







转自:https://zhuanlan.zhihu.com/p/89665397
本文作者:kurffzhou,腾讯 TEG 安全工程师
最近,Nature发表了一篇关于深度学习系统被欺骗的新闻文章,该文指出了对抗样本存在的广泛性和深度学习的脆弱性,以及几种可能的解决方法。安全平台部基础研究组自2017年来在对抗样本的生成及防守方法进行了深入研究,在这里团队通过在攻击方面的经验,分享我们对于防守对抗样本的一些思考,欢迎共同讨论。
深度学习在现实生活中的应用越来越广,然而越来越多的例子表明,深度学习系统很容易受到对抗样本的欺骗。那么,AI到底是怎么“想”的?为什么这么容易被骗?
要回答这个问题,我们首先看图片来做个小实验——

- 图1左图:原始图片(图片来源:ImageNet数据集)
- 图1中图:局部块保持像素的布局不变,但是整体图像的全局布局改变
- 图1右图:局部块的像素的布局变化,但是整体图像的全局布局不变
对于这三幅图,神经网络会“认为”图1中图和图1右图哪张图片更与图1左图是一致的呢?
毫无疑问,对于人的直觉来说,相对图1中图而言,图1右图更与图1左图一致,因为人类普遍倾向于对整体图像的布局进行识别。
然而我们通过统计实验发现,利用神经网络进行预测,图1中图的预测结果更加倾向于与图1左图的预测结果保持一致。可见,人与机器对图片的识别结果存在较大差异。
为了深入解释这种差异,下文首先对深度学习常用的模型进行简单介绍,再对深度学习模型所学习得到的特征进行可视化来解释深度学习模型在图像方面的优势,并通过相关实验研究深度学习模型到底在“想”什么、学习了什么。
1、深度学习常用模型以及特征可视化
深度学习常用模型之一的Alexnet模型:Alexnet模型通过多层卷积以及max-pooling操作,最后通过全连层得到最后预测结果,通过计算损失L来刻画网络预测结果与我们人工标注类别的差异大小,然后通过计算损失对可学习参数的梯度,通过梯度下降的方式来更新网络的权重,直到损失L下降到网络预测的结果与我们人工标注差异很小时,即神经网络通过对输入图像的层层卷积、max-pooling、全连等操作获得了正确的结果。
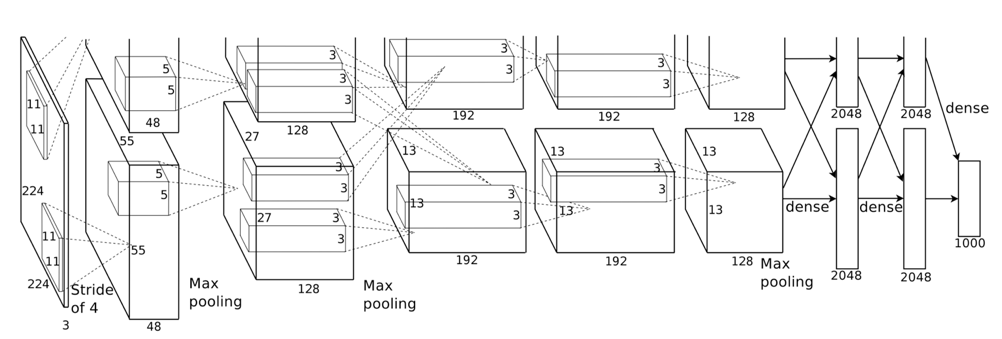
我们首先对多种不同类型的网络(AlexNet, ResNet等)的底层卷积核进行可视化,我们发现这些底层特征存在一定的共性:这些网络底层卷积核都在提取梯度、颜色等局部模式,对应图像中边和线等,如图3所示。

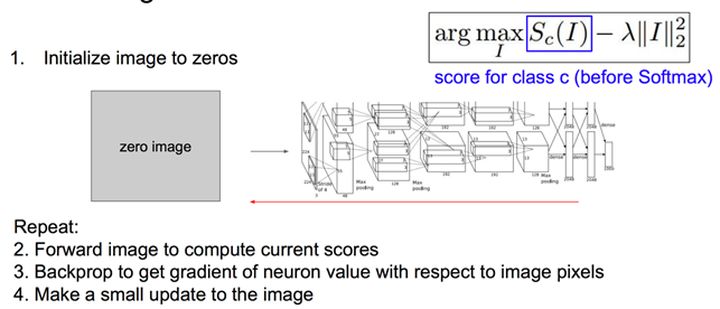
为了可视化高层特征,我们通过梯度上升优化目标函数的方式来直观认识高层特征所对应的直观图像。我们首先将图像初始化为0,并通过计算如图4中损失函数对图像的梯度,并不断修改图像像素就会得到图5中的可视化结果。这些图表示,要使得最终某类的分数最大,那么所对应的输入图像应该是什么样子,从图56


2、深度学习模型到底学习了什么?
那么,深度学习模型到底都在学习什么呢?
首先输入一张正常图像,我们通过放大的方式来可视化神经网络看到的模式:首先将原始图片通过神经网络进行计算,得到当前图片的输出结果,然后用梯度上升的方式最大化该输出结果,利用如图4中所使用的方法,最后得到如图8所示的结果。

从图中可以看出,神经网络对输入图像中的颜色和纹理进行了语义类别的放大,并产生对应的语义理解。例如,在山的区域,神经网络进行了建筑以及动物的解释,在天空区域有某些海洋生物的解释。但是由于这幅输入图像的这种解释所产生的特征响应并没有达到一定的程度,因此不会影响最后网络的识别,即神经网络不会把山那块区域识别成动物等。

从上述可视化的结果可以看出,神经网络是对纹理颜色等进行了语义的理解,但并没有显著对全局的形状等信息进行了理解,最近一系列工作都表明了这点,例如Geirhos, Robert等人指出,在ImageNet预训练的网络对纹理存在偏向,他们利用实验做了说明:如下图所示:

第一幅没有任何全局形状的信息,神经网络预测该幅图像为大象,对于第二幅图像预测为猫,对于第三幅图像,神经网络依然预测为大象,尽管人可能会识别出是一只猫,因此从这个对比实验中可以看出,神经网络更倾向于对纹理等信息进行了语义理解。
本文开头的小实验也进一步验证了这个假设:局部纹理的打乱,能够显著破坏神经网络的高层语义理解,但是全局结构的打乱并不能显著破坏神经网络的语义理解。
3、对抗样本生成
那么,一般是如何生成对抗样本呢?主要有两种方法:
1)基于梯度的方法:一般采用类似可视化的方法,只不过优化的目标不同,通过梯度更新的方式使得损失变大,并将生成纹理扰动叠加到原始图像上得到对抗样本。比较常用的方法有FGSM,BIM,基于momentum的方法,基于所有图片的梯度进行平滑的方法UAP,以及我们为了解决黑盒迁移性提出的TAP方法,这类方法速度较慢,一般通过多次迭代得到对抗样本,这类方法简单易扩展到其他任务。
2)基于神经网络的对抗样本生成方法:采用神经网络直接输出对抗样本,例如,AdvGAN、ATN等方法。这类方法的速度较快,但由于神经网络参数固定后生成的对抗样本会存在不丰富的问题。
4、如何避免“被骗”?
如Nature新闻中所说,不停的加入对抗样本训练能够获得对对抗样本的鲁棒性吗?我们给出答案是NO。对于对抗训练生成的模型,我们论文中的方法已经实验证明无法扛住低频扰动的对抗样本,文献3通过大量的实验也已证明,NIPS 2017对抗样本挑战赛中所使用的防守方法都无法防住包含低频扰动的对抗样本。
此外,底层图像去噪这种方法也是见效甚微。底层图像去噪只能防止高频的噪声的对抗样本,对于低频的噪声的对抗样本也无法完全抵抗。
通过在攻击方面的经验,团队对于对抗样本的防守方法有以下思考:
1)对特征值进行截断限制
对神经网络里使用truncated relu这类激活函数,对特征值进行截断处理,防止因为对抗样本造成的特征突变太大,影响网络最终预测结果。
2)设计模型更加关注图像整体结构,而不是纹理特征获得更强的鲁棒性
如Nature新闻中指出的,DNN和符号AI的结合,加入结构化的规则来融合整体的结构信息。
安全平台部公共平台中心基础研究组在对抗样本方面进行了深入的研究,并在计算机视觉顶级会议之一的ECCV 2018上发表对抗样本生成的论文,在NIPS 2017对抗样本挑战赛、极棒上海邀请赛等国内外大赛中均取得优异成绩。欢迎各位对对抗样本生成以及防守感兴趣的同学与我们交流。

















 3955
3955

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









