








编者按:
本文不局限于对某一篇论文的详细介绍,而是通过对一系列工作的概括性叙述,帮助读者从直观上对知识图谱质量控制领域有一个大体的了解。
一、知识图谱质量控制概述
数据的数量和质量宛如一枚硬币的两面,对数据管理同样重要。随着以4v 为特征的大数据时代的到来,人们往往更关注数据的数量,集中于对高速变化的海量异构数据的处理和分析,例如从异构数据中构建知识库、提升从海量数据中进行查询优化的算法等,对数据质量的研究并没有那么重视。但是,现实世界的数据往往是脏的,会存在不一致、不准确、不完整、过时、重复等问题。如果不能对数据质量进行合理的评估,并针对发现的问题进行改进和修复,无论怎样优化数据处理和查询算法,都不能得到准确的答案和对获取的数据实现有效利用。数据质量研究在大数据时代相当重要。
传统关系数据常用的一种质量控制方法是函数依赖(对于关系模式R(U)的任意两个可能的关系r1、r2,若r1[x]=r2[x],则r1[y]=r2[y])及其变体,而知识图谱由于其无模式性,更难利用有效的规则进行质量控制。近年来知识图谱的构建技术方兴未艾,但其质量问题并没有得到很好的重视。

评估数据质量需要确定一组质量维度和相应的度量方式,但是对知识图谱的质量尚未形成一套统一的维度标准,并且针对不同的下游任务和不同的数据集往往会有不同的质量要求。对数据质量评估的一个宽泛定义是“fit for use”,即只要适用于具体任务即可;而从技术上理解,可以从“free of defects”的角度,即机器找不出错误。虽然不同的工作给出了不同的质量维度,但是除去用户交互和表征等外部维度,数据本身的质量维度大致可以归纳为准确性、一致性、完整性、时效性、重复性五类。并且可以明确的是,不同质量维度之间往往存在相关性,在实际使用时需要权衡。
下面两图给出了两套质量维度框架,更多内容可以参考[1][2]。
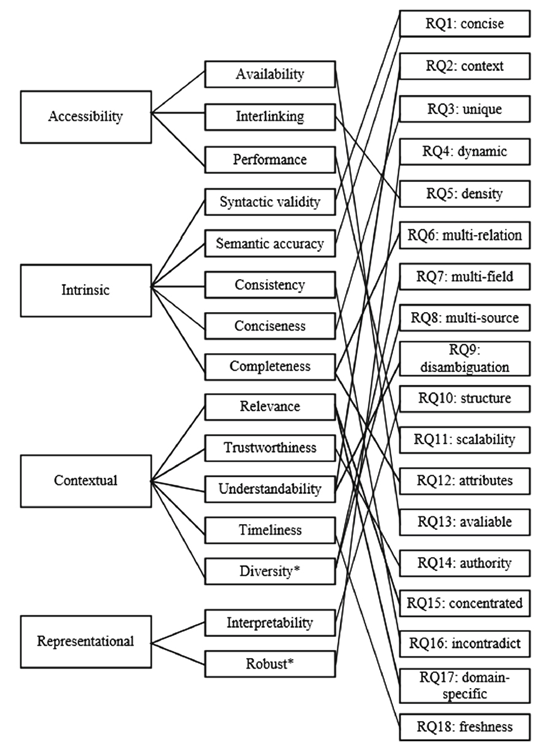
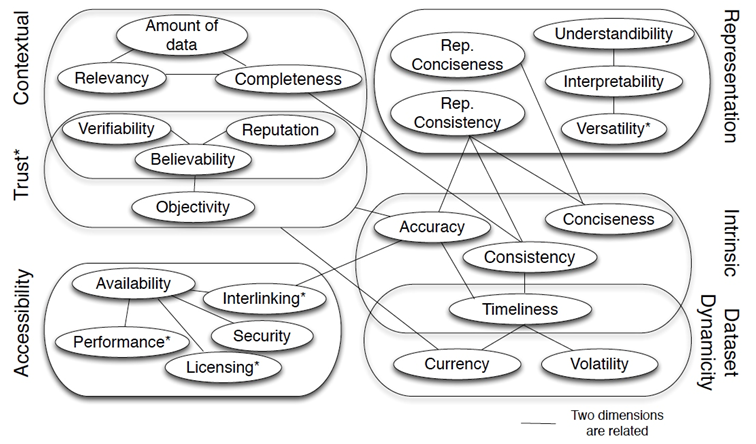
从整体上,知识图谱质量研究的主要工作包括质量评估、问题发现和质量提升三类,从方法上可以分为基于统计、人工和规则推理三种。下面主要对基于人工抽样进行质量评估和基于规则的质量控制框架展开叙述。

二、基于人工抽样的质量评估
这里介绍一篇2019年VLDB的工作[3],它对使用人工抽样进行知识图谱质量评估的研究很有代表性。
评估知识图谱的准确率,即正确的三元组所占的比例,最自然的方式是人工检测。但对于大规模知识图谱,人工检测所有条目并不现实,这就需要进行抽样,用样本的准确率均值来估计总体的准确率。但抽样数量过少,可能会使估计结果与真实值之间存在偏差,这就存在一个怎么抽样和抽样多少的问题,即怎么在尽可能降低人工标注成本的情况下获得具有统计意义的结果。
这篇文章提出了一个迭代的评估框架,每次抽取小批量样本进行人工评估,当误差率满足要求时迭代停止;提出了若干种抽样方法,以及增量评估的两种抽样方法;进行了详实的理论分析和大量的实验验证,是第一个在静态和动态图上进行高效质量评估并可得到无偏和有效置信度的质量估计的工作。
本文所要保证的统计意义,包括无偏性和置信区间两个。前者保证估计量的数值在真实值附近摆动,且无系统误差;后者衡量了在给定置信度的情况下,参数真实值落在测量结果周围的程度。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1167
1167

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









