







主要是解决DenseNet的检测速度慢效率低的问题。
本文被CVPR2019收录
论文地址:https://arxiv.org/abs/1904.09730
1. 摘要
DenseNet通过密集连接聚集不同的感受野来保存中间特征,因此在目标检测有着很好的性能。但是DenseNet的backbone速度较慢,主要是由于密集的连接导致输入通道增加进而导致大量的内存访问开销,从而导致计算缓慢,效率低。
本文为了解决这个问题,提出了一种OSA(One-Shot Aggregation)模型,OSA在继承DenseNet的多感受野表示多种特征的优点的情况下,同时解决了密集连接效率低的问题。本文的网络性能优于DenseNet,而且速度也比DenseNet快2倍。
此外,本文网络速度和效率也都优于ResNet,而且对于小目标检测的性能有了显著提高。
2. 相关工作
2.1 DenseNet与ResNet比较
ResNet和DenseNet的主要区别在于它们聚合特征的方式;ResNet通过求和从较浅的地方聚合特征,而DenseNet则通过concat来聚合特征。
早期的特征图所携带的信息会随着与其他特征图的累加而逐渐稀释。另一方面,通过concat,信息将持续存在。有文献证明具有多个感受野的抽象特征可以在不同尺度上捕捉视觉信息。由于相比于分类任务,检测任务要求模型在多样的尺度上识别一个目标,因此对于检测来说,保存来自不同层次的信息尤为重要,因为每一层都有不同的感受野。因此,与ResNet相比,DenseNet在保留和积累多个感受野的特征图方面具有更好的、多样的特征表示。
然而,作者在实验中也发现,与ResNet相比,使用DenseNet的检测器虽然具有较低的FLOPs和模型参数,但是会花费更多的能量和时间。这是因为除了FLOPs和模型大小之外,还有其他因素影响能量和时间消耗。
首先,访问中间特征映射的存储器所需的存储器访问成本(MAC)是消耗的关键因素。由于DenseNet中所有先前的特征映射都被密集连接用作后续层的输入,因此它导致内存访问成本随网络深度呈二次增长,进而导致计算开销和更多的能量消耗。
其次,在GPU并行计算方面,DenseNet存在计算瓶颈的限制。一般来说,当操作数张量较大时,GPU并行计算利用率最大。但是,由于输入通道线性增加,DenseNet需要采用1×1卷积瓶颈结构来降低输入维数和FLOPs,这使得操作数张量较小的层数增加。结果,GPU计算变得效率低下。
2.2 设计高效率网络的因素
在设计高效网络时,许多研究,如MobileNet v1、MobileNet v2、ShuffleNet v1、ShuffleNet v2和Pelee主要集中在通过使用深度卷积和1×1卷积瓶颈结构(一头大一头小,针对输入输出说的)来减少FLOPs和模型大小。
然而,减少FLOPs和模型大小并不总是保证减少GPU推理时间和实际能耗,FLOPs和模型大小只是衡量实用性的间接指标,基于这些指标的网络设计需要重新考虑。为了构建高效的网络体系结构,除了FLOPs和模型参数外,还需要考虑其他影响能量和时间消耗的因素,这一点非常重要。
2.2.1 内存访问成本
第一个因素是内存访问成本(MAC)。CNN的主要能耗来源是内存访问,而不是计算。具体地说,从DRAM(动态随机存取存储器)中存取数据进行操作所消耗的能量比计算本身要高出几个数量级。此外,内存访问的时间预算占时间消耗的很大比例,甚至可能成为GPU进程的瓶颈。这意味着即使在相同的计算量和参数下,如果内存访问总量随模型结构的变化而变化,其能耗也会有所不同。
导致模型大小和内存访问次数之间差异的一个原因是中间激活内存占用。内存占用被归因于过滤器参数和中间特征映射。如果中间特征映射很大,即使使用相同的模型参数,内存访问的成本也会增加。因此,MAC覆盖了卷积参数和中间特征映射大小的内存占用,是网络设计的一个重要因素。具体来说计算每个卷积层的MAC如下:
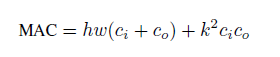
2.2.2 GPU计算效率
一般情况下,在一个设备中,每一个浮点运算都以相同的速度处理。但是,当网络部署在GPU上时,这是不合理的。这是因为GPU的并行处理机制,GPU能够及时地处理多个浮动进程。因此有效地充分的利用GPU的计算能力尤为重要。
随着计算数据张量的增大,GPU并行计算能力得到了更好的利用。而将一个大的卷积运算拆分成几个零碎的小运算则使得GPU计算效率低下,因为这样并行处理的计算量更少。在网络设计的背景下,这意味着如果行为函数相同,最好用较少的层组成网络。此外,采用额外的层会导致内核启动和同步,从而导致额外的时间开销。
因此,尽管深度卷积和1×1卷积瓶颈等技术可以减少运算次数,但由于采用了附加的1×1卷积,对GPU计算效率不利。一般来说,GPU的计算效率随模型结构的不同而不同。因此,为了验证网络结构的计算效率,作者引入了每秒浮点数(FLOP/s),它是通过将实际的GPU推断时间与总的浮点数相除来计算的。高FLOP/s意味着体系结构可以有效地利用GPU。
3. 本文方法
3.1 rethinking densenet
实际上,DenseNet通过密集连接来交换特征数量和特征质量。尽管DenseNet的表现证明了这种交换是有益的,但从能源和时间的角度来看,这种交换还有其他一些缺点。
- 首先,密集的连接会导致较高的内存访问成本。因为在固定的计算量或模型参数下,当输入和输出信道尺寸相同时,MAC可以最小化。密集连接增加了输入通道大小,而输出通道大小保持不变,因此,每个层的输入和输出通道大小都不平衡。因此,DenseNet在计算量或参数相同的模型中具有较高的mac值,并且消耗更多的能量和时间。
- 其次,密集连接引入瓶颈结构,影响了GPU并行计算的效率。当模型尺寸较大时,线性增加的输入尺寸是一个严重的问题,因为它使得整体计算相对于深度呈二次增长。为了抑制这种增长,DenseNet采用了增加1×1卷积层的瓶颈结构来保持3 × 3卷积层的输入大小不变。尽管这种方法可以减少FLOPs和参数,但同时它会损害GPU并行计算的效率。瓶颈结构将一个3 × 3卷积层分成两个较小的层,导致更多的顺序计算,从而降低了推理速度。
3.2 OSA模型

基于前面的讨论,本文提出一次性聚合(one-shot aggregation 即OSA)模块,该模块将其特征同时聚合到最后一层。如上图所示。每个卷积层包含双向连接,一个连接到下一层以产生具有更大感受野的特征,而另一个仅聚合到最终输出特征映射中一次。
与DenseNet的不同之处在于,每一层的输出并没有按路线(route)到所有后续的中间层,这使得中间层的输入大小是恒定的。这样就提高了GPU的计算效率。
另外一个不同之处在于没有了密集连接,因此MAC比DenseNet小得多。
此外,由于OSA模块聚集了浅层特征,它包含的层更少。因此,OSA模块被设计成只有几层,可以在GPU中高效计算。
3.3 网络结构

由于OSA模块具有多样的特征表示和高效性,所以VoVNet可以通过只叠加几个模块来构造,具有较高的精度和速度。基于图2显示的浅层深度更聚集,可以使用比DenseNet更大的信道、用更少的卷积配置OSA模块。有两种类型的VoVNet

分别为轻量级网络,例如VoVNet-27-slim,大型网络,例如VoVNet-39/57。VoVNet由一个包括3个卷积层和4个输出步长为32的OSA模块组成。OSA模块由5个卷积层组成,具有相同的输入/输出信道,用于最小化MAC。
当逐步执行时,特征图会被步长为2的3 × 3 max pooling下采样。VoVNet-39/57在第4和第5阶段有更多的OSA模块,在最后一个模块中进行下采样。
由于高层语义信息对目标检测任务的重要性更大,本文通过在不同阶段增加输出通道来增加高层特征相对于低层特征的比例。与DenseNet中只有少量新输出的限制相反,本文的策略允许VoVNet用更少的总层数来表达更好的特征表示。
4. 实验
- 应用在DSOD上的结果:


- 1×1 conv bottleneck虽然参数少但是耗时费力

- 应用在RefineDet上的结果


- 应用在两阶段上,且比ResNet效果好
















 3160
3160











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









