






摘要
现有的四旋翼轨迹重规划方法在有限时间内不能为解决方案的可行性和质量提供强有力的保证。而且,大多数方法没有考虑环境感知,然而环境感知是快速飞行的关键问题。本文提出了 RAPTOR,一个稳定和意识感知重规划框架(a robust and perception-aware replanning
framework),来支持快速和安全飞行,系统性地解决了上述问题。设计了一个包含多个拓扑路径的路径引导优化(PGO)方法,确保在十分有限的时间里找到可行高质量的轨迹。引入了意识感知规划策略来主动观察和避开位置障碍物。一个风险感知策略优化保证能够更早观察到可能危及四旋翼的未知障碍物并及时避开。通过对偏航角方向运动的规划,主动探索与飞行方向相关的周围空间。
引言
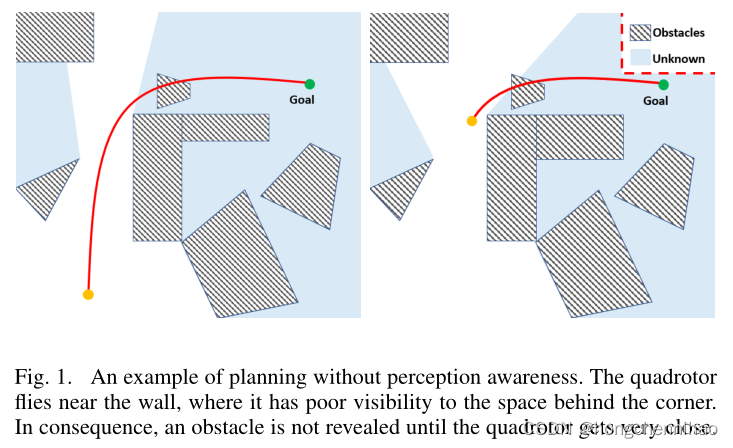
(a)在未知环境中高速飞行,四旋翼应该重新规划新的轨迹,以在相当短的时间内避免意外障碍,否则它会坠毁。然而,大多数方法不能保证在非常有限的时间内找到可行的轨迹。(b)目前的方法通常找到一个局部最优的轨迹,局限在一个拓扑等效类内,这并不一定包含一个令人满意的解决方案,以实现平稳和安全的航行,特别是在快速飞行中。©现有方法没有意识到环境感知,当飞行速度和障碍物密度变大时,这可能是致命的。如果不注意感知,计划的运动可能会导致对环境的能见度受限,这反过来又会导致缺乏安全导航所需的周围空间信息。图1可以更好地说明在重规划中不考虑感知的后果。为了最大限度地减少能源消耗,在靠近墙壁的地方产生了一条轨迹,沿着这条轨迹,对角落后面未知空间的可见性非常有限。因此,在转角后面的障碍物是看不见的,直到四旋翼向右转并非常接近,这“令人惊讶”甚至崩溃的四旋翼。而不是被动地回避观察到的东西,主动观察和避免可能的危险是安全高速飞行的关键。
本文提出了一个基于意识感知的稳定轨迹重规划框架(RAPTOR)。为确保在有限时间内获得可行的轨迹,提出了一个路径引导的基于梯度的优化方法,利用集合引导路径来消除不可行的局部极小值和保证重规划的成功。为进一步提高重规划的最优性,引进了一个在线拓扑路径规划来提取一个综合的路径集合,捕获环境的结构。在几条不同路径的引导下,多条路径被并行优化,对解空间进行全面地探索。
上述解决问题(a)和(b)的方法是我们在之前的工作[1]中首次提出的。但是它采用乐观假设并且缺乏对环境的感知,不适应高速飞行和复杂环境。为解决该问题,采用意识环境感知策略,从两方面实现更快和更安全飞行。首先,提出一个风险感知轨迹优化方法,与乐观规划器想结合。它认为沿着乐观轨迹的未知区域对四旋翼有潜在危险。要求强制保持对这些区域的可见度与安全反应距离,确保未建图区域的障碍物能够被更早发现和避免。第二,将四旋翼的偏航角融入到一个两步运动规划框架中。在离散状态空间中搜索一个信息增益和平滑度最大化的偏航角的最优序列,并通过优化器进一步平滑。规划的偏航角运动可以使视场角(field-of-view,FOV)有限的四旋翼主动地探索未知空间,获得对未来飞行的重要信息。
系统概述
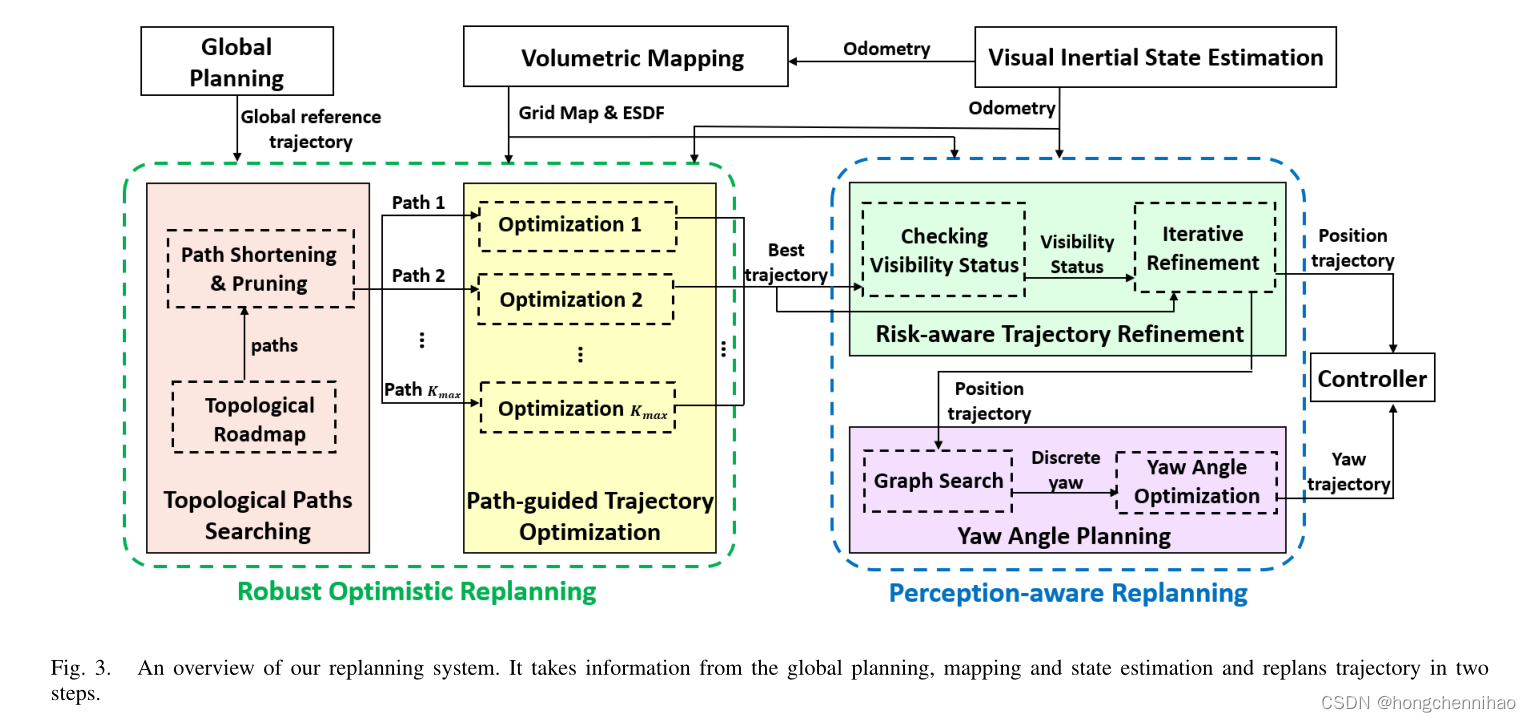
提出的重规划系统如图 3 所示。它采用全局规划、稠密建图和状态估计模块的输出,并改变全局参考路径的局部形状来避开先前未知的障碍物。重规划工作分为两步。首先,鲁棒乐观规划通过路径引导优化并行生成多条局部最优的轨迹(Sect. IV)。该优化是通过拓扑路径搜索中提取并细心选择的不同路径来引导的,这将在 Sect.V 中具体描述。在这一步会采取乐观假设。在第二步中,利用了意识感知规划策略。局部最优轨迹中最好的轨迹将通过风险意识轨迹优化方法进一步圆滑,提高它的安全性和对未知和危险空间的可见度,将在 Sect.VI 中描述。基于这个优化轨迹,将会规划偏航角来主动探索未知环境(Sect.VII)。全局规划,建图,估计和控制器将会在 Sect.VIII-A 中介绍。
路径引导的轨迹优化
基于梯度的轨迹优化(GTO)对于重规划是有效的但是容易陷入局部极小值。为了提高重规划的鲁棒性和确保飞行安全,提出了 路径引导的优化(PGO),在优化中利用几何引导路径来保证成功。
A.优化失败分析
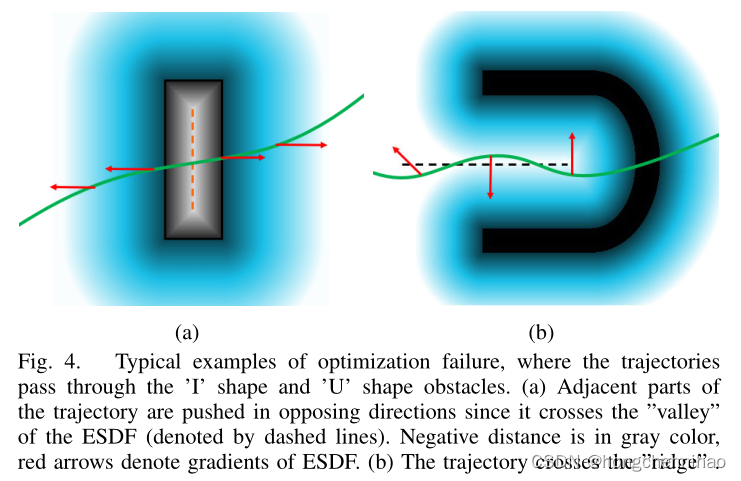
先前的工作[39]显示 GTO 的失败与不好的初始化有关,即初始化的路径已某种方式穿过障碍物时可能会被卡住。造成这种现象的根本原因如图 4 所示。典型的 GTO 方法将 ESDF 的梯度信息融合进碰撞代价中,来推动轨迹脱离障碍物。但是在ESDF的一些“山谷”或“山脊”周围梯度差异很大。因此,如果轨迹发生碰撞并且穿过这些区域,ESDF 的梯度将会在某些点发生突然变化。这会使碰撞代价的梯度朝相反的方向推动轨迹的不同部分,导致优化失败。
通常,难以避免与附近障碍物表面有相同距离的所对应空间的“山脊”和“山谷”,尤其是在复杂环境中。因此,仅依赖 ESDF 的优化不可避免有时会失败。为了解决这个问题,必须要引进额外的可以生成一个目标函数的信息,它的梯度可以持续的将轨迹推离到自由空间。
B.问题描述
所提出的 PGO 是建立在之前那的工作[15]之上的,其为了进行更有效的代价估计,将轨迹表示为 B 样条。对于发生碰撞的轨迹段,将其重参数化为带有控制点
{
q
0
,
q
1
,
.
.
.
,
q
N
}
\{q_0,q_1,...,q_N\}
{q0,q1,...,qN} 和节点跨度
Δ
t
\Delta t
Δt 的
p
b
p_b
pb 阶均匀 B 样条。PGO 包含两个不同的阶段。一阶段会生成一个中间的过渡轨迹。如上所述,应当引入外部信息来使轨迹有效地变形而不是只依赖 ESDF。因为无碰撞轨迹很容易从 A* 或 RRT* 等标准方法中获取,本文采用一个几何引导路径来吸引初始轨迹到自由空间中(如图 5(a)所示)。

本文中的路径由基于采样的拓扑路径搜索提供(Sect. V)。第一阶段的目标函数为:
f
p
1
=
λ
s
f
s
+
λ
g
f
g
=
λ
s
∑
i
=
p
b
−
1
N
−
p
b
+
1
∥
q
i
+
1
−
2
q
i
+
q
i
−
1
∥
2
+
λ
g
∑
i
=
p
b
N
−
p
b
∥
q
i
−
g
i
∥
2
f_{p1}=\lambda_{s}f_{s}+\lambda_{g}f_{g} = \begin{array}{c}{{\lambda_{s}\sum_{i=p_{b}-1}^{N-p_{b}+1}}} {{\|\mathbf{q}_{i+1}-2\mathbf{q}_{i}+\mathbf{q}_{i-1}\|^{2}+\lambda_{g}\sum_{i=p_{b}}^{N-p_{b}}\|\mathbf{q}_{i}-\mathbf{g}_{i}\|^{2}}}\end{array}
fp1=λsfs+λgfg=λs∑i=pb−1N−pb+1∥qi+1−2qi+qi−1∥2+λg∑i=pbN−pb∥qi−gi∥2
其中,
f
s
f_s
fs 是平滑度项,
f
g
f_g
fg 是引导路径和 B 样条轨迹之间距离的惩罚项。如文献[15],
f
s
f_s
fs 被设计为弹性带代价函数,用来模拟一系列弹簧的弹性力。利用 B 样条的形状由它的控制点精确控制的特性来简化
f
g
f_g
fg 的设计。每个控制点都会分配一个沿引导路径均匀采样的与之相关联的点。之后
f
g
f_g
fg 被定义为这些点对之间欧氏距离的平方和。
f
p
1
f_{p1}
fp1 最小化是一个无约束二次规划问题,它的最优解可以以封闭形式得到。它会在引导路径周围输出一个平滑轨迹。因为引导路径是无碰撞的,所以过渡轨迹经常也是无碰撞的。即使不是完全无碰撞,它的主要部分将会被吸引到自由空间。在这一阶段,ESDF 沿着轨迹的梯度变化平稳,并且目标函数的梯度会将轨迹按相同的方向推动到自由空间。因此,可以使用标准的GTO方法来改进轨迹。
在第二阶段,调整了[15]中的 B 样条优化方法来进一步优化过渡轨迹的平滑度、安全性和动态可行性,目标函数如下:
f
p
2
=
λ
s
f
s
+
λ
c
f
c
+
λ
d
(
f
v
+
f
a
)
=
λ
s
∑
i
=
p
b
−
1
N
−
p
b
+
1
∥
q
i
+
1
−
2
q
i
+
q
i
−
1
∥
2
+
λ
c
∑
i
=
p
b
N
−
p
b
F
(
d
(
q
i
)
,
d
min
)
+
λ
d
∑
μ
∈
{
x
,
y
,
z
}
{
∑
i
=
p
b
−
1
N
−
p
b
F
(
v
max
2
,
q
˙
i
,
μ
2
)
+
∑
i
=
p
b
−
2
N
−
p
b
F
(
a
max
2
,
q
¨
i
,
μ
2
)
}
(
2
)
\begin{array}{l} f_{p 2}=\lambda_{s} f_{s}+\lambda_{c} f_{c}+\lambda_{d}\left(f_{v}+f_{a}\right)= \\ \lambda_{s} \sum_{i=p_{b}-1}^{N-p_{b}+1}\left\|\mathbf{q}_{i+1}-2 \mathbf{q}_{i}+\mathbf{q}_{i-1}\right\|^{2}+\lambda_{c} \sum_{i=p_{b}}^{N-p_{b}} \mathcal{F}\left(d\left(\mathbf{q}_{i}\right), d_{\min }\right) \\ +\lambda_{d} \sum_{\mu \in \{x,y, z\}}\left\{\sum_{i=p_{b}-1}^{N-p_{b}} \mathcal{F}\left(v_{\max }^{2}, \dot{q}_{i, \mu}^{2}\right)+\sum_{i=p_{b}-2}^{N-p_{b}} \mathcal{F}\left(a_{\max }^{2}, \ddot{q}_{i, \mu}^{2}\right)\right\} \end{array} \quad (2)
fp2=λsfs+λcfc+λd(fv+fa)=λs∑i=pb−1N−pb+1∥qi+1−2qi+qi−1∥2+λc∑i=pbN−pbF(d(qi),dmin)+λd∑μ∈{x,y,z}{∑i=pb−1N−pbF(vmax2,q˙i,μ2)+∑i=pb−2N−pbF(amax2,q¨i,μ2)}(2)
这里
F
(
)
{\mathcal{F}}(\mathbf{})
F() 是一般变量的惩罚函数:
F
(
x
,
y
)
=
{
(
x
−
y
)
2
x
≤
y
0
x
>
y
(
3
)
\mathcal{F}(x,y)=\left\{\begin{array}{c l}{{\big(x-y\big)^{2}}}&{{x\leq y}}\\ {{0}}&{{x > y}}\end{array}\right. \quad (3)
F(x,y)={(x−y)20x≤yx>y(3)
f
c
f_c
fc 是碰撞代价,如果轨迹与障碍物的距离小于
d
m
i
n
d_{min}
dmin 它将快速增长,其中,
d
(
q
)
d(\mathbf{q})
d(q) 是点
q
\mathbf{q}
q 在 ESDF 中的距离。
f
v
f_v
fv 和
f
a
f_a
fa 惩罚不可行的速度和加速度,
q
˙
i
=
[
q
˙
i
,
x
,
q
˙
i
,
y
,
q
˙
i
,
z
]
T
,
q
¨
i
=
[
q
¨
i
,
x
,
q
¨
i
,
y
,
q
¨
i
,
z
]
T
\dot q_{i}=\ [\dot{q}_{i,x},\dot{q}_{i,y},\dot{q}_{i,z}]^{\mathrm{T}} , \ddot q_{i}=\ [\ddot{q}_{i,x},\ddot{q}_{i,y},\ddot{q}_{i,z}]^{\mathrm{T}}
q˙i= [q˙i,x,q˙i,y,q˙i,z]T,q¨i= [q¨i,x,q¨i,y,q¨i,z]T 是控制点的速度和加速度,它们可由下式计算:
q
˙
i
=
q
i
+
1
−
q
i
Δ
t
,
q
¨
i
=
q
i
+
2
−
2
q
i
+
1
+
q
i
Δ
t
2
{\dot{\mathbf{q}}}_i={\frac{\mathbf{q}_{i+1}-\mathbf{q}_{i}}{\Delta t}},\quad{\ddot{\mathbf{q}}}_{i}={\frac{\mathbf{q}_{i+2}-2\mathbf{q}_{i+1}+\mathbf{q}_{i}}{\Delta t^{2}}}
q˙i=Δtqi+1−qi,q¨i=Δt2qi+2−2qi+1+qi
v
m
a
x
v_{max}
vmax 和
a
m
a
x
a_{max}
amax 是单轴最大速度和最大加速度。
f
v
,
f
c
,
f
a
f_v,f_c,f_a
fv,fc,fa 的公式都是基于 B 样条的凸包性,这足以限制 B 样条的控制点来保证安全和动态可行性。虽然PGO比以往的方法多了一步优化,但它可以在更短的时间内生成更好的轨迹。第一阶段只需要忽略不计的时间,但是产生了一个更容易进一步细化的过渡轨迹,从而提高了整体效率。
拓扑路径搜索
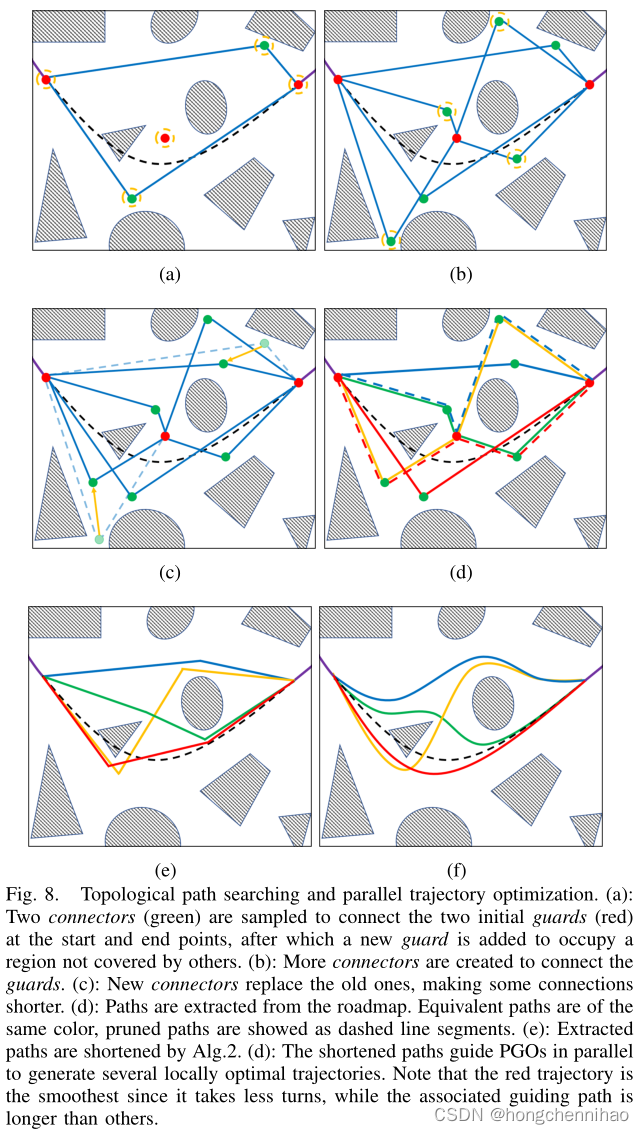
给出一个几何引导路径,PGO 方法可以获得一个局部最优轨迹。然而,这种轨迹被限制在一个拓扑等价的类中,即使有最短路径的引导,也不一定令人满意,如图8(e)和8(f)所示。实际上很难确定最佳几何路径,因为这些路径不包含高阶信息(速度、加速度等),不能完整地反映真实运动。搜索一条运动动力学路径可以满足,但是在重新规划轨迹的开始和结束位置获得一个有边界状态约束的有希望的路径会花费过多的时间。
为了获得更好的解决方案,需要多种引导路径。本文提出了一种基于采样的拓扑路径搜索来寻找不同路径的集合。虽然方法[18,23]-[25]是针对这个问题的,但它们都不能在复杂的 3D 环境中实时运行。本文仔细地重新设计了算法,以实时解决这个具有挑战性的问题。

A.拓扑等价关系

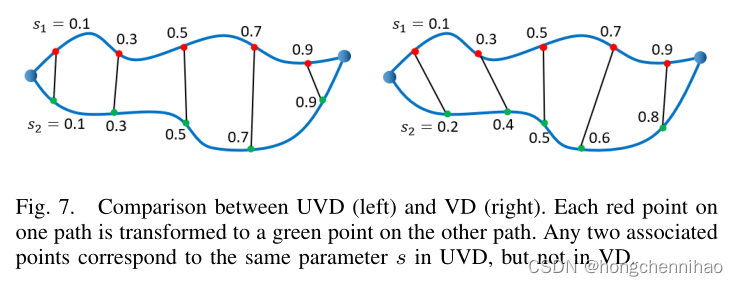
广泛使用的同伦概念在 3D 环境中捕捉的有用轨迹不足,如图 6(a)。[23]提出了一个在 3D 空间中更有用的关系——可见性变形(visibility deformation,VD),但它等效检验的计算成本太高。基于 VD,本文定义了均匀可见性变形(uniform visibility deform,UVD),可以捕捉大量有用的轨迹,并且等效检验更有效。
Definition 1. 通过
s
∈
[
0
,
1
]
s\in [0,1]
s∈[0,1] 参数化的两条轨迹
τ
1
(
s
)
,
τ
2
(
s
)
\tau_1(s),\tau_2(s)
τ1(s),τ2(s),满足
τ
1
(
0
)
=
τ
2
(
0
)
,
τ
1
(
1
)
=
τ
1
(
1
)
\tau_1(0) = \tau_2(0),\tau_1(1)=\tau_1(1)
τ1(0)=τ2(0),τ1(1)=τ1(1),属于同一个均匀可见性变形类,对于所有
s
s
s,线
τ
1
(
s
)
τ
2
(
s
)
‾
\overline{{{\tau_{1}\left(s\right)\tau_{2}\left(s\right)}}}
τ1(s)τ2(s) 是无碰撞的。
图 6(b) 给出了一个三条轨迹属于两个 UVD 类的例子。VD 和 UVD 的关系如图 7。它们都在路径
τ
1
(
s
)
\tau_1(s)
τ1(s) 和
τ
2
(
s
)
\tau_2(s)
τ2(s) 之间定义了一个连续的映射,
τ
1
(
s
)
\tau_1(s)
τ1(s) 上的一个点通过一条直线转换为
τ
2
(
s
)
\tau_2(s)
τ2(s) 上的点。主要的区别是:对于 UVD,点
τ
1
(
s
1
)
\tau_1(s_1)
τ1(s1) 映射为
τ
2
(
s
2
)
\tau_2(s_2)
τ2(s2),其中
s
1
=
s
2
s_1 = s_2
s1=s2,而VD 不必满足这个关系。在概念上,UVD 不够一般化,并且是 VD 的子集。实际上,它要比 VD 捕获更多类的不同路径,但是等效检查代价要更低。
为了测试 UVD 关系,可以将 s∈[0,1] 均匀离散为
s
i
=
i
/
K
,
i
=
0
,
1
,
…
,
K
s_i=i / K, i=0,1, \ldots, K
si=i/K,i=0,1,…,K,并且检查线
τ
1
(
s
)
τ
2
(
s
)
‾
\overline{\tau_1(s) \tau_2(s)}
τ1(s)τ2(s) 的碰撞。对于分段直线路径(如Alg.1 所示,Equivalent() 所示),简单地均匀参数化它,使得对于任何 s ,除了
τ
(
s
)
\tau(s)
τ(s) 是两条直线的连接点以外,都有
∥
d
τ
(
s
)
d
s
∥
=
const
\left\|\frac{d \tau(s)}{d s}\right\|=\text { const }
dsdτ(s)
= const 。
B.拓扑路图
Alg.1 用于构建一个 UVD 路图
g
g
g,捕获来自不同 UVD 类的丰富路径集。与标准 PRM 包含许多荣誉循环不同,本算法生成一个更紧凑的路图,其中每个 UVD 类包含一个或几个路径(如图 8(a)-8©所示)。
引进了与 Visibility-PRM [42]类似的两种图节点,guard 和 connector。guards 负责探索自由空间的不同部分,任意两个 guards
g
1
,
g
2
g_1,g_2
g1,g2 都不能看到对方(连线
g
1
g
2
‾
\overline {g_1 g_2}
g1g2 在障碍物中)。在主循环之前,会在起始点
s
s
s 和终点
g
g
g 创建两个 guards。每当一个采样点对其他所有 guards 都不可见时,就会在该点处创建一个新的 guard (6-7 行)。为了形成路图的路径,使用 connectors 用于连接不同的 guards (7-19行)。当一个采样点被两个 guards 看见时,会创建一个新的 connector,要么连接 guards 形成一个拓扑上不同的连接(19-20行),或者代替已有的 connector 形成一个更短的路径(16-17行)。通过设置最大时间(
t
m
a
x
t_{max}
tmax)或最大采样数量(
N
m
a
x
N_{max}
Nmax)来终止循环。
在 UVD 路图中,一个通过访问节点列表扩展的深度优先搜索被应用于搜索
s
s
s 和
g
g
g 之间的路径,与[20]中类似。
路径缩短和修剪
如图 8(d) 所示,一些从 Alg. 1 中获取的路径可能会绕路。这些路径是不合适的,因为在 PGO 的第一阶段,它会使轨迹过渡变形并使它不光滑。因此,Alg. 2为深度优先搜索找到的每个
P
r
P_r
Pr 找到一个拓扑等价的缩短的路径
P
s
P_s
Ps(如图 9所示)。该算法将 KaTeX parse error: Expected group after '_' at position 3: Pr_̲ 统一离散为一个
P
d
P_d
Pd 点集。在每次迭代中,如果
P
d
P_d
Pd 中的一个点
p
d
p_d
pd 对于
P
s
P_s
Ps 中的最后一个点不可见(3-4行),第一个被占据的体素的中心会阻挡被找到的
P
s
.
b
a
c
k
(
)
P_s.\mathbf {back()}
Ps.back() 的视线。该点会沿着与
l
d
l_d
ld 垂直的方向被推离障碍物,并在
p
b
p_b
pb 点与
l
d
l_d
ld 和 ESDF 梯度方向共面(行 6),之后该点会被加入
P
s
P_s
Ps (行 7)。这个过程一直持续到最后一点。


虽然在 Alg. 1 中排除了两个 guards 之间的冗余连接,但是
s
s
s 和
g
g
g 之间仍然可能存在一小部分重复的路径(图 8(d))。为了完全排除重复的路径,需要检查任意两条路径之间的等效性,值保存拓扑上不同的那条。还要注意,不同路径的数量随着障碍的数量呈指数增长。在复杂环境下,在计算方面,使用所有的路径来引导并行优化是不可行的。因此,只选择前
K
m
a
x
K_{max}
Kmax 条最短路径。比最短路径长
r
m
a
x
r_{max}
rmax 倍的路径也会被修剪掉。这种策略限制了复杂性,不会错过潜在的最优解,因为很长的路径不太可能产生最优轨迹。
风险感知轨迹优化
将来自并行 PGO
p
i
(
t
)
\mathbf p_i(t)
pi(t) 中的最好的轨迹作为轨迹优化的输入,在它的周围对其进行修改并输出优化后的轨迹
p
r
(
t
)
\mathbf p_r(t)
pr(t)(Alg. 3 中详解)。从检查
p
i
(
t
)
\mathbf p_i(t)
pi(t) 的可视状态开始,之后在迭代优化中执行对有关未知空间的可见性和安全反应距离。

检查可见性状态
可见性状态由
t
f
,
p
f
,
t
c
,
p
c
,
v
c
t_f,\mathbf{p}_f,t_c,\mathbf{p}_c,\mathbf{v}_c
tf,pf,tc,pc,vc 几个变量编码,他们是
p
i
(
t
)
\mathbf{p}_i(t)
pi(t) 经过的未知空间的重要信息。一些有关的变量如图 10 所示。
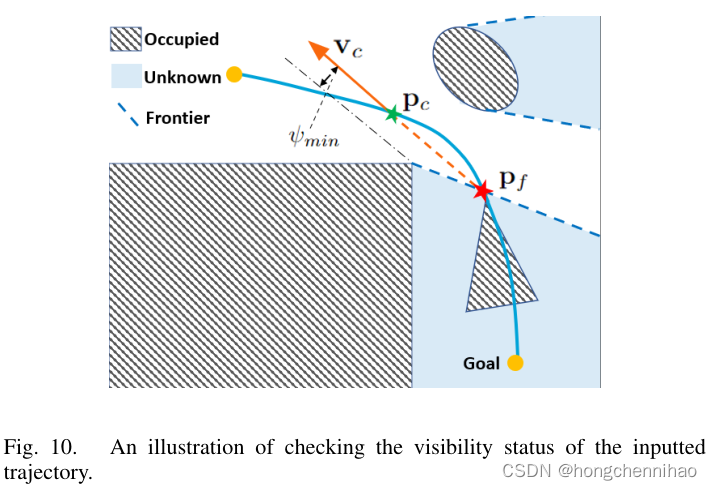
1)边界交叉点:由于未知环境只被部分观察到,在某一时刻
t
f
t_f
tf,轨迹
p
i
(
t
)
\mathbf{p}_i(t)
pi(t) 离开已知的自由空间进入未知空间。位置
p
f
=
p
i
(
t
f
)
{\bf p}_{f}\,=\,{\bf p}_{i}(t_{f})
pf=pi(tf) 应该被优先观察,理由如下有三:1,该点与未来飞行高度相关,因为它属于前往目标点的一个可能的轨迹。2,它可能对飞行造成危险,在最坏的情况下,它旁边可能有一个障碍物。3,相比于沿着
p
i
(
t
)
{\bf p}_i(t)
pi(t) 上的其他未知位置,该点将更早到达。因此,在 FrontierIntersection() 中,我们用离散的时间步长沿着
p
i
(
t
)
{\bf p}_i(t)
pi(t) 搜索,记录第一个未知点和相应的时间。
2)可见性度量:在飞行中,更希望
p
f
{\bf p}_f
pf 对
p
i
(
t
)
{\bf p}_i(t)
pi(t) 的一些靠前的位置可见。定量的角度,希望
p
f
{\bf p}_f
pf 的可见性等级
ψ
ψ
ψ 不低于期望的等级
ψ
m
i
n
ψ_{min}
ψmin,这样
p
f
{\bf p}_f
pf 是可见的,同时也能应对外部干扰。为衡量
p
f
{\bf p}_f
pf 可见性的可靠性,采用 [35,43] 中的方法,定义从位置
p
∈
R
3
\mathbf{p}\in\mathbb{R}^{3}
p∈R3 到
p
f
{\bf p}_f
pf 的可见性等级为:
ψ
(
p
,
p
f
)
=
min
q
∈
l
(
p
,
p
f
)
d
(
q
)
(
5
)
\psi\left(\mathbf{p}, \mathbf{p}_{f}\right)=\min _{\mathbf{q} \in l\left(\mathbf{p}, \mathbf{p}_{f}\right)} d(\mathbf{q}) \quad (5)
ψ(p,pf)=q∈l(p,pf)mind(q)(5)
ψ
(
p
,
p
f
)
\psi\left(\mathbf{p}, \mathbf{p}_{f}\right)
ψ(p,pf)表示线段
l
(
p
,
p
f
)
l({\bf p}, {\bf p}_f)
l(p,pf) 与障碍物之间的最小欧几里得符号距离。方程(5)的求值需要遍历
l
(
p
,
p
f
)
l({\bf p}, {\bf p}_f)
l(p,pf) 并检查每个点的欧几里得符号距离。幸运的是,我们的建图模块维护了一个由占用网格图导出的 ESDF,以支持轨迹优化(Sect.IV),因此可以在恒定时间内查询最小距离。
3)临界视图方向:我们感兴趣的是,是否可以从
p
i
(
t
)
{\bf p}_i(t)
pi(t) 上前面的位置看到
p
f
{\bf p}_f
pf,即在某一时刻
t
k
≤
t
f
t_{k}≤t_{f}
tk≤tf,
ψ
(
p
i
(
t
k
)
,
p
f
)
≥
ψ
m
i
n
\psi(\mathbf{p}_{i}(t_{k}),\mathbf{p}_{f})\geq\psi_{m i n}
ψ(pi(tk),pf)≥ψmin。最好的情况是对于所有的
t
≤
t
f
t ≤ t_f
t≤tf,可见性等级均高于
ψ
m
i
n
\psi_{m i n}
ψmin,这样就不需要对轨迹进行修改(3-4行)。然而,复杂环境中知道
t
c
t_c
tc 时刻之前都不能观察到
p
f
{\bf p}_f
pf,即在
t
<
t
c
t<t_c
t<tc 时,
ψ
(
p
i
(
t
k
)
,
p
f
)
<
ψ
m
i
n
\psi(\mathbf{p}_{i}(t_{k}),\mathbf{p}_{f}) < \psi_{m i n}
ψ(pi(tk),pf)<ψmin,而
t
≥
t
c
t≥t_c
t≥tc 时,
ψ
(
p
i
(
t
k
)
,
p
f
)
≥
ψ
m
i
n
\psi(\mathbf{p}_{i}(t_{k}),\mathbf{p}_{f}) ≥ \psi_{m i n}
ψ(pi(tk),pf)≥ψmin。在这里,视图方向
v
c
=
p
c
−
p
f
∣
∣
p
c
−
p
f
∣
∣
\mathbf{v}_{c}={\frac{\mathbf{p}c-\mathbf{p}f}{||\mathbf{p}c-\mathbf{p}f||}}
vc=∣∣pc−pf∣∣pc−pf,其中
p
c
=
p
i
(
t
c
)
{\bf p}_c = {\bf p}_i(t_c)
pc=pi(tc) 是一个临界视图方向,其中
ψ
(
p
i
(
t
)
ψ({\bf p}_i(t)
ψ(pi(t),
p
f
)
{\bf p}_f)
pf)刚好达到期望的水平
ψ
m
i
n
ψ_{min}
ψmin。在本例中,CriticalView() 报告
v
c
v_c
vc 和相应的位置
p
c
p_c
pc 和时间
t
c
t_c
tc。
迭代优化
最坏情况是一个未知的障碍物出现在
p
f
{\bf p}_f
pf 后面,阻碍轨迹。为了确保安全,我们改进了
p
i
(
t
)
{\bf p}_i(t)
pi(t),以便在最坏的情况下,四旋翼将能够通过采取一些单轴加速度不超过极限
a
m
a
x
a_{max}
amax 的机动来避免碰撞。首先检查
p
i
(
t
)
{\bf p}_i(t)
pi(t) 是否满足最坏情况下的安全标准(5-7行)。如果没有,将执行临界视图和安全反应距离约束(8-15行)。
1)最坏情况下的安全标准:如 sect.VI-A3 所述,初始
p
f
p_f
pf 将不能被稳定看见,知道
t
c
t_c
tc 在
p
c
{\bf p}_c
pc 上。假设在
p
c
{\bf p}_c
pc 处,速度是
v
c
v_c
vc,同时与
p
f
{\bf p}_f
pf 之间的距离是
d
c
f
d_{cf}
dcf。与[7]类似,检查下式是否成立:
v
c
2
/
2
a
m
a
x
≤
d
c
f
−
R
q
v_{c}^{2}/2a_{m a x}\leq d_{c f}\,-\,R_{q}
vc2/2amax≤dcf−Rq
意思是如果在
p
c
{\bf p}_c
pc 处四旋翼看到了一个障碍物,他可以减速直至在撞上
p
f
{\bf p}_f
pf 后的障碍物之前停下。
R
q
R_q
Rq 是四旋翼的大小和扰动的补偿项。如果不满足上式,则需要加入额外的约束来满足安全标准。
2)视图和安全约束:如果一开始就来不及避免碰撞,
p
f
{\bf p}_f
pf 应该在更早的阶段
t
s
<
t
c
t_s < t_c
ts<tc 被观察到,这样可以提前机动来避免碰撞。给出临界视图方向
v
c
{\bf v}_c
vc,约束可以表达为:
∣
∣
d
v
∣
∣
2
≤
δ
v
(
7
)
d
v
=
(
p
i
(
t
s
)
−
p
f
)
−
(
(
p
i
(
t
s
)
−
p
f
)
⋅
v
c
)
v
c
(
8
)
\left| |\mathbf{d}_{v} |\right|_{2}\;\le\;\delta_{v} \quad (7) \\ {\bf d}_{v}=({\bf p}_{i}(t_{s})-{\bf p}_{f})-\left(({\bf p}_{i}(t_{s})-{\bf p}_{f}\right)\cdot{\bf v}_{c} ){\bf v}_{c} \quad (8)
∣∣dv∣∣2≤δv(7)dv=(pi(ts)−pf)−((pi(ts)−pf)⋅vc)vc(8)

对此的解释是,在
t
s
t_s
ts 时,四旋翼应该已经到达可以看到
p
f
{\bf p}_f
pf 的射线
{
q
∣
q
=
p
f
+
λ
v
c
,
λ
>
0
}
\{{\bf q} | {\bf q}={\bf p}_f + \lambda {\bf v}_c,\lambda > 0\}
{q∣q=pf+λvc,λ>0}(如图 11 所示)。除了提前的观察,
p
r
(
t
s
)
{\bf p}_r(t_s)
pr(ts) 到
p
f
{\bf p}_f
pf 的距离应满足紧急制动距离:
d
s
f
=
∣
∣
p
i
(
t
s
)
−
p
f
∣
∣
2
≥
d
s
(
9
)
d_{s f}=\big||\mathrm{p}i(t_{s})-\mathrm{\bf p}_f||_{2}\geq\,d_{s} \quad (9)
dsf=
∣pi(ts)−pf∣∣2≥ds(9)
其中,
d
s
d_s
ds 是安全反应距离,它取决于在优化后的轨迹
p
r
(
t
s
)
:
d
s
=
v
s
2
/
2
a
m
a
x
+
R
q
{\bf p}_{r}(t_{s}) :d_{s}=v_{s}^{2}/2a_{m a x}+R_{q}
pr(ts):ds=vs2/2amax+Rq 上的速度
v
s
v_s
vs。但是,由于还没有得到优化后的轨迹,所以现阶段还不能得到
v
s
v_s
vs。引进一个迭代策略来解决这个问题。开始时,使用
[
t
0
,
t
f
]
[t_0,t_f]
[t0,tf] 之间
p
i
(
t
)
{\bf p}_i(t)
pi(t) 的平均速度作为
v
s
v_s
vs 的估计(8 行),
t
0
t_0
t0 是
p
i
(
t
)
{\bf p}_i(t)
pi(t) 的开始时间。之后使用视图和安全约束对轨迹进行优化(10-12 行)。优化后检查新的轨迹是否满足安全标准。如果不满足,则为估计速度
v
^
s
\hat{v}_{s}
v^s 增加一个略大于 1 的因子,然后重新优化(13-15 行)。该策略是完整的,因为它只会在安全标准满足之后才会终止。同时也会很快结束,因为沿着平滑轨迹的速度变化很小,在实际中,只需要一次或几次就可以得到一个
v
s
v_s
vs 的好的估计。
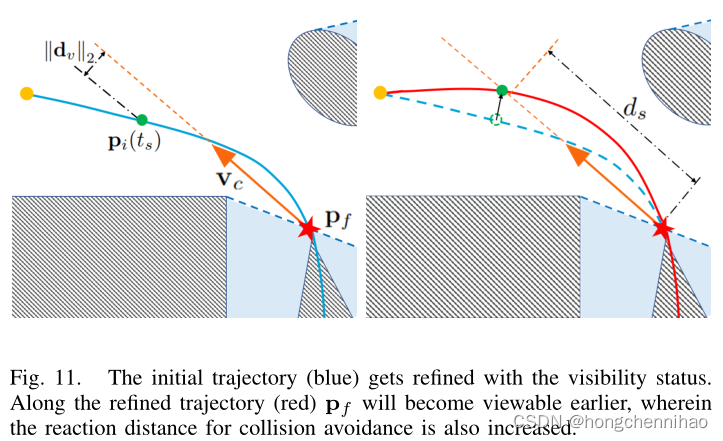
RefineTrajectory() 本质上是用新引入的视图和安全约束优化轨迹。将他们融入基于梯度的优化当中(Sect.IV -B),等式 7-9 通过惩罚函数进行软约束:
f
d
v
=
F
(
δ
v
,
∣
∣
d
v
∣
∣
2
)
f
d
s
,
f
=
F
(
∣
∣
p
i
(
t
s
)
−
p
f
∣
∣
2
,
d
s
)
f_{{\bf d}_{v}}=\mathcal{F}(\delta_{v},||{\bf d}_{v}||_{2}) \\ f_{{\bf d}_{s,f}}\,=\,{\mathcal F}(||{\bf p}_{i}(t_{s})\,-\,{\bf p}_{f}||_{2}\,,d_{s})
fdv=F(δv,∣∣dv∣∣2)fds,f=F(∣∣pi(ts)−pf∣∣2,ds)
F
(
)
\mathcal{F}()
F() 是惩罚函数(等式 3)。这些项的雅克比行列式是:
∂
f
d
v
∂
q
k
=
{
2
(
∥
d
v
∥
2
−
δ
v
)
d
v
T
∥
d
v
∥
2
(
I
−
v
c
v
c
T
)
∂
p
i
(
t
s
)
∂
q
k
,
∥
d
v
∥
2
>
δ
v
0
,
else
∂
f
d
s
f
∂
q
k
=
{
0
,
∥
p
i
(
t
s
)
−
p
f
∥
2
≥
d
s
2
(
∥
p
i
(
t
s
)
−
p
f
∥
2
−
d
s
)
p
i
(
t
s
)
T
∥
p
i
(
t
s
)
−
p
f
∥
2
∂
p
i
(
t
s
)
∂
q
k
,
else
\begin{array}{l} \frac{\partial f_{\mathbf{d}_{v}}}{\partial \mathbf{q}_{k}}=\left\{\begin{array}{c} \frac{2\left(\left\|\mathbf{d}_{v}\right\|_{2}-\delta_{v}\right) \mathbf{d}_{v}^{\mathrm{T}}}{\left\|\mathbf{d}_{v}\right\|_{2}}\left(\mathbf{I}-\mathbf{v}_{c} \mathbf{v}_{c}^{\mathrm{T}}\right) \frac{\partial \mathbf{p}_{i}\left(t_{s}\right)}{\partial \mathbf{q}_{k}},\left\|\mathbf{d}_{v}\right\|_{2}>\delta_{v} \\ 0, \text { else } \end{array}\right. \\ \frac{\partial f_{\mathbf{d}_{s f}}}{\partial \mathbf{q}_{k}}=\left\{\begin{array}{c} 0 \qquad,\left\|\mathbf{p}_{i}\left(t_{s}\right)-\mathbf{p}_{f}\right\|_{2} \geq d_{s} \\ \frac{2\left(\left\|\mathbf{p}_{i}\left(t_{s}\right)-\mathbf{p}_{f}\right\|_{2}-d_{s}\right) \mathbf{p}_{i}\left(t_{s}\right)^{\mathrm{T}}}{\left\|\mathbf{p}_{i}\left(t_{s}\right)-\mathbf{p}_{f}\right\|_{2}} \frac{\partial \mathbf{p}_{i}\left(t_{s}\right)}{\partial \mathbf{q}_{k}}, \text { else } \end{array}\right. \end{array}
∂qk∂fdv={∥dv∥22(∥dv∥2−δv)dvT(I−vcvcT)∂qk∂pi(ts),∥dv∥2>δv0, else ∂qk∂fdsf={0,∥pi(ts)−pf∥2≥ds∥pi(ts)−pf∥22(∥pi(ts)−pf∥2−ds)pi(ts)T∂qk∂pi(ts), else
这里
q
k
{\bf q}_k
qk 个 B 样条控制点与
p
i
(
t
s
)
{\bf p}_i(t_s)
pi(ts) 相关联。该优化使代价函数最小化:
f
r
=
λ
s
f
s
+
λ
c
f
c
+
λ
d
(
f
v
+
f
a
)
⏟
f
p
2
+
λ
r
(
f
d
v
+
w
r
f
d
s
f
)
f_{r}=\underbrace{\lambda_{s} f_{s}+\lambda_{c} f_{c}+\lambda_{d}\left(f_{v}+f_{a}\right)}_{f_{p 2}}+\lambda_{r}\left(f_{\mathbf{d}_{v}}+w_{r} f_{\mathbf{d}_{s f}}\right)
fr=fp2
λsfs+λcfc+λd(fv+fa)+λr(fdv+wrfdsf)
其中
f
p
2
f_{p2}
fp2 与等式 2 完全相同。注意,对不同的
t
s
t_s
ts 应用约束会产生不同的结果。然而,将
t
s
t_s
ts 纳入优化以找到最佳的值会使得问题太困难难以快速解决。
简单起见,将
t
s
t_s
ts 确定为使得初始
p
i
(
t
)
{\bf p}_i(t)
pi(t) 的
f
d
v
+
w
r
f
d
s
f
f_{{\bf d}_{v}}+w_{r}f_{{\bf d}_{s f}}
fdv+wrfdsf 最小的时间,使用它来进行优化(11-12 行)。从数量上讲,所选的
t
s
t_s
ts 会使得对约束的违反最小化,而且在
t
s
t_s
ts 出执行约束也要求对
p
i
(
t
)
{\bf p}_i(t)
pi(t) 的修改最小,这是一个不错的选择。
偏航角规划
通常四旋翼都只有有限的传感器视场角。为提高飞行安全性,规划偏航角的轨迹来主动观察周围环境。由最近的两步四旋翼运动规划方法 [4]-[8,15] 启发,将偏航角规划分解为一个图搜索问题和一个轨迹优化问题。
A.图搜索
1)问题模型:对图搜索问题建模,沿着优化后的轨迹寻找一个平衡了平滑度和对未知空间信息获取(IG, detailed in Sect.VII-A2)的偏航角序列
Ξ
:
=
{
ξ
0
,
ξ
1
,
⋯
,
ξ
M
}
\Xi:=\left\{\xi_{0}, \xi_{1}, \cdots, \xi_{M}\right\}
Ξ:={ξ0,ξ1,⋯,ξM}。给定四旋翼飞机的轨迹
p
r
(
t
)
{\bf p}_r(t)
pr(t)(Sect.VI),选择一组沿轨迹均匀分布在
{
t
0
,
t
1
,
.
.
.
,
t
M
}
\{t_0, t_1,..., t_M \}
{t0,t1,...,tM}的位置
p
r
,
i
,
i
∈
[
0
,
1
,
.
.
.
,
M
]
{\bf p}_r,i, i∈ [0, 1,..., M]
pr,i,i∈[0,1,...,M]。在
p
i
{\bf p}_i
pi 预计
i
=
0
i = 0
i=0,其中偏航角已经由当前四旋翼的状态所确定,创建了几个图节点
n
i
,
j
,
j
∈
[
0
,
1
,
.
.
.
,
J
]
n_{i,j},j \in [0,1,...,J]
ni,j,j∈[0,1,...,J],每个节点不同的角度和当前状态
(
P
r
,
i
,
ξ
i
,
j
)
\left(\mathbf{P}_{r,i},{\xi}_{i,j}\right)
(Pr,i,ξi,j) 下的 IG
g
i
,
j
g_{i,j}
gi,j 相关联。为与相邻位置相关联的每对节点
n
i
,
j
1
,
n
i
+
1
,
j
2
n_{i,j_1},n_{i+1,j_2}
ni,j1,ni+1,j2 创建一条从
n
i
,
j
1
n_{i,j_1}
ni,j1 到
n
i
+
1
,
j
2
n_{i+1,j_2}
ni+1,j2 的边。这个过程会创建一个如图 12 的有向图。为找到一个使 IG 和平滑度最大化的偏航角序列,在图中搜索一条代价
c
(
Ξ
)
c(\Xi)
c(Ξ) 最小的路径,这可以通过 Dijkstra 算法有效求解:
c
(
Ξ
)
=
∑
i
=
1
M
{
−
g
i
,
j
i
+
μ
(
ξ
i
,
j
i
−
ξ
i
−
1
,
j
i
−
1
)
2
}
c(\Xi)=\sum_{i=1}^M\left\{-g_{i, j_i}+\mu\left(\xi_{i, j_i}-\xi_{i-1, j_{i-1}}\right)^2\right\}
c(Ξ)=i=1∑M{−gi,ji+μ(ξi,ji−ξi−1,ji−1)2}
其中,
μ
\mu
μ 用来调整平滑度的权重。

2)信息增益:采用与 [44] 中类似的方法,将潜在的 IG 估计为符合相机模型且可见的(未被已占用体素阻挡)的未建图体素的数量。然而,原方法对每个相机视场角内的体素都进行光线投射来验证其可见性,这对在线功能来说代价高昂。因此对其进行了几个房间的调整以适应实时规划:(a)如[38]中所示,对 FOV 内的体素进行二次采样使其接近实际增益,这会导致微小的误差但会大大减少运行时间;(b)并行地估计不同
ξ
i
,
j
ξ_{i,j}
ξi,j 的增益;(c)借用[45]中的技术来避免重复投射。如图 13(a) 所示,注意到评估不同
ξ
i
,
j
ξ_{i,j}
ξi,j 中的一个位置
p
r
,
i
{\bf p}_{r,i}
pr,i,许多体素位于重叠区域并且被检查了不止一次可见性。为了避免不必要的重复,当每个体素被首次检查后即存储它的可见性,在后续检查检查时可直接查询。这种方式可以将 IG 的整体评估时间至少降低两个数量级。
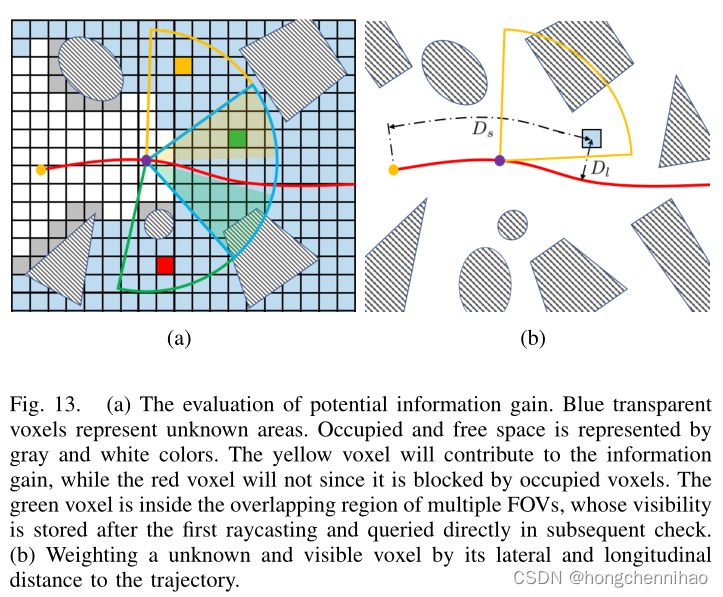
在[44]探索的背景下,每个体素都对四旋翼贡献相同的 IG,确保所有的空间都可以被传感器均匀的覆盖到。但是对于点到点的导航,目标不是全覆盖,而是倾向于与飞行有关的空间。实际上,靠近轨迹和当前位置的体素对飞行有更高的影响。因此,采用下式对一个以
m
{\bf m}
m 为中心的可见体素的 IG 贡献
I
g
I g
Ig 进行偏置:
I
g
(
m
)
=
exp
{
−
w
l
D
l
(
m
,
p
r
(
t
)
)
−
w
s
D
s
(
m
,
p
r
(
t
)
)
}
I g({\mathbf{m}})=\exp{\{-w_{l}\,D_{l}({\mathbf{m}},{\mathbf{p}}_{r}(t))}-w_{s}\,D_{s}({\mathbf{m}},{\mathbf{p}}_{r}(t))\}
Ig(m)=exp{−wlDl(m,pr(t))−wsDs(m,pr(t))}
其中,
D
l
(
m
,
p
r
(
t
)
)
D_{l}({\mathbf{m}},{\mathbf{p}}_{r}(t))
Dl(m,pr(t)) 和
D
s
(
m
,
p
r
(
t
)
)
D_{s}({\mathbf{m}},{\mathbf{p}}_{r}(t))
Ds(m,pr(t)) 分别代表到轨迹
p
r
(
t
)
{\bf p}_r(t)
pr(t) 的横向和纵向距离(图 13(b))。
B.偏航角优化
给定在图中搜索到的最优路径
Ξ
\Xi
Ξ,计算平滑,动态可行的偏航角
ϕ
(
t
)
\phi(t)
ϕ(t) 轨迹,并通过连续的角度
ξ
i
,
j
ξ_{i,j}
ξi,j。将
ϕ
(
t
)
\phi(t)
ϕ(t) 参数化为带有控制点
Φ
:
=
{
ϕ
c
,
0
,
ϕ
c
,
1
,
⋅
⋅
⋅
,
ϕ
c
,
N
c
}
\Phi\;:=\;\{\phi_{c,0},\phi_{c,1},\cdot\cdot\cdot,\phi_{c,N_{c}}\}
Φ:={ϕc,0,ϕc,1,⋅⋅⋅,ϕc,Nc} 和节点跨度
δ
t
ϕ
\delta t_{\phi}
δtϕ 的 B 样条。通过这种方式,可以使用凸包特性来确保动态可行性[15]。问题可以归纳为:
arg
min
Φ
∫
t
0
t
M
(
ϕ
¨
˙
(
t
)
)
2
d
t
+
γ
1
∑
i
=
0
M
(
ϕ
(
t
i
)
−
ξ
i
)
2
+
γ
2
{
∑
j
=
0
N
c
−
1
F
(
ϕ
˙
max
,
∣
ϕ
˙
c
,
j
∣
)
+
∑
j
=
0
N
c
−
2
F
(
ϕ
¨
max
,
∣
ϕ
¨
c
,
j
∣
)
}
\begin{array}{l}\underset{\Phi}{\arg \min } \int_{t_{0}}^{t_{M}}(\dot{\ddot{\phi}}(t))^{2} d t+\gamma_{1} \sum_{i=0}^{M}\left(\phi\left(t_{i}\right)-\xi_{i}\right)^{2} \\+\gamma_{2}\left\{\sum_{j=0}^{N_{c}-1} \mathcal{F}\left(\dot{\phi}_{\max },\left|\dot{\phi}_{c, j}\right|\right)+\sum_{j=0}^{N_{c}-2} \mathcal{F}\left(\ddot{\phi}_{\max },\left|\ddot{\phi}_{c, j}\right|\right)\right\}\end{array}
Φargmin∫t0tM(ϕ¨˙(t))2dt+γ1∑i=0M(ϕ(ti)−ξi)2+γ2{∑j=0Nc−1F(ϕ˙max,
ϕ˙c,j
)+∑j=0Nc−2F(ϕ¨max,
ϕ¨c,j
)}
其中,第一项代表平滑度,第二项代表使
ϕ
(
t
)
\phi(t)
ϕ(t) 通过
Ξ
\Xi
Ξ 的软路径点约束。最后两项是动态可行性的软约束,其中
ϕ
˙
c
,
j
\dot{\phi}_{c, j}
ϕ˙c,j 和
ϕ
¨
c
,
j
\ddot{\phi}_{c, j}
ϕ¨c,j 是角速度和加速度的 B 样条控制点:
ϕ
˙
c
,
j
=
ϕ
c
,
j
+
1
−
ϕ
c
,
j
δ
t
ϕ
,
ϕ
¨
c
,
j
=
ϕ
c
,
j
+
2
−
2
ϕ
c
,
j
+
1
+
ϕ
c
,
j
δ
t
ϕ
2
\dot{\phi}_{c,j}=\frac{\phi_{c,j+1}-\phi_{c,j}}{\delta t_{\phi}},\;\;\;\ddot{\phi}_{c,j}=\frac{\phi_{c,j+2}-2\phi_{c,j+1}+\phi_{c,j}}{\delta t_{\phi}^{2}}
ϕ˙c,j=δtϕϕc,j+1−ϕc,j,ϕ¨c,j=δtϕ2ϕc,j+2−2ϕc,j+1+ϕc,j
由于 B 样条的凸包特性,在控制点不超过动态极限
ϕ
˙
m
a
x
\dot{\phi}_{max}
ϕ˙max 和
ϕ
¨
m
a
x
\ddot{\phi}_{max}
ϕ¨max 的情况下,可以保证整个轨迹是可行的。















 1654
1654











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









