








LDA
线性判别分析(Linear Discriminant Analysis, 简称LDA),最早由Fisher提出,也叫“Fisher判别分析”。
线性判别分析的思想:给定样本数据集,设法将样本投影到某一条直线上,使得同类样本的投影点尽可能接近,异类样本的投影点尽可能远;在对新的点进行分类预测时,将其投影到这条直线上,根据投影点的位置来判断样本的类别。
当x是二维时,我们就要寻找一个方向为
ω
的直线来使得这些样本点的投影分离。
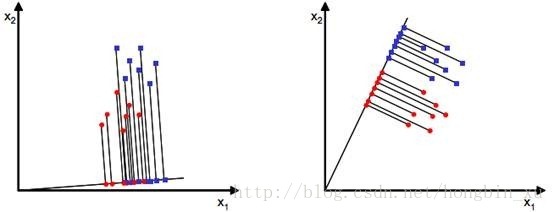
二分类情况
先只考虑二分类情况,给出数据集
{xi,yi}mi=1,yi={0,1}
。
设有
N0
个样本的标签
yi=0
,其类别为
D0
;
N1
个样本的标签
yi=1
,其类别为
D1
。
则分别对应类别
D0
和
D1
的均值向量
μ0
和
μ1
可以求出来:
再给出一组新的度量值,称作散度值(scatter):
这东西看上去很眼熟吧,不就是方差,少除了样本数量吗?因为这里只需要定量表示样本集合的分散程度,对常数系数不敏感,所以方差中上面的部分就足够了。
给出一组参数
ω
,假设值为:
h(xi)=ωTxi
,后面简写为
hi=ωTxi
。
在线性回归中,我们的目标是使得这个假设值等于样本的标签
yi
;
而线性判别分析中,假设值
hi
实质上是样本
xi
在
w
上的投影的长度;以二维情况考虑,就是样本
再放一次这幅图,看看图不难理解:

接着,根据 ω 可以求出投影后的样本均值 μ0~ 和 μ1~ :
同理得:
还有,投影后的散度矩阵(scatter):
同理得:
回到最开始说的思想:希望同类样例的投影点尽可能接近,即散度矩阵尽可能小,也即
s0~
和
s1~
都要尽可能小,简单表示为
s0~+s1~
;异类样例的投影点尽可能远,也即均值差值尽可能大,
(μ0~−μ1~)2
尽可能大;
同时考虑上面两个条件,可以给出一个目标函数:
代入前面求出的 μ0~ 、 μ1~ 、 s0~ 、 s1~ :
这坨东西看得挺复杂的,定义类内散度矩阵(within-class scatter matrix):
还有定义类间散度矩阵(between-class scatter matrix):
则优化的目标函数变为:
这个东西就是LDA希望最大化的目标,实质是 Sb 和 Sω 的“广义瑞利商”(generalized Rayleigh quotient)。
好的,接下来的任务就是通过
J
来确定最优的
观察式子可以发现,
J
的大小不随
所以可以令
ωTSωω=1
,则式子等价于:
使用拉格朗日乘子法:
设未知数 λ ,写出拉格朗日函数:
对拉格朗日函数求导,且导数为0:
矩阵求导中 ωTSbω 可以简单看作是 Sbω2 。
得到结果:
这是一个典型的求矩阵特征值的问题。
从前面的公式:
我们知道 ω 的大小并不影响结果,而是方向才会影响结果。
另外,由这个式子:
观察发现 Sbω 的方向恒为 μ0−μ1 ,因为任取其中一个 (μ0−μ1)T 与 ω 相乘之后是常数,总会剩下一个 μ0−μ1 。
所以,设一个新的常量 λω ,使得:
回到前面拉格朗日方程求导得到的结果:
得到:
若 ω 可逆,则有:
注意,由于最后结果只与 ω 的方向有关,与其大小无关;而这个结果前面的常量 λωλ 可以舍去:
这个就是最终的结果。
前面已经推导出了 Sω 、 μ0 、 μ1 ,代入即可。我们只要有散度矩阵和均值即可求出最优的 ω 。
这里还有一点,考虑到数值解的稳定性,在实践中通常是对 Sω 进行奇异值分解,即 Sω=UΣVT ,这里 Σ 是一个实对角矩阵,其对角线上的元素是 Sω 的奇异值,然后再由 S−1ω=VΣ−1UT 得到 Sω 。(摘自西瓜书,没学矩阵论,发现好多不懂的)
多分类情况
其实结果跟前面呢二分类差不多,不过是扩展到了多维情况下。
假设存在
N
个类别,且第
定义
μ
为所有样本的均值向量,如图中就是二维下的情况。

μi
表示第
i
类的所有样本的均值向量;
考虑所有类的情况,定义全局散度矩阵:
展开类似与二分类的类内散度矩阵:
实质是将所有类别的散度矩阵加在一起。
接下来考虑类间散度矩阵
Sb
,在二分类中,只考虑了两个均值点
μ0
和
μ1
的情况;现在在多分类情况下,考虑每个均值点
μi
与全局的均值点
μ
之间的距离。
由于每个类别的样本数量不同会对全局均值点
μ
产生影响:
注:共有 N 个类别,且第
所以还要引入加权求和,每个类的权值为: mi∑Ni=0mi 。由于 J 对倍数不敏感,所以可以把下面的总和去掉,直接使用
写出类间散度矩阵 Sb :
与二分类时的步骤一样,求出投影后的 Sb 和 Sω ,步骤就不作赘述了:
好了,现在可以写出目标函数了:
我们希望:同类样例的投影点尽可能接近,即散度矩阵尽可能小,也即 Sω~ 要尽可能小;异类样例的投影点尽可能远,也即类间距离尽可能大, Sb~ 尽可能大;
写出与二分类时一样的目标函数:
由于我们得到的分子分母都是散列矩阵,要将矩阵变成实数,需要取行列式。又因为行列式的值实际上是矩阵特征值的积,一个特征值可以表示在该特征向量上的发散程度。因此我们使用行列式来计算(此处我感觉有点牵强,道理不是那么有说服力)。
现在又回到了求 J 的最大值的问题了,跟前面一样的步骤进行求解。
使用拉格朗日乘子法,得到特征方程:
强调内容接下来就是求矩阵的特征值的问题了,先求出矩阵 S−1ωSb 的特征值,之后取前 N−1 个特征向量,构成 ω 即可。(好吧,这又是个要填的“坑”)
参考资料:
1、《机器学习》周志华
2、线性判别分析(Linear Discriminant Analysis)(一)
写了快一下午了,满脑子数学公式,还有矩阵分析真的有必要补补了。
(~.~)















 389
389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









