







一、基本思想
序列最小最优化算法(Sequential Minimal Optimization, SMO)。优化目标函数:
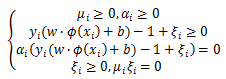
二、目标函数的优化
假设选择的变量是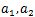 ,其他变量固定。定义
,其他变量固定。定义



根据约束条件,
 均只能取值1或-1,这样
均只能取值1或-1,这样
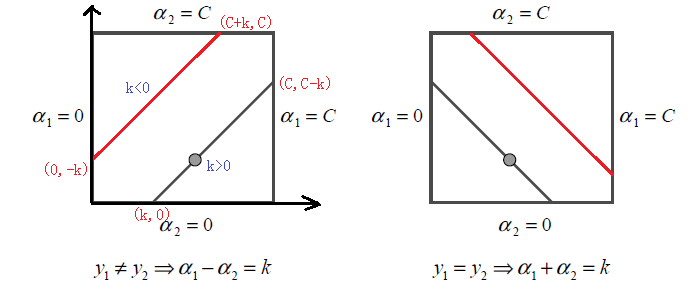
 的盒子内,且二者的关系直线斜率只能为1或-1,这样它们的关系被限制在盒子里的一条线段上,所以两变量的优化问题实际上是一个变量的优化问题,不妨考虑为变量a2的最优化问题。
的盒子内,且二者的关系直线斜率只能为1或-1,这样它们的关系被限制在盒子里的一条线段上,所以两变量的优化问题实际上是一个变量的优化问题,不妨考虑为变量a2的最优化问题。
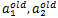 ,本轮迭代完成后的解是
,本轮迭代完成后的解是
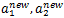 ,假设沿着约束方向a2未经剪辑的解是
,假设沿着约束方向a2未经剪辑的解是
 。由于
。由于
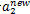 必须满足上图中的线段约束,假设L和H分别是图中
所在线段的边界。显然有:
必须满足上图中的线段约束,假设L和H分别是图中
所在线段的边界。显然有:
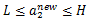

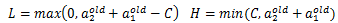 ,则最终的
应该为:
,则最终的
应该为:

 ,可以得到
,可以得到
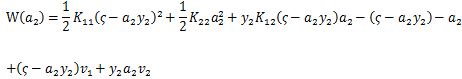
对a2求偏导数,令其为0,得到
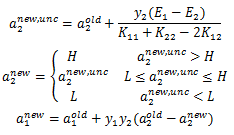
三、两个变量的选择
SMO算法需要选择两个变量迭代,其中至少一个变量是违反KKT条件的,其余变量做常量进行优化。3.1 第一个变量的选择
SMO算法称选择第一个变量的过程为外层循环,这个变量需要选择在训练集中违反KKT条件最严重的样本点,对于每个样本点,要满足的KKT条件如下: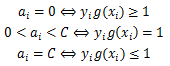
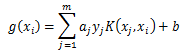
3.2 第二个变量的选择
SMO称选择第二个变量的过程为内层循环,假设在外层循环中已经找到第一个变量a1,第二个变量选择的标准是希望能使a2有足够大的变化。是依赖于
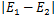 的,由于a1确定后,E1也确定了,所以要使
最大,只需在E1为正时,选择最小的Ei作为E2,在E1为负时,选择最大的Ei作为E2。为了节省计算时间,将所有Ei值保存在一个列表中。
的,由于a1确定后,E1也确定了,所以要使
最大,只需在E1为正时,选择最小的Ei作为E2,在E1为负时,选择最大的Ei作为E2。为了节省计算时间,将所有Ei值保存在一个列表中。
在特殊情况下,如果内层循环通过以上方法选择的a2不能使目标函数有足够的下降,那么遍历在间隔边界上的支持向量点,将其对应的变量作为a2试用,直到目标函数有足够的下降;若找不到,遍历训练数据集;若仍找不到合适的a2,则放弃第一个a1,再通过外层循环寻求另外的a1。
3.3 计算阈值b和差值Ei
在每次完成两个变量的优化后,都需要重新计算阈值b,当 时,由KKT条件可知:
时,由KKT条件可知:

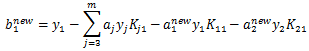

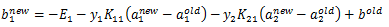
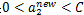 ,那么
,那么
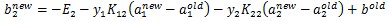

四、SMO算法

五、SVM算法小结
SVM算法是一个很优秀的算法,在集成学习和神经网络之类的算法没有表现出优越性能前,SVM基本占据了分类模型的统治地位。目前则是在大数据时代的大样本背景下,SVM由于其在大样本时超级大的计算量,热度有所下降,但是仍然是一个常用的机器学习算法。
SVM算法的主要优点有:
1) 解决高维特征的分类问题和回归问题很有效,在特征维度大于样本数时依然有很好的效果。
2) 仅仅使用一部分支持向量来做超平面的决策,无需依赖全部数据。
3) 有大量的核函数可以使用,从而可以很灵活的来解决各种非线性的分类回归问题。
4) 样本量不是海量数据的时候,分类准确率高,泛化能力强。
SVM算法的主要缺点有:
1) 如果特征维度远远大于样本数,则SVM表现一般。
2) SVM在样本量非常大,核函数映射维度非常高时,计算量过大,不太适合使用。
3)非线性问题的核函数的选择没有通用标准,难以选择一个合适的核函数。
4)SVM对缺失数据敏感。















 697
697

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









