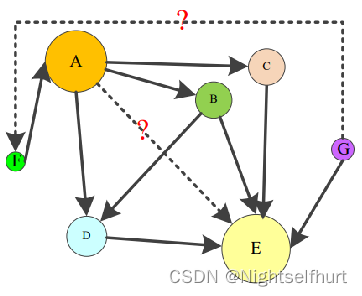
本文采用关系路径置信度算法ResourceRank。(算法将两个实体之间的路径看做一种流动的资源(参考pagerank算法,看做变种的pageRank算法),也就是两个实体之间的路径越多可以看做两个实体之间连接越紧密)
算法思想:如果实体对(h,t)之间的关联更强,那么会有非常多的资源从在图中从头部实体h通过所有关联路径传递到尾部实体t。 聚合到t的资源数量巧妙地表示了从h到t的关联强度。
这个算法是一种用于预测两个实体之间是否存在关系的方法。它基于一个以头实体为中心的有向图,通过计算实体间资源的流动量(即通过多条路径从头实体传递到尾实体的资源总量)来刻画实体之间的关联强度。在这个有向图中,尾实体所持有的资源量反映了它与头实体之间的关联强度,资源量越大则关联强度越大,存在关系的可能性也就越大。**通过迭代计算,可以得到每个实体的ResourceRank值,表示该实体在图中的重要性程度。最后,通过将实体间的关联强度转换为量化表示实体间存在关系的概率,来预测实体间是否存在关系。**整个算法包括构建有向图、计算ResourceRank值、计算ResourceRank概率和融合特征等步骤,最终通过多层感知器和分类器输出三元组的结构置信度。
**算法主要包括三个步骤: **
①构建以头部实体h为中心的有向图。
②迭代图中资源的流向直到收敛并计算出尾部实体t的资源保留值。
③综合其他特征并输出(h, ?,t)的可能性。
头节点h拥有的资源将通过所有相关路径流向整个有向图中的其他节点。本文参考PageRank算法,模拟了资源流到分布稳定的过程,将尾实体上资源的值表示为R(t|h):
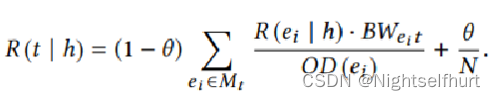
计算三元组的ResourceRank 概率C(h,r,t)
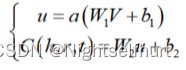
最后,将 M和 C融合构建特征向f(s),通过一个多层感知器和分类器,输出三元组的结构置信度。
实验部分
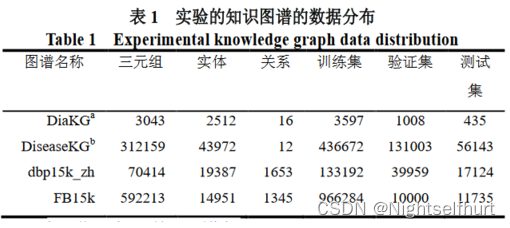
实验使用的四个开源真实的知识图谱。4个数据集按 7:2:1 比例进行划分训练集、验证集和测试集
实验对比了基于知识表示学习 TransE 方法结合随机森林(Random Forest Classifier,RFC)、K 近邻(K NearestNeighbor Classifier, KNC)、极端梯度提升(eXtreme Gradient Boosting, XGB)等传统机器学习分类模型以及知识图谱三元组置信度评估 KGTtm 模型、BERT 模型。
总结:
研究背景和目的
这篇文献的研究背景是图谱质量评估,主要关注三元组的质量评估。文章的目的是提出一种基于语义和结构置信度的图谱质量校验方法,以解决现有方法无法准确判断三元组质量的问题。
方法和实验过程
文章提出了一种基于语义和结构置信度的图谱质量校验方法,该方法结合了语义和结构两个方面,从而提高了三元组质量的评估准确性。作者在实验中使用了多个数据集,包括YAGO和DBpedia等公共数据集,以验证所提出的方法的有效性。
实验结果
实验结果表明,所提出的方法相比于其他方法具有更高的准确性和鲁棒性,可以更好地检测出低质量的三元组,并能够提高整个图谱的质量。
结论
本文提出一种基于语义和结构双重置信度的三元组质量评估模型,此模型从语义真实性、结构真实性两个层面进行三元组质量评估,其中,语义真实性评估器将三元组质量校验问题转换为文本分类问题,对三元组中的关系部分进行子句扩展并构建句子序列,使其贴近自然语言表达;结构置信度评估器充分挖掘实体和关系的特征结构信息,评估三元组在结构上的合理性,并且通过实验(在多个开放数据集上验证模型的有效性)验证了该方法的有效性。该方法可以提高三元组质量的评估准确性,从而进一步提高整个图谱的质量,同时,该方法还具有较高的鲁棒性和实用性。总之这篇文献提出了一种新的图谱质量校验方法,该方法结合了语义和结构置信度两个方面,提高了三元组质量评估的准确性,并在实验中取得了良好的效果。

















 392
392

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









