






4 月 29 号凌晨,阿里巴巴发布了新一代通义千问 Qwen3 模型,并同步开源。(总是半夜搞大动作!)模型发布后,科技领域、AI 领域的知乎答主们第一时间体验该模型,并纷纷给出了自己的分析和思考,一起来看看吧~
阿里通义千问 Qwen3 系列模型正式发布,该模型有哪些技术亮点?

简单说结论——可以加显卡了,这就是可以本地部署的最强开源写代码大模型。

****|****** *答主:****Karminski-牙医*****
Qwen3 写代码能力测试来啦!
简单说结论——可以加显卡了,这就是可以本地部署的最强开源写代码大模型。
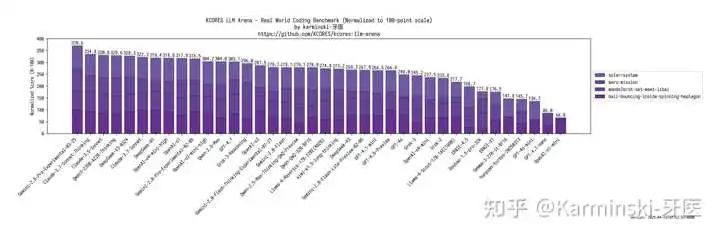
来看 KCORES LLM Arena 的测试结果:
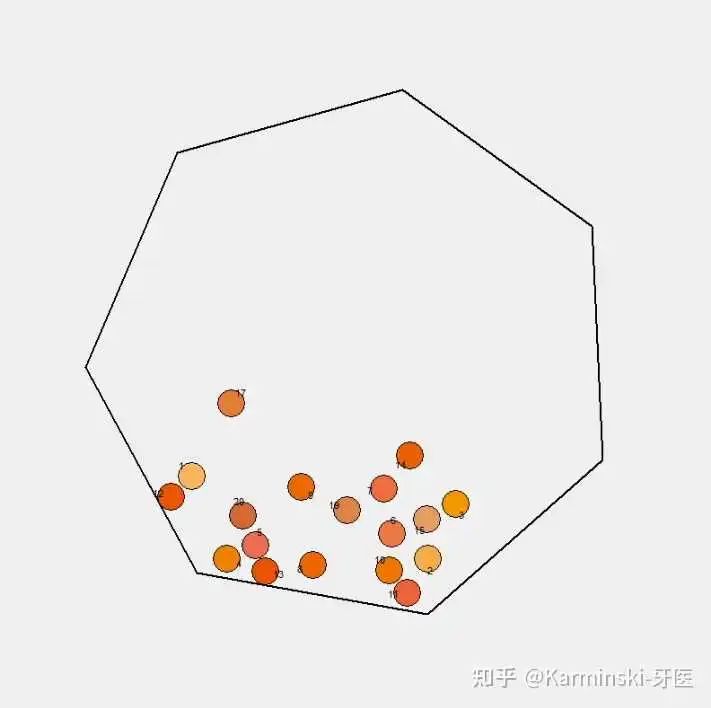
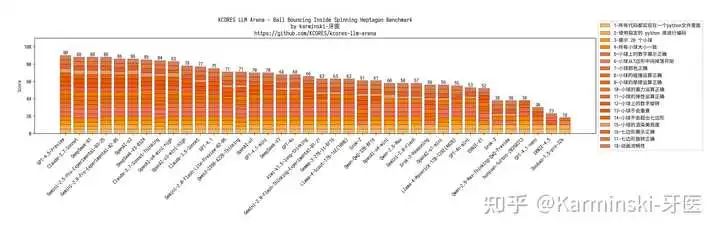
20 小球七边形测试结果:
主要问题出现在小球掉出了七边形,以及小球摩擦极其微弱判定为无摩擦的扣分,但整体实现效果仍然很好。得分 71 分,与 Gemini-2.0-Flash 相当。
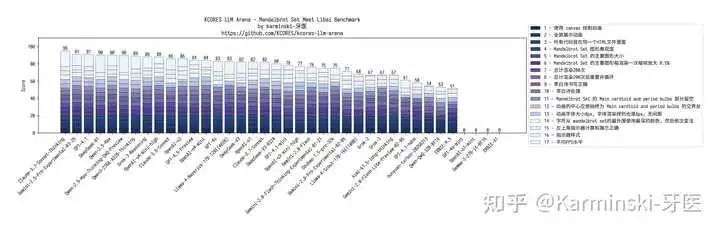
mandelbrot-set-meet-libai 测试结果:
主要问题出现在渲染过大以及颜色弄反了造成的扣分。但是渲染性能和绘制准确度都很好。得分 89 分,与 Qwen2.5-Max-Thinking-QwQ-Preview 相当。

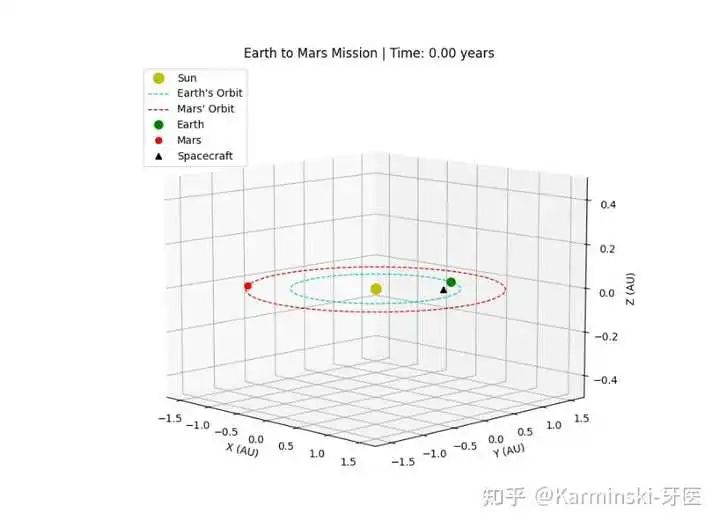
火星任务测试结果:
表现非常好,发射和返回窗口虽然有误差但是都小于 50% ,要知道很多模型正是因为完全不知道从火星返回也需要窗口因此丢了很多分数。得分 49 分,仅次于Gemini-2.5-Pro。

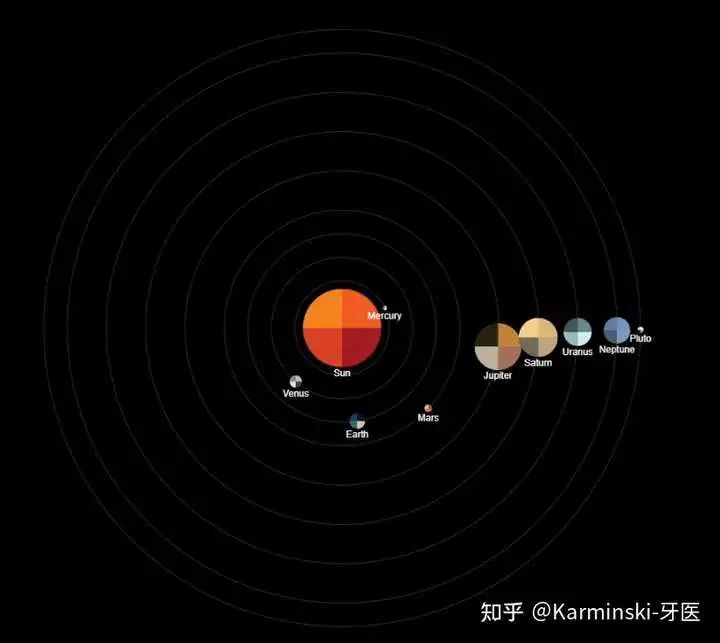
太阳系九大行星测试结果:
这个渲染得就毫无亮点可言,也没土星环,也没华丽的星球效果。但是,没有犯致命的错误,得分 85 分,与 OpenAI-o4-mini 相当。
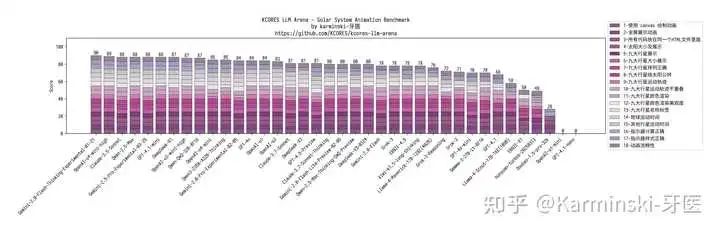
看上去没有任何一个结果特别强,但是!每个测试都发挥很稳定,这导致最终得分特别高,得分 329.6 分,排在了排行榜的第四名!是目前开源模型第一名!
Qwen3 可以在端侧实现足够强的推理能力。
****|****** ****答主:****桔了个仔
亲自在多个环境部署了 Qwen3 的一些模型,给我感觉:确实不一样,不愧是大版本更新。
在开始讲部署前以及测试结果之前,先给读者大概介绍下 Qwen3 吧。
Qwen3 是国内首个混合推理模型。说个题外话,我个人认为,今年大模型其中一个发展方向,就是混合推理模型,例如 Claude 3.7 Sonnet,Gemini 2.5 Flash,都是混合推理模型,都展示出了优秀的性能。不知道大家有没读过丹尼尔·卡尼曼的《思考,快与慢》这本书,**所谓混合推理模型,其实就是参考了人类的思维方式,简单问题快速响应,复杂问题认真推理,模型自己根据问题难度,自主选择快思考还是慢思考方式。**这样能优化资源利用,防止对简单问题过度推理。当然,要让 Qwen3 强行推理也是能做到的,可以通过设置 enable_thinking=True 开启推理模式。
这次 Qwen3 发布了两种模型( Dense 和 MoE ),共 8 个尺寸,其中 Dense 模型包括 0.6B、1.7B、4B、8B、14B、32B 六种参数,而两款 MoE 模型分别是 Qwen3-30B-A3B(总参数量 30B,激活参数仅 3B)和旗舰版 Qwen3-235B-A22B(总参数量 235B,激活参数仅 22B)。
根据技术报告,Qwen3 系列的性能还是强劲的,在数学、代码、推理等方面全面提升,直接登顶全球最强开源模型。根据他们谦虚的说法是,在各同尺寸开源模型里面,它都做到了 SOTA(注:全称「state-of-the-art」,用于描述机器学习中取得某个任务上当前最优效果的模型)。但实际上,面对很多比其尺寸大的模型,其性能也是不输的。例如Qwen3-30B-A3B,比GPT-4o,还有自家参数更大的Qwen2.5-72B-Instruct 都强不少。
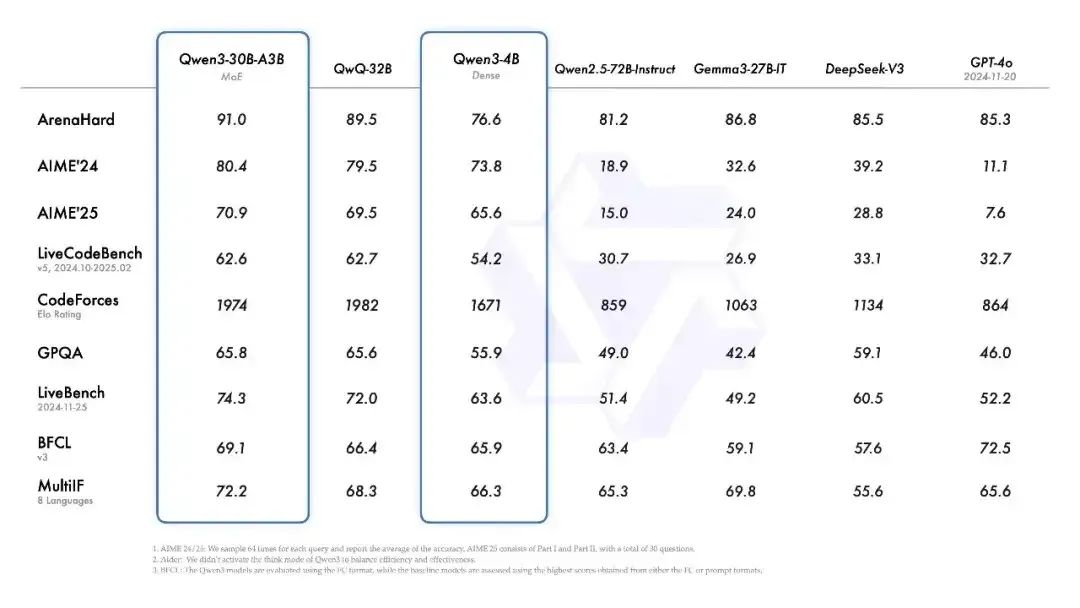
尤其是 Qwen3-235B-A22B,做到了开源模型性能新高,各项得分比 O1 和 R1 都高。
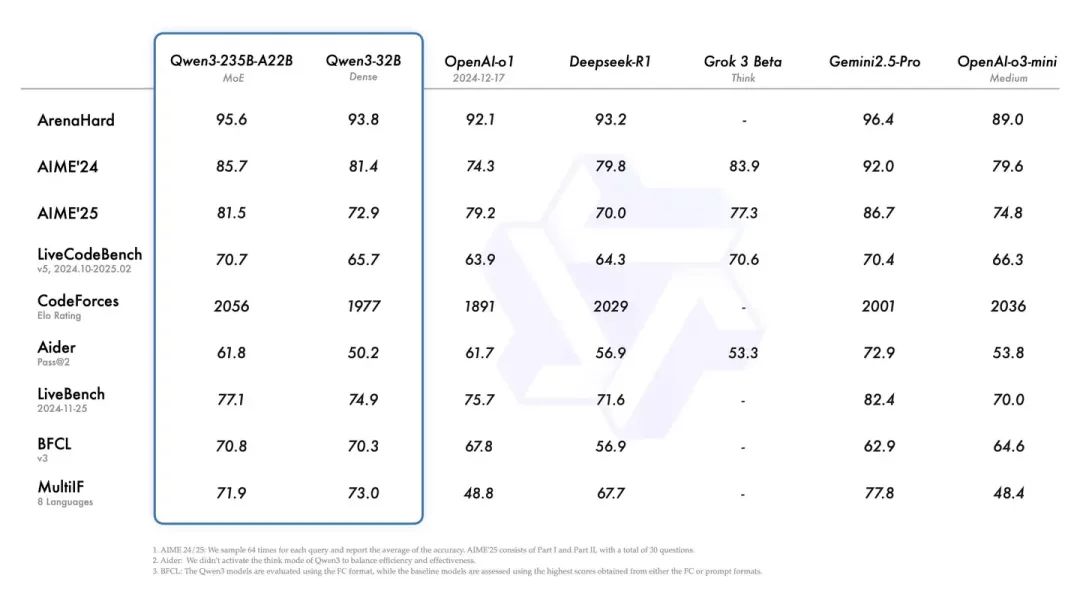
另外,推理成本方面,由于 Qwen3 系列的小尺寸模型比很多上一代的大尺寸模型还好,因此,性价比更划算,意味着可以用相同成本使用更好的模型,或者用更低成本使用和以前能力相当的模型。
除此之外,Qwen3 继续延续其优秀的多语言支持传统,支持 119 种语言和方言。这也是为啥 Qwen 在国际开发者社区受欢迎的原因之一。
世界第一梯队并非遥不可及。
****|****** ****答主:****toyama nao
距离 Qwen2.5 发布其实只过了 3 个月,距离 QwQ-32B 发布更是 1 个月多一点。然而大模型在 3 个月内风起云涌,流光溢彩。曾经进入第二梯队前列的 Qwen2.5 max 滑落第三梯队末尾。曾经一鸣惊人的 DeepSeek R1 也变得「平淡无奇」。甚至一个月前平地一声雷的 Gemini 2.5 Pro 也好像并非遥不可及,这不,Qwen3就站在了业界第一梯队的门槛上。
本次 Qwen3 超大杯虽然极限分数进入第一梯队,但更体现普通用户体感的中位分还停留在第二梯队,甚至 Qwen3 无论超大杯的 235B 还是 30B ,其最佳成绩都只在 3pass 中出现 1 次,其他 2pass 是思路完全不对或者极低分。而上位的 Gemini 2.5Pro 中位分只低 3%,O4 mini 只低 4% 。
这次 Qwen3 带来的系列模型相比前作,模型更丰富,超大杯和大杯都有推理和非推理可选,这也给测评带来了双倍的工作量。
国产模型和美国差距还是有的,但前途我认为是光明的。
****|****** ***答主:*风止于林
如果按照 sota 模型发布时间作为技术的时间,整体技术大概相当于今年 3 月初的水平,在 open AI 和谷歌没有新模型出现的情况下,考虑到发布的延后性,比 gemini 和 open AI 刚好落后两个月。感觉还是有一定可取之处的,毕竟开源嘛。整体水平处于我预期之内吧。对比一下 llama4 就知道了。
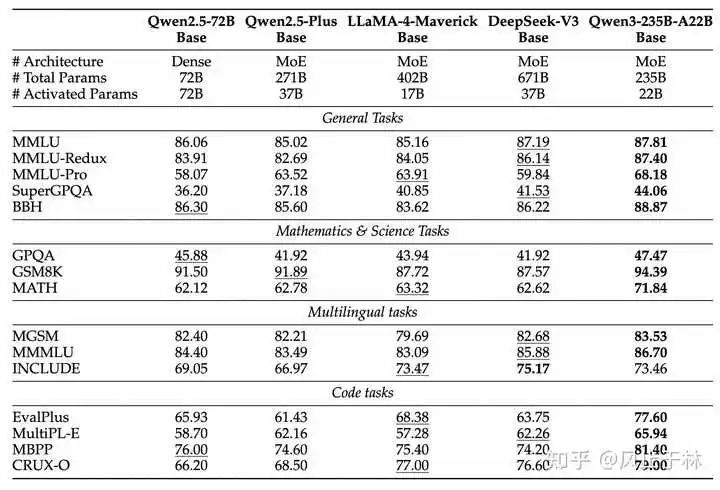
Qwen chat app 上也更新了 Qwen3 模型,还增加了一个思考长度功能。
总之,作为开源模型目前是最先进的,但打O3和 gemini2.5pro 还是等等看 R2 吧。豆包前几天刚更新,也仅仅是稍稍超过 deepseek R1 的水平,目前国内三家里垫底。所以来看,国产模型和美国差距还是有的,但前途我认为是光明的。
简单来说,从技术堆料的角度看,Qwen 3 不输国际一线水平,尤其在中文优化、复杂推理、推理效率等方面做了不少针对性打磨(核心亮点在于稀疏 MoE 架构、混合思考机制、动态 RoPE 与高效注意力机制)。比之前的国产开源模型有明显进步,但从开箱即用到真正规模化落地,的确还有距离。
从技术堆料的角度看,Qwen 3 不输国际一线水平,尤其在中文优化、复杂推理、推理效率等方面做了不少针对性打磨(核心亮点在于稀疏 MoE 架构、混合思考机制、动态 RoPE 与高效注意力机制)。比之前的国产开源模型有明显进步,但从开箱即用到真正规模化落地,的确还有距离。
虽然说 Qwen 3 给国产开源模型再次注入一针强心剂,但更长远的竞争,注定不仅仅是发布一组参数漂亮的模型,而是看谁能真正构建起稳定、开放、可信赖的开发者友好生态。就像在知乎社区里的讨论,这一年多也开发者关注点也逐渐从「跑分」转向「可用性」、「落地成本」,从热闹走向理性。另一悬念在于,Qwen 3 会领先 DeepSeek 多少天呢?🤔
大模型岗位需求
大模型时代,企业对人才的需求变了,AIGC相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把全套AI技术和大模型入门资料、操作变现玩法都打包整理好,希望能够真正帮助到大家。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
零基础入门AI大模型
今天贴心为大家准备好了一系列AI大模型资源,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
1.学习路线图




如果大家想领取完整的学习路线及大模型学习资料包,可以扫下方二维码获取

👉2.大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。(篇幅有限,仅展示部分)

大模型教程
👉3.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(篇幅有限,仅展示部分,公众号内领取)

电子书
👉4.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(篇幅有限,仅展示部分,公众号内领取)

大模型面试
**因篇幅有限,仅展示部分资料,**有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
**或扫描下方二维码领取 **

















 643
643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









