






 英伟达CEO黄仁勋在人工智能伍德斯托克活动中发布了Blackwell芯片,展示其在人工智能领域的实力。然而,随着ChatGPT时代的到来,Nvidia面临的挑战是如何保持其软件优势,尤其是在AI微服务NIM可能影响生态竞争的背景下。
英伟达CEO黄仁勋在人工智能伍德斯托克活动中发布了Blackwell芯片,展示其在人工智能领域的实力。然而,随着ChatGPT时代的到来,Nvidia面临的挑战是如何保持其软件优势,尤其是在AI微服务NIM可能影响生态竞争的背景下。
来自华尔街日报:
英伟达对人工智能的狂热已经达到了这样的程度:周一,首席执行官黄仁勋在一场被分析师称为“人工智能伍德斯托克”的活动中,在运动场上推出了该公司的最新芯片。
这家芯片公司的客户、合作伙伴和粉丝纷纷涌入美国冰球联盟圣何塞鲨鱼队的主场 SAP 中心,聆听黄仁勋在 Nvidia 年度大会上发表的主题演讲,今年的大会可容纳约 11,000 名观众。职业摔跤的 WWE Monday Night RAW 赛事于二月份在那里举行。贾斯汀·汀布莱克 (Justin Timberlake) 计划于五月到该体育馆进行比赛。即使是苹果公司备受关注的 iPhone 和 iPad 发布会也没有坐满这么大的场地。科技界关注的焦点是黄仁勋,他从一位拥有视频游戏爱好者忠实追随者的半导体首席执行官,变成了一位具有足够广泛吸引力的人工智能经理,能够吸引数千人参加企业活动。
或者,正如 Nvidia 研究经理 Jim Fan在 X 上所说的那样:
我对《华尔街日报》在有关该事件的文章中使用此线索感到失望,但这并不是因为我认为他们应该谈论实际的公告:相反,他们和我有完全相同的想法。黄的主题演讲黄仁勋黄的主题演讲中最引人注目的内容是场面,甚至比公告更重要。
与《华尔街日报》相反,我确实认为 iPhone 的发布是一个相关的类比;苹果本可以轻松地坐满 11,000 个座位,尤其是在 iPhone 的早期。不过,也许一个更好的类比是 Windows 95 的发布。Lance Ulanoff于 2001 年在 Medium 上写了一篇回顾:
很难想象有一个操作系统能够像 1995 年 Windows 95 的发布那样获得近乎全球的关注。1995 年 8 月 24 日,来自世界各地的记者们来到了郁郁葱葱、规模较小的微软公司。校园位于华盛顿州雷德蒙德。有一些带有原始 Windows 开始按钮(“开始”是整个活动的主题)的门票(我仍然保留着),允许进入仅限受邀者参加的嘉年华式活动……那是一段相对快乐和纯真的时光。技术。也许是互联网主宰一切之前的最后一次重大发布,当时一个软件平台,而不是博客文章或硬件,可以改变世界。
人们可以想象在 2040 年写一篇文章回顾“科技领域相对快乐和纯真的时光”,因为我们目睹了“也许是人工智能主宰一切之前的最后一次重大发布”,当时芯片“可以改变世界”;也许对过去的回顾将是像我这样的人类作家最后的避难所。
旧的 GTC
对于像我这样曾经和未来的老顽童来说,有趣的是这个活动的相对集中性:是的,黄仁勋谈到了天气、机器人、全宇宙和汽车等话题,但这是第一次- 最重要的是,芯片发布 - Blackwell B200 一代 GPU - 主题演讲的大部分内容都在谈论其各种功能和排列、性能、合作伙伴关系等。
我认为这与GTC 2022形成鲜明对比,当时黄仁勋宣布了 Hopper H100 一代 GPU:关于芯片/系统架构的部分要短得多,伴随着大量关于潜在用例的讨论以及所有Nvidia 为 CUDA 开发的各种库。正如我一年前解释的那样,这对于 GTC 来说是正常的:
坦率地说,这是一个相当压倒性的主题演讲。 Liberty 认为这很酷:
机器人、数字孪生、游戏、机器学习加速器、数据中心规模计算、网络安全、自动驾驶汽车、计算生物学、量子计算、元宇宙构建工具和万亿参数人工智能模型!是的,请
不过,黄在主题演讲 的引言中强调的一点 是,这本书有其韵律和理由……
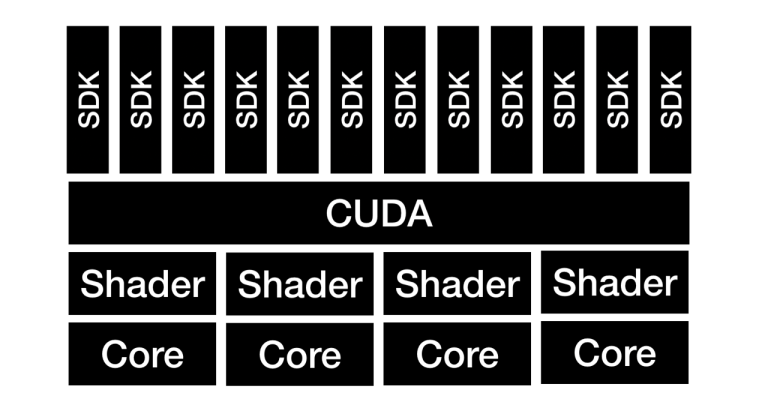
然后,我对 CUDA 进行了详细解释,并解释了为什么它对于理解 Nvidia 的长期机会至关重要,并得出结论:
这是思考 Nvidia 堆栈的一种有用方法:编写着色器就像编写汇编一样,因为它非常困难,而且很少有人能做好。CUDA 将其抽象为一个通用 API,该 API 更加通用且易于使用——在这个类比中,它就是操作系统。不过,就像操作系统一样,拥有可以减少程序员之间重复工作、使他们能够专注于自己的程序的库很有用。CUDA 和黄提到的所有 SDK 也是如此:这些库使实现在 Nvidia GPU 上运行的程序变得更加简单。
这就是一个主题演讲可以涵盖“机器人、数字孪生、游戏、机器学习加速器、数据中心规模计算、网络安全、自动驾驶汽车、计算生物学、量子计算、元宇宙构建工具和万亿”的原因。 -参数人工智能模型”;其中大多数是基于 CUDA 的新库或更新库,Nvidia 制造的越多,他们就能制造的越多。
这并不是 Nvidia 堆栈的唯一部分:该公司还在硬件和软件层面上对网络和基础设施进行了投资,使应用程序能够在整个数据中心内扩展,并在数千个芯片上运行。这也需要一个独特的软件平面,这强调了了解英伟达最重要的一点是,它不是一家硬件公司,也不是一家软件公司:它是一家整合了两者的公司。
回想起来,这些 GTC 是一家公司在产品与市场契合度达到天文数字之前就推出的。当然,黄和 Nvidia 了解 Transformer 和 GPT 模型——黄在昨天的开场白中提到了他在 2016 年亲手向 OpenAI 交付的第一台 DGX 超级计算机——但请注意,他手绘的计算历史幻灯片似乎排除了很多GTC 以前的东西:
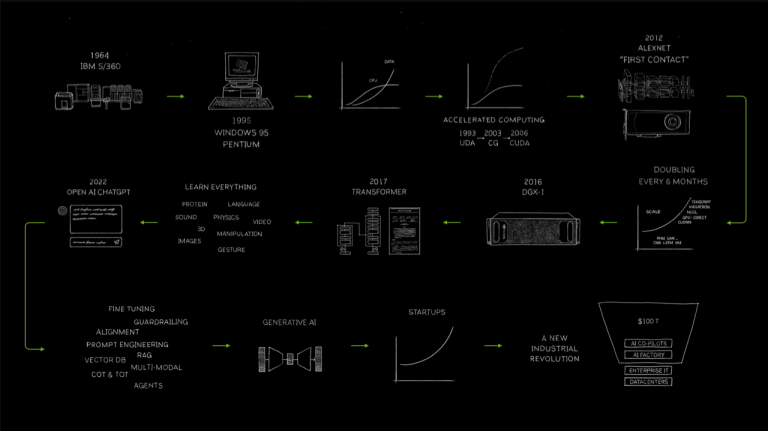
突然间,在那几年里最重要的是Transformer!
明确地说,我并没有以任何方式欺骗黄仁勋或 Nvidia。恰恰相反。绝对正确的是,Nvidia 拥有一种新的计算方式,而之前的 GTC 的目的是进行实验并推动世界寻找它的用例;今天,在这个后 ChatGPT 世界中,最大的用例——生成式人工智能——已经非常明确,黄仁勋要传达的最重要的信息是为什么 Nvidia 将在可预见的未来继续主导该用例。
Blackwell
那么关于Blackwell本身;来自彭博社:
Nvidia 公司在年度 GPU 技术大会上推出了其最强大的芯片架构,该大会被一些分析师称为 AI 伍德斯托克大会。首席执行官黄仁勋上台展示了新的 Blackwell 计算平台,其核心是 B200 芯片,这是一个拥有 2080 亿个晶体管的强大芯片,其性能超过了 Nvidia 已经领先的人工智能加速器的性能。在主要企业甚至国家都将人工智能发展作为优先事项之际,该芯片有望扩大英伟达对竞争对手的领先优势。在 Blackwell 的前身 Hopper 的推动下,Nvidia 的估值突破了 2 万亿美元以上,现在,Nvidia 对其最新产品设定了很高的期望。
关于 Blackwell,首先需要注意的是,它实际上是将两个芯片融合到一个芯片中,该公司称其为完全一致性;这在实践中意味着布莱克威尔相对于霍珀的收益很大一部分在于它要大得多。这是黄拿着 Hopper 和 Blackwell 芯片进行比较:
 “Blackwell 更大”的主题适用于 Nvidia 围绕它构建的系统。完全集成的 GB200 平台具有两颗 Blackwell 芯片和一颗 Grace CPU 芯片,而不是 Hopper 的 1 对 1 架构。Huang 还推出了 GB200 NVL72,这是一种液冷机架大小的系统,包括与新一代 NVLink 互连的 72 个 GPU,该公司声称,与相同数量的 H100 GPU 相比,该系统在 LLM 推理方面的性能提高了 30 倍(部分归功于用于基于变压器的推理的专用硬件),成本和能耗降低了 25 倍。我发现这些幻灯片上有一组值得注意的数字:
“Blackwell 更大”的主题适用于 Nvidia 围绕它构建的系统。完全集成的 GB200 平台具有两颗 Blackwell 芯片和一颗 Grace CPU 芯片,而不是 Hopper 的 1 对 1 架构。Huang 还推出了 GB200 NVL72,这是一种液冷机架大小的系统,包括与新一代 NVLink 互连的 72 个 GPU,该公司声称,与相同数量的 H100 GPU 相比,该系统在 LLM 推理方面的性能提高了 30 倍(部分归功于用于基于变压器的推理的专用硬件),成本和能耗降低了 25 倍。我发现这些幻灯片上有一组值得注意的数字:

值得注意的是,两次训练花费相同的时间——90 天。这是因为实际计算速度基本相同;这是有道理的,因为 Blackwell 和 Hopper 一样,都是采用台积电的 4nm 工艺制造的,
并且实际的计算本质上是相当连续的(因此主要由芯片的底层速度决定)。不过,“加速计算”并不是指串行速度,而是并行性,每一代新一代芯片与新的网络相结合,都可以实现更高效的并行性,从而保持 GPU 满载。这就是为什么必要的 GPU 数量以及总功耗方面有了巨大的改进。
推而广之,这意味着 Hopper 大小的 Blackwell GPU 群将能够构建更大的模型,并且考虑到规模和模型能力之间似乎存在线性关系,GPT-6 和除此之外仍然很清楚(GPT-5 可能是在 Hopper GPU 上训练的;GPT-4 是在 Ampere A100 上训练的)。
有趣的是,有报道称,虽然 B100 的制造成本是 H100 的两倍,但 Nvidia 的涨价幅度远低于预期;这解释了该公司预计未来利润率会略低的原因。该报告后来从互联网上消失了(也许是因为它是在主题演讲之前发布的?),推测 Nvidia 担心面对 AMD 的激进价格及其最大的客户试图建立自己的市场份额,以保持其市场份额。自己的芯片。不用说,寻找替代方案有巨大的动力,特别是在推理方面。
Nvidia 推理微服务 (NIM)
我认为这为另一项 GTC 公告提供了有用的背景;来自Nvidia 开发者博客:
生成式人工智能的采用率显着上升。在 2022 年 OpenAI ChatGPT 推出的推动下,这项新技术在几个月内就积累了超过 1 亿用户,并推动了几乎所有行业的开发活动激增。到 2023 年,开发人员开始使用来自 Meta、Mistral、Stability 等的 API 和开源社区模型进行 POC [概念验证]。
进入 2024 年,组织将重点转向全面生产部署,其中涉及将 AI 模型连接到现有企业基础设施、优化系统延迟和吞吐量、日志记录、监控和安全性等。这条生产之路既复杂又耗时——它需要专门的技能、平台和流程,尤其是大规模生产。
NVIDIA NIM 是 NVIDIA AI Enterprise 的一部分,为开发 AI 驱动的企业应用程序和在生产中部署 AI 模型提供了简化的路径。
NIM 是一组优化的云原生微服务,旨在缩短上市时间并简化生成式 AI 模型在云、数据中心和 GPU 加速工作站上的部署。它通过使用行业标准 API 抽象化 AI 模型开发和生产打包的复杂性来扩展开发人员库。
NIM 是预构建的容器,其中包含组织开始模型部署所需的一切,它们不仅满足当前的实际需求,而且满足未来的实际需求;Huang 提出了一个令人信服的场景,公司在代理类型的框架中使用多个 NIM 来完成复杂的任务:
想想什么是 AI API:AI API 是一个您只需与之交谈的接口。所以这是一个未来有一个非常简单的 API 的软件,这个 API 被称为人类。这些软件包,令人难以置信的软件体,将被优化和打包,我们将把它放在一个网站上,你可以下载它,你可以随身携带它,你可以在任何云上运行它,你可以在你的计算机上运行它。如果适合的话,您可以在工作站上运行它,您所要做的就是访问 ai.nvidia.com。我们称之为 Nvidia Inference Microservices,但在公司内部我们都称之为 NIM。
想象一下,有一天将会出现这样的聊天机器人,并且这些聊天机器人将位于 NIM 中。你将组装一大堆聊天机器人,这就是有一天软件的构建方式。未来我们如何构建软件?您不太可能从头开始编写它,或者编写一大堆 Python 代码或类似的东西。你很可能组建了一支人工智能团队。
你可能会使用一个超级人工智能,它会接受你赋予它的任务并将其分解为执行计划。部分执行计划可以移交给另一个 NIM,该 NIM 可能会理解 SAP。SAP的语言是ABAP。它可能会理解 ServiceNow 并从其平台检索一些信息。然后,它可能会将结果交给另一个 NIM,后者会对其进行一些计算。也许它是一个优化软件,一个组合优化算法。也许这只是一些基本的计算器。也许是 pandas 对其进行一些数值分析。然后它会返回自己的答案,并与其他人的答案结合起来,因为它已被呈现为“这就是正确的答案应该是什么样子”,所以它知道要产生什么正确的答案,并将其呈现给您。我们每天都可以得到一份报告,该报告与构建计划或某些预测或某些客户警报或数据库中的某些错误或任何发生的情况有关,我们可以使用所有这些 NIM。
由于这些 NIM 已打包并准备在您的系统上工作,因此只要您的数据中心或云端有 Nvidia GPU,这些 NIM 就会作为一个团队协同工作,并做出令人惊奇的事情。
你注意到这个陷阱了吗?NIM(Nvidia 将自行创建并刺激更广泛的生态系统创建,目标是免费提供它们)将仅在 Nvidia GPU 上运行。
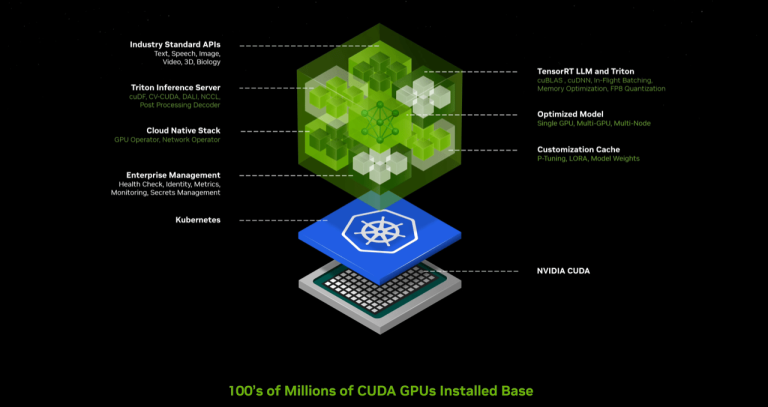
这使本文回到了原点:在以前,即在 ChatGPT 发布之前,Nvidia 正在围绕其 GPU 构建相当多的(免费)软件护城河;挑战在于尚不完全清楚谁将使用所有这些软件。与此同时,今天这些 GPU 的用例非常明确,并且这些用例发生在比 CUDA 框架更高的级别(即在模型之上);再加上寻找更便宜的 Nvidia 替代品的巨大激励措施,意味着逃离 CUDA 的压力和可能性都比以往任何时候都要高(即使对于较低级别的工作来说仍然很遥远,特别是在培训方面) )。
Nvidia 已经开始做出回应:我认为理解 DGX Cloud 的一种方式是,Nvidia 试图在 AMD 芯片更好的世界中占领仍在购买英特尔服务器芯片的同一市场(因为他们已经对其进行了标准化);NIM 是建立锁定的另一种尝试。
但与此同时,值得注意的是,Nvidia 似乎并没有像许多人预期的那样从 Blackwell 获得那么多利润。他们是否需要在未来几代人中回馈更多的问题不仅取决于他们的芯片性能,还取决于重新挖掘软件护城河,而软件护城河正日益受到使 GTC 成为如此奇观的浪潮的威胁。

















 1292
1292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









