







目录
摘要
抗生素耐药性构成全球威胁,一项战略是开发新一代抗菌素,天然抗菌肽(AMPs)是公认的模板,其中一些已经在临床使用。为了加速新抗生素的发现,从各种生物体的基因组测序中预测新的抗菌肽是有用的。抗菌肽数据库(APD)提供了第一个经验肽预测程序。它还促进了第一批机器学习算法的测试。本文概述了amp的机器学习预测。大多数预测因子,如AntiBP、CAMP和iAMPpred,都涉及对抗菌活性的单标签预测,这种类型的预测已经扩展到抗真菌、抗病毒、抗生物膜、抗结核、溶血和抗炎肽。在APD中注释的amp的多种功能作用也使多标签预测(iAMP-2L、MLAMP和AMAP)成为可能,包括抗菌、抗病毒、抗真菌、抗寄生虫、抗生物膜、抗癌、抗hiv、抗疟疾、杀虫、抗氧化、趋化、杀精活性和蛋白酶抑制活性,在预测中还考虑了肽的翻译后修饰、3D结构和微生物物种特异性信息。文章比较了机器学习预测的amp的重要氨基酸与天然肽中频繁出现的残基。
1. 引言
抗生素的发现和生产挽救了数百万人的生命,它被认为是二十世纪人类最伟大的成就之一,然而病原体会进行反击,导致传统抗生素的效力降低。为减少毒性作用,细菌可以将药物泵出细胞,通过突变降低药物对特定靶点的亲和力,并通过蛋白酶降解抗生素。在各种多重耐药性(MDR)微生物中,ESKAPE病原菌(粪肠球菌、金黄色葡萄球菌、肺炎克雷伯菌、鲍曼不动杆菌、铜绿假单胞菌和肠杆菌)占医院感染的90%[1]。还有其他新出现的耐药病原体,包括人类免疫缺陷病毒1型(HIV-1)、SARS-CoV2、埃博拉病毒、寨卡病毒、耐药细菌结核分枝杆菌、沙门氏菌、念珠菌、淋病奈瑟菌和艰难梭菌。如果不采取行动,预计到2050年每年死亡人数将达到1000万。为应对这一挑战,一项基本战略是开发能够消除这些耐多药病原体的新一代抗微生物药物。
抗菌肽(AMPs)被认为是传统非肽抗生素的替代品,本文的重点是抗菌肽的预测:
第一,AMP简介;
第二,AMP主要预测方法;
第三,描述用于预测的数据集和机器学习算法;
第四,讨论了AMP的主要机器学习预测;
第五,比较机器学习在同一平台上的预测结果的准确性;
第六,概述了可能加速计算机辅助新型抗菌药物发现的其他预测;
第七,总结了AMP预测的主要成就和局限性,并讨论了未来的发展方向。
2. 先天免疫抗菌肽
天然抗菌肽是先天免疫系统的重要组成部分,通常是基因编码的,可以组成性地表达以保护某些生态位或诱导应对入侵的病原体。根据抗菌肽数据库(APD, https://aps.unmc.edu),目前,74%的肽来自动物,11.2%和11.1%分别来自细菌和植物。大多数天然amp(88%)是阳离子,只有一小部分(6%)是阴离子。阴离子amp,如已在临床使用的达托霉素,可能需要金属才能发挥活性[12]。在APD中,大多数amp具有10%至70%之间的疏水含量(Pho),只有约1%的此类肽具有非常高(>70%)或非常低(<10%)的Pho。从长度上看,目前APD3中88%的肽短于50个氨基酸。APD3中所有amp(截至2021年1月为3257)的平均长度为33.2,平均净电荷为+3.3。出现频率最高的氨基酸(>8%)是亮氨酸(L)、甘氨酸(G)和赖氨酸(K),而出现频率最低的氨基酸(<2%)包括蛋氨酸(M)和色氨酸(W)。
天然AMPs在不同结构、活性和来源基团中氨基酸(组成)特征的变化已在其他文章制成表格。
Wang G (2020) The antimicrobial peptide database provides a platform for decoding the design principles of naturally occurring antimicrobial peptides. Protein Sci. 29(1):8–18. [PubMed: 31361941]
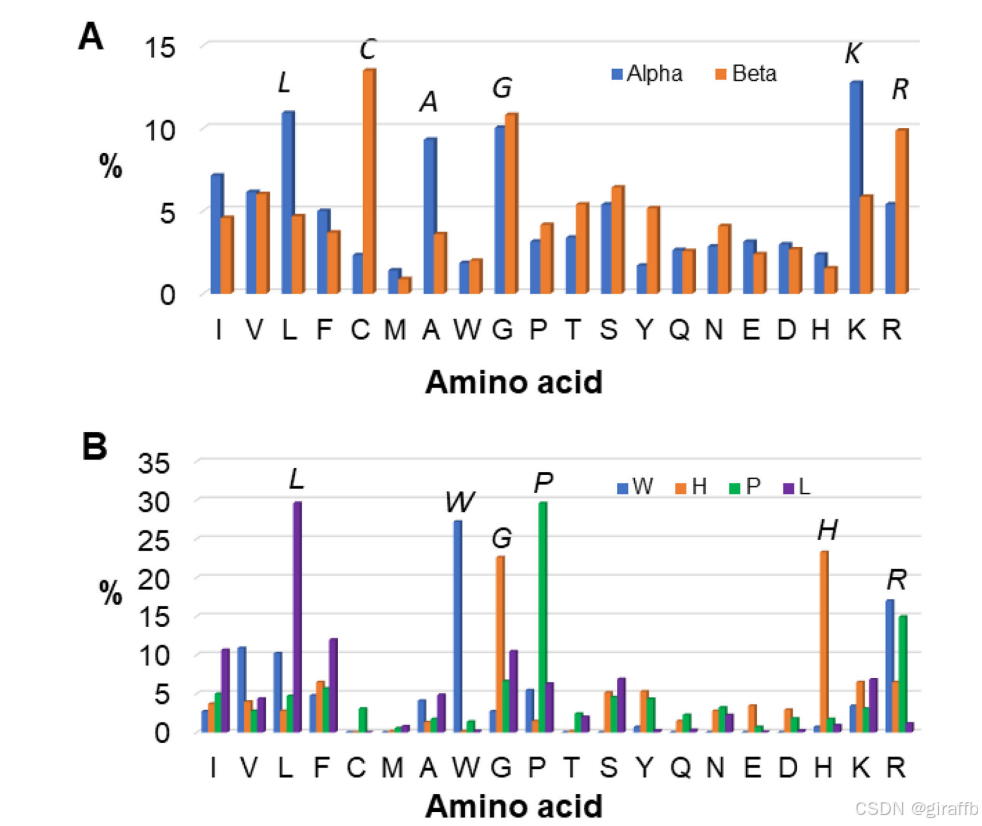
上图显示了已知α-螺旋肽、β-折叠肽、富含色氨酸(Trp-rich)、富含组氨酸(His-rich)、富含脯氨酸(Pro-rich)和富含亮氨酸(Leu-rich)的肽段的氨基酸特征。很明显,这些特征取决于APD中一组肽段的氨基酸组成,然而肽的氨基酸序列显然也在决定肽的结构和活性方面发挥作用。另一个重要的参与者是肽序列的翻译后修饰(如酰胺化、糖基化、卤化、羟基化和环化),截至2020年10月,目前的APD3中注释了24种修饰。通常,由于形成了经典的两亲螺旋结构,阳离子amp靶向阴离子细菌膜,然而这些肽也可以攻击其他目标如细菌细胞壁和核糖体,同时攻击一个以上的目标使细菌难以对抗菌肽产生耐药性。除了杀死细菌和抑制生物膜外,AMPs还具有其他功能作用,从病原体毒素中和、伤口愈合到宿主免疫调节等等。
3. 抗菌肽预测方法综述
大多数天然抗菌肽是用经典的分离和表征方法鉴定的,这种多肽鉴定程序既费力又费时。一种替代方法是基于当前肽知识和许多生物体的测序基因组,通过计算机预测amp,这些预测方法根据编程中考虑的信息分为五类:(1)成熟肽(即AMPs)(2)前肽(3)成熟肽和前肽(4)加工酶,(5)基因组背景。
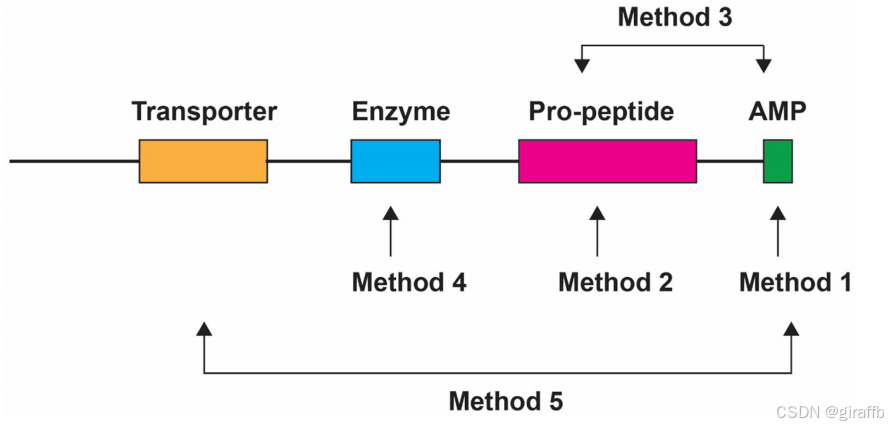
一些AMPs在成熟肽之前具有保守的前序列结构域,这种保守的序列模式成为从哺乳动物、鱼类、爬行动物、鸟类和两栖动物的测序基因组中鉴定未鉴定的cathelicidin的一种方法。同样,从细菌中发现细菌素已经从高度保守的加工酶扩展到转运蛋白和整个基因簇,已经建立了BAGEL、antiSMASH和BACIIα等计算机程序来鉴定细菌素。在聚类amp时,有时会考虑前序列和成熟序列,这可能是由于当时可用的特定数据集的性质。最广泛探索的预测信息是成熟肽,序列模式如多个二硫键被用于识别植物、牛、小鼠和人类中的防御素amp,在这些肽中也发现了一个GXC γ-核心基序,并用于AMP预测。
amp数据库的建立极大地促进了基于计算机的设计和预测方法的发展,下表提供了amp 数据库。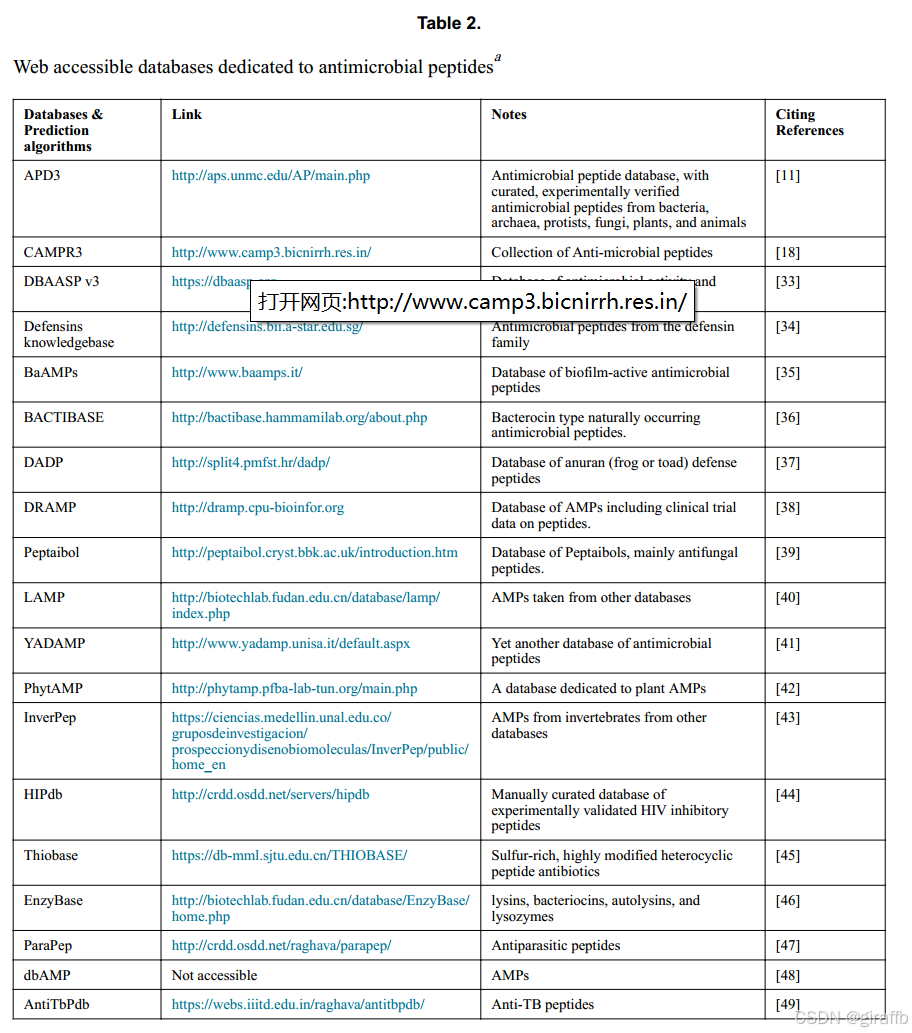
在2004年,APD和ANTIMIC同时在《核酸研究》期刊的数据库特刊中发布。APD专注于成熟AMP的结构和活性,广受AMP领域的认可和使用。从那时起,随着范围的变化或额外细节的增加,建立了更多的数据库。关于这些数据库的系统评估已在其他地方描述过。由于APD在AMP领域中的示范作用,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1459
1459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









