









作者及本文框架
作者
Cewu Lu, Jiaya Jia, Chi-Keung Tang
其中一作、三作来自香港科技大学,二作来自港中文。一作在2013年从港中文phd毕业,现在是香港科技大学的reasearch fellow。二作在图像去模糊方面颇有研究,其个人主页上也有丰富的代码,基本上由他作为一作或者是他的组里发的论文都有代码可供下载。不过比较可惜的是,虽然本文的效果非常好,但是他的主页上只有本文的PDF,没有代码下载。
本文框架
本文解决的问题是,在已经由kinect提取出来骨架点的坐标的基础上,对于RGB-D视频序列中的动作进行识别和定位。动作识别指的是,给定一些视频,需要给出视频中的人做了什么支l作。动作定位是指,给定一些视频和动作的名称,当视频中出现了相应的动作时,需要给出相应动作的起始和终止时间点。
本文的特征提取部分是利用了
τ
检验的思想,并作了一定修正。这个在后文详述。
活动距离(activity Range)测定
这里的activity range指的是人所在的深度(距离kinect)范围。整个流程如下图所示:
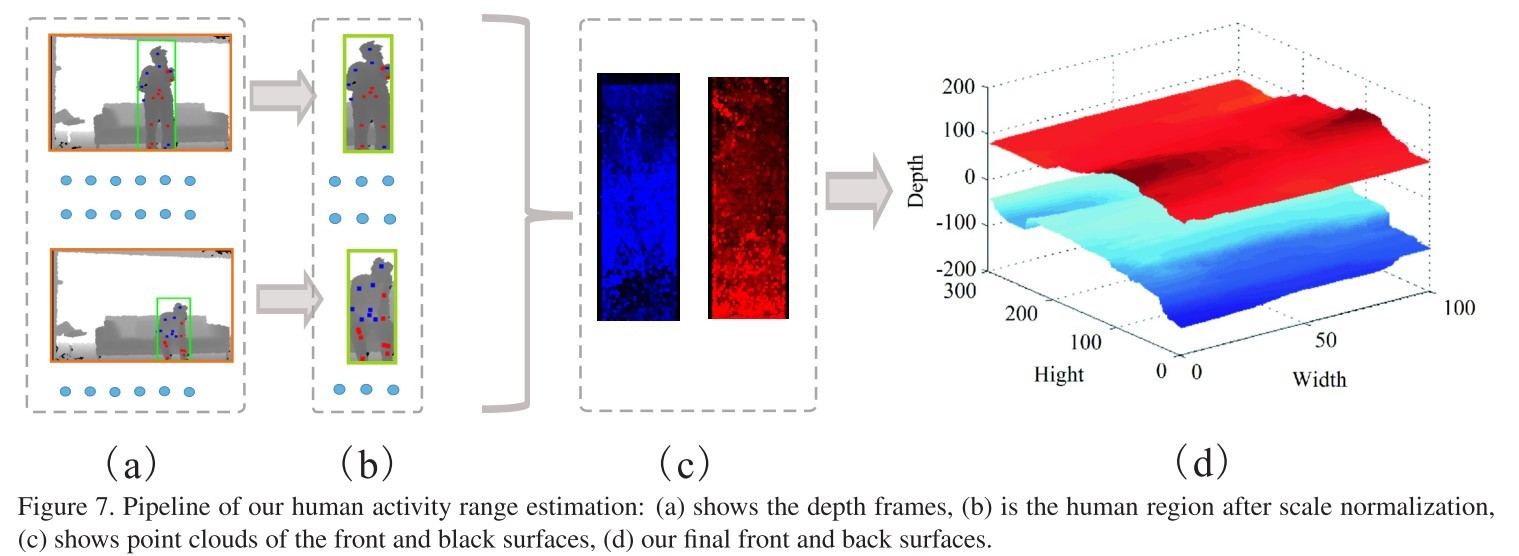
预处理
首先从Kinect中提取出人体骨架点的位置(x,y,d)。对于提取出的骨架点进行归一化处理,即取其平均深度为0。
尺度归一化
因为动作类型的不同,所以需要对人体区域进行归一化处理。这里的归一化是指x-y平面的尺度归一化。作者在文中的处理方法是,对于骨架点做留有裕度为15%的矩形bounding box。然后把这些bounding box归一化为300 × 100。如图(b)。
点云处理
作者在本文把深度划定为3个范围,前景(遮挡区域),活动区,背景。为了划定出2个边界,首先采集前景和背景的种子点(seed points),再从种子点中找到前景-活动区域边界和活动区域-背景边界。其中,前景种子点为深度小于0的点对应的范围,背景种子点为比30cm更远的范围的点。然后,对训练数据集中的所有图片的所有前景种子点和所有背景种子点放在同一幅图上,这两部分的点云分别记为 Cfront 和 Cback 。
Max- and Min-Pooling
对于一个像素点p,则前景边界为
测试时取的边界
在测试时,首先进行尺度归一化(300
×
100大小的人体区域),然后,求出测试图像里的骨架的平均深度,记为
h
。于是,前景边界和背景边界分别为:
其中, ψ[.] 是尺度变化的操作子。这里作者在原文里应该是有typo,把背景的边界的表达式写到和前景边界是一样的。最后加入深度误差修正项,如下:
这里的 z 的单位是mm。于是加入修正项后,测试时前景和背景边界分别为:
于是,这两个边界就把图像的深度范围分割为前景,活动区和背景三个范围。以便为下文的特征提取做准备
特征设计
重温 τ 检验
对于一个patch,
τ
检验定义为:
其中, p(j) 为像素点在 j 处的值(对于灰度图像,是灰度值。对于深度图像,是指深度值)。对于一个patch,可以随机选取多对像素点进行
通过 τ 检验计算所得特征实质上一个弱的边缘特征。大量的 τ 检验的结果组合的特征会有很强的表达复杂结构的能力,而且还具备尺度不变性、旋转不变性、背景不变性、遮挡不变性、小范围的视角转换不变性和信息丢失(深度信息丢失)不变性等优良的性质。在后文有详细分析。
二值化特征设计
类比于RGB图像,深度图像也可以计算
τ
检验。本文仅仅会用到RGB-D图像中的深度图像,并没有用到RGB作为辅助数据参与计算。对于像素点对,如果两个像素点都在前景(遮挡物)上,对于人体动作识别是没有什么用处的,甚至会有害,如果都在背景上,同样用处不大。如果一个在背景一个在前景,也需要滤除。于是要滤除这三类像素点对。
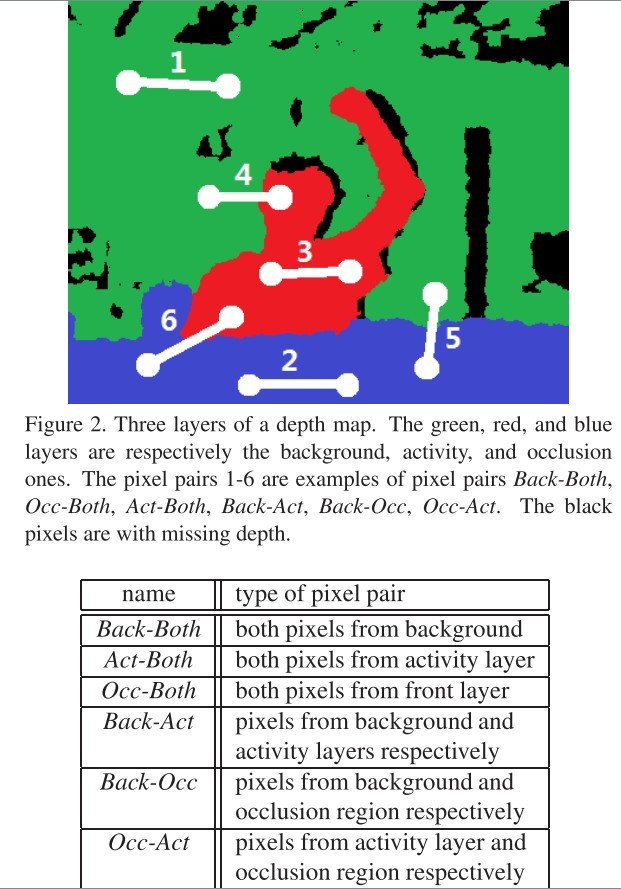
又因为,前景与活动区之间的像素点对,主要是因为遮挡导致的信息的缺失,所以也不能加入特征中。
活动区内的像素点对往往指示了人体的动作,背景-活动区的像素点对往往可以体现人体的轮廓。因此,最终,只有像素点对都在活动区域,或者一个像素点在活动区一个像素点在背景区域的像素点对才会被先采样再进行
τ
检验。对应于上图,就是像素点对3,像素点对4的情形才会计算
τ
检验。
为了达到这个滤除的功能,就需要用到上一节所述的,找到前景和背景的边界,然后把空间分割成三层。这里不重复说了。
特征提取和比较
特征立方体(cubes)
文章中的特征都是在一个时空局部3D立方体里提取的,该立方体中心为
(x,y,t)
,其中
(x,y)
是空间轴,
t
是时间轴。所以,一个cube的大小为
在本文中,当中心点为
(x,y,t)
时,
dx
或
dy
的大小为
αH(x,y,t)
,其中
α
为当深度为1m时,垂直或者水平长度为的0.6m的线段对应于图像里的像素值,
H(x,y,t)
为中心点的深度。
修正后的 τ 检验
先对于每个cube内的像素点,提取出合适的像素点对。然后对这些像素点对进行抽样。文章对于每一帧图像提取512个像素点对,其中256个像素点对是均匀分布抽样,另外有256个像素点对的两点之间的空间距离服从高斯分布。
然后,作者对于这些像素点对提取修正后的
τ
检验形成特征,如下:
如上文所述, 这里的p(j)指的是像素j处的深度,阈值c=20cm。这里, τ1 和 τ2 可以看作是像素点i,j形成的相位特征和辐值特征。
于是,一帧提取512个特征,一个cube内包含T帧图像,所以一个cube的特征大小为 T×512×2 位。文章作者称这些特征为range-sample feature。
为了使提取出来的特征具有一定的旋转不变性,还对图片进行 −30o,−15o,0,15o,30o 的旋转,并提取特征。即一个cubes提取5组特征,所以一个cube的特征大小为 5×T×512×2 位。
特征匹配
对于两个给定的cube,计算其Hamming距离。于是两个cube之间可以得到 5×5=25 个Hamming距离,取其中最小的为特征匹配值为匹配结果。
效率上的讨论
虽然计算两个cube之间的Hamming距离是很快的,但是这个特征是弱特征,作出一次决策需要大量的比较。于是作者提出了以下的方法,来找到与当前cube距离最小的cube的滤除方法。
以
C
表示在test视频中的一个cube,然后与已经学习过的cube
上式中, d(Tu,Ti) 可以提前计算, d(Ti,C) 在之前的比较中已经计算过。所以, d(Tu,C) 的下界可以很快就计算出来,并把较大的cube拒绝。
总结
本文作者提出了一个易于计算的深度图像特征,这个特征还非常易于并行化的计算,取得的效果也非常不错(这部分可以看论文原文的实验数据)。
论文原文下载地址:http://download.csdn.net/detail/icelights/8765861















 3654
3654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









